
- 1[附源码]Java计算机毕业设计SSM航空订票系统
- 2Spring boot Druid 多数据源JDBC和注解事务_mybatisplus druid多数据源
- 3GitHub打不开解决办法
- 4python获取app信息的库_python爬取 “得到” App 电子书信息
- 5【SQL】一文详解嵌入式SQL(建议收藏)_嵌入式sql编程
- 6零基础手把手教你如何使用Laf免费玩转Midjourney
- 7安全模型和业务安全体系_ipdrr 安全模型
- 8零基础入门:使用Python pyWinAuto自动化你的Windows任务_windows pyton automatic
- 9QProgressBar+中间显示文本
- 10你必须要掌握的大数据计算技术,都在这了
存内计算技术—解决冯·诺依曼瓶颈的AI算力引擎_存内计算非冯诺依曼架构
赞
踩
存内计算技术背景
存内计算技术是一种革新性的计算架构,旨在克服传统冯·诺依曼架构的瓶颈,并实现更高效的数据处理。随着大数据时代的到来,传统的冯·诺依曼架构已经难以满足不断增长的计算需求,因为它将处理单元和存储器分开,导致数据传输成本高昂且计算效率低下。存内计算技术的提出就是为了解决这个问题。
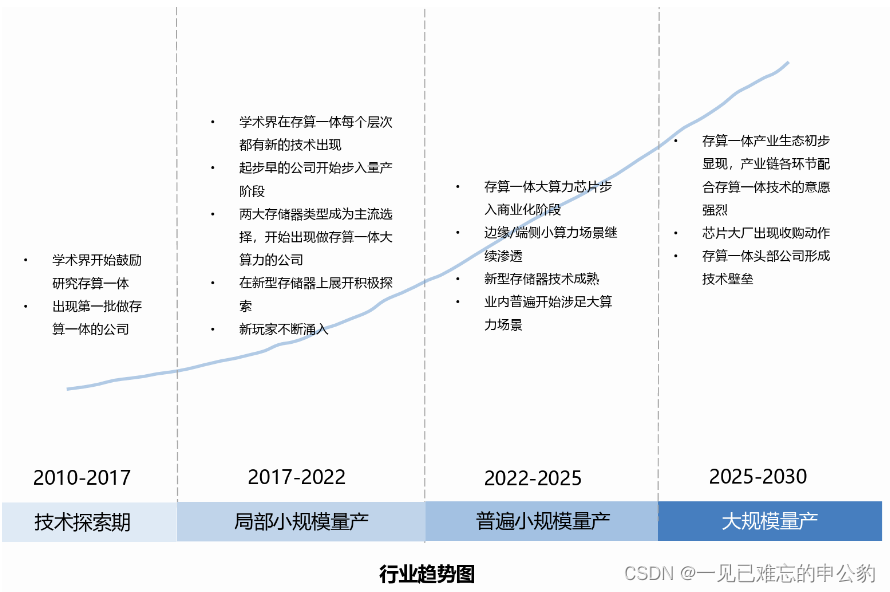
存内计算产业分析如下图:
CSDN首个存内计算开发者社区
CSDN首个存内计算开发者社区来了,基于知存科技领先的存内技术,涵盖最丰富的存内计算内容,以存内技术为核心,史无前例的技术开源内容,囊括云/边/端侧商业化应用解析以及新技术趋势洞察等, 邀请业内大咖定期举办线下存内workshop,实战演练体验前沿架构;从理论到实践,做为最佳窗口,存内计算让你触手可及。
传送门:https://bbs.csdn.net/forums/computinginmemory
首个存内计算开发者社区,0门槛新人加入,发文享积分兑超值礼品;
成为存内计算大使,享受资源支持与激励,打造亮眼个人品牌,共同引流存内计算潮流。

硅基光电子技术
近年来,硅基光电子技术在高密度、高性能光电集成电路方面崭露头角,尤其是其与CMOS技术的兼容性,为其成为大规模、廉价光电子集成电路平台打开了无限可能。然而,硅材料的禁带宽度却使其在通信波段的光电探测器应用受到限制,引发对光电转换的迫切需求。
光电转换作为光互连系统中不可或缺的关键部分,要求高速和高灵敏度的探测器,而传统的冯·诺依曼体系结构却面临着内存与计算单元之间频繁数据传输的问题,导致大量能源的消耗,尤其在资源受限的设备中更为显著。这就是我们迎来的存储墙问题。
为了解决这一问题,学者们提出了内存计算(computing in-memory, CIM)技术,一种能够直接在内存中进行计算的新型体系结构。而在内存计算技术中,基于静态随机存取存储器(SRAM)的存内计算成为研究热点,其单元的健壮性和存取速度使其成为突破冯·诺依曼瓶颈的一项关键技术。
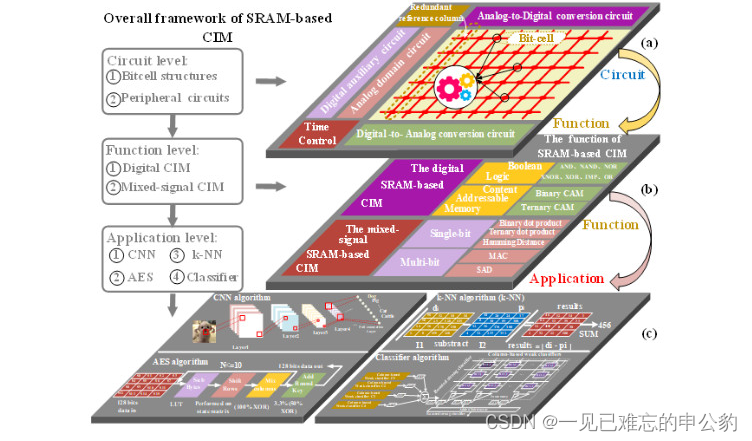
第一个层面电路主要包括两方面:
1)基本存储单元,包括读写分离结构、可转置结构和紧凑耦合结构;
2)外围辅助电路,包括模数转换电路(analog-to-digitalconversion, ADC)、数模转换电路(digital-to-analogconversion, DAC)、冗余参考列,数字辅助电路和模拟辅助电路(图1(a))。
第二个层面所能实现的运算操作:
1)纯数字存内计算,包括布尔逻辑和内容可寻址(content-addressablememory, CAM);
2)混合信号存内计算,包括乘累加(multiplication andaccumulation, MAC)、汉明距离和绝对值差和(sum of absolute difference, SAD)(图1(b))。
第三个层次主要从加速卷积神经网络算法(Convolutional Neural Network, CNN)、分类器算法、模式识别算法(k-nearest neighbor, k-NN)和高级加密标准算法(Advanced Encryption Standard, AES)等应用方面进行总结与回顾(图1©)。
存内计算提升AI算力
存内计算:AI芯片领域的璀璨明星
在人工智能(AI)的时代浪潮中,存内计算技术被广泛认为是最适合AI的芯片架构,备受学术界和产业界的瞩目。2018年,国际固态电路会议(ISSCC)专门设立了存内计算议程,为该领域的深入讨论奠定了基础。而在2019年和2020年,ISSCC会议上关于存内运算的论文更是如火如荼,仅ISSCC2020就涌现了7篇与存内计算相关的论文。
学术界在电子器件领域的研究会议中也持续掀起存内计算的热潮。在2019年的IEDM会议上,有三个专门的议程,共呈现了二十余篇与存内计算相关的论文。这一现象反映了学术界对于存内计算技术前景的高度关注和积极探索。

除了学术界的深入研究外,产业界也纷纷加入存内计算的布局。IBM以其独特的相变存内计算技术为基础,积累了数年的技术经验。台积电正在全力推进基于ReRAM的存内计算方案。而在产业投资方面,诸如英特尔、博世、美光、Lam Research、应用材料、微软、亚马逊、软银等巨头已纷纷投资于基于NOR Flash的存内计算芯片。
事实上,利用存储器进行计算的研究可追溯至上世纪90年代。然而,长期以来,存内计算一直未能真正实现产业落地。这一现象的原因在于设计挑战较大,更为关键的是缺乏杀手级应用。然而,随着深度学习的大规模爆发,存内计算技术才开始逐渐走向产业化,成为AI芯片领域的璀璨明星。
存内计算技术的兴起得益于深度学习技术的蓬勃发展,为其提供了杀手级应用。深度学习的大规模应用使得对计算速度和效率的需求急剧增加,而传统的冯·诺依曼架构面临着瓶颈。存内计算技术通过将计算与存储结合,避免了数据在内存和处理器之间频繁传输的问题,极大地提高了计算效率。这为AI应用提供了更加高效、快速的计算解决方案,成为当前AI芯片领域的重要技术趋势。
知存科技存算一体芯片技术
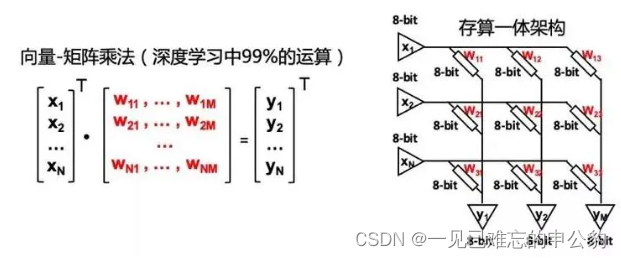
知存科技引领存内计算技术:NOR FLASH芯片的崭新时代
存内计算技术正成为人工智能芯片领域的一颗璀璨明星,而知存科技凭借其先进的NOR FLASH存内计算技术正引领这一技术的新时代。

王绍迪在谈及NOR FLASH存内计算时指出,相较于使用数字电路计算,NOR FLASH在进行存内计算时能够显著减少数据搬运消耗的能量。更为引人瞩目的是,NOR FLASH在乘加法运算方面的功耗也相当低,这为芯片带来了百倍甚至千倍的功耗降低。考虑到外围电路的功耗,NOR FLASH存内计算最终能够实现的功耗降低在几十倍到上百倍之间,不同的算法和应用也将实现不同程度的提升。
目前,NOR FLASH存内计算技术已经在单芯片中支持了约300M左右的深度学习权重参数,无需额外的内存即可进行计算。这使得该技术能够满足大部分AI场景的需求。智能语音模型和端侧图像推理模型的大小通常在几百K到几十兆之间,而NOR FLASH存内计算芯片却能轻松胜任这些任务。
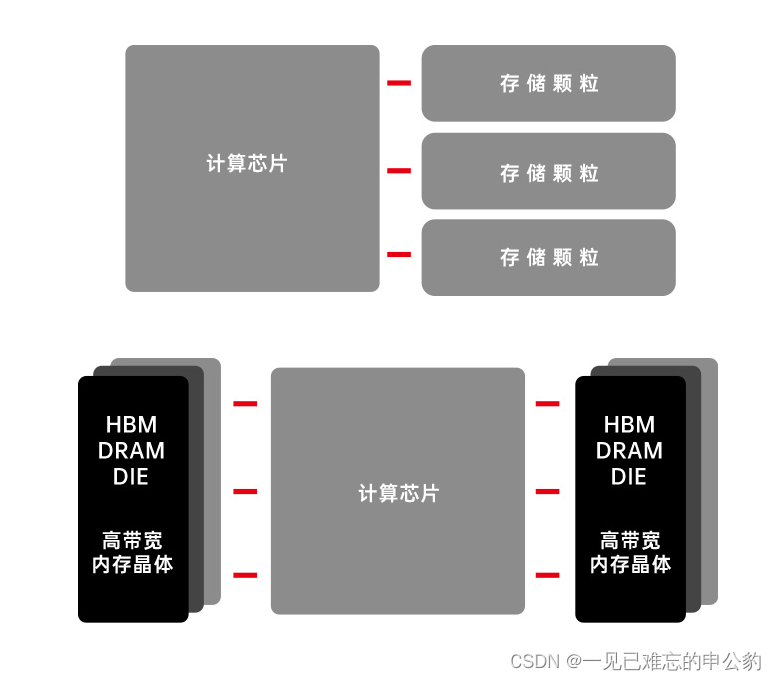
存内计算技术不仅能够支持主流的8比特模型精度,而且还在研发高达16比特的解决方案以满足更高要求的极限场景。王绍迪表示,知存科技的目标是未来存内计算技术能够覆盖60%-70%的AI应用,为各种场景提供高效、低功耗的计算解决方案。
知存科技在存内计算技术上的技术水平领先业界3-4年。早在2012、2013年,郭昕婕博士就开始研究基于NOR FLASH的存内计算技术。与其他公司相比,知存科技投入研发的时间更早,经历了一系列流片迭代,积累了大量的技术经验。存内计算涉及到的设计挑战包括控制电路、模拟电路、编程技术、可靠性设计和架构设计等方面。特别是模拟设计方面,由于FLASH进行的是模拟计算,需要满足数字电路算法的要求,这对模拟运算提出了严格的要求。
存内处理
“存”与“算”距离更近,但电路设计仍然是分离的,
计算由存储器内部的独立计算单元完成。

基于存内计算的语音芯片的实现挑战
深度学习已广泛应用于各类人工智能任务,但传统的深度学习加速器在面向数据流的计算架构优化上仍受制于传统冯·诺依曼体系结构所带来的「存储墙」问题。频繁的计算单元与存储单元间数据搬移导致了巨大的能耗,迫切需要创新性的解决方案。
存内计算技术(computing-in-memory,CIM)崭露头角,成为解决「存储墙」问题的有效途径。然而,传统存内计算仅支持有限的运算,例如向量内积。为了支持完整的AI应用,一支团队在可重构计算架构的基础上,融合了存内计算技术,成功设计了一款数模混合计算芯片,代号为Thinker-IM。这一创新性的芯片在语音识别应用中展现出了卓越的能耗表现。
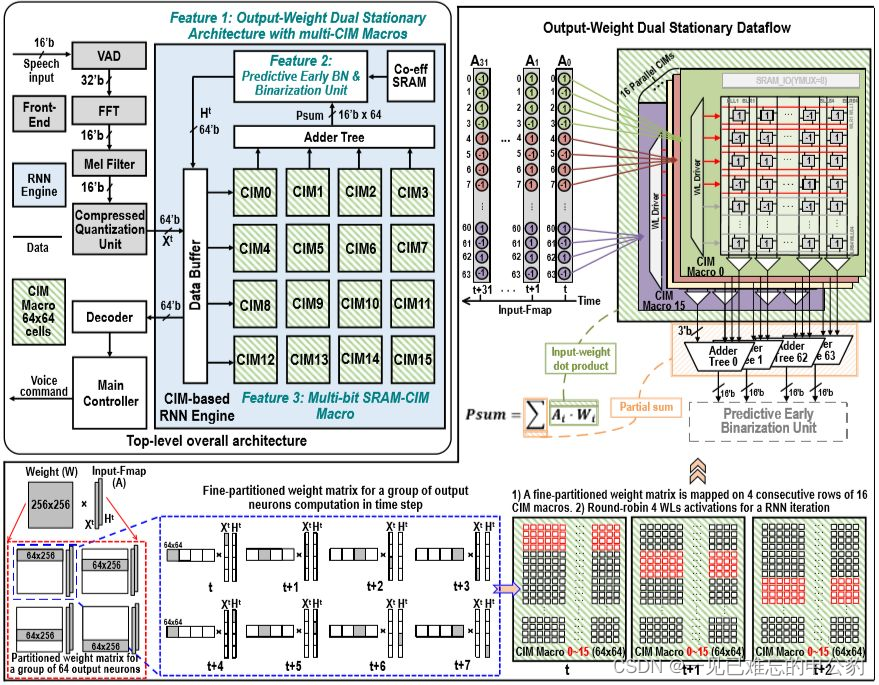
挑战一:需要设计融合多个 SRAM-CIM 单元的计算架构和数据流调度方案。一般情况下,单个 SRAM-CIM 无法存下 DNN 中的全部权重。因此需要多个 SRAM-CIM 单元协同计算,需要考虑如何组织它们的计算方式。
挑战二:需要针对复杂 AI 任务设计多比特输出 SRAM-CIM 单元。对于简单 AI 任务(如手写体识别),SRAM-CIM 单元 1 比特输出精度可以满足识别需求。但对于复杂的识别任务(如语音识别),SRAM-CIM 单元 1 比特输出就会导致 Partial Sum(部分和)的精度损失,影响最终识别精度。
挑战三:RNN 推理过程是一种时域上的迭代计算,其计算过程相当耗时。我们发现在二值 RNN 中的累加过程中存在一些冗余计算。见图 2©,在累加过程中,如果中间数据足够大而超过剩余累加的最大值,将保证最终结果大于 0。此时剩余累加周期的计算就是冗余的,如能去除这些计算,将能够有效加速 RNN 计算。
Thinker-IM 架构如图所示,主要包括语音信号处理部分和基于 CIM 的 RNN 计算引擎。芯片设计中三项关键技术分别针对性解决了上述三个问题。
参考文献
1.中国科学院-基于静态随机存取存储器的存内计算研究综述:电路,功能以及应用
2.知存科技
3.Thinker 人工智能芯片团队 清华大学微电子所
4.存内计算白皮书
![解决“由于没有远程桌面授权服务器可以提供许可证……”(亲测可用)_[window title] 远程](https://img-blog.csdnimg.cn/direct/e6942f34fd114213b5ba4b41eb861c50.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

