
热门标签
热门文章
- 1书生·浦语大模型实战营-学习笔记1
- 2【服务器数据恢复】FreeNAS+ESXi虚拟机数据恢复案例
- 3Axure9.0零基础学习篇 一元件库_元件库定义
- 4Anaconda创建虚拟环境默认在C盘:如何更改?_anaconda prompt默认c盘
- 5python 基本特点_python的基本特性
- 6Java高并发编程实战8,同步容器与并发容器
- 7Sonatype Nexus安装
- 8搭建个人深度学习环境(二)—— Xfce4 远程桌面安装及配置_xfce4 限制系统访问
- 9ERROR 1198 (HY000): This operation cannot be performed with a running slave; run STOP SL
- 10【SpringBoot】24、SpringBoot中实现数据字典_springboot 数据字典
当前位置: article > 正文
python编程代码大全小海龟,python编程代码大全分享
作者:菜鸟追梦旅行 | 2024-02-19 21:45:34
赞
踩
python编程代码大全小海龟,python编程代码大全分享
这篇文章主要介绍了python编程代码大全 初学编程100个代码,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。

大家好,给大家分享一下python语言的代码书写规则有哪些,很多人还不知道这一点。下面详细解释一下python自学好学嘛。现在让我们来看看!
一些常用的python代码合集,方便检索引用
模块1:读写excel文件
- from datetime import datetime
- import odps
- import xlwt
- import os
- from odps import DataFrame
- import pandas as pd
- import xlrd
- import numpy as np
- from collections import defaultdict
- from collections import Counter
-
-
- # 写入工作簿
- def write_imf(fl_save_path, data):
- wb = xlwt.Workbook(encoding='utf-8') # 不写encoding会出现编码错误
- sh = wb.add_sheet(u'data', cell_overwrite_ok=True)
-
- # 表头部分,单独写
- colnames = data.columns.values
- for i in range(0, data.shape[1]):
- sh.write(0, i, colnames[i])
- # 表内容,循环写入,好像没简便的方法
-
- for i in range(1, len(data) + 1):
- for j in range(0, data.shape[1]):
- value = data.iloc[i - 1, j]
- # print(value)
- # 这里的坑特别多!!!数据读进来之后就成numpy.xxx64的类型了,在dataframe的时候就需要统一干掉!
- try:
- value.dtype
- if value.dtype == 'int64':
- value = int(value)
- # print('value is:%d,type is:%s'%(value,type(value)))
- if value.dtype == 'float64':
- value = float(value)
- # print('value is:%d,type is:%s' % (value, type(value)))
- except(RuntimeError, TypeError, NameError, ValueError, AttributeError):
- pass
- sh.write(i, j, value)
-
- wb.save(fl_save_path)
- print('congratulation save successful!')
-
- def save_pd_to_csv(fl_save_path, data):
- try:
- # 直接转csv不加encoding,中文会乱码
- data.to_csv(fl_save_path, encoding="utf_8_sig", header=True, index=False) # 存储
- return True
- except:
- return False
-
- def get_excel_content(file_path):
- # 获取excel内的SQL语句,需要通过xlrd获取workbook中的SQL内容,或者读txt,后续改为配置文件
- wb = xlrd.open_workbook(file_path, encoding_override='utf-8')
- sht = wb.sheet_by_index(0) # 默认第一个工作表
- # print(sht.name)
- wb_cont_imf = []
- nrows = sht.nrows # 行数
- wb_cont_imf = [sht.row_values(i) for i in range(0, nrows)] # 第一个工作表内容按行循环写入
- df = pd.DataFrame(wb_cont_imf[1:], columns=wb_cont_imf[0])
- return df

模块2:获取各种时间
- # 获取年月第一天最后一天
- def getMonthFirstDayAndLastDay(year=None, month=None):
- """
- :param year: 年份,默认是本年,可传int或str类型
- :param month: 月份,默认是本月,可传int或str类型
- :return: firstDay: 当月的第一天,datetime.date类型
- lastDay: 当月的最后一天,datetime.date类型
- """
- if year:
- year = int(year)
- else:
- year = datetime.date.today().year
- if month:
- month = int(month)
- else:
- month = datetime.date.today().month
-
- # 获取当月第一天的星期和当月的总天数
- firstDayWeekDay, monthRange = calendar.monthrange(year, month)
-
- # 获取当月的第一天
- firstDay = datetime.date(year=year, month=month, day=1)
- lastDay = datetime.date(year=year, month=month, day=monthRange)
-
- # return firstDay, lastDay
- return lastDay
模块3:pd中的dataframe转png
- # dataframe2png
- def render_mpl_table(data, col_width=5.0, row_height=0.625, font_size=1,
- header_color='#40466e', row_colors=['#f1f1f2', 'w'], edge_color='w',
- bbox=[0, 0, 1, 1], header_columns=0,
- ax=None,**kwargs):
- if ax is None:
- # size = (np.array(data.shape[::-1]) + np.array([0, 1])) * np.array([col_width, row_height])
- # fig, ax = plt.subplots(figsize=size)
- fig, ax = plt.subplots() # 创建一个空的绘图区
- # 衍生知识点,服务器上安装中文字体
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
- # plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei Mono']
- plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
- plt.style.use('ggplot')
- ax.axis('off')
-
- mpl_table = ax.table(cellText=data.values, bbox=bbox, colLabels=data.columns, **kwargs)
-
- mpl_table.auto_set_font_size(False)
- mpl_table.set_fontsize(font_size)
-
- for k, cell in six.iteritems(mpl_table._cells):
- cell.set_edgecolor(edge_color)
- nrow = k[0]
- ncol = k[1]
- # 设置表格底色
- if nrow == 0 or ncol < header_columns:
- cell.set_text_props(weight='bold', color='w')
- cell.set_facecolor(header_color)
- else:
- cell.set_facecolor(row_colors[k[0] % len(row_colors)])
-
- # # 对当日异常数据为0的部分,着重体现
- # row_num = []
- # for k, cell in mpl_table._cells.items():
- # nrow = k[0]
- # ncol = k[1]
- # val = cell.get_text().get_text()
- # if nrow > 0 and ncol == 2 and val != '0':
- # row_num.append(nrow)
- # for k, cell in six.iteritems(mpl_table._cells):
- # nrow = k[0]
- # # 设置表格底色
- # if nrow in row_num:
- # cell.set_facecolor('gold')
-
- # 保留原图的设置
- # fig.set_size_inches(width/100.0,height/100.0)#输出width*height像素
- plt.gca().xaxis.set_major_locator(plt.NullLocator())
- plt.gca().yaxis.set_major_locator(plt.NullLocator())
- plt.subplots_adjust(top=1, bottom=0, left=0, right=1, hspace=0, wspace=0)
- plt.margins(0, 0)
-
- return ax
模块4:绘制词云
- #!/user/bin/python
- # -*- coding:utf-8 -*-
- _author_ = 'xisuo'
-
- import datetime
- import calendar
- import xlwt
- import os
- import pandas as pd
- import xlrd
- import openpyxl
- import numpy as np
- from collections import defaultdict
- import platform
- from wordcloud import WordCloud,STOPWORDS
- import matplotlib.pyplot as plt
- from PIL import Image
-
-
- def create_wordcloud(docs=None,imgs=None,filename=None):
- '''
- :param docs:读入词汇txt,尽量不重复
- :param imgs: 读入想要生成的图形,网上随便找
- :param filename: 保存图片文件名
- :return:
- '''
- # Read the whole text.
- text = open(os.path.join(current_file, docs)).read()
- alice_mask = np.array(Image.open(os.path.join(current_file, imgs)))
- print(font_path)
- wc = WordCloud(background_color="white",
- max_words=2000,
- font_path=font_path, # 设置字体格式,如不设置显示不了中文
- mask=alice_mask,
- stopwords=STOPWORDS.add("said")
- )
- # generate word cloud
- wc.generate(text)
- # store to file
- if filename is None:filename="词云结果.png"
- wc.to_file(os.path.join(current_file, filename))
-
- def main():
- docs='demo.txt' #读入的文本
- imgs="eg.jpg" #需要绘制的图像
- filename='res_eg.png' #保存图片文件名
- create_wordcloud(docs=docs,imgs=imgs,filename=filename)
- print('create wordcloud successful')
-
- if __name__ == '__main__':
- start_time = datetime.datetime.now()
- print('start running program at:%s' % start_time)
-
- systemp_type = platform.system()
- if (systemp_type == 'Windows'):
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
- plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
- font_path='simfang.ttf'
- try:
- current_path = os.getcwd()
- except:
- current_path = os.path.dirname(__file__)
- current_file = os.path.join(current_path, 'docs')
- current_file = current_path
- elif (systemp_type == 'Linux'):
- font_path = 'Arial Unicode MS.ttf'
- plt.rcParams['font.family'] = ['Arial Unicode MS'] # 用来正常显示中文标签
- plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
- current_file = '/home/xisuo/mhc_work/docs/' # 服务器上的路径
- else:
- quit()
- if not os.path.exists(current_file):
- os.mkdir(current_file)
- print('目录中部存在docs文件夹,完成新文件夹创建过程。')
- print('当前操作系统:%s,文件存储路径为:%s' % (systemp_type, current_file))
-
- main()
-
- end_time = datetime.datetime.now()
- tt = end_time - start_timepython
- print('ending time:%s', end_time)
- print('this analysis total spend time:%s' % tt.seconds)
模块5:下载ppt素材
- #!/user/bin/python
- #-*- coding:utf-8 -*-
- _author_ = 'xisuo'
-
- import urllib.request
- import requests
- from bs4 import BeautifulSoup
- from lxml import etree
- import os
-
- url='http://www.pptschool.com/1491.html'
-
- response=requests.get(url).text
- # soup=BeautifulSoup(response,'lxml')
- # cont=soup.find('article', class_='article-content')
-
- html=etree.HTML(response)
-
- src_list=html.xpath('//div/article/p/img/@src')
-
- current_path=os.path.dirname(__file__)
- save_path=os.path.join(current_path,'ppt_img')
-
- if os.path.exists(save_path):
- pass
- else:
- os.mkdir(save_path)
- print('img folder create successful')
-
- i=1
- for src in src_list:
- save_img_path=os.path.join(save_path,'%d.jpg'%i)
- try:
- with open(save_img_path,'wb') as f:
- f.write(urllib.request.urlopen(src).read())
- f.close()
- i=i+1
- print('save true')
- except Exception as e:
- print('save img fail')
模块6:模型存储和读取
- rom sklearn import joblib
- from sklearn import svm
- from sklearn2pmml import PMMLPipeline, sklearn2pmml
- import pickle
-
- def save_model(train_X,train_y):
- ''''
- save model
- :return:
- '''
- clf = svm.SVC()
- clf.fit(X, y)
- joblib.dump(clf, "train_model.m")
- sklearn2pmml(clf, "train_model.pmml")
- with open('train_model.pickle', 'wb') as f:
- pickle.dump(clf, f)
- return True
-
- def load_model():
- '''
- laod model
- :return:
- '''
- clf_joblib=joblib.load('train_model.m')
- clf_pickle== pickle.load(open('linearregression.pickle','rb'))
- return clf_joblib,clf_pickle
模块7:TF-IDF
- import time
- import pandas as pd
- import numpy as np
- from sklearn.feature_extraction.text import CountVectorizer
- from sklearn.feature_extraction.text import TfidfVectorizer
-
- # 读取数据 - 性能不好待优化
- print('开始读取KeyTag标签...')
- read_data_path = 'D:/untitled/incomelevel_kwtag_20190801.txt'
- load_data = pd.read_csv(read_data_path, sep='\t',encoding='utf-8')
- data = pd.DataFrame(load_data,columns = ['income_level','kw_tag'])
- print('...读取KeyTag标签完成')
-
-
- # 将数据分组处理
- print('开始分组处理KeyTag标签...')
- # 高收入
- incomelevel_top = data[data['income_level'] == '高']
- incomelevel_top = incomelevel_top.head() #test
- kw_tag_top = ' '.join(incomelevel_top['kw_tag'])
- print('kw_tag_top : \n',kw_tag_top)
- # 中收入
- incomelevel_mid = data[data['income_level'] == '中']
- incomelevel_mid = incomelevel_mid.head() #test
- kw_tag_mid = ' '.join(incomelevel_mid['kw_tag'])
- print('kw_tag_mid : \n',kw_tag_mid)
- # 低收入
- incomelevel_low = data[data['income_level'] == '低']
- incomelevel_low = incomelevel_low.head() #test
- kw_tag_low = ' '.join(incomelevel_low['kw_tag'])
- print('kw_tag_low : \n',kw_tag_low)
-
- print('...分组处理KeyTag标签完成')
-
- # 开始加载TF-IDF
- vectorizer = CountVectorizer()
- result = vectorizer.fit_transform([kw_tag_top, kw_tag_mid, kw_tag_low])
- transformer = TfidfVectorizer()
- kw_tag_score = transformer.fit_transform([kw_tag_top, kw_tag_mid, kw_tag_low])
- print('...KeyTag分词结束')
- # 获取全量标签
- kw_tag_value = transformer.get_feature_names()
- result_target = pd.DataFrame(kw_tag_value,columns = ['kw_tag'])
- print('result_target : \n',result_target)
- # 分词得分处理
- tf_score = kw_tag_score.toarray()
- print('tf_score : \n',tf_score)
- kw_tag_score_top = pd.DataFrame(tf_score[0],columns = ['kw_tag_score_top']) # 217
- kw_tag_score_mid = pd.DataFrame(tf_score[1],columns = ['kw_tag_score_mid'])
- kw_tag_score_low = pd.DataFrame(tf_score[2],columns = ['kw_tag_score_low'])
- print(len(kw_tag_score_top))
模块8:生成省市地图
- import time
- import pandas as pd
- import xlrd
- import re
- import matplotlib.pyplot as plt
- import six
- import numpy as np
- # 载入ppt和pyecharts相关的包
- from pyecharts.render import make_snapshot
- from snapshot_phantomjs import snapshot
- from pyecharts import options as opts
- from collections import defaultdict
- from pyecharts.charts import Bar, Geo, Map, Line,Funnel,Page
- import os
- from example.commons import Faker
-
- def create_zjs_map():
- folder_path = os.getcwd()
- file_name = "白皮书数据地图.xlsx"
- file_path = os.path.join(folder_path, file_name)
- dat = get_excel_content(file_path, sheet_name="省份地图")
-
- df = dat[['城市', '渗透率']]
- df.columns = ['city', 'penarate']
- print(df)
-
- # df['city'] = df['city'].apply(lambda x: reg.sub('', x))
- citys = df['city'].values.tolist()
- values = df['penarate'].values.tolist()
- print(citys)
- print('{:.0f}%'.format(max(values)*100),'{:.0f}%'.format(min(values)*100))
-
- city_name='浙江'
- penetration_map = (
- Map(init_opts=opts.InitOpts(width='1200px', height='1000px', bg_color='white'))
- .add("{}透率分布".format(city_name), [list(z) for z in zip(citys, values)], city_name)
- .set_series_opts(
- label_opts=opts.LabelOpts(
- is_show=True,
- font_size=15
- )
- )
- .set_global_opts(
- visualmap_opts=opts.VisualMapOpts(
- is_show=True,
- max_=max(values),
- min_=min(values),
- is_calculable=False,
- orient='horizontal',
- split_number=3,
- range_color=['#C2D5F8', '#88B0FB', '#4D8AFD'],
- range_text=['{:.0f}%'.format(max(values)*100),'{:.0f}%'.format(min(values)*100)],
- pos_left='10%',
- pos_bottom='15%'
- ),
- legend_opts=opts.LegendOpts(is_show=False)
- )
- )
- # penetration_map.render()
- make_snapshot(snapshot, penetration_map.render(), "zj_map.png")
- print('保存 zj_map.png')
- return penetration_map
-
- def create_county_map(city_name):
-
- folder_path = os.getcwd()
- file_name = "白皮书数据地图.xlsx"
- file_path = os.path.join(folder_path, file_name)
- dat = get_excel_content(file_path, sheet_name="城市地图")
-
- df = dat[['city', 'county', 'penarate']][dat.city == city_name]
-
- citys = df['county'].values.tolist()
- values = df['penarate'].values.tolist()
- max_insurance = max(values)
-
- print(citys)
-
- province_penetration_map = (
- Map(init_opts=opts.InitOpts(width='1200px', height='1000px', bg_color='white'))
- .add("{}透率分布".format(city_name), [list(z) for z in zip(citys, values)], reg.sub('',city_name))
- .set_series_opts(
- label_opts=opts.LabelOpts(
- is_show=True,
- font_size=15
- )
- )
- .set_global_opts(
- visualmap_opts=opts.VisualMapOpts(
- is_show=True,
- max_=max(values),
- min_=min(values),
- is_calculable=False,
- orient='horizontal',
- split_number=3,
- range_color=['#C2D5F8', '#88B0FB', '#4D8AFD'],
- range_text=['{:.0f}%'.format(max(values) * 100), '{:.0f}%'.format(min(values) * 100)],
- pos_left='10%',
- pos_bottom='5%'
- ),
- legend_opts=opts.LegendOpts(is_show=False)
- )
- )
- # insurance_map.render()
- make_snapshot(snapshot, province_penetration_map.render(), "city_map_{}.png".format(city_name))
- print('保存 city_map_{}.png'.format(city_name))
- return province_penetration_map
-
- def create_funnel_label():
-
- folder_path=os.getcwd()
- file_name = "白皮书数据地图.xlsx"
- file_path = os.path.join(folder_path, file_name)
- dat = get_excel_content(file_path, sheet_name="漏斗图")
-
- df = dat[['category', 'cnt']]
- print(df)
-
- category = df['category'].values.tolist()
- values = df['cnt'].values.tolist()
-
- funnel_map = (
- Funnel(init_opts=opts.InitOpts(width='1200px', height='1000px', bg_color='white'))
- .add("漏斗图", [list(z) for z in zip(category, values)])
- .set_series_opts(
- label_opts=opts.LabelOpts(
- position='inside',
- font_size=16,
- )
- )
- .set_global_opts(
- legend_opts=opts.LegendOpts(is_show=False)
- )
- )
- # insurance_map.render()
- make_snapshot(snapshot, funnel_map.render(), "funnel.png")
- print('保存 funnel.png')
- return funnel_map
-
- city_list=['温州市','杭州市','绍兴市','嘉兴市','湖州市','宁波市','金华市','台州市','衢州市','丽水市','舟山市']
-
- for city_name in city_list:
- create_county_map(city_name)
关于Python学习资料:
在学习python中有任何困难不懂的可以微信扫描下方CSDN官方认证二维码加入python交流学习
多多交流问题,互帮互助,这里有不错的学习教程和开发工具Deepl降重。
(python兼职资源+python全套学习资料)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具

四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、Python练习题
检查学习结果。
七、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。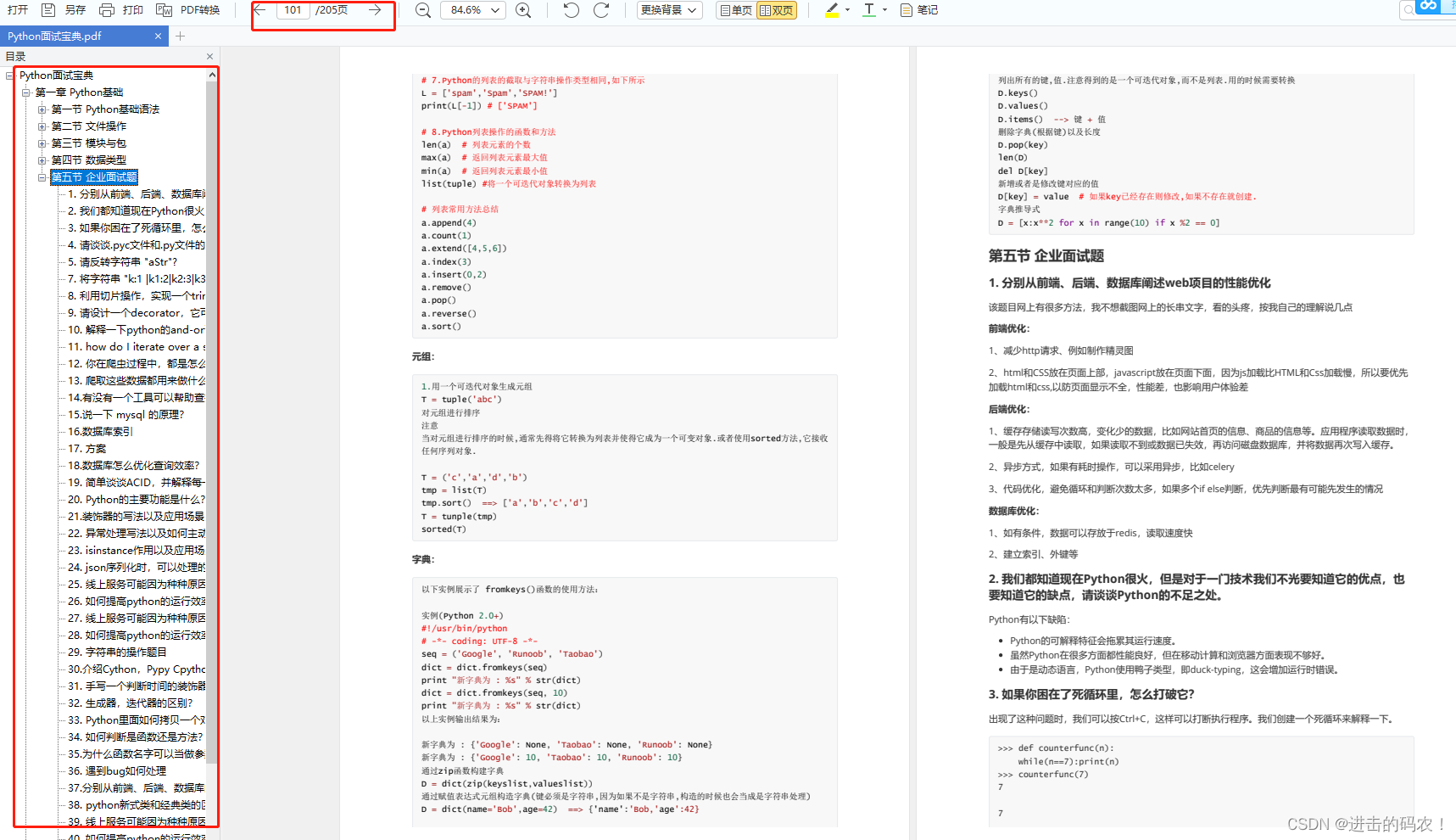

最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。
文章知识点与官方知识档案匹配,可进一步学习相关知识
Python入门技能树首页概览393669 人正在系统学习中
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/116931
推荐阅读
相关标签

