
- 1软件开发:看上去简单,做起来难_软件行业看似简单实则很难的功能
- 2TypeScript 实用程序类型:选择和省略_typesript ... 省略号
- 3three.js CSS2DRenderer、CSS2DObject渲染HTML标签_css2dobject threejs
- 4讨论 | 算法工程师也会遇到35岁这道坎么?
- 5python 环境搭建 -anaconda_python环境anaconda
- 6使用Express搭建https服务器
- 7RabbitMQ整合Spring项目xml配置文件形式_rabbitmq xml配置
- 8使用obi fluid进行洪水模拟,持续更新~_unity 洪水推进
- 9ElasticSearch -- ES 7.x 集群版安装部署_es7部署
- 10GPT Zero 是什么?_zerogpt
【论文解读】针对生成任务的多模态图学习_多模态任务把一种特征映射到另一个向量空间
赞
踩
一、简要介绍

多模态学习结合了多种数据模式,拓宽了模型可以利用的数据的类型和复杂性:例如,从纯文本到图像映射对。大多数多模态学习算法专注于建模来自两种模式的简单的一对一数据对,如图像-标题对,或音频文本对。然而,在大多数现实世界中,不同模式的实体以更复杂和多方面的方式相互作用,超越了一对一的映射。论文建议将这些复杂的关系表示为图,允许论文捕获任意数量模式的数据,并使用模式之间的复杂关系,这些关系可以在不同样本之间灵活变化。为了实现这一目标,论文提出了多模态图学习(MMGL),这是一个通用而又系统的、系统的框架,用于从多个具有关系结构的多模态邻域中捕获信息。特别是,论文关注用于生成任务的MMGL,建立在预先训练的语言模型(LMs)的基础上,旨在通过多模态邻域上下文来增强它们的文本生成。论文研究了MMGL提出的三个研究问题:(1)如何在避免可扩展性问题的同时,向预先训练好LM中注入多个邻域信息,从而避免可扩展性问题?(2)如何将多模态邻域之间的图结构信息注入到LM中?(3)论文如何调整预先训练过的LM,以便以一种参数高效的方式从邻域上下文中学习?论文进行了广泛的实验来回答MMGL上的这三个问题,并分析了实证结果,为未来的MMGL研究铺平了道路。
二、研究背景
在现实世界的应用程序中有不同的数据模态,从常见的文本、图像和视频到时间序列数据或特定领域的模态,如蛋白质序列。这些不同的模态不是单独收集的,而是与它们之间的多方面的关系一起收集的。维基百科是最流行的多模态网络内容来源之一,提供多模态数据,如文本、图像和标题。Meta最近发布的网站使用每个用户的多模态数据构建个人时间线,包括他们的照片、地图、购物和音乐历史。除了这些例子之外,重要的工业和医疗决策也通过考虑多种的多模态数据,如图像、表格或音频。这些多模态数据使它们的多模态实体之间的多对多关系变得复杂——可以用图来表示——为如何全面理解它们提供了开放的研究空间。
随着多模态数据集的兴起,在多模态学习方面进行了各种开创性的研究。以前,多模态学习专注于新的架构,扩展transformer或图神经网络,并使用大规模的多模态数据集从头开始训练它们。在预训练的语言模型(LMs)具有强大的生成能力的推动下,最近的多模态方法建立在预训练的LMs之上,并专注于多模态内容的生成。例如,之前的工作使用预先训练好的图像编码器和LM,基于给定的文本/图像生成图像/文本。然而,所有现有的模型都假设提供了一对具有清晰的1对1映射的模式作为输入(例如,图1(a)中的图像-标题对)。因此,它们不能直接应用于模态之间具有更一般的多对多映射的多模态数据集(例如,图1(b)中的多模态维基百科网页)

在这里,论文将多模态学习的范围从1对1映射扩展到多模态图学习(MMGL)中,同时通过将它们集成到预先训练的LM中来保持生成能力。论文介绍了一个系统的框架,说明MMGL如何处理具有图结构的多模态邻域信息,并使用预先训练的LM生成自由形式的文本(图2)。论文的MMGL框架提取邻域编码,并将它们与图结构信息相结合,并使用参数高效的微调来优化模型。因此,论文定义了三个设计空间来研究MMGL的三个研究问题如下:
研究问题1:论文如何为LM提供多个多模态邻域信息,同时避免可伸缩性问题?
研究问题2:如何将多模态邻域之间的图结构信息注入到LM中?
研究问题3:论文如何调整预先训练过的LM,以参数高效的方式通过多模态邻域信息进行学习?
在传统的具有1对1映射假设的多模态学习中,通常只提供一个邻域(例如,一个用于文本标题的图像)。相反,MMGL需要处理几个具有不同数据大小的邻域(例如,图像分辨率和不同长度的文本序列),这就导致了可伸缩性问题。对于研究问题1,论文研究了三个邻域编码模型:(1)使用文本+嵌入的自注意力(SA-Text+embedding)使用冻结编码器预先计算图像嵌入,然后将它们与来自邻域的原始文本连接到输入的文本序列中,(2)使用嵌入的自注意力(SA-embedding)使用冻结编码器预先计算文本和图像模式的嵌入,并连接到输入文本,(3)使用嵌入的交叉注意(ca-embedding)将预先计算的文本或图像嵌入输入到LM的交叉注意层中。
在研究问题2中,论文研究了如何将多模态邻域之间的图结构信息注入到LM中(例如,图1(b)中的部分层次结构和图像顺序)。论文比较了序列位置编码与图转换器中广泛使用的两种图位置编码:拉普拉斯特征向量位置编码(LPE)和图神经网络编码(GNN),它们在输入之前使用图结构在预先计算的邻域嵌入上运行GNN。
研究问题3试图提高与完全微调LM相比的成本和内存效率。在这项工作中,论文探索了三种参数高效的微调(PEFT)方法:前缀调优,LoRA ,和Flamingo tuning。使用哪些PEFT方法取决于邻域编码模型:当邻域信息被连接到输入序列中(SA-Text+embedding或SA-embedding邻域编码)时,论文可以应用前缀调优或LoRA进行微调。当邻域信息被输入交叉注意层(ca-embedding)时,论文应用Flamingo tuning,只对带有门控模块的交叉注意层进行稳定的微调。
基于论文的MMGL框架,论文在最近发布的多模态数据集WikiWeb2M 上进行了广泛的实验。WikiWeb2M统一了每个维基百科的网页内容,并将所有文本、图像及其结构包含在一个示例中。这使得它对于研究在生成任务中使用多对多文本和图像关系的多模态内容理解非常有用。在这里,论文关注部分摘要任务,该任务的目的是通过理解每个维基百科页面上的多模式内容来生成一个句子来捕获关于一个部分内容的信息。通过对WikiWeb2M的严格测试,论文为MMGL中提出的研究问题提供了直观的实证经验答案。
综上所述,论文的贡献是:
多模态图学习(MMGL):论文引入了一个系统的MMGL框架,用于处理多模态图结构的邻域信息,并使用预先训练的LM生成自由形式的文本。
原则研究问题:论文介绍了MMGL需要回答的三个研究问题: (1)如何向预先训练好的LMs提供多个邻域信息,(2)如何将图结构信息注入到LM中,(3)如何有效地微调LMs=参数。这为未来的MMGL研究铺平了研究方向。
广泛的实证结果:论文表明经验,(1)邻域上下文提高生成性能,(2)SA-Text+embedding邻域编码显示最高的性能而牺牲可伸缩性,(3) GNN嵌入是最有效的图位置编码,和(4)SA-Text+embedding邻域编码LoRA和ca-embedding邻域编码与Flamingo tuning调整显示不同的PEFT模型中最高的性能。
三、针对生成任务的多模态图学习(Multimodal Graph Learning for Generative Tasks)
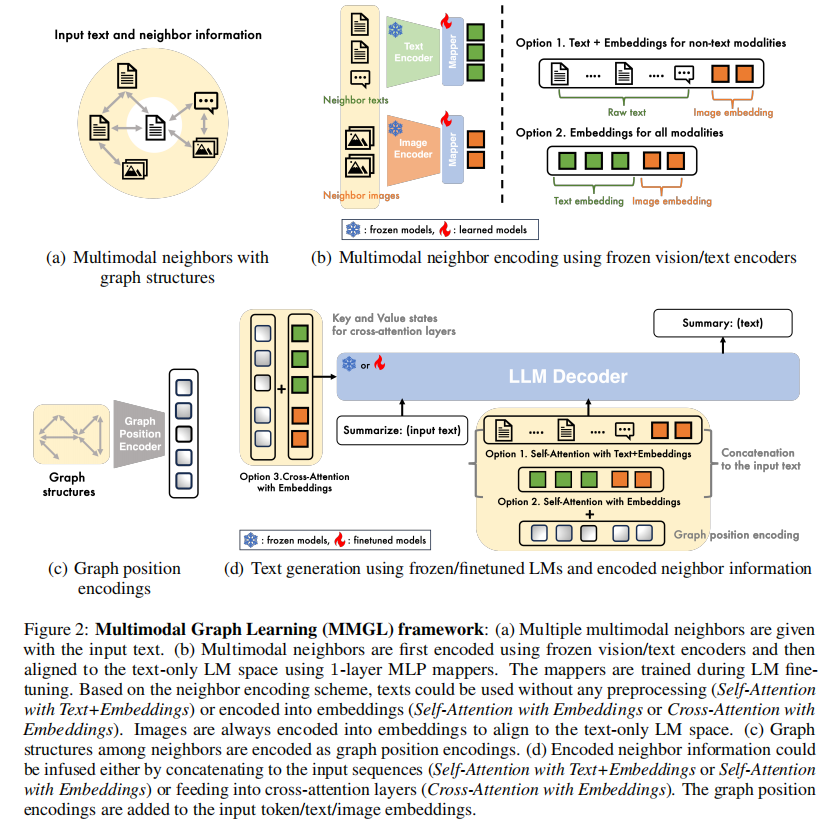
给定每个节点上带有文本或图像的多模态图,论文的目标是生成以每个节点及其相邻节点为条件的文本。更具体地说,给定目标节点上的文本输入,预先训练的LM生成基于输入文本和目标节点周围的多模态上下文的自由形式的文本。在论文的多模态图学习(MMGL)框架中,论文首先使用冻结的编码器分别编码每个邻域的信息(图2(b))。冻结编码器可以是预先训练的ViT或ResNeT,用于将像素映射到嵌入的图像,以及预先训练的LM,用于将文本映射到嵌入的文本(类似于其他模式)。然后,论文使用图位置编码对目标节点周围的图结构进行编码(图2(c))。最后,将带有图位置编码的编码邻域信息输入到经过输入文本的LM中,生成基于多模态输入内容的文本(图2(d))。
该框架给论文留下了三个设计空间: (1)论文如何向LM提供邻域信息?(2)如何将多模态邻域之间的图结构信息注入到LM中?(3)论文如何调整预先训练的LM,以有效地从邻域上下文参数学习?在本节中,论文将研究每个问题,并讨论论文可以应用的可能方法。
3.1研究问题1:邻域编码
与现有的多模态学习假设单个图像(对应于输入文本)作为输入不同,多模态图学习考虑任意数量的邻域图像/文本作为输入;因此,可伸缩性是从多个多模态邻域中学习所需要解决的第一个问题。在视觉-文本模型中,标准的方法是首先使用图像编码器(例如,ViT,ResNet)将图像处理到图像嵌入中,然后将嵌入映射到仅使用文本的LM空间,最后将它们输入到LM中。两种流行的将图像嵌入输入到LM中的方法是对跨序列维度连接的模态的完全自注意或与跨模态注意层。
基于这两种方法,论文提出了以下三种邻域编码方法:
使用文本+嵌入的自注意力(SA-Text+embedding):文本邻域被连接为原始文本,而其他模式首先由冻结的编码器处理(例如,图像的ViT),然后它们的嵌入被连接到输入序列中。论文添加了一个线性映射器,它将预先计算的嵌入对齐到lLM的文本空间中。
使用嵌入的自注意力(SA-embedding):与SA-Text+embedding,除了文本邻域也由单独的冻结编码器处理,它们的嵌入被连接到输入序列。文本编码器可以与基本的LLM模型相同或不同。
使用嵌入的交叉注意(ca-embedding):所有的邻域都由单独的冻结编码器处理,通过线性映射器映射到文本空间,然后输入交叉注意层。
一般来说,当论文提供文本嵌入而不是原始文本时,LLM能够利用的信息量会受到预先计算的嵌入的限制。然而,由于LM的注意机制使用了序列长度为T的O(T 2)计算,因此原始文本引入了可伸缩性问题。因此,在计算成本和可伸缩性之间存在一种权衡。对于SA-Text+embedding和SA-embedding,论文只针对位于LM之外的映射器有额外的参数,而ca-embedding将额外的交叉注意层插入到预先训练的LM中,并从头开始训练它们。这意味着ca-embedding可能会导致一个不稳定的初始状态,因为预先训练好的LLM层会受到随机初始化的交叉注意层的影响。在第4.4节中,论文将探讨这三种方法,并讨论它们的实证结果。
3.2研究问题2:图的结构编码
给定邻域信息,论文可以简单地将邻域信息作为原始文本或嵌入的信息连接起来,并将它们作为一个序列来处理。但邻域之间都有结构。例如,部分具有层次结构,图像包含在WikiWeb2M中的某些部分中(图1(b))。为了在邻域信息中编码这个图结构,论文从图transformer中借用了两种流行的图位置编码,并将它们与顺序位置编码进行了比较。
拉普拉斯位置编码(LPE):论文利用从邻域的图结构中计算出的拉普拉斯特征向量作为它们的位置编码。
图神经网络(GNN):论文首先从冻结的编码器中计算邻域嵌入,并使用图结构在嵌入上运行GNN。然后,论文使用输出的GNN嵌入,它编码图结构信息作为位置编码。
LPE有一个额外的1层MLP映射器来将拉普拉斯特征向量映射到LM的文本空间。用于图结构编码的参数(例如,LPE或GNN参数的映射器)在LM微调过程中以端到端方式进行训练。在第4.5节中,论文将探讨这些不同的位置编码如何将额外的邻域之间的图结构信息带到LM中并提高性能。
3.3研究问题3:参数-效率
虽然论文需要针对特定的任务和新添加的邻域信息对预先训练好的LM模型进行微调,但完全的微调需要较高的计算成本,并且在用户决定使用邻域信息时也给共享MMGL模块带来了不便。近年来,各种参数高效微调(PEFT)方法被提出,以只微调少量的参数,同时保持完整的微调性能。论文选择了适合于论文上面描述的三种邻域编码方法的三种不同的PEFT模型。
前缀调优:当论文选择SA-Text+embedding或SA-embedding作为邻域编码时,除了自注意层,没有任何新添加的参数;因此,论文可以很容易地应用前缀调优,它保持语言模型参数冻结,并优化所有层中原始激活向量的连续任务特定向量序列。
LoRA:与前缀调优一样,低秩自适应(LoRA)也适用于SA-Text+embedding或SA-embedding邻域编码。LoRA将每层注入可训练的秩分解矩阵,同时冻结原始参数。
Flamingo:对于ca-embedding邻域编码,论文可以直接应用Flamingo,它只对新添加的tanh门的交叉注意层进行微调,以保持初始化预训练的LM在初始化时的完整,以提高稳定性和性能。
在第4.6节中,论文将探讨PEFT模型如何通过调优少量参数来保持完整的微调性能。
四、实验
4.1 WikiWeb2M数据集
WikiWeb2M数据集是为对具有多对多文本和图像关系的多模态内容理解的一般研究而构建的。WikiWeb2M建立在WIT数据集的基础上,它包括页面标题、部分标题、部分文本、图像及其标题,以及每个部分的索引、父部分、子部分的索引等等。
在这项工作中,论文专注于部分摘要任务,以生成一个突出显示特定部分内容的单一句子。摘要是根据给定在目标和上下文部分中出现的所有图像和(非摘要)文本生成的。论文从维基web2M中随机抽取600k个维基百科页面,用于部分摘要任务。总的来说,部分总结任务的训练/验证/测试集大小分别为680k/170k/170k。
4.2实验设置
从WikiWeb2M中,论文可以获得四种类型的信息: (1)部分文本,(2)部分图像,(3)页面描述和其他部分的文本,(4)页面描述和其他部分的图像。论文逐步向LM提供信息来研究多模态邻域信息的有效性: (1)部分文本,2)所有部分文本(文本 +图像),3)页面文本(所有来自输入部分所属的维基百科页面),4)所有页面(所有来自维基百科页面的文本和图像)。
论文使用Open pre-trained transformer(OPT-125m)为基本LM读取输入部分文本并生成摘要。对于获取邻域信息的文本和图像编码器,论文使用来自CLIP 的文本/图像编码器。,论文微调了125个批处理大小的10000步的OPT,学习率为10−4。文本/图像编码器在所有实验中都被冻结。论文在验证集上测量了BLEU-4 、ROUGE-L和CIDEr分数。所有实验都运行在4个带有24GB内存的Nvidia-RTX 3090gpu上。
4.3邻域信息的有效性
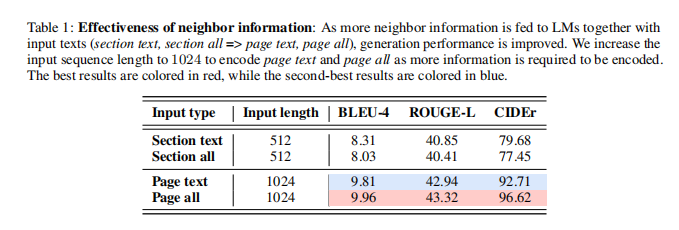
论文首先研究了多模态邻域信息的有效性。如第4.2节所述,论文逐步向基本LM提供更多信息:(1)部分文本、(2)所有部分(文本+图像)、(3)页面文本和4)所有页面(所有文本和图像)。在这里,论文使用自注意力与文本+嵌入(SA-text+embedding)跨不同输入类型的邻域编码。对于图像,论文首先从冻结的CLIP图像编码器中计算图像嵌入,并在每个图像所属的部分的文本之后连接它们,以保持结构。表1中的结果表明,更多的多模态邻域信息是有用的:当从部分内容到页面内容时,性能显著提高,并且根据他们的BLEU-4、ROUGE-L和CIDEr分数添加页面所有内容时,性能进一步提高。
讨论:缺少模式。尽管添加了部分图像,但所有部分的性能都比部分文本略有下降。在维基百科中,并不是每个部分都有相应的图像。因此,在所有部分的情况下,对LM的输入与一些有文本和图像的样本不一致,而其他样本只有文本。这指出了一个重要的未解决的缺失模态问题,这在现实世界中很常见,这在传统的1对1多模态设置中通常不会遇到,强调了开发对缺失模态存在的MMGL方法的重要性。
4.4邻域编码
论文使用三种不同的邻域编码对多个多模态邻域信息进行编码,即使用文本+嵌入的自注意力(SA-TE)、使用嵌入的自注意力(SA-E)和使用嵌入的交叉注意力(CA-E)。SA-E和CA-E使用冻结编码器将所有模式,包括文本编码到嵌入中,而SA-TE则通过连接到输入文本序列,将文本邻域进行编码。因此,SA-TE需要更长的输入序列长度(1024)来编码额外的文本,从而导致潜在的可伸缩性问题。另一方面,SA-E和CA-E需要一个令牌长度来编码一个文本邻域,从而通过更短的输入长度提高了可伸缩性(512)。表2中的结果表明,可伸缩性与性能是权衡的:在不同输入类型时,SA-TE的性能始终优于SA-E和CA-E,但输入长度更长。
讨论:信息丢失。在传统的具有1-1映射的多模态学习中,SA-TE通常用于注入文本输入,而作为嵌入的图像输入是由冻结编码器预先计算的。这些方法成功地生成了基于输入图像的文本,显示了图像嵌入作为预训练的LM的输入的有效性。
然而,表2中SA-TE和SA-E之间的性能差距表明,文本嵌入可能导致LM中的信息丢失。这可能是因为1层MLP映射器将预先计算的文本嵌入到文本空间的LM不够表达,或者因为长输入文本比短文本用于传统的多模式学习(例如,一句话标题)使LM很难从预先计算的文本嵌入。从实际的角度来看,论文的结果阐明了可伸缩性和性能之间的权衡。同时,论文的研究结果强调了需要更多的MMGL研究来解决在使用嵌入来捕获文本信息时信息丢失的挑战性问题。

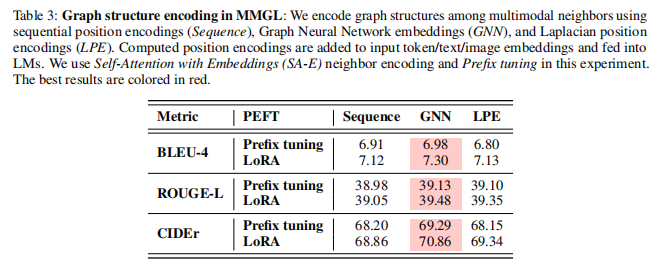
4.5图结构编码
除了邻域上的每个模态外,多模态图还包含邻域之间的图结构信息。论文使用顺序位置编码(序列)、图神经网络嵌入(GNN)和拉普拉斯位置编码(LPE)对多模态邻域之间的图结构进行编码。计算出的位置编码首先通过1层MLP映射到LMs的文本空间,添加到输入标记/文本/图像嵌入中,并输入到LMs中。在表3中,GNN嵌入显示的性能最好。特别是对序列位置编码的改进表明了图感知结构编码方法在MMGL中的重要性。
4.6参数高效的微调
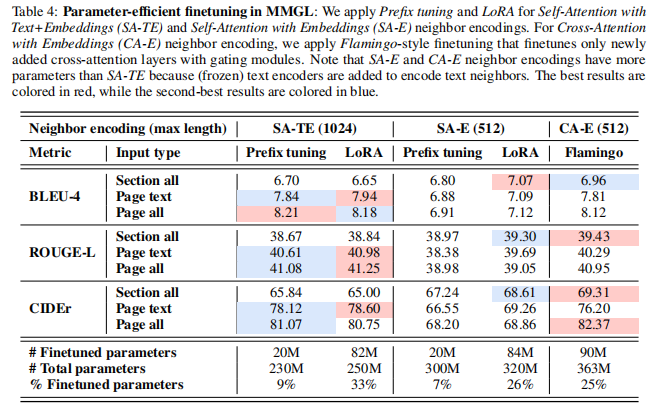
对预先训练好的LM进行完全微调需要很高的计算成本。为了实现MMGL进行参数高效微调,论文研究了文本+嵌入(SA-TE)和嵌入自注意(SA-E)邻域编码的前缀调优和LoRA。对于嵌入交叉注意(CA-E)邻域编码,论文采用flamingo风格的微调,只添加带门模块的交叉注意层。
表4中的结果显示,对于具有更多微调参数的SA-TE和SA-E邻域编码,LoRA调优(前缀调优为7−9%,LoRA为26−33%)。然而,前缀调优仍然显示了与使用SA-TE邻域编码使用近4倍少的参数的LoRA相当的性能。CA-E邻域编码的Flamingo与LoRA相似的性能(LoRA为82M,90M)。请注意,SA-E和CA-E邻域编码比SA-TE有更多的参数,这是由于包含了用于文本邻域处理的(冻结)文本编码器。
在表2(没有PEFT)中,CA-E邻域编码比SA-TE邻域编码的性能明显滞后。然而,当注入Flamingo时,Flamingo中的门控模块有效地确保了预训练的LM在初始化时不受随机设置的交叉注意层的影响,从而提高了CA-E的性能,如表4(与PEFT)所示。这强调了战略初始化在MMGL中引入邻域编码的补充模块以及将它们集成到预先训练的LM中时,战略初始化的关键作用。
五、总结
在这项工作中,论文将传统的多模态学习与一对模态之间的一对一映射扩展到多个模态之间的多对多关系的多模态图学习(MMGL)。论文的MMGL框架围绕三个关键组件系统结构: (1)邻域编码,(2)图结构编码和(3)参数高效的微调。通过对WikiWeb2M数据集的严格测试,论文探索了每个组件的不同选项: (1)邻域编码、使用文本+嵌入的自注意力(SA-Text+embedding)使用嵌入的自注意力(SA-embedding)和使用嵌入的交叉注意(ca-embedding),强调可伸缩性和性能之间的平衡,(2)三个不同的图位置编码,序列,LPE和GNN,(3)三个PEFT模型,前缀调优、LoRA和Flamingo,以及它们在参数效率和性能之间的权衡。论文的深入分析和发现旨在为未来的MMGL研究奠定基础,引发在该领域的进一步探索。


