
- 1android.app.RemoteServiceException can‘t deliver broadcast 异常定位&解决方案_can't deliver broadcast
- 2VLAN帧格式_vlan帧中的tpid
- 3JVM探究_jprofile反编译
- 4【附源码】计算机毕业设计java英语单词记忆系统设计与实现_英语单词在线背诵系统毕业设计
- 5如何安装下载激活MathType?2024最新免费MathType许可证_mathtype免费安装
- 6解决更新Xcode 15.2后,下载 iOS_17 Simulator失败_ios_17.2_simulator_runtime.dmg
- 7【系统分析师之路】第十九章 复盘知识产权标准化_孙某在书店租到一张带有注册商标的应用软件光盘,擅自复制后在网络进行传播,其行为
- 8hellocharts-android图表库使用详解_com.github.lecho:hellocharts设置网格
- 9输入两个整数,输出由输入的两个整数组合而成的四位整数_1输出两个两位数:2可以通过键盘3生成新的四位数ab cdacbd4判断是否是两个正整
- 10linux文件操作——基于unix标准库函数(open、read、write函数等)_open是linux标准库函数吗
西储大学轴承监测数据集及数据集分类_西储大学轴承数据集
赞
踩
1.数据集简介
振动数据来源于美国凯斯西储大学的开发数据集。轴承试验装置的示意图如图1-1所示。平台组成:
一个1.5KW(2马力)的电动机(图左侧);
一个扭矩传感器/ 译码器(图中间连接处);
一个功率测试计(图右侧);
驱动端轴承为SKF6205 ,采样频率为12Khz和48Khz;
电子控制器(图中没显示) 。

DE - drive end accelerometer data 驱动端加速度数据;
FE - fan end accelerometer data 风扇端加速度数据;
BA - base accelerometer data 基座加速度数据(正常);
time - time series data 时间序列数据;
RPM- rpm during testing 转每分钟,除以60为旋转频率;
B -滚动体故障;IR – 内圈故障;OR –外圈故障;
驱动端和风扇端轴承外圈的损伤点分别放置在3点钟、6点钟、12点钟三个不同位置。
数据文件为Matlab格式。每个文件包含风扇和驱动端振动数据,以及电机转速。
例子:12k_Fan_End_OR007@6_3_297.mat
12k:12KHZ采样频率
Fan_End_OR:风扇端外圈故障
007:直径
@6:外圈的损伤点在6点钟位置
3:表电机载荷模式
297:编号。
数据集由
12kHz采样率下电机端轴承的故障数据(DE)60个、
12kHz采样率下风扇端轴承的故障数据(FE)45个、
48kHz采样率下电机端轴承的故障数据(DE)52个,
还有正常运转的轴承数据4个组成。
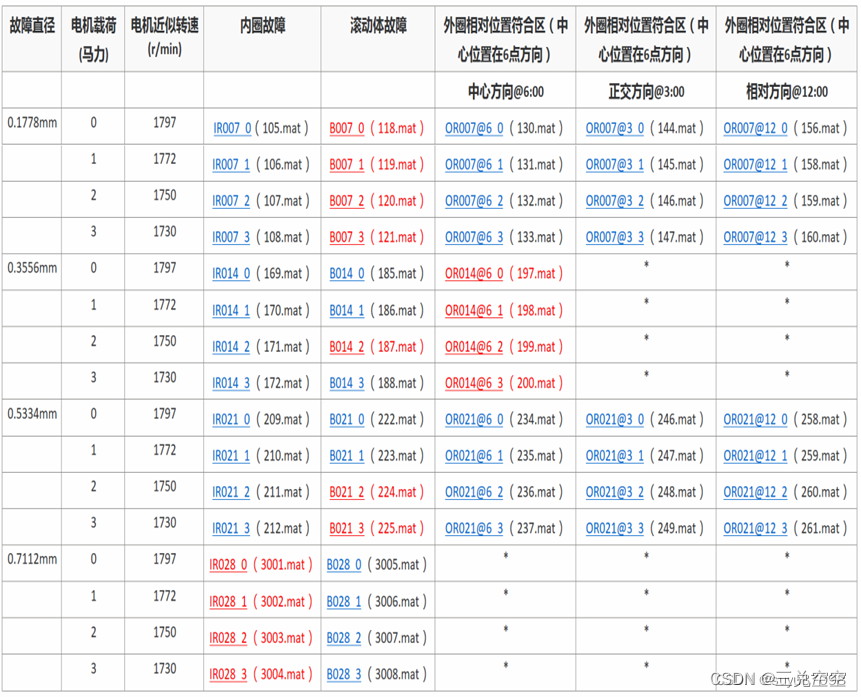
图1-2 12k驱动端故障数据列表
3.python 训练及验证数据集制作代码.
- from scipy.io import loadmat
- import numpy as np
- import os
- from sklearn import preprocessing # 0-1编码
- from sklearn.model_selection import StratifiedShuffleSplit # 随机划分,保证每一类比例相同
-
-
- def prepro(d_path, length=864, number=1000, normal=True, rate=[0.5, 0.25, 0.25], enc=True, enc_step=28):
- """对数据进行预处理,返回train_X, train_Y, valid_X, valid_Y, test_X, test_Y样本.
- :param d_path: 源数据地址
- :param length: 信号长度,默认2个信号周期,864
- :param number: 每种信号个数,总共10类,默认每个类别1000个数据
- :param normal: 是否标准化.True,Fales.默认True
- :param rate: 训练集/验证集/测试集比例.默认[0.5,0.25,0.25],相加要等于1
- :param enc: 训练集、验证集是否采用数据增强.Bool,默认True
- :param enc_step: 增强数据集采样顺延间隔
- :return: Train_X, Train_Y, Valid_X, Valid_Y, Test_X, Test_Y
- ```
- import preprocess.preprocess_nonoise as pre
- train_X, train_Y, valid_X, valid_Y, test_X, test_Y = pre.prepro(d_path=path,
- length=864,
- number=1000,
- normal=False,
- rate=[0.5, 0.25, 0.25],
- enc=True,
- enc_step=28)
- ```
- """
- # 获得该文件夹下所有.mat文件名
- filenames = os.listdir(d_path)
-
- def capture(original_path):
- """读取mat文件,返回字典
- :param original_path: 读取路径
- :return: 数据字典
- """
- files = {}
- for i in filenames:
- # 文件路径
- file_path = os.path.join(d_path, i)
- file = loadmat(file_path)
- file_keys = file.keys()
- for key in file_keys:
- if 'DE' in key:
- files[i] = file[key].ravel()
- return files
-
- def slice_enc(data, slice_rate=rate[1] + rate[2]):
- """将数据切分为前面多少比例,后面多少比例.
- :param data: 单挑数据
- :param slice_rate: 验证集以及测试集所占的比例
- :return: 切分好的数据
- """
- keys = data.keys()
- Train_Samples = {}
- Test_Samples = {}
- for i in keys:
- slice_data = data[i]
- all_lenght = len(slice_data)
- end_index = int(all_lenght * (1 - slice_rate))
- samp_train = int(number * (1 - slice_rate)) # 700
- Train_sample = []
- Test_Sample = []
- if enc:
- enc_time = length // enc_step
- samp_step = 0 # 用来计数Train采样次数
- for j in range(samp_train):
- random_start = np.random.randint(low=0, high=(end_index - 2 * length))
- label = 0
- for h in range(enc_time):
- samp_step += 1
- random_start += enc_step
- sample = slice_data[random_start: random_start + length]
- Train_sample.append(sample)
- if samp_step == samp_train:
- label = 1
- break
- if label:
- break
- else:
- for j in range(samp_train):
- random_start = np.random.randint(low=0, high=(end_index - length))
- sample = slice_data[random_start:random_start + length]
- Train_sample.append(sample)
-
- # 抓取测试数据
- for h in range(number - samp_train):
- random_start = np.random.randint(low=end_index, high=(all_lenght - length))
- sample = slice_data[random_start:random_start + length]
- Test_Sample.append(sample)
- Train_Samples[i] = Train_sample
- Test_Samples[i] = Test_Sample
- return Train_Samples, Test_Samples
-
- # 仅抽样完成,打标签
- def add_labels(train_test):
- X = []
- Y = []
- label = 0
- for i in filenames:
- x = train_test[i]
- X += x
- lenx = len(x)
- Y += [label] * lenx
- label += 1
- return X, Y
-
- # one-hot编码
- def one_hot(Train_Y, Test_Y):
- Train_Y = np.array(Train_Y).reshape([-1, 1])
- Test_Y = np.array(Test_Y).reshape([-1, 1])
- Encoder = preprocessing.OneHotEncoder()
- Encoder.fit(Train_Y)
- Train_Y = Encoder.transform(Train_Y).toarray()
- Test_Y = Encoder.transform(Test_Y).toarray()
- Train_Y = np.asarray(Train_Y, dtype=np.int32)
- Test_Y = np.asarray(Test_Y, dtype=np.int32)
- return Train_Y, Test_Y
-
- def scalar_stand(Train_X, Test_X):
- # 用训练集标准差标准化训练集以及测试集
- scalar = preprocessing.StandardScaler().fit(Train_X)
- Train_X = scalar.transform(Train_X)
- Test_X = scalar.transform(Test_X)
- return Train_X, Test_X
-
- def valid_test_slice(Test_X, Test_Y):
- test_size = rate[2] / (rate[1] + rate[2])
- ss = StratifiedShuffleSplit(n_splits=1, test_size=test_size)
- for train_index, test_index in ss.split(Test_X, Test_Y):
- X_valid, X_test = Test_X[train_index], Test_X[test_index]
- Y_valid, Y_test = Test_Y[train_index], Test_Y[test_index]
- return X_valid, Y_valid, X_test, Y_test
-
- # 从所有.mat文件中读取出数据的字典
- data = capture(original_path=d_path)
- # 将数据切分为训练集、测试集
- train, test = slice_enc(data)
- # 为训练集制作标签,返回X,Y
- Train_X, Train_Y = add_labels(train)
- # 为测试集制作标签,返回X,Y
- Test_X, Test_Y = add_labels(test)
- # 为训练集Y/测试集One-hot标签
- Train_Y, Test_Y = one_hot(Train_Y, Test_Y)
- # 训练数据/测试数据 是否标准化.
- if normal:
- Train_X, Test_X = scalar_stand(Train_X, Test_X)
- else:
- # 需要做一个数据转换,转换成np格式.
- Train_X = np.asarray(Train_X)
- Test_X = np.asarray(Test_X)
- # 将测试集切分为验证集合和测试集.
- Valid_X, Valid_Y, Test_X, Test_Y = valid_test_slice(Test_X, Test_Y)
- return Train_X, Train_Y, Valid_X, Valid_Y, Test_X, Test_Y
-
-
- if __name__ == "__main__":
- path = r'D:\360安全浏览器下载\轴承故障检测\数据源\西储大学\CWRU轴承数据\cwru_data\0'
- train_X, train_Y, valid_X, valid_Y, test_X, test_Y = prepro(d_path=path,
- length=864,
- number=1000,
- normal=False,
- rate=[0.5, 0.25, 0.25],
- enc=False,
- enc_step=28)


