
热门标签
热门文章
- 1Qt QLCDNumber 13行实现 显示日期时间 颜色设置 刷新_qlcdnumber设置字体大小
- 2用Vmware创建并运行Ubuntu64虚拟机,安装配置跳坑记录
- 3大数据时代下,需要什么样的冷存储?
- 4助力精准可信时空智能:卫星授时安全隔离装置_卫时空
- 5MIPS 指令译码器设计_mips指令译码器设计
- 62000+java毕业设计实例,包含代码论文,软件工程专业必看
- 7vue项目中对axios进行二次封装_vue3 axios二次封装
- 8微信小程序脚手架
- 9Pycharm服务器配置与内网穿透工具结合实现远程开发的解决方法_pycorrector 内网接口使用
- 10高性能计算的线程模型:Pthreads 还是 OpenMP_相同条件下openmp加速效果比pthreads好
当前位置: article > 正文
【Preprocessing数据预处理】之Scaler
作者:菜鸟追梦旅行 | 2024-03-13 07:49:46
赞
踩
【Preprocessing数据预处理】之Scaler
在机器学习中,特征缩放是训练模型前数据预处理阶段的一个关键步骤。不同的缩放器被用来规范化或标准化特征。这里简要概述了您提到的几种缩放器:
StandardScaler
`StandardScaler` 通过去除均值并缩放至单位方差来标准化特征。这种缩放器假设特征分布是正态的,并将它们缩放为均值为零和标准差为一。用于缩放特征 `X` 的公式是:

其中 `μ` 是特征值的平均值,`σ` 是标准差。
MinMaxScaler
`MinMaxScaler` 将特征缩放到给定范围,通常在零和一之间,或者使最小和最大值与某个特定范围对齐。转换公式为:

其中 `X_min` 和 `X_max` 分别是特征的最小值和最大值。这种缩放将所有内点压缩到 [0, 1] 范围内。
RobustScaler
`RobustScaler` 使用类似于 `StandardScaler` 的方法,但它使用中位数和四分位数范围而不是均值和方差。这使得 `RobustScaler` 对异常值的敏感度较低。公式是:
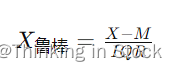
其中 `M` 是中位数,`IQR` 是特征值的四分位数范围。
何时使用每种缩放器:
- **StandardScaler**:当您的特征大致呈正态分布,并且您希望假设您的特征具有高斯分布时。
- **MinMaxScaler**:当您知道特征的边界并希望将特征转换为在这些边界之间缩放时。
- **RobustScaler**:当您的特征中有异常值并希望减少其影响时。
需要注意的是,特征缩放可能会影响您的机器学习模型的性能,特别是对于那些计算数据点之间距离的算法,比如 SVM 或 k-NN,或者那些对特征缩放敏感的基于梯度下降的算法。对于基于树的算法,特征缩放则不那么重要,因为它们是尺度不变的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/228493
推荐阅读
相关标签

