- 1机器学习算法的业务应用实践
- 2Java 环境变量及其配置_java 配置环境变量
- 3鸿蒙应用开发培训笔记05:线程管理和数据管理_鸿蒙worker线程最大激活数
- 4点击按钮一次之后禁用按钮_deveco studio如何点一次禁用按钮
- 5滑动窗口计数java实现
- 6 sklearn MLP(多层感知机、Multi-layer Perceptron)模型使用RandomSearchCV获取最优参数及可视化_sklearn多层感知机模型超参数优化
- 7oracle-分组统计查询和子查询_oracle 一张表 获取每个分类下的所有数据,并统计总数
- 8冯·米塞斯分布
- 9C++开发基础——可变参数与可变参数模板
- 10linux下进程总结_linux不同进程的结果如何汇总
RocketMQ 迈入50万TPS消息俱乐部的优化工作_rocketmq tps多少
赞
踩
前言
消息团队一直致力于RocketMQ的性能优化,双十一前进行了低延时(毛刺)优化,保障了双十一万亿消息的流转如丝般顺滑,在2016年双十一种,MetaQ以接近万亿的消息总量支撑着全集团数千个应用,在系统解耦、削峰填谷、数据库同步、位点回滚消费等多种业务场景中,MetaQ都有精彩、稳定的表现。高可用低延迟,高并发抗堆积,2016双11的MetaQ真正做到了如丝般顺滑。
而最近通过对性能的持续优化,在RocketMQ最新的中小消息TPS已达47万,本人在F43机型上自测时TPS峰值为57万TPS,所以取了这么一个标题。
RocketMQ高性能优化探索
本章节简单介绍下在优化RocketMQ过程中用到的方法和技巧。部分方法在消息领域提升不明显却带来了编码和运维的复杂度,这类方法虽然最终没有利用起来,也在下面做了介绍供大家参考。
Java篇
在接触到内核层面的性能优化之前,Java层面的优化需要先做起来。有时候灵机一动的优化方法需要实现Java程序来进行测试,注意测试的时候需要在排除其他干扰的同时充分利用JVM的预热(JIT)特性。推荐使OpenJDK开发的基准测试(Benchmark)工具JMH。
JVM停顿
影响Java应用性能的头号大敌便是JVM停顿,说起停顿,大家耳熟能详的便是GC阶段的STW(Stop the World),除了GC,还有很多其他原因,如下图所示。

当怀疑我们的Java应用受停顿影响较大时,首先需要找出停顿的类型,下面一组JVM参数可以输出详细的安全点信息:
-XX:+LogVMOutput -XX:LogFile=/dev/shm/vm.log -XX:+PrintGCApplicationStoppedTime -XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1 -XX:+PrintGCApplicationConcurrentTime |
在RocketMQ的性能测试中,发现存在大量的RevokeBias停顿,偏向锁主要是消除无竞争情况下的同步原语以提高性能,但考虑到RocketMQ中该场景比较少,便通过-XX:-UseBiasedLocking关闭了偏向锁特性。
停顿有时候会让我们的StopWatch变得很不精确,有一段时间经常被StopWatch误导,观察到一段代码耗时异常,结果花时间去优化也没效果,其实不是这段代码耗时,只是在执行这段代码时发生了停顿。停顿和动态编译往往是性能测试的两大陷阱。
GC
GC将Java程序员从内存管理中解救了出来,但也对开发低延时的Java应用带来了更多的挑战。对GC的优化个人认为是一项调整参数的工作,垃圾收集方面最值得关注的两个性能属性为吞吐量和延迟,对GC进行优化往往是寻求吞吐量和延迟上的折衷,没办法鱼和熊掌兼得。
RocketMQ通过GC调优后最终采取的GC参数如下所示,供大家参考。
-server -Xms8g -Xmx8g -Xmn4g -XX:+UseG1GC -XX:G1HeapRegionSize=16m -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:SurvivorRatio=8 -XX:+DisableExplicitGC -verbose:gc -Xloggc:/dev/shm/mq_gc_%p.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintAdaptiveSizePolicy -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=30m |
可以看出,我们最终全部切换到了G1,16年双十一线上MetaQ集群采用的也是这一组参数,基本上GC时间能控制在20ms以内(一些超大的共享集群除外)。
对于G1,官方推荐使用该-XX:MaxGCPauseMillis设置目标暂停时间,不要手动指定-Xmn和-XX:NewRatio,但我们在实测中发现,如果指定过小的目标停顿时间(10ms),G1会将新生代调整为很小,导致YGC更加频繁,老年代用得更快,所有还是手动指定了-Xmn为4g,在GC频率不高的情况下完成了10ms的目标停顿时间,这里也说明有时候一些通用的调优经验并不适用于所有的产品场景,需要更多的测试才能找到最合适的调优方法,往往需要另辟蹊径。
同时也分享下我们在使用CMS时遇到的一个坑,-XX:UseConcMarkSweepGC在使用CMS收集器的同时默认在新生代使用ParNew, ParNew并行收集垃圾使用的线程数默认值更机器cpu数(<8时)或者8+(ncpus-8)*5/8,大量垃圾收集线程同时运行会带来大量的停顿导致毛刺,可以使用-XX:ParallelGCThreads指定并行线程数。
还有避免使用finalize()方法来进行资源回收,除了不靠谱以为,会加重GC的压力,原因就不赘述了。
另外,我们也尝试了Azul公司的商业虚拟机Zing,Zing采用了C4垃圾收集器,但Zing的长处在于GC的停顿时间不随堆的增长而变长,特别适合于超大堆的应用场景,但RocketMQ使用的堆其实较小,大多数的内存需要留给PageCache,所以没有采用Zing。我这里有一份MetaQ在Zing下的测试报告,感兴趣的可以联系我,性能确实不错。
线程池
Java应用里面总会有各式各样的线程池,运用线程池最需要考虑的两个因素便是:
- 线程池的个数,避免设置过多或过少的线程池数,过少会导致CPU资源利用率不够吞吐量低,过多的线程池会带来更多的同步原语、上下文切换、调度等方面的性能损失。
- 线程池的划分,需要根据具体的业务或者模块做详细的规划,线程池往往也起到了资源隔离的作用,RocketMQ中曾有一个重要模块和一个非重要模块共享一个线程池,在去年双十一的压测中,非重要模块因压力大占据了大部分的线程池资源,导致重要模块的业务发生饥饿,最终导致了无法恢复的密集FGC。
关于线程池个数的设置,可以参考《Java Concurrency in Practice》一书中的介绍:

需要注意的是,增加线程数并非提升性能的万能药,且不说多线程带来的额外性能损耗,大多数业务本质上都是串行的,由一系列并行工作和串行工作组合而成,我们需要对其进行合适的切分,找出潜在的并行能力。并发是不能突破串行的限制,需遵循Amdahl 定律。
如果线程数设置不合理或者线程池划分不合理,可能会观察到虚假竞争,CPU资源利用不高的同时业务吞吐量也上不去。这种情况也很难通过性能分析工具找出瓶颈,需要对线程模型仔细分析,找出不合理和短板的地方。
事实上,对RocketMQ现存的线程模型进行梳理后,发现了一些不合理的线程数设置,通过对其调优,带来的性能提升非常可观。
CPU篇
CPU方面的调优尝试,主要在于亲和性和NUMA。
CPU亲和性
CPU亲和性是一种调度属性,可以将一个线程”绑定” 到某个CPU上,避免其在处理器之间频繁迁移。有一篇IBM的技术文章介绍得比较详细,可供参考。
同时,有一个开源的Java库可以支持在Java语言层面调用API完成CPU亲和性绑定。参见Java-Thread-Affinity。该库给出了Thread如何绑定CPU,如果需要对线程池里面的线程进行CPU绑定,可以自定义ThreadFactory来完成。
我们通过对RocketMQ中核心线程进行CPU绑定发现效果不明显,考虑到会引入第三方库便放弃了此方法。推测效果不明显的原因是我们在核心链路上已经使用了无锁编程,避免上下文切换带来的毛刺现象。
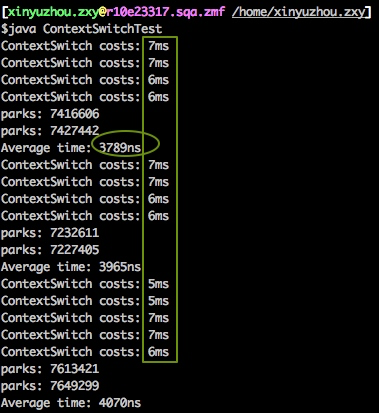
上下文切换确实是比较耗时的,同时也具有毛刺现象,下图是我们通过LockSupport.unpark/park来模拟上下文切换的测试,可以看出切换平均耗时是微妙级,但偶尔也会出现毫秒级的毛刺。
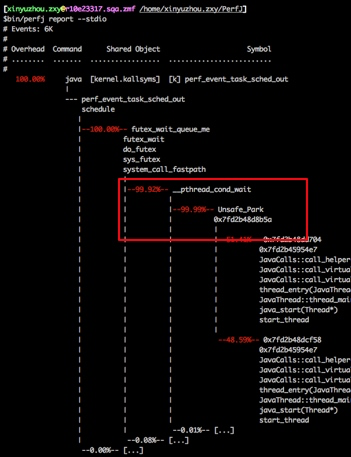
通过Perf也观察到unpark/park也确实能产生上下文切换。
此外有一个内核配置项isolcpus,可以将一组CPU在系统中孤立出来,默认是不会被使用的,该参数在GRUB中配置重启即可。CPU被隔离出来后可以通过CPU亲和性绑定或者taskset/numactl来分配任务到这些CPU以达到最优性能的效果。
NUMA
对于NUMA,大家的态度是褒贬不一,在数据库的场景忠告一般是关掉NUMA,但通过了解了NUMA的原理,觉得理论上NUMA对RocketMQ的性能提升是有帮助的。
前文提到了并发的调优是不能突破Amdahl 定律的,总会有串行的部分形成短板,对于CPU来讲也是同样的道理。随着CPU的核数越来越多,但CPU的利用率却越来越低,在64核的物理机上,RocketMQ只能跑到2500%左右。这是因为,所有的CPU都需要通过北桥来读取内存,对于CPU来说内存是共享的,这里的内存访问便是短板所在。为了解决这个短板,NUMA架构的CPU应运而生。
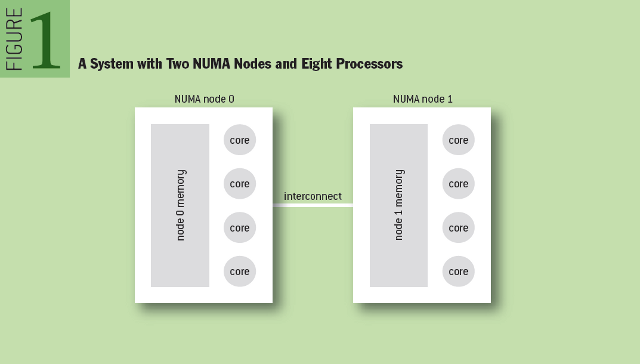
如下图所示,是两个NUMA节点的架构图,每个NUMA节点有自己的本地内存,整个系统的内存分布在NUMA节点的内部,某NUMA节点访问本地内存的速度(Local Access)比访问其它节点内存的速度(Remote Access)快三倍<忘记该数据的出处了⊙▽⊙>。
RocketMQ通过在NUMA架构上的测试发现有20%的性能提升,还是比较可观的。特别是线上物理机大都支持NUMA架构,对于两个节点的双路CPU,可以考虑按NUMA的物理划分虚拟出两个Docker进行RocketMQ部署,最大化机器的性能价值。
感兴趣的同学可以测试下NUMA对自家应用的性能影响,集团机器都从BIOS层面关闭了NUMA,如果需要测试,按如下步骤打开NUMA即可:
-
打开BIOS开关:
打开方式跟服务器相关。
-
在GRUB中配置开启NUMA
vi /boot/grub/grub.conf 添加boot参数:numa=on
-
重启
-
查看numa node个数
numactl --hardware 如果看到了>1个节点,即为支持NUMA
内存篇
可以将Linux内存分为以下三类:

《如丝般顺滑—METAQ2016双11总结》一文中比较详细地介绍了访存过程中需要注意的地方,同时给出了消除访问匿名内存和PageCache的方法。本章节介绍一些其它需要注意的地方。
页错误
我们知道,为了使用更多的内存地址空间切更加有效地管理存储器,操作系统提供了一种对主存的抽象概念——虚拟存储器(VM),有了虚拟存储器,就必然需要有从虚拟到物理的寻址。进程在分配内存时,实际上是通过VM系统分配了一系列虚拟页,此时并未涉及到真正的物理页的分配。当进程真正地开始访问虚拟内存时,如果没有对应的物理页则会触发缺页异常,然后调用内核中的缺页异常处理程序进行的内存回收和分配。
页错误分为两种:
- Major Fault, 当需要访问的内存被swap到磁盘上了,这个时候首先需要分配一块内存,然后进行disk io将磁盘上的内容读回道内存中,这是一系列代价比较昂贵的操作。
- Minor Fault, 常见的页错误,只涉及页分配。
为了提高访存的高效性,需要观察进程的页错误信息,以下命令都可以达到该目的:
1. ps -o min_flt,maj_flt <PID> 2. sar -B |
如果观察到Major Fault比较高,首先要确认系统参数vm.swappiness是否设置恰当,建议在机器内存充足的情况下,设置一个较小的值(0或者1),来告诉内核尽可能地不要利用磁盘上的swap区域,0和1的选择原则如下:

切记不要在2.6.32以后设置为0,这样会导致内核关闭swap特性,内存不足时不惜OOM也不会发生swap,前端时间也碰到过因swap设置不当导致的故障。
另一方面,避免触发页错误,内存频繁的换入换出,还有以下手段可以采用:
- -XX:+AlwaysPreTouch,顾名思义,该参数为让JVM启动时将所有的内存访问一遍,达到启动后所有内存到位的目的,避免页错误。
- 对于我们自行分配的堆外内存,或者mmap从文件映射的内存,我们可以自行对内存进行预热,有以下四种预热手段,第一种不可取,后两种是最快的。
-
即使对内存进行了预热,当内存不够时,后续还是会有一定的概率被换出,如果希望某一段内存一直常驻,可以通过mlock/mlockall系统调用来将内存锁住,推荐使用JNA来调用这两个接口。不过需要注意的是内核一般不允许锁定大量的内存,可通过以下命令来增加可锁定内存的上限。
echo '* hard memlock unlimited' >> /etc/security/limits.conf echo '* soft memlock unlimited' >> /etc/security/limits.conf

Huge Page
大家都知道,操作系统的内存4k为一页,前文说到Linux有虚拟存储器,那么必然需要有页表(Page Table)来存储物理页和虚拟页之间的映射关系,CPU访问存时首先查找页表来找到物理页,然后进行访存,为了提高寻址的速度,CPU里有一块高速缓存名为ranslation Lookaside Buffer (TLB),包含部分的页表信息,用于快速实现虚拟地址到物理地址的转换。
但TLB大小是固定的,只能存下小部分页表信息,对于超大页表的加速效果一般,对于4K内存页,如果分配了10GB的内存,那么页表会有两百多万个Entry,TLB是远远放不下这么多Entry的。可通过cpuid查询TLB Entry的个数,4K的Entry一般仅有上千个,加速效果有限。
为了提高TLB的命中率,大多数CPU支持大页,大页分为2MB和1GB,1GB大页是超大内存的不二选择,可通过grep pdpe1gb /proc/cpuinfo | uniq查看CPU是否支持1GB的大页。
开启大页需要配置内核启动参数,hugepagesz=1GB hugepages=10,设置大页数量可通过内核启动参数hugepages或者/proc/sys/vm/nr_hugepages进行设置。
内核开启大页过后,Java应用程序使用大页有以下方法:
- 对于堆内存,有JVM参数可以用:-XX:+UseLargePages
- 如果需要堆外内存,可以通过mount挂载hugetlbfs,
mount -t hugetlbfs hugetlbfs /hugepages,然后通过mmap分配大页内存。
可以看出使用大页比较繁琐的,Linux提供透明超大页面 (THP)。THP 是可自动创建、管理和使用超大页面。可通过修改文件/sys/kernel/mm/transparent_hugepage/enabled来关闭或者打开THP。
但大页有一个弊端,如果内存压力大,需要换出时,大页会先拆分成小页进行换出,需要换入时再合并为大页,该过程会加重CPU的压力。LinkedIn有位工程师有一个比较有趣的尝试,在内存压力小的时候启用THP,在内存压力大的时候关闭THP,通过这种动态调整达到最优性能,可以看看他的论文:Ensuring High-performance of Mission-critical Java Applications in Multi-tenant Cloud Platforms。
网卡篇
网卡性能诊断工具是比较多的,有ethtool, ip, dropwatch, netstat等,RocketMQ尝试了网卡中断和中断聚合两方面的优化手段。
网卡中断
这方面的优化首先便是要考虑是否需要关闭irqbalance,它用于优化中断分配,通过自动收集系统数据来进行中断负载,同时还会综合考虑节能等因素。但irqbalance有个缺点是会导致中断自动漂移,造成不稳定的现象,在高性能的场合建议关闭。
关闭irqbalance后,需要对网卡的所有队列进行CPU绑定,目前的网卡都是由多队列组成,如果所有队列的中断仅有一个CPU进行处理,难以利用多核的优势,所以可以对这些网卡队列进行CPU一一绑定。
这部分优化对RocketMQ的小消息性能提升有很大的帮助。
中断聚合
中断聚合的思想类似于Group Commit,避免每一帧的到来都触发一次中断,RocketMQ在跑到最大性能时,每秒会触发近20000次的中断,如果可以聚合一部分,对性能还是有一定的提升的。
可以通过ethtool设置网卡的rx-frames-irq和rx-usecs参数来决定凑齐多少帧或者多少时间过后才触发一次中断,需要注意的是中断聚合会带来一定的延迟。
总结
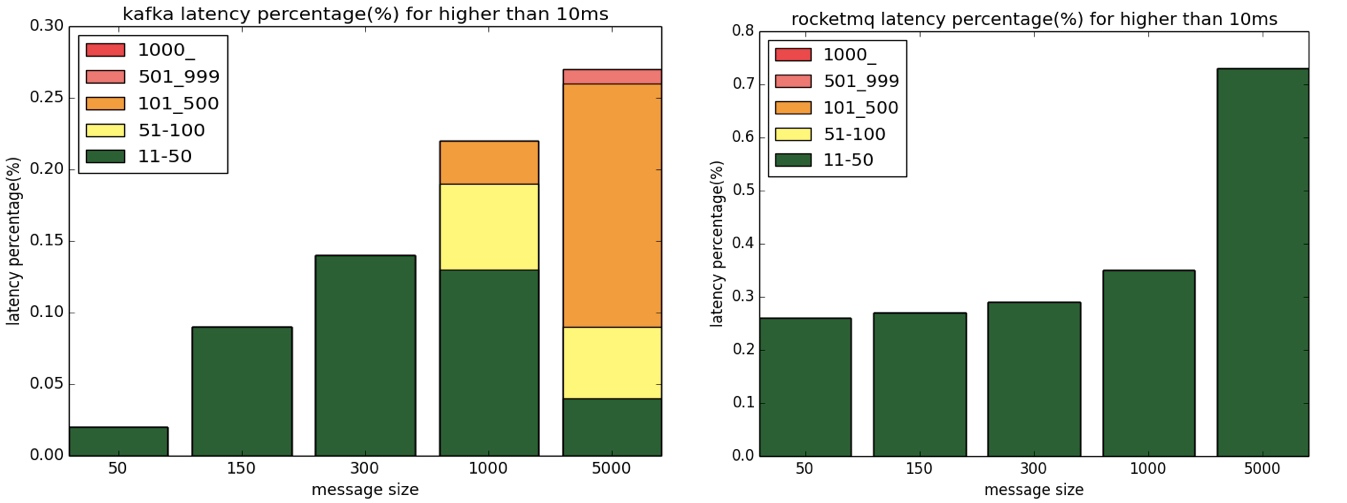
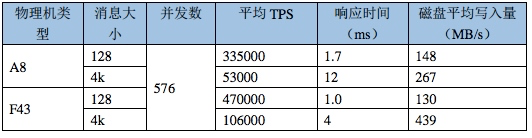
目前RocketMQ最新的性能基准测试中,128字节小消息TPS已达47W,如下图所示:
高性能的RocketMQ可应用于更多的场景,能接管和替代Kafka更多的生态,同时可以更大程度上承受热点问题,在保持高性能的同时,RocketMQ在低延迟方面依然具有领先地位,如下图所示,RocketMQ仅有少量10~50ms的毛刺延迟,Kafka则有不少500~1s的毛刺。