
- 1Appium环境搭建(windows10系统)_windows10 安装appium
- 2理解NLP迁移学习/Transformers/GPT/Bert中遇到的难点和笔记_迁移学习 transformer
- 3HarmonyOS鸿蒙学习基础篇 - 项目目录和文件介绍_鸿蒙项目目录
- 4http请求常见的status状态码_status常见错误
- 5【UE4学习】04——官方教程代码_ue4 某校不良生
- 6散点图绘制三维曲面_PCA、RDA等排序图的一些三维可视化示例
- 7数学建模之灰色关联分析(GRA)_灰色关联分析法
- 8Windows 环境下,cmake工程导入OpenCV库_opencvconfig.cmake
- 9Compose的附加效应(十四)_compose remember 和 rememberupdatedstate
- 10基于微信小程序求职招聘系统设计与实现 毕业设计论文大纲提纲参考
Libcomm通信库:GaussDB(DWS) 为解决建联过多的小妙招
赞
踩
本文分享自华为云社区《GaussDB(DWS) 集群通信系列三:Libcomm通信库》,作者: 半岛里有个小铁盒。
1.前言
适用版本:【8.1.0(及以上)】
在大规模集群、高并发业务下,如果有1000DN集群,每个stream线程需要建立1000个连接。如果1000 stream并发,DN总共需要建立100万个连接,会消耗大量的连接、内存、fd资源。为了解决这个问题,我们引入了Libcomm通信库,在一个物理长连接上模拟n个逻辑连接,使得所有并发的数据跑在一个物理连接上,极大的解决了物理连接数过多和建连耗时的问题。
2.基本原理
GaussDB(DWS)为解决建联过多的问题,实现了Libcomm通信库(即逻辑连接通信库),在一个物理长连接上模拟n个逻辑连接,使得所有并发的数据跑在一个物理连接上。比如DN1需要给DN2发送数据,并发数1000,在原有逻辑下,DN1需要建立与DN2连接的1000个线程与之进行交互,消耗了大量的连接、内存、fd资源,而改造Libcomm通信库之后,DN1与DN2仅需建立一个真正的物理连接,在这个物理连接上可以建立很多个逻辑链接,这样可以使得1000个并发就可以用同一个物理连接进行数据交互。
那么GaussDB(DWS)的逻辑连接是怎么实现的呢?首先我们从连接数据流入手,挖掘其实现逻辑。
物理连接支持TCP、RDMA等协议连接,以TCP为例,其物理连接数据流可以分为两部分,即数据包头+数据。数据包头为固定长度,其中包含逻辑连接号和数据块长度,用来区别逻辑连接,并接收每个连接各自对应的数据。
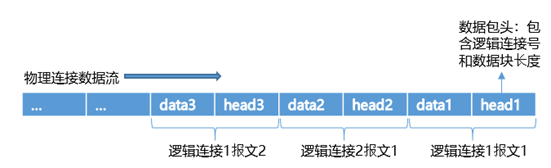
了解了物理连接发送的数据流,那具体的发送逻辑是什么样的呢?其具体的流程如下图所示:
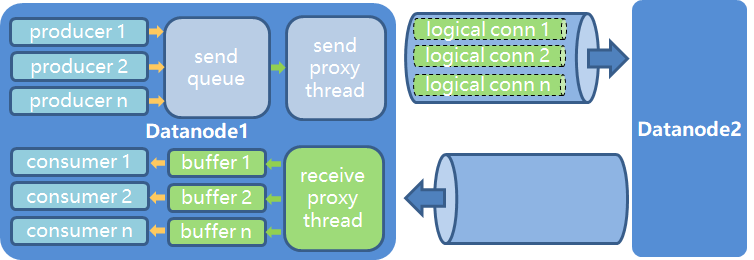
上图中producer线程为发送线程,consumer线程为接收线程,发送端逻辑如下:
- send queue:producer发送线程将要发送的数据先push到一个无锁队列中,push完成之后,producer线程就可以继续做自己的事情了
- send proxy thread:通信存在一个发送端代理线程,会统一将无锁队列中的数据,通过物理连接发送到对端
接收端逻辑如下:
- receive proxy thread:通信存在一个接收端代理线程,会统一将无锁队列中的数据,通过物理连接接收回来,解析数据包头之后,放到对应线程的buffer池中
- buffer1:consumer接收线程会从自己对应的buffer池中取出数据,执行自己的数据加工逻辑。
上述这个方法可能会存在一些问题,并发比较高时producer线程会一直往队列里push,如果此时对端cunsumer1线程正在处理别的数据导致接收buffer1满了的话,producer2和producer3无法往网络上填充更多的数据,发送阶段就会阻塞,而此时可能consumer2和consumer3正在空闲状态,等待这个接收数据,但是因为发送端阻塞而接收不到,这种场景会严重影响性能。这个模型我们称之为push模型。因此我们需要通过另外一种流控机制来解决这个问题,我们称之为pull模型。
- push模型:发送端不感知接收端状态。一直往无锁队列中push,直到push阻塞。
- poll模型:发送端感知接收端状态。发送端一开始不会发送数据,当接收端里的buffer池内存满足一定条件时,通知对应的发送端,并告知可以接收的数据量,发送端可以按照对端可以接收的数据量进行发送。
通过poll模型的实现,在本线程阻塞的情况下,其他的线程不会阻塞,以确保物理连接中数据永远不会阻塞,保证连接的通畅性。
3.相关视图
3.1.pgxc_comm_delay
该视图展示所有DN的通信库时延状态。
该视图中的字段包括节点名称、连接对端节点的节点名称、连接对端IP的对端地址、当前物理连接使用的stream逻辑连接数量、当前物理连接一分钟内探测到的最小时延、当前物理连接一分钟内探测道德平均值和当前物理连接一分钟内探测到的最大时延。

3.2.pgxc_comm_recv_stream
该视图展示所有DN上的通信库接收流状态。其中字段包括节点名称、使用此通信流的线程ID、连接对端节点名称、连接对端节点ID、通信对端DN在本DN内的标识编号、通信流在物理连接中的标识编号、通信流所使用的tpc通信socket、通信流当前的状态、通信流对应的debug_query_id编号、通信流所执行查询的plan_node_id编号、通信流所执行查询send端的smpid编号、通信流所执行查询recv端的smpid编号、通信流接收的数据总量、通信流当前生命周期使用时长、通信流的平均接收速率、通信流当前的通信配额值、通信流当前缓存的数据大小。

3.3.pgxc_comm_send_stream
该视图展示所有DN上的通信库发送流状态。其中字段包括节点名称、使用此通信流的线程ID、连接对端节点名称、连接对端节点ID、通信对端DN在本DN内的标识编号、通信流在物理连接中的标识编号、通信流所使用的tpc通信socket、通信流当前的状态、通信流对应的debug_query_id编号、通信流所执行查询的plan_node_id编号、通信流所执行查询send端的smpid编号、通信流所执行查询recv端的smpid编号、通信流接收的数据总量、通信流当前生命周期使用时长、通信流的平均接收速率、通信流当前的通信配额值和通信流等待quota值产生的额外时间开销。

3.4.pgxc_comm_status
该视图展示所有DN的通信库状态。其中字段包括节点名称、节点通信库接收速率,单位为byte/s、节点通信库发送速率,单位为byte/s、节点通信库接收速率,单位为Kbyte/s、节点通信库发送速率,单位为Kbyte/s、cmailbox的buffer大小、libcomm进程通信内存的大小、libpq进程通信内存的大小、postmaster线程实时使用率、gs_sender_flow_controller线程实时使用率、gs_receiver_flow_controller线程实时使用率、多个gs_receivers_loop线程中最高的实时使用率、当前使用的逻辑连接总数。

4.相关GUC参数
4.1 comm_max_datanode
表示TCP代理通信库支持的最大DN数,最小值为1,最大值为8192。当DN数小于256时,默认值为256;否则,为大于等于DN数的2的N次方。在集群扩容、缩容场景下,要注意此参数的变更。
4.2 comm_max_stream
表示TCP代理通信库支持的最大并发stream数量,默认值为1024,最大为60000,此参数要保证大于并发数每并发平均stream算子数(smp的平方),否则会报错Cannot get stream index, maybe comm_max_stream is not enough。此外,在设置此参数时需要考虑占用内存问题,其大小为256byte * comm_max_stream * comm_max_datanode,可见在内存、comm_max_datanode和comm_max_stream三者之间需要一个动态的规划。
针对comm_max_stream不足问题,可以考虑三种解决方案:
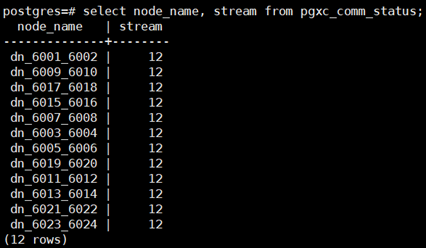
- 新版本直接使用pgxc_comm_status视图查看DN的stream使用情况:select node_name, stream from pgxc_comm_status order by 2 desc;
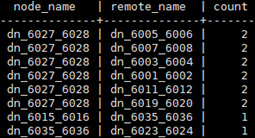
- 在CN上查询当前任意两个DN之间的stream情况:select node_name, remote_name, count(*) as stream from pgxc_comm_send_stream group by 1, 2 order by 3 desc limit 30;
- 若当前业务恢复, 可使用脚本对stream进行监控;
然而,还有情况是个别的SQL语句严重消耗stream,此时可以使用实时topsql或历史topsql找到对应的语句,修改以解决问题。
4.3 comm_max_receiver
表示TCP代理通信库接收端接收线程的数量,最大值为50,默认值为4。在大集群、大并发场景下,适当的调大该参数有利于提升查询的性能;但如果通信层可用内存不足,线程间有竞争会对接收性能有负面影响。
注:SMP是指对称多处理技术,数据库领域的SMP并行技术一般指利用多线程技术实现查询的并行执行,以充分利用CPU资源,从而提升查询性能。SMP特性通过算子并行来提升性能,同时会占用更多的系统资源,在使用时,需要根据使用场景与限制进行合理的配置。在GaussDB中,SMP功能由query_dop参数决定,默认值为1。
4.4 comm_cn_dn_logic_conn
对于256节点的集群来说,并发场景导致CN和DN之间存在大量连接,每个连接占用一个端口,则CN的端口号很容易受限。为解决此问题,设计了CN多流,即CN与DN之间采用逻辑连接。comm_cn_dn_logic_conn参数默认值是off,在集群规模或并发达到一定程度时,需要将其开启为on,避免CN与DN之间由于端口号受限而无法建连。
4.5 comm_quota_size
TCP代理通信库采用pull模式进行流量控制,避免消息堵塞。两个DN分别有一个buffer,当一条通道发送端数据量过大时,很容易造成buffer填满,阻塞了其他通道的发送。此时,对于每条通道设置一个quota,接收端根据buffer剩余空间的大小发送给发送端一个合理quota值,发送端根据quota大小发送数据。
comm_quota_size表示每个通道单次不间断发送数据量配额,默认值1MB。当通道发送数据量达到配额时,发送端等待接收端重新发送配额,进而继续发送数据,从而实现流控功能。其取值为0时,表示不使用quota,在一些大流量等场景中,查询之间可能会有影响。在1GE网卡环境中,受网卡能力限制,应该调小该参数,推荐20KB~40KB。如果环境内存充足,参数comm_usable_memory设置较大,可以适当调大,从而提升性能。
4.6 comm_usable_memory
commusable_memory表示的是TCP代理通信库可使用的最大内存大小,默认值4000MB。此参数需要根据环境内存及部署方式具体配置,保证了系统不会因为通信层接收缓存造成进程内存膨胀。在单台机器上,通信占用内存最坏情况=部署节点个数* comm_usable_memory。考虑环境内存情况,此参数配置过小,会影响通信性能,过大则可能造成系统内存不足等问题。与comm_quota_size结合,进行合理的配置至关重要。
5.总结
本文详细介绍了Libcomm通信库及其原理,让我们更好的理解GaussDB(DWS)集群通信中的具体逻辑,对于GaussDB(DWS)通信运维也具备一定的参考意义。

