
- 1斯坦福AI2021报告出炉!详解七大热点,论文引用中国首超美国
- 2OpenAI 开发系列(七):LLM提示工程(Prompt)与思维链(CoT)_llm 将高层次指令拆分成子任务
- 32. Transformer相关的原理(2.3. 图解BERT)_bertencoder图
- 4adb devices找不到设备的很多原因
- 5pytorch初学笔记(一):如何加载数据和Dataset实战_python dataset
- 6鸿蒙开发,对于前端开发来说,究竟是福是祸呢?_前端 鸿蒙
- 7宇视VM新BS界面配置告警联动上墙
- 8决策树python源码实现(含预剪枝和后剪枝)_def createdatalh(): data = np.array([['青年', '否', '
- 9hive集群搭建
- 10掌握Go语言:Go语言类型转换,解锁高级用法,轻松驾驭复杂数据结构(30)
第10章 PCA降维技术
赞
踩
序言
1. 内容介绍
本章详细介绍了PCA 主成分分析算法基本原理、python 实现PCA 算法方法以及sklearn实现方法等内容。
2. 理论目标
- 了解PCA 主成分分析算法基本原理
- 了解python 实现PCA 算法方法以及sklearn实现方法
3. 实践目标
- 掌握PCA 算法实现方法,能完成python 实现PCA算法过程
- 掌握sklearn 库的PCA 方法,能完成目标数据集的降维任务
4. 实践案例
无
5. 内容目录
-
1.PCA降维概述
-
2.PCA降维的思想及流程
-
3.PCA降维案例讲解
第1节 PCA降维概述
1. 降维概述
降维是对数据高维度特征的一种预处理方法。
降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。
在实际的生产和应用中,降维在一定的信息损失范围内,可以节省大量的时间和成本。
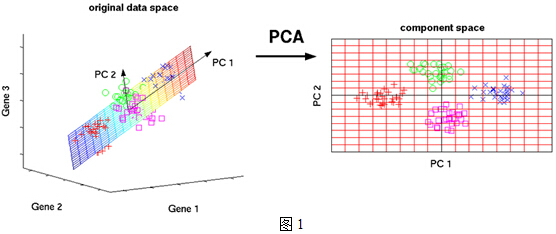
- 假设三维空间中有一系列点,可用自然坐标系xyz来表示这组数据。
- 若这些点都分布在一个过原点的斜面上,可以尝试把xyz坐标系旋转一下,使数据所在平面与xy平面重合。
- 如果把旋转后的坐标系记为x’,y’,z’,那么这组数据的表示只用x’和y’两个维度表示即可!
以上过程将点 a(x1,y1,z1),转变为以 a(x2,y2) 表示,这样就把数据维度降下来了!
2. 降维目的
数据降维的主要目的有以下几点:
- 使数据集更容易使用。
- 确保变量是相互独立的。
- 降低很多算法的计算开销。
- 去除噪音。
- 使得结果易懂。
3. 降维方法
常见的降维技术主要有:
-
PCA(Principal Components Analysis,主成分分析)。就是找出一个最主要的特征,然后进行分析。例如:考察一个人的智力情况,从数学、语文、英语成绩中,直接看数学成绩就行。
-
FA(Factor Analysis,因子分析)。是指将多个实测变量转换为少数几个综合指标,通过将相关性高的变量聚在一起,从而减少需要分析的变量数量,以减少问题分析的复杂性。例如:考察一个人的学习效果,看3 科(数学、语文、英语)平均成绩即可。
-
ICA(Independ Component Analysis,独立成分分析)。ICA认为,如果观察测到的信号是若干个独立信号的线性组合,ICA可对其进行解混。例如:KTV里面,辨别原唱和主唱。
4. PCA概述
PCA基本定义
PCA(Principal Components Analysis,主成分分析),作为一种降维技术,使数据更易用于分析数据集建立数据模型。
PCA方法主要是通过对变量协方差矩阵进行特征分解,以得到数据的主成分(即特征向量)与相应的权重值(即特征值)
回顾下特征值和特征向量的定义如下:
Ax = \lambda xAx=λx
即对于矩阵AA,存在向量 xx 和 \lambdaλ 使得上式成立。
数据区分度
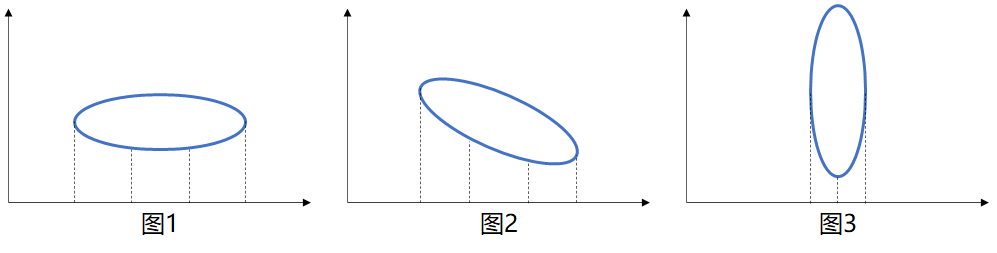
若将下图分别投影到横坐标:图1的数据分布最广,图2稍小,图3最小。
数据分布越广、离散度越大,代表数据在所投影的维度上具有越高的区分度,这个区分度就是信息量。
一般来说,数据的离散度可用方差来形容,即可认为数据方差越大,区分度越高,所蕴含的信息量越大。
坐标系转换
针对图3,通过旋转坐标系(即图3-1红色坐标轴即旋转后坐标系),发现图3在新坐标的纵向分布达到了最广,即区分度最高、方差最大。
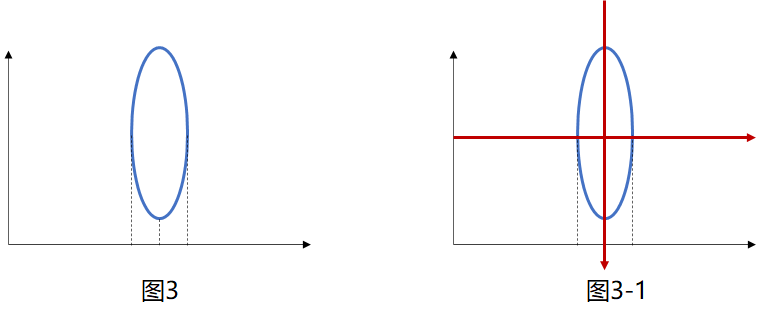
PCA的主要任务就是通过寻找最优坐标系,使得原数据的在各个坐标轴上区分度最高。此处有两个核心的值分别是特征向量 和 特征值
- 特征向量,决定了最优坐标系旋转后的方向
- 特征值,决定了图形拉伸的比例(某一特征值除以所有特征值之和称为方差贡献率,代表了该维度下蕴含的信息量的比例)
5. PCA应用场景
PCA 主要目的是用于降维,即原数据通过矩阵的线性变换,在尽可能保留原数据信息的前提下,减少数据的维度(即属性字段的数量)。可考虑应用于以下场景:
-
汽车样本数据,同时具有两个字段:最大速度属性(“千米/小时”)、最大速度属性(“公里/小时”),显然两个字段基本一致。
-
学生成绩数据,具备以下字段:学习兴趣度、复习时间、考试成绩,三项属性存在明显的强相关。
-
二手房数据,二手房样本数据较少(可能只收集到10个房子数据),但是属性字段较多(大小、位置、朝向、是否学区房、建造年代、是否二手、层数、所在层数),明显不符模型数据要求。
-
文本数据,相同含义的词组(study 和 learn),但是计算机系统会认为是两个相互独立的词组。
第2节 PCA降维的思想及流程
1. PCA思想
PCA 的核心思想是通过矩阵线性变换,找到特征向量和特征值,利用特征值计算方差贡献度决定采用哪几个主成分。主要思考过程如下:
- 去除平均值
- 计算协方差矩阵
- 计算协方差矩阵的特征值和特征向量
- 将特征值排序
- 保留前N个最大的特征值对应的特征向量
- 将原数据转换到上一步得到的N个特征向量构建的新空间中(即实现降维)
2. PCA算法流程
依据PCA思想,设计PCA具体的算法流程如下:
-
输入: mm 维样本集 D = (x^{(1)}, x^{(2)}, ……, x^{(m)})D=(x(1),x(2),……,x(m)),以及要降维到的维数nn。
-
输出: 降维后的样本集 D^{'}D′
-
算法流程:
- 对所有的样本进行中心化:x^{(i)} = x^{(i)} - \frac{1}{m}\sum_{j=1}^m x^{(j)}x(i)=x(i)−m1∑j=1mx(j)。
- 计算样本的协方差矩阵XX^{T}XXT。
- 对矩阵XX^{T}XXT进行特征值分解。
- 取出最大的 nn 个特征值对应的特征向量 (w^{1}, w^{2},……, w^{n})(w1,w2,……,wn),将所有的特征向量标准化后,组成特征向量矩阵 WW。
- 对样本集中的每一个样本 x^{(i)}x(i),转化为新的样本 z^{(i)} = W^{T}x^{(i)}z(i)=WTx(i)。
- 得到输出样本集 D^{'} = (z^{(i)}, z^{(i)},……, z^{(i)})D′=(z(i),z(i),……,z(i))。
3. PCA优缺点
-
优点: 降低数据的复杂性,可识别出最重要的多个特征。
-
缺点: 不一定需要,且可能损失有用信息
-
适用的数据类型: 数值数据类型
第3节 PCA降维案例
1. 案例问题描述
现有样例数据集文件(txt格式),文件名称testSet.txt(分割符为 \t),文件内容如下:
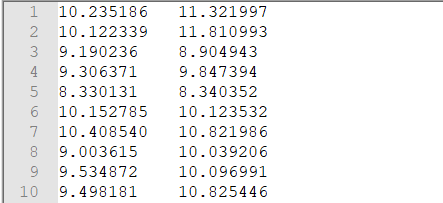
以上数据包含两列数据,即两个维度数据。需要借助PCA 主成分分析方法,对数据降维处理,降到1维(即1 列)
2. 案例解决方法
解决思路
- 文件数据内容读取功能以函数封装,通过传递文件路径、分隔符即可读取数据内容,以数组形式返回
- PCA降维功能以函数封装,通过传递数据集、降维的维数即可完成数据降维
- 2.1. 去除平均值
- 2.2. 计算协方差矩阵
- 2.3. 计算协方差矩阵的特征值和特征向量
- 2.4. 将特征值排序
- 2.5. 保留前N个最大的特征值对应的特征向量
- 2.6. 将原数据转换到上一步得到的N个特征向量构建的新空间中(即实现降维)
代码实现
step1. 文件数据内容读取功能
文件数据内容读取功能以函数封装,通过传递文件路径、分隔符即可读取数据内容,以数组形式返回
## 1. 文件数据内容读取功能 def loadDataSet(fileName, delim='\t'): with open(fileName) as fin: lines = fin.readlines() infoList = [] for line in lines: rList = line.strip().split(delim) ## .strip() 去除前后空格,.split(delim) 按分割符delim 进行分割 infoList.append(list(map(float, rList))) ## map(function, object) 将object 变为 float 类型 return np.mat(infoList)
step2. PCA降维功能
PCA降维功能以函数封装,通过传递数据集、降维的维数即可完成数据降维
## 2. PCA降维功能 def myPca(dataMat, topNfeat=9999999): # 2.1.去除平均值 meanVals = np.mean(dataMat, axis=0) # axis=0表示列,axis=1表示行 print('各列的均值:\n', meanVals) # 2.2.计算协方差矩阵 meanRemoved = dataMat - meanVals print('每个向量同时都减去均值:\n', meanRemoved) # 2.3.计算协方差矩阵的特征值和特征向量 covMat = np.cov(meanRemoved, rowvar=0) eigVals, eigVects = np.linalg.eig(np.mat(covMat)) print('特征值:\n', eigVals,'\n特征向量:\n', eigVects) # 2.4.将特征值排序 eigValInd = np.argsort(eigVals) # 特征值从小到大的排序,返回从小到大的index序号 # 2.5.保留前N个最大的特征值对应的特征向量 eigValInd = eigValInd[:-(topNfeat+1):-1] redEigVects = eigVects[:, eigValInd] print('重组n特征向量最大到最小:\n', redEigVects.T) # 特征值方差贡献率 eigValsPer = np.sum(eigVals[eigValInd]) / np.sum(eigVals) # 2.6.将原数据转换到上一步得到的N个特征向量构建的新空间中(即实现降维) lowDDataMat = meanRemoved * redEigVects reconMat = (lowDDataMat * redEigVects.T) + meanVals return lowDDataMat, reconMat, eigValsPer
step3. 方法调用
通过调用以上方法,实现数据降维,打印相关结果内容
import numpy as np fileName = r"testSet.txt" ## 1. 文件数据内容读取功能以函数封装,通过传递文件路径、分隔符即可读取数据内容,以数组形式返回 dataMat = loadDataSet(fileName, delim='\t') # print(dataMat) ## 2. PCA降维功能以函数封装,通过传递数据集、降维的维数即可完成数据降维 lowDmat, reconMat, eigValsPer = myPca(dataMat, topNfeat=1) print('自定义PCA降维前的数据规模如下:\n',np.shape(dataMat)) print('自定义PCA降维后的数据规模如下:\n',np.shape(lowDmat)) print('自定义PCA降维后的原始数据转换至新数据如下:\n', reconMat[0]) print('自定义PCA降维后的数据信息完整度如下:\n', str(round(eigValsPer*100, 2))+"%")
- 各列的均值:
- [[9.06393644 9.09600218]]
- 每个向量同时都减去均值:
- [[ 1.17124956 2.22599482]
- [ 1.05840256 2.71499082]
- [ 0.12629956 -0.19105918]
- ...
- [ 0.79098556 0.10539082]
- [ 0.05064356 0.03821282]
- [ 1.27096256 -0.55239818]]
- 特征值:
- [0.36651371 2.89713496]
- 特征向量:
- [[-0.85389096 -0.52045195]
- [ 0.52045195 -0.85389096]]
- 重组n特征向量最大到最小:
- [[-0.52045195 -0.85389096]]
- 自定义PCA降维前的数据规模如下:
- (1000, 2)
- 自定义PCA降维后的数据规模如下:
- (1000, 1)
- 自定义PCA降维后的原始数据转换至新数据如下:
- [[10.37044569 11.23955536]]
- 自定义PCA降维后的数据信息完整度如下:
- 88.77%

3. sklearn实现方法
基于sklearn 库的 PCA降维功能以函数封装,通过传递数据集、降维的维数即可完成数据降维
## 3. 基于sklearn 库的 PCA降维功能 def skPca(dataMat, topNfeat): mySKPca = PCA(n_components=topNfeat) # 加载PCA算法,设置降维后主成分数目为2 # .fit(X) 表示用数据X来训练PCA模型。 # .transform(X) 将数据X转换成降维后的数据。当模型训练好后,对于新输入的数据,都可以用transform方法来降维。 lowDDataMat = mySKPca.fit_transform(dataMat) # .fit_transform(X) 用X来训练PCA模型,同时返回降维后的数据。 reconMat = mySKPca.inverse_transform(lowDDataMat) # .inverse_transform(X) 将降维后的数据转换成原始数据 # components_ :返回具有最大方差的成分。 # n_components_:返回所保留的成分个数n。 # explained_variance_ratio_:返回所保留的n个成分各自的方差百分比。 eigValsPer = np.sum(mySKPca.explained_variance_ratio_) return lowDDataMat, reconMat, eigValsPer
from sklearn.decomposition import PCA lowDmat, reconMat, eigValsPer = skPca(dataMat, topNfeat=1) print('sklearn PCA降维前的数据规模如下:\n',np.shape(dataMat)) print('sklearn PCA降维后的数据规模如下:\n',np.shape(lowDmat)) print('sklearn PCA降维后的原始数据转换至新数据如下:\n', reconMat[0]) print('sklearn PCA降维后的数据信息完整度如下:\n', str(round(eigValsPer*100, 2))+"%")
- sklearn PCA降维前的数据规模如下:
- (1000, 2)
- sklearn PCA降维后的数据规模如下:
- (1000, 1)
- sklearn PCA降维后的原始数据转换至新数据如下:
- [10.37044569 11.23955536]
- sklearn PCA降维后的数据信息完整度如下:
- 88.77%

