- 1python:实现基于NLTK的名词短语提取器(附完整源码)_nltk 词库导出
- 2鸿蒙一次开发,多端部署(五)页面开发的一多能力介绍
- 3【Pytorch神经网络实战案例】20 基于Cora数据集实现图卷积神经网络论文分类_基于pytorch图像分类论文
- 4【NLP】每个NLP工程师都应该知道的10 种不同的 NLP 技术
- 5curl命令忽略不受信任的https安全限制_curl performs ssl certificate verification by defa
- 6云原生 (Cloud Native) = 微服务 + DevOps + 持续交付 + 容器化 ?_采用微服务架构、容器、持续集成与交付、devops等云原生技术
- 7python笔记(5)Numbers(数字)
- 8Pytorch 下载失败原因
- 9搭建 rasa 框架中遇到的 domain.yml 无效问题_rasa报错core training was skipped because no valid d
- 10论文阅读-多级检查点重新启动MPI应用的共同设计
Ram Based Shift Register Xilinx IP核仿真与理解_ram_base_shift
赞
踩
在学习图像处理过程中,卷积模板和FIFO的运用是肯定离不开的,以彬哥的《基于MATLAB与FPGA的图像处理教程》里的腐蚀与膨胀知识点、帧差法运动目标检测为例。
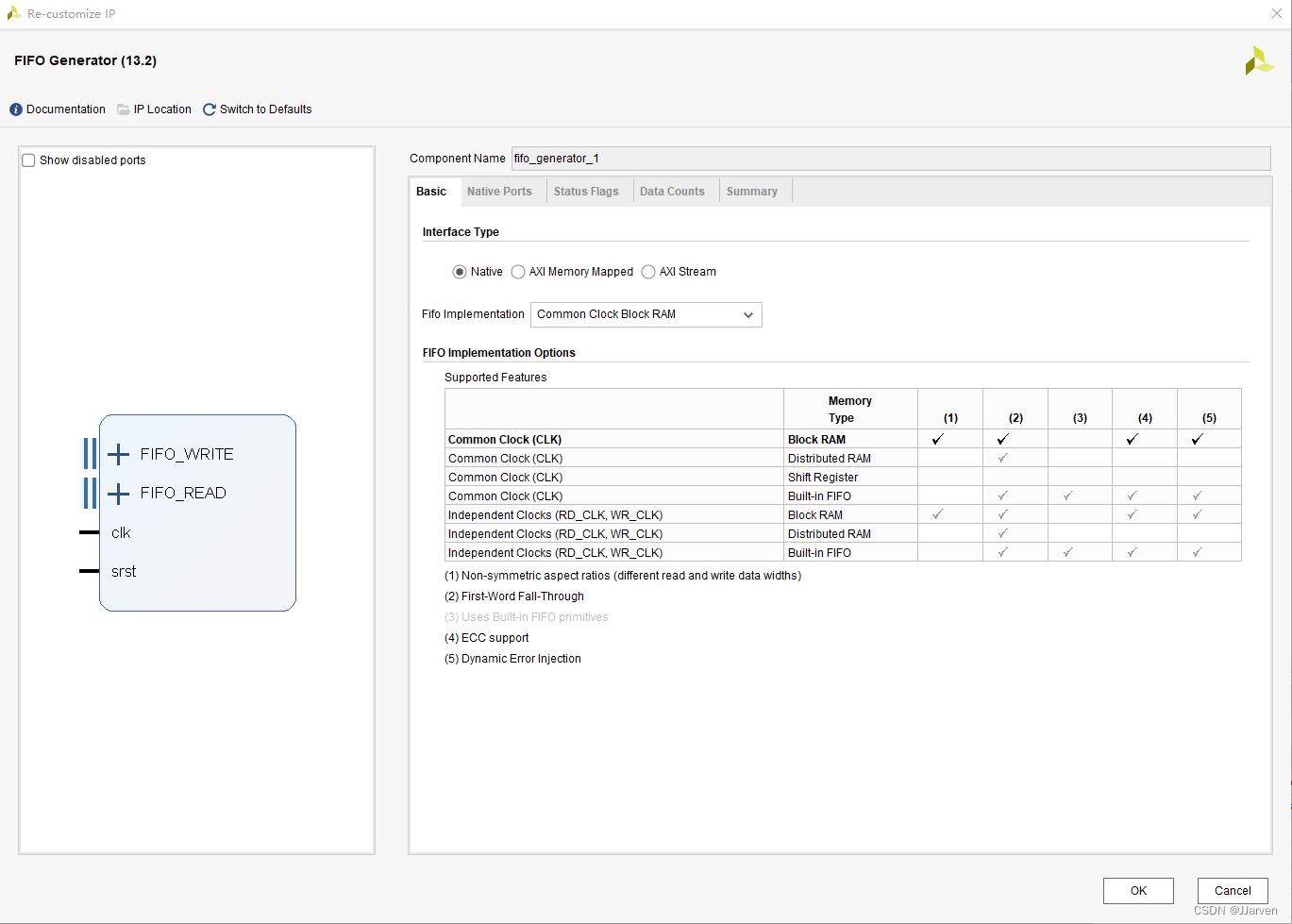
开运算在生成3x3的卷积模板的时候,就需要调用Xilinx官方IP核:FIFO Ganerator 和 Ram-based Shift Register。同步FIFO是将从VDMA IP核中读取到的AXI_Stream流数据信号进行缓存做帧差运算,调用这个IP核的目的是防止前面的数据还没有处理完,后面的数据就已经改变导致数据混乱发生错误。
接下来只需要例化两次Shift Ram IP核,以菊花链的方式进行连接,作用等同于寄存帧差之后的两行数据,第三行的数据为输入的实时数据,就能够实现一个3x1的模板,Shift Ram IP核的数据位宽设置为1(因为之前的帧差结果是二值化数据,所以数据只会是0和1,同时能够节约一部分资源),深度设置为800(因为本人的tft显示屏是800*480,一行的像素数据是800个,根据具体情况而定),如下图所示:
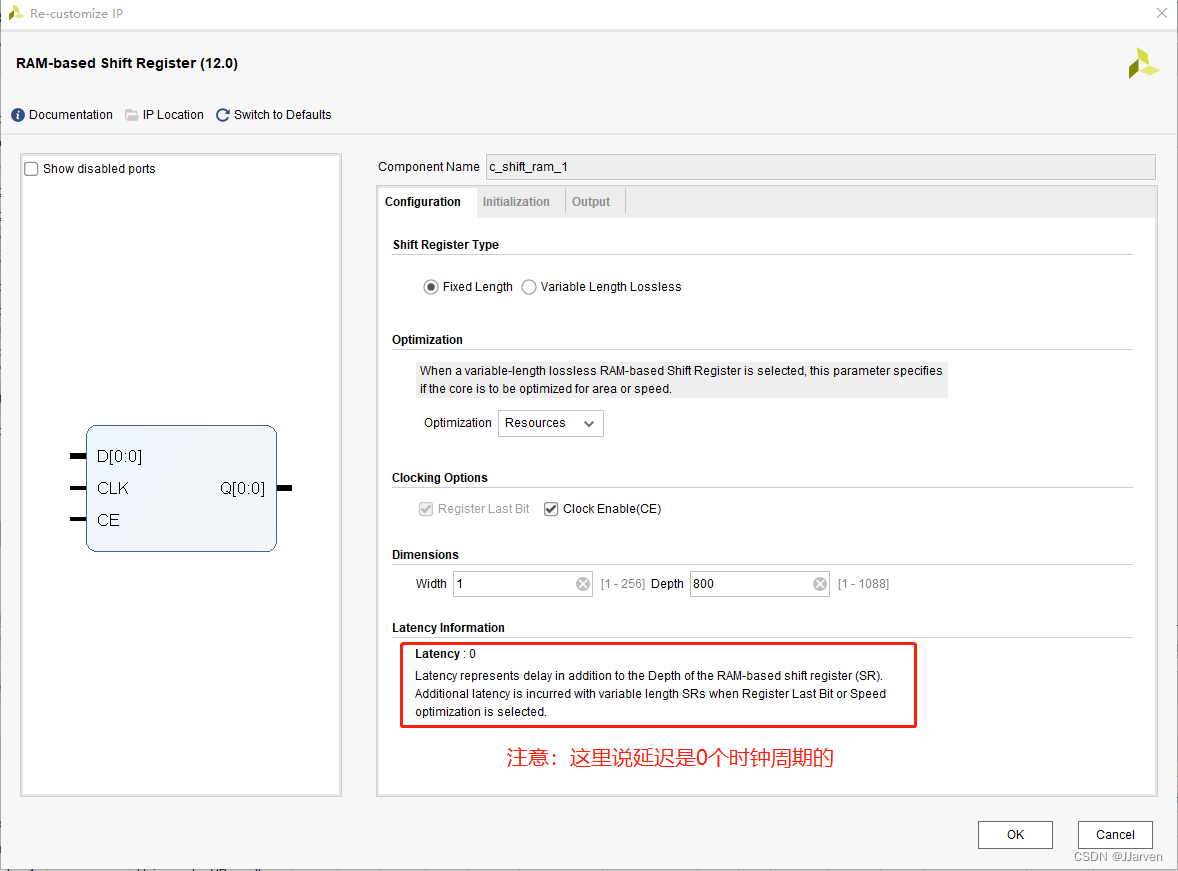
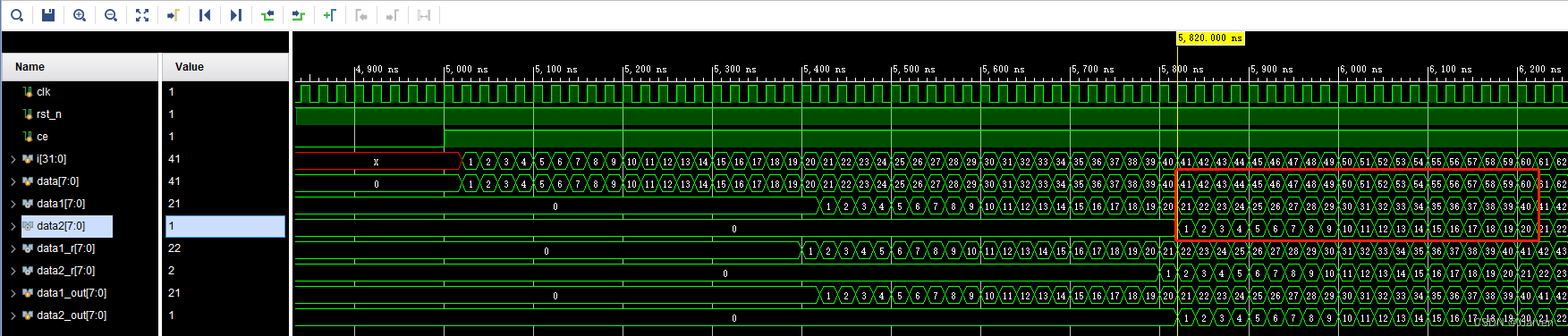
在例化完Ram-based Shift Register IP核和时序约束之后,我以为直接进行封装就能用了,因为说是0延迟,我也就没有进行仿真,但是其实是需要将IP核的输出寄存一拍之后才能对齐输入的帧差数据,要不然生成的3x3矩阵就是错误的。测试代码如下:
- module top( //顶层模块
- input clk,
- input rst_n,
- input CE, //时钟使能信号,在配置中可以打开,也可以关闭
-
- input [7:0]data,
-
- output [7:0]data1,
- output [7:0]data2
- );
-
- reg [7:0]data1_out; //寄存一拍后的数据
- reg [7:0]data2_out;
- wire [7:0]data1_r; //IP核输出数据
- wire [7:0]data2_r;
-
- c_shift_ram_0 c_shift_ram_u0 (
- .D(data),
- .CLK(clk),
- .CE(CE),
- .Q(data1_r)
- );
-
- c_shift_ram_0 c_shift_ram_u1 (
- .D(data1_r),
- .CLK(clk),
- .CE(CE),
- .Q(data2_r)
- );
-
- always@(posedge clk or negedge rst_n)begin //将数据寄存一拍
- if(!rst_n)begin
- data1_out <= 8'd0;
- data2_out <= 8'd0;
- end
- else begin
- data1_out <= data1_r;
- data2_out <= data2_r;
- end
- end
-
- assign data1 = data1_out;
- assign data2 = data2_out;
-
- endmodule

- `timescale 1ns / 1ps
- `define clk_period 20
-
- module top_tb(); //testbench模块
- reg clk;
- reg rst_n;
- reg ce;
- reg [7:0]data ;
-
- wire [7:0]data1;
- wire [7:0]data2;
-
- top top_u(
- .clk (clk),
- .rst_n (rst_n),
- .CE (ce),
-
- .data (data),
-
- .data1 (data1),
- .data2 (data2)
- );
-
- initial clk = 1;
- always#(`clk_period/2) clk = ~clk;
-
- integer i;
-
- initial begin
- rst_n = 1'b0;
- data = 8'd0;
- ce = 1'b0;
-
- #(`clk_period*200);
- rst_n = 1'b1;
- #(`clk_period*50);
- ce = 1'b1; //这里会有一个小bug,后面再解释
- for(i=1;i<400;i=i+1)begin //连续输入400个数据
- data = 8'd0 + i;
- #(`clk_period);
- end
- #200;
- ce = 1'b0;
- $stop;
- end
- endmodule

在这里发现数据是对齐的,但是data2的第一个数据是从2开始的,这就明显是错误的,其实就是我的基础不是太牢固,在testbench中 ce 信号拉高之后我就紧跟着开始输入了数据,这时候在下一个时钟的上升沿才开始把输入数据传进Shift Ram IP核,所以开始的数据就变成了2而不是1。只要在拉高ce之后再延迟一个时钟周期就能解决这个问题(不是卖关子,只是记录一下自己平常会犯的错)。