
- 1kubernetes容器技术基础入门_kubernetes边缘侧和容器基础
- 2基于微信小程序医院预约挂号系统设计与实现(源码+lw+部署文档+讲解等)
- 3shell find命令中“+n”、“-n”和“n”的区别_find +n -n
- 4Meta 开源语音 AI 模型支持 1,100 多种语言_开源ai配音模型
- 5runuser: warning: cannot change directory to /nonexistent: No such file or directory
- 6Modelsim的脚本仿真流程_modelsim do path to build/build.do
- 7反编译微信小程序保姆级教程(PC端程序包)_微信小程序反编译
- 8【同步】文件同步rsync |自动同步软件FreeFileSync
- 9ChatGPT:将人工智能技术融入论文写作,提升创作品质
- 102.五子棋_c++中五子棋获胜的逻辑
基于跨模态预测的多模态情感分类
赞
踩
每天给你送来NLP技术干货!
论文名称:A Text-Centered Shared-Private Framework via Cross-Modal Prediction for Multimodal Sentiment Analysis
论文作者:吴洋,林子杰,赵妍妍,秦兵,朱李楠
原创作者:吴洋
论文链接:https://aclanthology.org/2021.findings-acl.417.pdf
出处:哈工大SCIR
1.引言
随着社交网络的快速发展,人们在平台上的表达方式变得更加丰富,越来越多的人选择使用视频来表达自己的观点和情感。如何分析这些多模态数据中人们所表达的情感成为当前情感分析领域所面临的机遇和挑战。一方面,多模态数据相对于单模态数据文本来说,扩展了信息的维度,提供了更多的信息,使得模型不仅可以考虑到文本中的信息,还可以综合利用其它模态中的信息,如音频中的语调,图像中的面部表情,帮助情感分析系统对情感进行更准确的别。另一方面,虽然多模态数据带来了更多的信息,但是分析和处理来自不同模态的异构数据(如音频数据,图像数据,文本数据)给研究人员带来了巨大的挑战。多模态数据带来更多的有效信息的同时也带来了更多的无效信息,如处理一秒的音频数据和一秒的视频数据就要分别处理上万个采样点信号以及数十张包含成千上万个像素点图片,如何从这些信息中挖掘出对情感分类有用的信息,如何高效融合来自不同模态的情感信息成为多模态情感分析面临的主要挑战。
2. 相关工作
相关研究工作可以根据使用的特征粒度分为两类工作,一类是基于句子级别特征的多模态特征融合方法。句子级别特征指的是使用一个整体特征向量表征整个句子,一整段音频,或一系列视频帧。此类方法中三个模态信息由三个不同模态的句子级别特征进行表示。为了充分融合三个模态的特征,Zadeh 等人 [1] 提出张量融合网络,其主要思想是利用向量外积操作对单模态信息,双模态以及三模态特征交互进行充分的建模。但张量融合网络所采用的向量外积操作会使得融合后的向量维度极高,并且操作耗时很长,因此 Liu 等人 [2] 在前人工作基础上提出低秩融合网络,该网络利用低秩张量分解对网络参数进行分解,进而加速了融合过程。以上基于句子级别特征的多模态特征融合方法的好处是可以基于全局特征进行预测,但是缺点是忽略了不同模态的局部特征之间的对齐关系。因此,另一类方法是基于词级别特征的多模态特征融合方法。Chen 等人 [3] 首先提出使用文本-语音强制对齐获取每个词语对应的时间起始点进而完成文本与语音/图像之间的特征对齐。基于词级别的特征,Chen 等人提出使用门控机制对输入特征进行过滤,去除特征中含有的噪音。Wang 等人 [4] 观察到不同词语在不同的模态上下文下会表达出不同的意思,由此观察的启发下,提出了词表示动态更新网络,通过融合其它模态的特征对词语特征进行更新,进而得到更准确的词语表征。但是由于获取词级别多模态特征需要对文本和语音进行强制对齐,耗时费力,因此 Tsai 等人 [5] 提出使用跨模态注意力机制进行隐式的跨模态特征对齐,其相对于显式的特征对齐来说有两点好处,第一点是将特征对齐蕴含在融合网络中,无需进行显式的特征对齐。第二点是经过显式对齐后,一个文本特征仅能跟少量的一小段时间内的特征进行交互,限制了特征交互的范围。而利用隐式的跨模态特征交互可以与整个句子的特征进行交互。基于此考虑,Tsai 等人基于 Transformer 架构 [5] 实现了多模态 Transformer,该模型无需显式的特征对齐,并可以捕捉到细粒度的特征交互。
3. 我们的动机
以往的多模态特征融合研究都是将是三个模态特征视为同等重要,然后隐式地对不同模态之间的交互进行建模。我们认为更深入的研究不同模态对于目标任务的贡献以及显式的分析和建模不同模态特征之间的关系将会帮助模型更有效的进行多模态特征融合。并且,我们提出了两点观察,第一点是,多模态情感分析中文本模态占据主要地位,以往实验结果表明当去掉文本模态后模型结果相比去去掉其它模态产生了巨大的下降。第二点是,相对于文本模态来说,其他模态提供了两类信息,一类信息是共享语义,共享语义没有提供文本模态外的信息,但可以增强相应的语义,并使得模型更加鲁棒。另一类信息是私有语义,私有语义提供了文本之外的语义信息,并可以使得模型预测更加准确。基于这两点观察,我们提出了一种基于跨模态预测的以文本为中心的共享私有框架。在该框架中,我们利用跨模态预测任务来分辨共享特征以及私有特征,并设计了以文本为中心的多模态特征融合机制对多模态特征进行特征融合。
4. 提出的方法
我们的方法主要包含两部分,一部分是共享特征与私有特征鉴别,另一部分是对共享特征和私有特征进行特征融合。
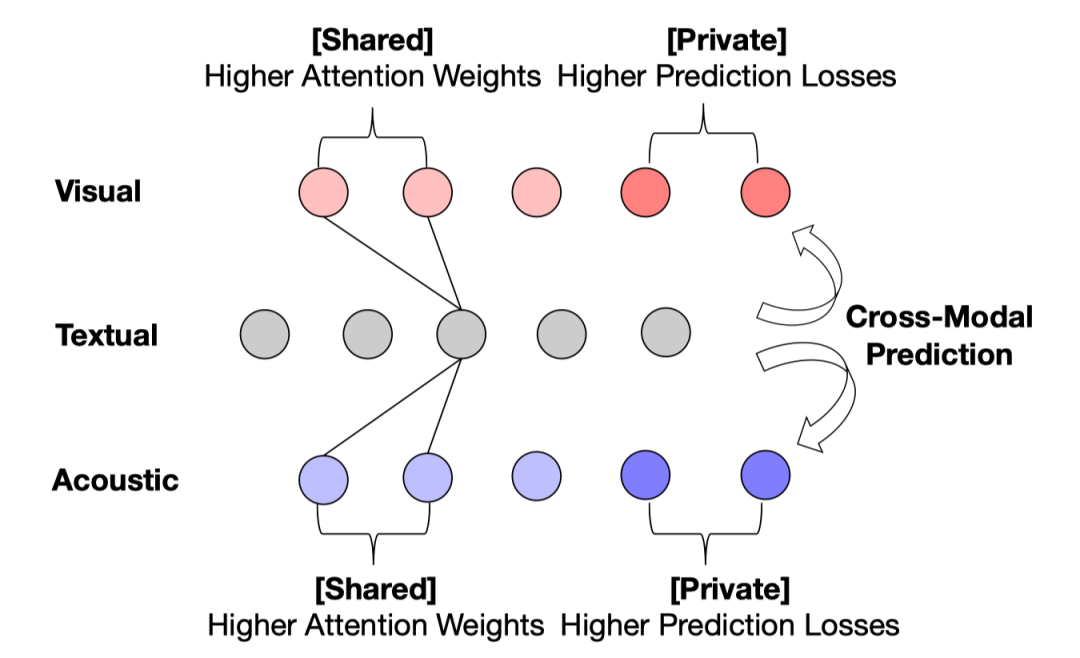
图1 基于跨模态预测的共享特征与私有特征鉴别
4.1 共享特征与私有特征鉴别
定性的来说,共享特征是指该特征包含与文本特征相关的信息,而私有特征是指该特征包含的信息没有包含在文本特征中。为了定量的分别共享特征与私有特征,我们使用了跨模态预测模型。具体来说,跨模态预测模型的输入是文本特征,输出是音频/图像特征。该模型是由带有注意力机制的 Seq2Seq 模型实现。通过该模型我们可以更为具体的定义共享特征和私有特征。如图1所示,私有特征是指通过文本特征难于预测出来的特征,即预测时损失函数值比较高的时间步的特征。在预测过程中,要把某一时间步特征预测准确则需要注意力机制注意到与所要生成特征相关的信息上,因此我们认为如果预测一个特征时,对于某一文本特征权重较高,则认为该特征为这一文本特征的共享特征。为了更直观地阐述这个思路,我们对其进行了可视化,见图2。(1)首先,我们将注意力权重可视化为图,每个节点代表一个特征,红色节点代表待预测的特征,灰色代表文本特征,点之间连边上的值表示注意力权重。(2)删除注意力权重低的连边,只保留部分连边。(3)对于每一个非文本特征节点进行该操作,剩余连边则表示每个文本特征与其对应的共享特征。共享特征与私有特征的位置用掩蔽矩阵 smask 和 pmask 进行表示。
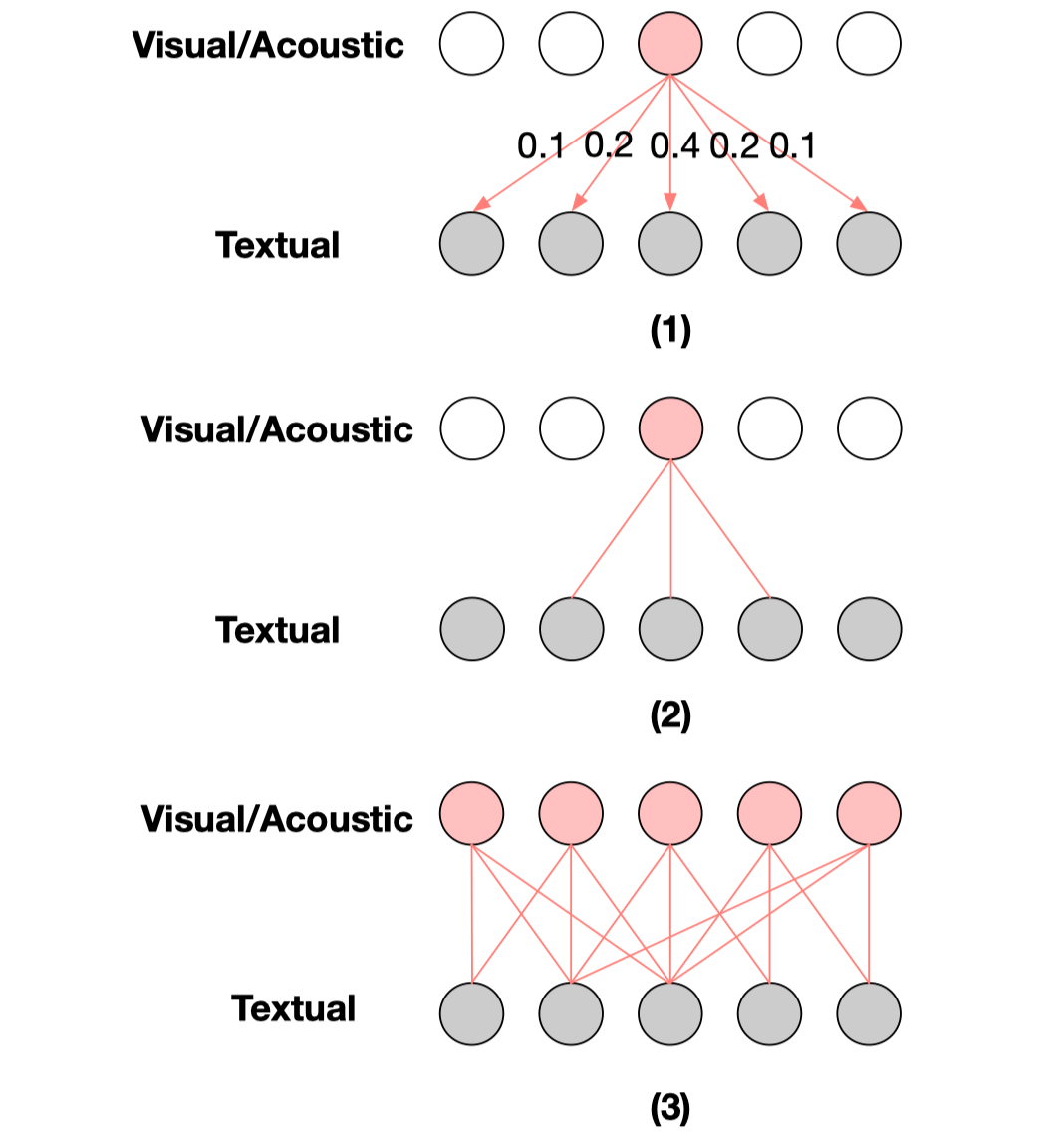
图2 获取共享特征的方法
4.2 多模态特征融合
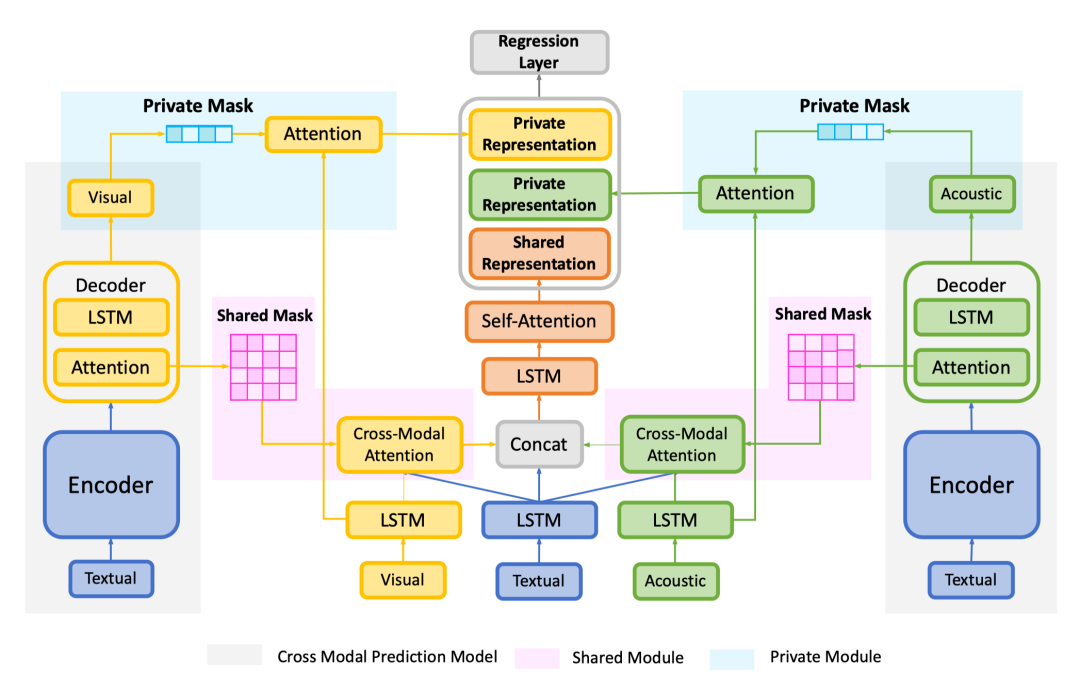
图3 模型架构
模型主要由四部分组成,输入层,共享模块,私有模块以及预测层。整体模型架构如图3所示。
首先,各个模态的特征分别通过输入层进行上下文特征编码,得到编码后的特征表示。
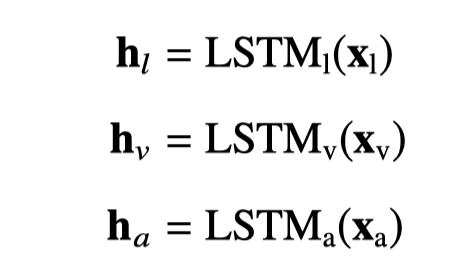
编码后的特征表示送入到共享模块中,该模块利用跨模态注意力机制融合文本特征与与其对应的共享特征。
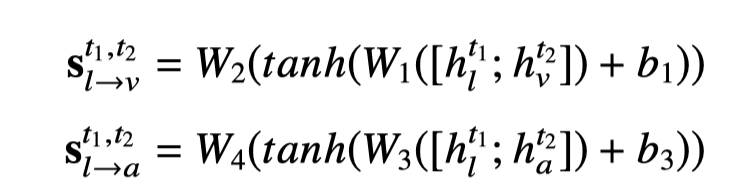
为了让模型只聚焦在共享特征上,我们使用从上一步获取掩蔽矩阵 smask 进行限定。
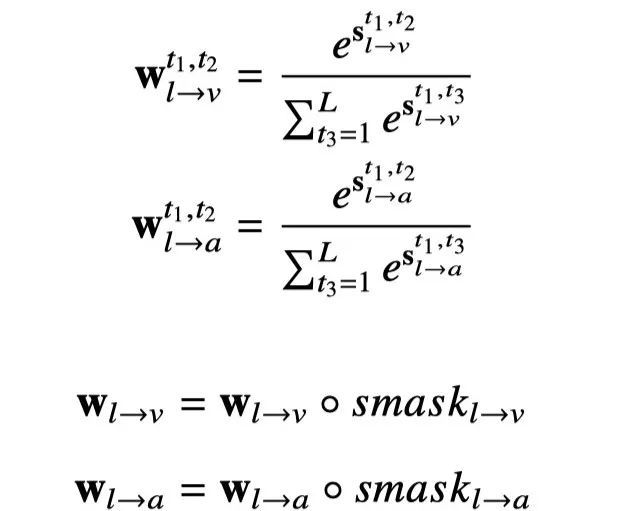
最终,对共享特征进行加权求和,并使用自注意力机制进行上下文联合建模,最终取 rn 的最后一个时间步的表示作为共享表示 rs。
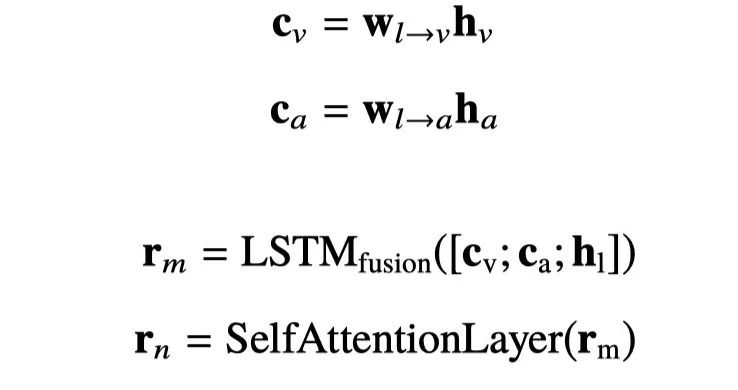
同时,经过输入层的特征表示也被送入私有模块中,并利用私有掩蔽矩矩阵smask 使得模型聚焦在私有特征上,最终得到私有表示 pv 和 pa 。最终共享表示和私有表示送入预测层中进行情感预测。

5. 实验结果
5.1 主实验结果
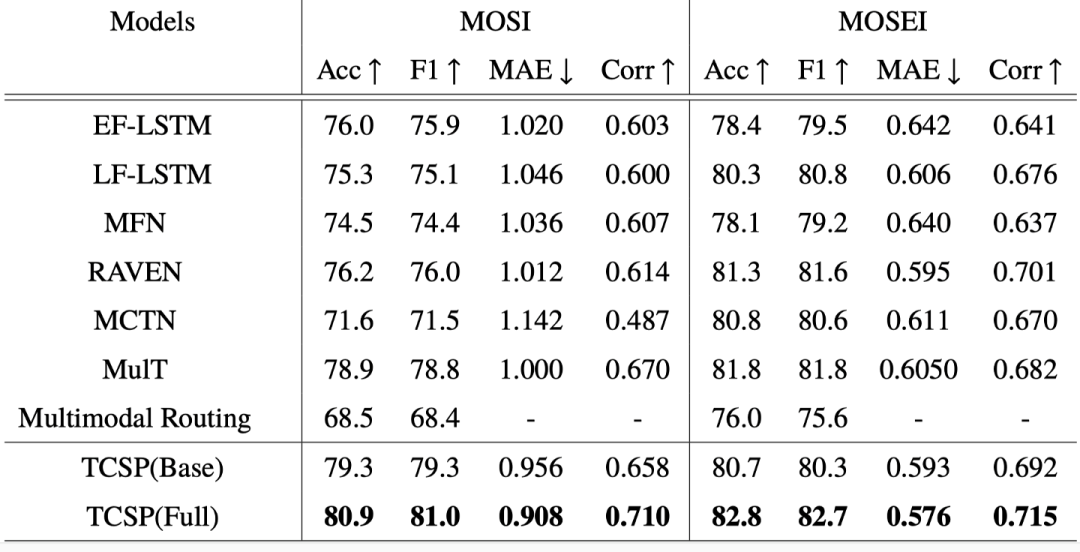
为了验证我们模型的有效性,我们在 MOSI 和 MOSEI 两个公开数据集上进行了实验,结果如表1所示。实验结果表明利用跨模态预测模型对共享特征和私有特征进行区分并显式地与两类特征分别进行交互可以取得更好的结果。
表1 主实验结果
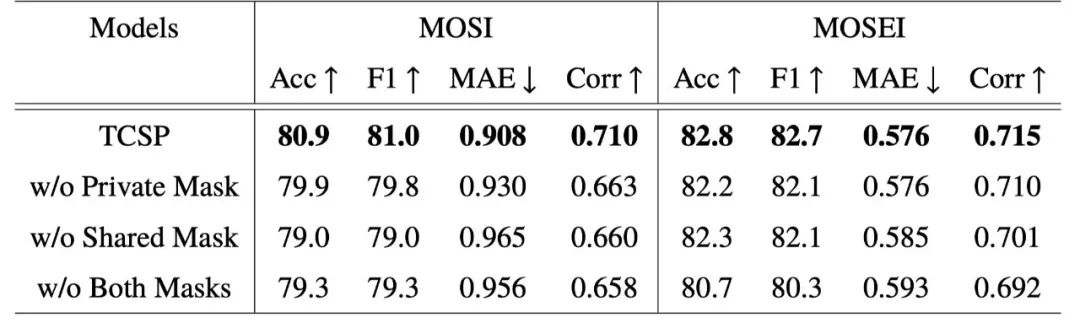
5.2 消融实验结果
为了分析区分共享特征与私有特征带来的影响,我们设计了消融实验,结果如表2所示。实验结果表明,消融任何一个掩蔽矩阵均导致模型性能下降,这验证了我们方法各个部件的有效性。
表2 消融实验结果
6. 结论
我们提出了一个以文本为中心的共享私有框架,该框架以文本模态为中心,从语音模态和图像模态中挖掘两类信息来辅助文本模态。一类信息是共享语义,利用该类信息可以加强文本中相应的语义,使得模型更加的鲁棒。另一类信息是私有语义,利用该类信息补充文本语义,进一步使得模型预测更加的准确。为了实现对两类信息的分辨,我们提出使用跨模态预测任务,并设计了相应的方法。实验结果表明,通过显式地让文本特征与共享和私有特征进行分别的交互,可以更有效的进行多模态特征融合。
参考文献
[1] Zadeh A, Chen M, Poria S, et al. Tensor Fusion Network for Multimodal Sentiment Analysis. EMNLP 2017.
[2] Liu Z, Shen Y, Lakshminarasimhan V B, et al. Efficient Low-rank Multimodal Fusion With Modality-Specific Factors. ACL 2018.
[3] Chen M, Wang S, Liang P P, et al. Multimodal Sentiment Analysis with WordLevel Fusion and Reinforcement Learning. ICMI 2017.
[4] Wang Y, Shen Y, Liu Z, et al. Words Can Shift: Dynamically Adjusting Word Representations Using Nonverbal Behaviors. AAAI 2019.
[5] Tsai Y-H H, Bai S, Liang P P, et al. Multimodal Transformer for Unaligned Multimodal Language Sequences. ACL 2019.
本期责任编辑:冯骁骋
本期编辑:彭 湃
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!
