
- 1VMWare克隆虚拟机之后,IP地址修改_虚拟机克隆后怎么修改ip地址
- 2Git branch && Git checkout常见用法
- 3开源模型应用落地-qwen1.5-7b-chat-LoRA微调(二)
- 4Linux项目自动化构建工具-make/ makefile及其应用:多文件编写第一个linux程序:进度条(懒人学习必备博文!!!)
- 5Javascript基础 86个面试题汇总 (附答案)_javascript面试
- 6《铸梦之路》Untiy高性能自动化UI管理框架ZMUIFramework
- 7spyder安装pyqt5_spyder怎么安装pyqt5
- 81694件AI事件大盘点!2020年12月,哪些让你记忆深刻_最优子集选择问题的多项式算法 王学钦讲座
- 9Matlab怎么计算信号的能量,Matlab小波包分解后如何求各频带信号的能量值? [转]...
- 10朴素贝叶斯(Naive Bayes)_贝叶斯公式小球
BiLSTM / BiRNN / BiLSTM-CRF / Bert-BiLSTM-CRF 全网最强大厂面试级深度的知识点整理_与bilstm-crf相似的算法模型
赞
踩
BiLSTM



BiRNN

BiLSTM-CRF


没有CRF的BiLSTM输出如上图所示,可以发现会出现B后面直接跟O的现象,直接会出错。
而我们可以通过CRF层来对输出结果进行各种约束,

接下来,我们对CRF层进行具体分析:
CRF层
CRF层中的损失函数包括两种类型的分数,而理解这两类分数的计算是理解CRF的关键。
1. 发射分数
第一个类型的分数是发射分数(状态分数)(该word 对应到 该tag)。这些状态分数来自BiLSTM层的输出。如下图所示,
w
0
w_0
w0被预测为B-Person的分数是1.5。

为方便起见,我们给每个类别一个索引,如下表所示:

X
i
,
y
j
X_{i,y_j}
Xi,yj代表状态分数,
i
i
i是单词的位置索引,
y
j
y_j
yj是类别的索引。根据上表,
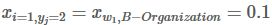
表示单词
w
1
w_1
w1被预测为B−Organization的分数是0.1。
2. 转移分数
我们用 t y i , y j t_{y_i,y_j} tyi,yj来表示转移分数。例如, t B − P e r s o n , I − P e r s o n t_{B−Person,I−Person} tB−Person,I−Person=0.9表示从类别B−Person→I−Person的分数是0.9。因此,我们有一个所有类别间的转移分数矩阵。(这个矩阵中的分数是学习出来的!)
为了使转移分数矩阵更具鲁棒性,我们加上START 和 END两类标签。START代表一个句子的开始(不是句子的第一个单词),END代表一个句子的结束。
下表是加上START和END标签的转移分数矩阵。


要怎样得到这个转移矩阵呢?
实际上,转移矩阵是BiLSTM-CRF模型的一个参数。在训练模型之前,你可以随机初始化转移矩阵的分数。这些分数将随着训练的迭代过程被更新,换句话说,CRF层可以自己学到这些约束条件。
3. CRF损失函数
CRF损失函数由两部分组成,真实路径的分数 和 所有路径的总分数。真实路径的分数应该是所有路径中分数最高的。
例如,我们的数据集中有如下几种类别:



现在的问题是:
- 怎么定义真实路径的分数?
- 怎么计算所有路径的总分?
- 当计算所有路径总分时,是否需要列举出所有可能的路径?(不能说是列举出所有可能的路径,而是使用类似动态规划的算法逐步累加,得到当时时刻的所有路径总分)
1.先集中注意力来计算真实路径
S
i
S_i
Si,
以“START B-Person I-Person O B-Organization O END”这条真实路径来说:
句子中有5个单词,
w
1
,
w
2
,
w
3
,
w
4
,
w
5
w_1,w_2,w_3,w_4,w_5
w1,w2,w3,w4,w5
加上START和END在句子的开始位置和结束位置,记为,
w
0
,
w
6
w_0,w_6
w0,w6
S
i
=
E
m
i
s
s
i
o
n
S
c
o
r
e
+
T
r
a
n
s
i
t
i
o
n
S
c
o
r
e
S_i = EmissionScore + TransitionScore
Si=EmissionScore+TransitionScore

上述这些分数来自BiLSTM层的输出,至于
x
0
,
S
T
A
R
T
x_{0,START}
x0,START 和
x
6
,
E
N
D
x_{6,END}
x6,END ,则设为0。

上述这些分数来自于CRF层。
将上述这两类分数加和即可得到 S i S_i Si 和 路径分数 e S i e^{S_i} eSi
2.所有路径的总分
如何计算所有路径的总分呢?
Step 1
我们的训练目标通常是最小化损失函数,所以我们加上负号进行变形:

前面我们已经很清楚如何计算真实路径得分,现在我们需要找到一个方法去计算
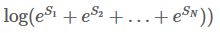
Step 2:回忆一下状态分数 和 转移分数
为了简化问题,我们假定我们的句子只有3个单词组成:
X
=
[
w
0
,
w
1
,
w
2
]
X = [w_0, w_1 ,w_2]
X=[w0,w1,w2]
另外,我们只有两个类别:
L
a
b
e
l
S
e
t
=
l
1
,
l
2
LabelSet = {l_1, l_2}
LabelSet=l1,l2
状态分数如下:

转移矩阵如下:

Step 3:开始!

接下来,你会看到两个变量:obs和 previous。Previous存储之前的发射分数和转移分数的一个累加,obs存储当前位置的发射分数。
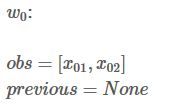
如果我们的句子只有一个单词,我们就没有之前步骤的结果,所以Previous 是空。我们只能观测到状态分数
o
b
s
=
[
x
01
,
x
02
]
obs = [x_{01},x_{02}]
obs=[x01,x02](状态矩阵见上方矩阵)
W
0
W_0
W0 的所有路径总分就是:
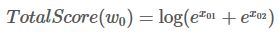
也就是说,当句子只有一个单词
w
0
w_0
w0时,其所有路径总分为TotalScore。
接着,我们计算当句子中有两个单词时,即计算
w
0
→
w
1
w_0 → w_1
w0→w1的所有路径总分。
在Previous里累加之前所得到的分数,而在obs中写入此刻的状态分数,进行计算所有路径总分。
以此类推,得到最终的所有路径总分,具体过程,看这里。
注意:
做预测的时候,整体过程和上述过程没有什么区别,唯一的区别就是每个时刻的Previous存储的是当前单词对应各类别的最佳路径得分!(使用维特比)
Bert-BiLSTM-CRF模型的损失函数是什么样子的 (直接背这个,上面不用看)
Bert-Bilstm它实际上的一个本质上的一个输出是 seq_len*标记数,假设我们是六个,那么这个输出矩阵就是 seq_len*6 这样的一个输出矩阵。这个输出矩阵便作为CRF的发射矩阵,那么CRF还有一个转移矩阵。
转移矩阵就是指的是之前的一个标记假设为B-person。那么此时的标记为I-person的这样的一个分数就叫做转移分数,以此类推,有这些转移分数就可以构造成整个这样的一个转移矩阵。
这里的转移分数矩阵,也正是为什么bert-bilstm需要加上CRF的一个原因,如果直接的bert-bilstm它这个输出。很有可能会出现b-person后面,紧接着b-organization这种情况。而加了CRF过后,有了这个转移分数矩阵。我们非常直观的可以从这个转移分数矩阵中看到。B-person,如果后面接的是。B-organization此时的这个转移分数是非常低的。这就在一定程度上对输出结果进行了约束、使其满足BIO标示符的规则。
那么我们知道从一个句子的左边到右边啊进行这个命名实体识别,实际上这个识别的结果是有着各种不同的组合,对于CRF来说,发射矩阵和转移矩阵参数化表示后其实就是各个权重和各个特征函数的乘积和(发射矩阵对应节点特征函数,转移矩阵对应局部特征函数),只有一个组合是正确的,我们的目标就是在最大化这个正确组合的概率。
以下损失函数具体方式没问的话,不要自己给自己挖坑,很复杂的!
这里损失函数的分子的计算,其实也是分成了两个部分,一个是发射的分数,一个是这个转移的分数嘛,对吧,刚刚也提到了这个发射矩阵和这个转移分数矩阵对吧,只不过是为了更加的这个啊,严谨是刚刚也是和这个CRF的这个参数表示进行一个对应,那么在训练过程当中的话,这个分子的这个真实路径,他的一个求解实际上就是由这个bert-bilstm它的这个输出的发射矩阵的分数,然后和这个啊,CRF本身的这个转移矩阵的这个分数啊相加,就完全可以得到这个分子的这个真实路径的分数。
而这里的分母的总体的这个啊,所有路径的一个分数,实际上他并不是要考虑所有路径的组合,而是使用一种动态规划的方式去进行一个分数的一个累加,分母,这里具体计算方式从左往右进行累加的话,当时他们主要是根据两个变量第一个变量,是啊计算当前这个状态的一个发射分数,那么,还有个变量是去计算啊,之前的这个发射分数和转移分数的一个累加。那么这样,通过不断地从左往右进行这样的一个不断的累积分数,最后达到最右边的时候,此时的这个分数,结果就是所有路径的一个分数的总和,具体计算方式是比较复杂,且涉及到行列式扩展等计算技巧。
为什么用Bert+BiLSTM+CRF这种结构?
(子问题1:为什么不直接用Bert + CRF?子问题2:为什么不直接用BiLSTM + CRF?)
先说下我个人觉得的效果:
BERT+BiLSTM +CRF比BiLSTM+CRF以及BERT+CRF效果好。但我自己没做过对比实验。
原因如下:
1.BERT+BiLSTM+CRF>BiLSTM+CRF多了一层BERT初始化word embedding,比随机初始化肯定要好,这个就不多解释了。
2.BERT+BiLSTM+CRF>BERT+CRF首先BERT使用的是transformer,而transformer是基于self-attention的,也就是在计算的过程当中是弱化了位置信息的(仅靠position embedding来告诉模型输入token的位置信息),而在序列标注任务当中位置信息是很有必要的,甚至方向信息也很有必要,所以我们需要用LSTM习得观测序列上的依赖关系,最后再用CRF习得状态序列的关系并得到答案,如果直接用CRF的话,模型在观测序列上学习力就会下降,从而导致效果不好。


