- 1VLC全部参数,libvlc_new函数参数,VLC SDK开发_vlc sdk gpu
- 2一文带你了解火遍全网的“AI大模型”_国内ai大模型涌现时间轴
- 3CSS核心样式-02-盒模型属性及扩展应用
- 4【数据结构】考研真题攻克与重点知识点剖析 - 第 8 篇:排序
- 5PMP学习重点笔记(项目资源管理)_资源管理pmp
- 6mysql指引(六):InnoDB的基本结构_mysql innodb 组织结构
- 7git push报错: Push rejected_git push rejected
- 8自学软件测试,没有项目经验,在西安找工作找了大半个月找不到,有点崩溃怎么办?
- 9通义千问-Qwen技术报告细节分享_qwen模型 隐藏层输出
- 10应用实战|使用DBGate管理MemFireDB数据库_dbgate字段提示
量化交易:传统小市值策略 VS AI市值策略_小市值策略提高夏普比
赞
踩
在BigQuant平台上可以快速开发股票传统策略和股票AI策略,今天拿市值因子来练手,看看两个策略在2015-01-01到2016-12-31这两年时间各自的收益风险情形。
市值因子是国内股票市场能够带来超额收益的alpha因子,已经被验证为长期有效的因子,也是广大私募基金常用的因子之一,传统的选股策略的股票组合大多在市值因子上有很大的风险暴露。希望了解多因子选股策略的小伙伴可以参考这篇报告:东方证券《因子选股系列研究之十》:Alpha因子库精简与优化-160812。
本文所介绍的传统小市值策略思想和操作都比较简单,就是选择市值最小的股票构建组合;而AI市值策略是通过策略生成器构建策略,采用StockRanker排序模型基于市值因子做预测选股,即AI市值策略只有一个特征:市值。
传统小市与AI小市策略
先看传统小市值策略的回测结果图:

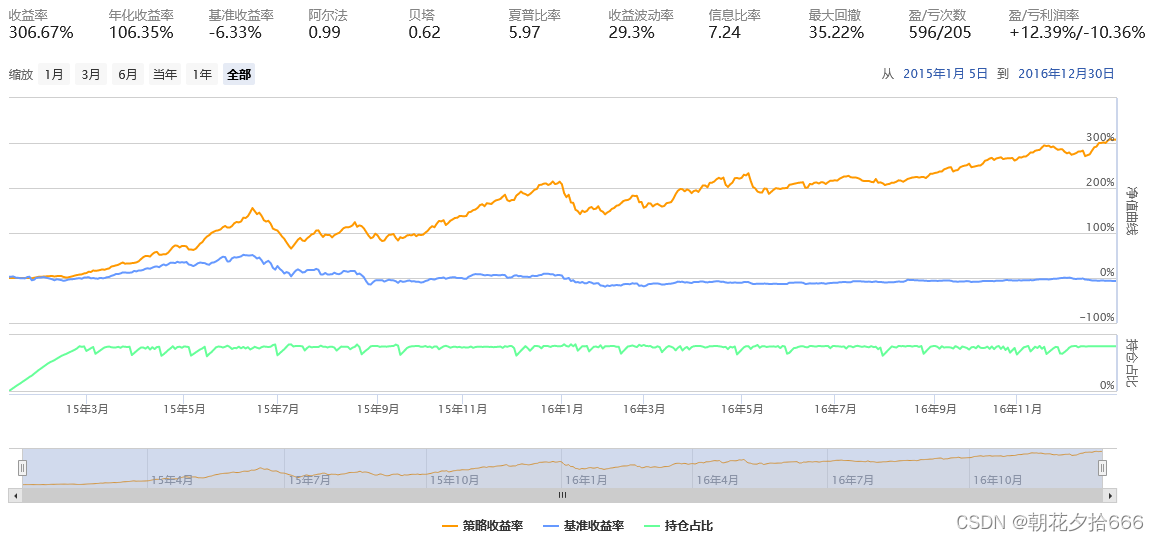
再看看AI市值策略回测结果图:
关注几个常用的指标来比较两个策略:

从总收益来看,AI市值策略收益达到了289.46%,也就是说,如果15年年初你开始按照这个策略交易,期初本金1000元的话,到2017年年初的时候,就增加到了3894.6元,收益达到了289.46%,是不是比自己主观交易强多啦。虽然收益这么高,但是最大回撤也不低啊,最大回撤为35.22%,这个指标可以这样理解,就是严格按照策略系统交易,资金跌得最恨的时候距离资金最高点相差35.22%,如果没有良好的心态和强大的心脏估计是无法继续坚持策略的,比如资金从2000元的高点跌倒了1300元,一般的人可是坐不住的啊。不过,正是做到了坚持,所以坚持到2017年初,最后取到了289.46%的总收益。AI市值策略的最大回撤比传统小市值策略略高。在收益率的波动性方面,两个策略差不多。专业的量化人员关注地比较多的指标是夏普比率,该指标表示每承受一单位总风险,会产生多少的超额报酬,可以同时对策略的收益与风险进行综合考虑,AI市值策略的夏普比率比传统小市值策略高,达到了5.77。
可以看出,虽然传统小市值策略也是一个不错的策略,因为15年初1000元的本金投资在2017年初可以增值到3120元。但是与AI市值策略相比,AI市值策略由于收益更高,而且传统小市值策略用的人比较多,现在大部分的私募公募都暴露在市值因子上,因此策略同质性比较强。再加上,我们还可以在开发AI策略的时候利用自己的专业知识和行业经验构造特征,因此AI策略整体上比传统策略更优。
传统小市值选股策略
- 根据总市值指标选择股票,选择市值最小的30只股票
- 每月调仓
- 等权重
# 获取股票代码
instruments = D.instruments()
# 确定起始时间
start_date = '2012-01-05'
# 确定结束时间
end_date = '2017-01-01'
market_cap_data = D.history_data(instruments,start_date,end_date,
fields=['market_cap','amount','suspended'])
# 根据是否停牌的字段确定每日选出来的股票
daily_buy_stock = market_cap_data.groupby('date').apply(lambda df:df[(df['amount'] > 0) # 需要有成交量
& (df['suspended'] == False) # 是否停牌
].sort_values('market_cap')[:30]) # 前三十只
# 回测参数设置,initialize函数只运行一次
def initialize(context):
# 手续费设置
context.set_commission(PerOrder(buy_cost=0.0003, sell_cost=0.0013, min_cost=5))
# 调仓规则(每月的第一天调仓)
context.schedule_function(rebalance,date_rule=date_rules.month_start(days_offset=0))
# 传入 整理好的调仓股票数据
context.daily_buy_stock = daily_buy_stock
# handle_data函数会每天运行一次
def handle_data(context,data):
pass
# 换仓函数
def rebalance(context, data):
# 当前的日期
date = data.current_dt.strftime('%Y-%m-%d')
# 根据日期获取调仓需要买入的股票的列表
stock_to_buy = context.daily_buy_stock.ix[date].instrument # 一定要转化为列表
# 通过positions对象,使用列表生成式的方法获取目前持仓的股票列表
stock_hold_now = [equity.symbol for equity in context.portfolio.positions]
# 继续持有的股票:调仓时,如果买入的股票已经存在于目前的持仓里,那么应继续持有
no_need_to_sell = [i for i in stock_hold_now if i in stock_to_buy]
# 需要卖出的股票
stock_to_sell = [i for i in stock_hold_now if i not in no_need_to_sell]
# 卖出
for stock in stock_to_sell:
# 如果该股票停牌,则没法成交。因此需要用can_trade方法检查下该股票的状态
# 如果返回真值,则可以正常下单,否则会出错
# 因为stock是字符串格式,我们用symbol方法将其转化成平台可以接受的形式
if data.can_trade(context.symbol(stock)):
# order_target_percent是平台的一个下单接口,表明下单使得该股票的权重为0,
# 即卖出全部股票,可参考回测文档
context.order_target_percent(context.symbol(stock), 0)
# 如果当天没有买入的股票,就返回
if len(stock_to_buy) == 0:
return
# 等权重买入
weight = 1 / len(stock_to_buy)
# 买入
for stock in stock_to_buy:
if data.can_trade(context.symbol(stock)):
# 下单使得某只股票的持仓权重达到weight,因为
# weight大于0,因此是等权重买入
context.order_target_percent(context.symbol(stock), weight)
# 回测接口
m=M.backtest.v5(
instruments=instruments,
start_date=start_date,
end_date=end_date,
# 必须传入initialize,只在第一天运行
initialize=initialize,
# 必须传入handle_data,每个交易日都会运行
handle_data=handle_data,
# 买入以开盘价成交
order_price_field_buy='open',
# 卖出也以开盘价成交
order_price_field_sell='open',
# 策略本金
capital_base=float("1.0e7") ,
# 比较基准:沪深300
benchmark='000300.INDX',
)

AI市值策略
- 每天买入AI(人工智能)算法推荐的5只股票
- 每天卖出得分最低的股票
- 开盘时,买入股票,收盘时卖出股票
# 基础参数配置
class conf:
start_date = '2010-01-01'
end_date='2017-01-20'
# split_date 之前的数据用于训练,之后的数据用作效果评估
split_date = '2015-01-01'
# D.instruments: https://bigquant.com/docs/data_instruments.html
instruments = D.instruments(start_date, end_date)
# 机器学习目标标注函数
# 如下标注函数等价于 max(min((持有期间的收益 * 100), -20), 20) + 20 (后面的M.fast_auto_labeler会做取整操作)
# 说明:max/min这里将标注分数限定在区间[-20, 20],+20将分数变为非负数 (StockRanker要求标注分数非负整数)
label_expr = ['return * 100', 'where(label > {0}, {0}, where(label < -{0}, -{0}, label)) + {0}'.format(20)]
# 持有天数,用于计算label_expr中的return值(收益)
hold_days = 30
# 特征 https://bigquant.com/docs/data_features.html,你可以通过表达式构造任何特征
features = [
'market_cap_0', # 总市值
]
# 给数据做标注:给每一行数据(样本)打分,一般分数越高表示越好
m1 = M.fast_auto_labeler.v5(
instruments=conf.instruments, start_date=conf.start_date, end_date=conf.end_date,
label_expr=conf.label_expr, hold_days=conf.hold_days,
benchmark='000300.SHA', sell_at='open', buy_at='open')
# 计算特征数据
m2 = M.general_feature_extractor.v5(
instruments=conf.instruments, start_date=conf.start_date, end_date=conf.end_date,
features=conf.features)
# 数据预处理:缺失数据处理,数据规范化,T.get_stock_ranker_default_transforms为StockRanker模型做数据预处理
m3 = M.transform.v2(
data=m2.data, transforms=T.get_stock_ranker_default_transforms(),
drop_null=True, astype='int32', except_columns=['date', 'instrument'],
clip_lower=0, clip_upper=200000000)
# 合并标注和特征数据
m4 = M.join.v2(data1=m1.data, data2=m3.data, on=['date', 'instrument'], sort=True)
# 训练数据集
m5_training = M.filter.v2(data=m4.data, expr='date < "%s"' % conf.split_date)
# 评估数据集
m5_evaluation = M.filter.v2(data=m4.data, expr='"%s" <= date' % conf.split_date)
# StockRanker机器学习训练
m6 = M.stock_ranker_train.v2(training_ds=m5_training.data, features=conf.features)
# 对评估集做预测
m7 = M.stock_ranker_predict.v2(model_id=m6.model_id, data=m5_evaluation.data)
## 量化回测 https://bigquant.com/docs/strategy_backtest.html
# 回测引擎:初始化函数,只执行一次
def initialize(context):
# 系统已经设置了默认的交易手续费和滑点,要修改手续费可使用如下函数
context.set_commission(PerOrder(buy_cost=0.0003, sell_cost=0.0013, min_cost=5))
# 预测数据,通过options传入进来,使用 read_df 函数,加载到内存 (DataFrame)
context.ranker_prediction = context.options['ranker_prediction'].read_df()
# 设置买入的股票数量,这里买入预测股票列表排名靠前的5只
stock_count = 5
# 每只的股票的权重,如下的权重分配会使得靠前的股票分配多一点的资金,[0.339160, 0.213986, 0.169580, ..]
context.stock_weights = T.norm([1 / math.log(i + 2) for i in range(0, stock_count)])
# 设置每只股票占用的最大资金比例
context.max_cash_per_instrument = 0.2
# 回测引擎:每日数据处理函数,每天执行一次
def handle_data(context, data):
# 按日期过滤得到今日的预测数据
ranker_prediction = context.ranker_prediction[context.ranker_prediction.date == data.current_dt.strftime('%Y-%m-%d')]
# 1. 资金分配
# 平均持仓时间是hold_days,每日都将买入股票,每日预期使用 1/hold_days 的资金
# 实际操作中,会存在一定的买入误差,所以在前hold_days天,等量使用资金;之后,尽量使用剩余资金(这里设置最多用等量的1.5倍)
is_staging = context.trading_day_index < context.options['hold_days'] # 是否在建仓期间(前 hold_days 天)
cash_avg = context.portfolio.portfolio_value / context.options['hold_days']
cash_for_buy = min(context.portfolio.cash, (1 if is_staging else 1.5) * cash_avg)
cash_for_sell = cash_avg - (context.portfolio.cash - cash_for_buy)
positions = {e.symbol: p.amount * p.last_sale_price for e, p in context.perf_tracker.position_tracker.positions.items()}
# 2. 生成卖出订单:hold_days天之后才开始卖出;对持仓的股票,按StockRanker预测的排序末位淘汰
if not is_staging and cash_for_sell > 0:
equities = {e.symbol: e for e, p in context.perf_tracker.position_tracker.positions.items()}
instruments = list(reversed(list(ranker_prediction.instrument[ranker_prediction.instrument.apply(
lambda x: x in equities and not context.has_unfinished_sell_order(equities[x]))])))
# print('rank order for sell %s' % instruments)
for instrument in instruments:
context.order_target(context.symbol(instrument), 0)
cash_for_sell -= positions[instrument]
if cash_for_sell <= 0:
break
# 3. 生成买入订单:按StockRanker预测的排序,买入前面的stock_count只股票
buy_cash_weights = context.stock_weights
buy_instruments = list(ranker_prediction.instrument[:len(buy_cash_weights)])
max_cash_per_instrument = context.portfolio.portfolio_value * context.max_cash_per_instrument
for i, instrument in enumerate(buy_instruments):
cash = cash_for_buy * buy_cash_weights[i]
if cash > max_cash_per_instrument - positions.get(instrument, 0):
# 确保股票持仓量不会超过每次股票最大的占用资金量
cash = max_cash_per_instrument - positions.get(instrument, 0)
if cash > 0:
context.order_value(context.symbol(instrument), cash)
# 调用回测引擎
m8 = M.backtest.v5(
instruments=m7.instruments,
start_date=m7.start_date,
end_date='2017-01-01',
initialize=initialize,
handle_data=handle_data,
order_price_field_buy='open', # 表示 开盘 时买入
order_price_field_sell='close', # 表示 收盘 前卖出
capital_base=2000000, # 初始资金
benchmark='000300.SHA', # 比较基准,不影响回测结果
# 通过 options 参数传递预测数据和参数给回测引擎
options={'ranker_prediction': m7.predictions, 'hold_days': conf.hold_days}
)