
- 1位图是什么_易语言 位图对比
- 22021年总结:缘起性空,归来不少年——回顾这荆棘的一年_我这一年博客
- 3【AI大模型实战】CVP架构:企业级知识库落地之路
- 4rpm包打包过程详解(二)——制作源代码安装包
- 5关于Tensorflow安装 测试应用以及在PyCharm中的应用_tensorflow可以用于pycharm吗
- 6数字人客服:人机互动的新时代
- 7科大讯飞星火大模型接入API js 部分 接口 安装注意事项_讯飞星火api
- 8如何将内部多个仓库上传到GitHub的一个仓库中(嵌套关系)_git多个项目放在一个仓库不通目录中
- 9智能计算自制题库_通用服务器是基于pc机体系结构
- 10Java 网络编程 —— Socket 详解_java客户端和服务端的socket编程
AnalyticDB 如何支撑数据银行超大规模低成本实时分析_数据银行测试付费渠道人群成本
赞
踩
前言
数据银行是一款品牌消费者运营的商业数据产品,由于其核心分析能力需要在海量数据上实现任意维度自由分析和响应时间上的强需求,我们大规模使用AnalyticDB作为底层的分析引擎,最终以较低的成本,出色的性能,支撑了上万品牌商大促期间每天百万级的OLAP查询。
当前数据银行在AnalyticDB中存储了约几十万亿条数据,占用存储空间约1.6P,查询平均响应时间在5秒以内。
数据银行业务介绍
数据银行作为消费者运营的商业数据产品,提供了链路流转分析、人群圈选、人群画像等众多数据能力。
链路流转分析
AIPL是数据银行的特有指标,用于衡量品牌和消费者关系的指标(AIPL是4个阶段的缩写,分别是A认知、I兴趣、P购买、L忠诚),链路流转分析用于获取品牌任意两天消费者AIPL关系的变化(如下图,某品牌在某个类目下,从去年双十一到今年双十一AIPL的变化,非真实数据)。
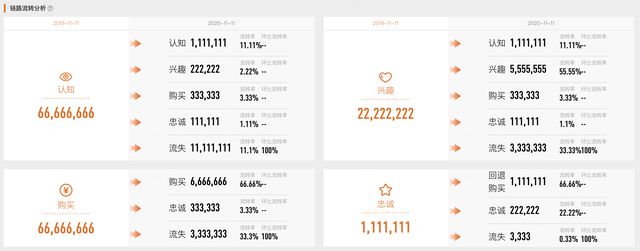
在这个场景,用户可以选择近540天内的任意两个日期,加上品牌和类目这两个维度,用户可能的输入情况在百万亿级别。
人群画像
人群画像是消费者运营产品的核心能力,数据银行除了可以针对用户沉淀的具体人群进行画像操作,还可以对链路流转的人群进行画像以帮助品牌分析消费者关系变化的原因(如下图,某品牌去年双十一是购买状态但今年双十一是流失状态的人群画像,非真实数据)。
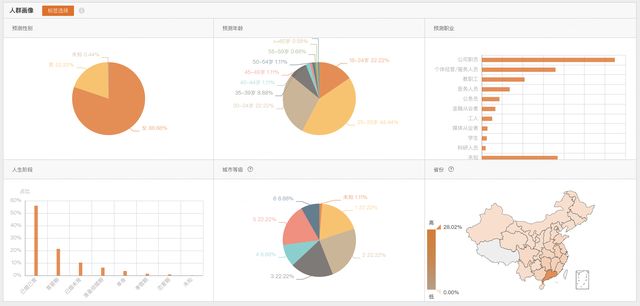
在这个场景,数据银行为用户提供了200多个标签,大部分为行业相关,每次人群画像只会涉及到部分标签,如果为人群预先计算所有标签会导致资源的极大浪费。
人群圈选计算人数 / 人群圈选
人群圈选是消费者运营产品的核心能力,相比大部分消费者运营产品限制用户只能使用标签数据,数据银行人群圈选(分钟级)可以让用户使用标签、触点(可以理解为消费者行为,如购买、搜索、看直播等)等各类数据,同时用户还可以即时查看圈选条件下消费者的数量(秒级)。

在这个场景,各类圈选条件可以通过交并差自由组合,同时部分圈选条件如购买金额是让用户填写的数值,无法枚举。
数据银行为什么选择AnalyticDB
普通的分析业务,如果对响应时间没有要求,离线计算(Hadoop/Hive/Maxcompute)几乎可以满足所有数据分析的需要,但是从用户在线响应的角度出发,高频使用的功能对响应时间都会有强需求。
例如:用户决策需要大量人群画像的对比,而人群的选择存在一定的依赖关系,下一个画像人群的选择取决于前一个人群画像的结果。如果采用离线计算,不仅会大幅度拉长用户的决策时间,还会打断用户分析思维的连续性,对用户体验产生较大的影响。
解决响应时间问题一般有两种思路:
- 预计算,把用户所有可选维度组合下的指标先离线计算出来,用户在分析时,系统直接去数据库取结果。
- OLAP在线计算,把轻度聚合的数据(保留所有用户可选维度)存放在MPP引擎中,根据用户提交的条件,即时计算出指标。
这两种思路各有特点,预计算需要考虑维度爆炸、离线预计算无法在有限时间内完成、或者是需求变化导致预先计算的结果没有被使用导致的资源浪费等一系列问题。而OLAP能够提任意维度的自由计算,无需预先计算,但则也需要考虑MPP引擎的存储成本、容量和计算性能等问题。
综合来看,作为面向消费者运营的数据产品,对响应时间有强需求,不适合使用预计算的情况;同时因为数据量巨大(几十万亿、PB级别),整体的成本也是一个重要的考虑点。
OLAP引擎选型
数据银行的OLAP有几大挑战:
- 数据量上的挑战:原始数据量非常庞大,历史数据总量有1.6PB、22万亿条记录,其中10张以上的万亿级大表,全部存储在AnalyticDB中。
- 数据写入性能上的挑战:单日新增写入量600亿行记录,总大小10TB,其中基线任务在每天早晨7:00 - 9:00两小时内完成导入,要求导入速度至少为千万级的tps;
- 复杂查询性能上的挑战:查询类型复杂,多为较大的复杂交互分析,2万亿级别的大表经过筛选后再与8张表做关联,需要在10秒内返回。
- 导出性能上的挑战:快速的结果集导出,业务中需要将分析圈选的人群做数据导出。需要能够将AnalyticDB计算好的结果便捷、高效的导出到Maxcompute中。并且要求能够支撑每分钟20个以上的百万级结果导出任务。
- 成本上的挑战:考虑到PB级的数据,全部存储到SSD成本太高,因此希望系统具备冷热数据分层存储能力,用接近离线的价格实现在线的性能。
- 稳定性上的挑战:复杂的工作负载,在真实线上场景,上面提到的3个挑战会同时出现,要求能够在这种复杂的workload下系统平稳运行。
通过前期技术调研和测试,选择AnalyticDB作为数据银行业务分析的基础平台,具体如下:
1.冷热数据分层能力
AnalyticDB提供的数据冷热分离这一企业级特性,可以大幅提升数据存储的性价比。可以按表粒度选择热表(存的在ESSD)、冷表(存储在OSS)和温表(混合方式,部分存在ESSD,部分存储在OSS)存储,客户完全可以按业务需求自由指定,并且冷热策略可以任意转换,对用户来说是一份存储,一套语法,轻松实现联合查询。我们使用的场景更多的是冷表为主,而且AnalyticDB针对冷表具有SSD Cache来做加速,降低成本的同时兼顾了性能。数据银行在AnalyticDB中存储几十万亿条数据,占用存储空间约2P,已经成为数据银行的核心数仓存储,而预计未来会继续增长。
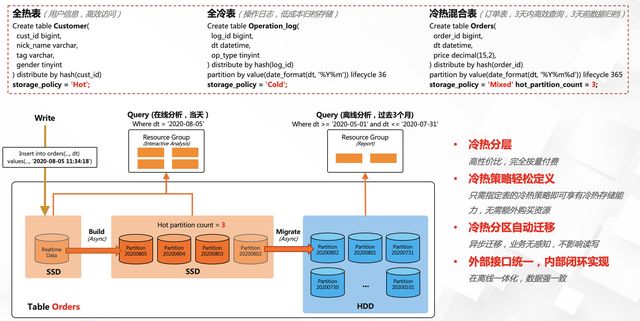
2.高吞吐实时写入
AnalyticDB底层采用分布并行的架构,实现了极高的写入/导入吞吐,海量数据可以直接以千万级甚至亿级tps实时写入。同时针对离线聚合过的表,AnalyticDB提供了直通的batch load方式可以高吞吐直接加载数据进行在线查询。
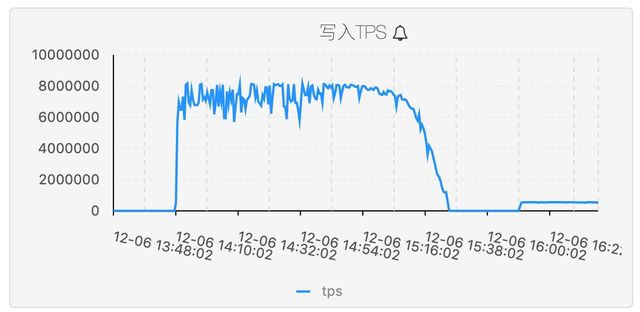
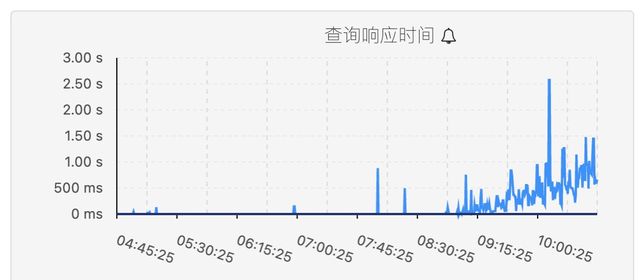
强大的高并发、低延时实时计算能力。
三类业务查询场景下对响应时间都是强需求,查询大部分是万亿大表圈选后的聚合和连接查询,AnalyticDB使用冷数据缓存、预热等技术,使这些查询的平均响应时间在10秒以下。
数据模型和表设计
数据银行主要在AnalyticDB中存储四类数据:
1、AIPL数据,即品牌和消费者关系
2、标签数据,即消费者属性
3、触点数据,即消费者行为
4、人群数据,即数据银行用户在数据银行沉淀的人群
由于所有场景的分析对象都是消费者ID,所以大部分表都以消费者ID为分布键,这样可以最大避免查询过程中的数据shuffle(重分布)。以下主要介绍AIPL和标签的表设计,触点和人群的表设计类似,不再赘述。
1、AIPL数据
AIPL数据按天分区,但由于每天产生的数据量较大(500多亿),即使AnalyticDB批量导入性能较为突出,仍然需要较长的导入时间,考虑到AnalyticDB不支持多级分区,我们将AIPL表从品牌维度拆分为20张子表,一方面提升导入性能,另一方面也能提升查询性能。
数据银行除了在品牌维度提供AIPL分析,用户还可以下钻到二级类目维度,要支持二级类目有两种方案:
1、在原有的AIPL表上扩展二级类目维度
2、新增一套包含二级类目维度的AIPL表
第一种方案更节省存储空间,也只需要导入一套表;第二种方案的查询性能更好。
经过验证,我们使用了第二种方案,不包含二级类目的查询在数据银行中占了较大比重,当查询不包含二级类目时,第一种方案需要group by 消费者ID,执行过程会占用较大内存,可承载的并发度较低,性能也较差。得益于AnalyticDB较低的存储成本,使用第二种方案在并没有导致成本大幅度增长。
同时由于品牌ID是查询时必带的维度,而AIPL状态是高频使用的维度,所以在建表时将品牌ID和AIPL状态设置为聚集列可以有效降低查询IO,提升查询性能。
两组表的表结构如下(示意):
- -- 不带二级类目维度的aipl表
- CREATE TABLE `aipl_[001-020]` (
- `customer_id` bigint,
- `brand_id` bigint,
- `aipl_status` int,
- `day` bigint
- )
- DISTRIBUTE BY HASH(`customer_id`)
- PARTITION BY VALUE(day)
- CLUSTERED BY (`brand_id`,`aipl_status`)
-
- -- 带二级类目维度的aipl表
- CREATE TABLE `aipl_cate_[001-020]` (
- `customer_id` bigint,
- `brand_id` bigint,
- `cate_id` bigint,
- `aipl_status` int,
- `day` bigint
- )
- DISTRIBUTE BY HASH(`customer_id`)
- PARTITION BY VALUE(day)
- CLUSTERED BY (`brand_id`,`cate_id`, `aipl_status`)

2、标签
一般由于有多值标签存在(例如一个消费者可以有多个兴趣爱好),标签表会设计为kv结构,如下(示意):
- CREATE TABLE `tag` (
- `customer_id` bigint,
- `tag_key` int,
- `tag_value` int
- )
- DISTRIBUTE BY HASH(`customer_id`)
但是数据银行在人群圈选时是可以选择多个标签进行交并差的,使用kv结构会导致多个标签值的消费者ID集合在内存中做交并差,性能较差。
利用AnalyticDB的多值列(multivalue/或者json列),数据银行的标签表的表结构如下(示意):
- CREATE TABLE `tag` (
- `customer_id` bigint,
- `tag1` int,
- `tag2` int,
- `tag3` multivalue,
- ......
- )
- DISTRIBUTE BY HASH(`customer_id`)
多个标签的交并差在底层会转换成标签表的AND / OR关系。但是由于标签较多,200多列的表不仅在导入性能上较慢,同时由于填入了较多的空值(customer_id在某个标签下如果没有值,会填充特定的值)导致数据膨胀得较为厉害,所以类似于AIPL的拆分,标签表也按不同的主题拆分成了十几张表。
人群圈选加速
数据银行会将用户圈选的人群固化下来(即保存消费者ID列表)用于后续操作,由于人群圈选会涉及到数十个子查询的交并差,圈选的时间长,中间结果可能会很大,所以数据银行会把一次圈选拆分为多个查询分片,发送到ADB执行,最后将每个分片的查询结果(消费者ID列表)在ETL中进行交并差,完成人群圈选。
整个人群圈选过程充分利用了ADB的索引能力和在离线混合负载能力,不但能加快人群圈选的速度,还能提高整体资源的利用率,特别是条件筛选率较高的查询(如涉及到AIPL的人群圈选)。同时ADB的云原生弹性能也能轻松应对双十一的峰值压力。
业务价值
总体来说,AnalyticDB对数据银行的业务价值主要体现在如下几个方面:
1、高性能的OLAP引擎:在数据银行高达22万亿条数据,占用1.6P存储空间的背景下,实现了平均3-5秒的查询响应,支撑数据银行秒级OLAP的产品实现,为用户提供了灵活高效的分析工具。
2、成本大幅下降:数据在使用AnalyticDB冷热分层存储后+按量付费模式后,在保证性能的同时,使用成本大幅下降,相比上一代版本,成本下降约46%。
3、应对大促的弹性能力,数据银行基于AnalyticDB实现的混合人群圈选模式,在大促期间,利用AnalyticDB的云原生弹性能力,可以实现快速扩展资源以应对峰值。
作者:崚嶒(杨然)数据技术及产品部-高级技术专家
本文为阿里云原创内容,未经允许不得转载。

