
- 1机器学习鸢尾花使用csv
- 2PostgreSQL 聚合函数讲解 - 3 总体|样本 方差, 标准方差_pg数据库求方差函数
- 3用c语言小游戏代码大全,c语言经典游戏代码
- 4Servlet的Cookie和Session机制_servlet cookie session
- 5【鸿蒙开发】第九章 ArkTS语言UI范式-状态管理(一)_鸿蒙强制刷新状态
- 6c语言链表和fifo,HDL的RAM与FIFO <===> C的数组与链表
- 7LeetCode 134. Gas Station (贪心)
- 8HMAC-SHA256 算法介绍_hmacsha256
- 9flask服务中如何request获取请求的headers信息
- 1007爬虫-selenium其它使用方法1,标签切换、窗口切换_爬虫浏览器对象怎么切换
Elasticsearch:图解写入流程_elasticsearch写入流程
赞
踩
一、Elasticsearch概述:
Elasticsearch是一个功能强大、性能高效、易于使用和扩展的分布式搜索和分析引擎,已被广泛应用于日志分析、企业搜索、电子商务等领域。
Elasticsearch是一个基于Lucene的分布式搜索和分析引擎,它能够快速存储、搜索和分析大量的数据。它支持多种数据类型的存储和检索,包括结构化、半结构化和非结构化数据。Elasticsearch具有以下特点:
-
分布式架构:Elasticsearch是一个分布式系统,数据可以分散在多个节点上,从而提高了数据的可用性和可扩展性。
-
实时搜索和分析:Elasticsearch支持实时搜索和分析,可以快速响应查询请求,帮助用户快速地找到需要的信息。
-
支持多种数据源:Elasticsearch支持多种数据源的数据导入和同步,包括数据库、日志文件、网络数据等。
-
易于使用和扩展:Elasticsearch具有易于使用和扩展的特点,通过简单的API可以实现搜索、聚合、过滤等多种功能,同时也支持插件扩展,可以方便地实现自定义功能。
-
开源免费:Elasticsearch是一个开源的软件,可以免费使用和部署,同时也有丰富的社区支持和文档资料。
二、理解Elasticsearch写入过程的必要性:
学习Elasticsearch的写入过程可以帮助我们更好地理解和应用这项技术,从而优化其性能,提高数据的可用性和可扩展性,实现更高效的搜索和分析。
-
更好地理解Elasticsearch的工作原理:通过学习Elasticsearch的写入过程,可以深入了解Elasticsearch是如何处理和存储数据的,有助于更好地理解其工作原理。
-
提高数据的可用性和可扩展性:Elasticsearch将索引数据分成多个分片,每个分片可以分布在不同的节点上,这样可以提高数据的可用性和可扩展性。
-
优化写入性能:了解Elasticsearch的写入过程可以帮助我们优化写入性能,例如通过合理的分片策略、调整刷新间隔等方式提高写入效率。
-
提高搜索效率:Elasticsearch的搜索效率与其写入效率密切相关,通过了解写入过程,可以更好地优化搜索效率,例如通过合理的分片策略、调整合并策略等方式提高搜索效率。
三、Elasticsearch写入流程图:
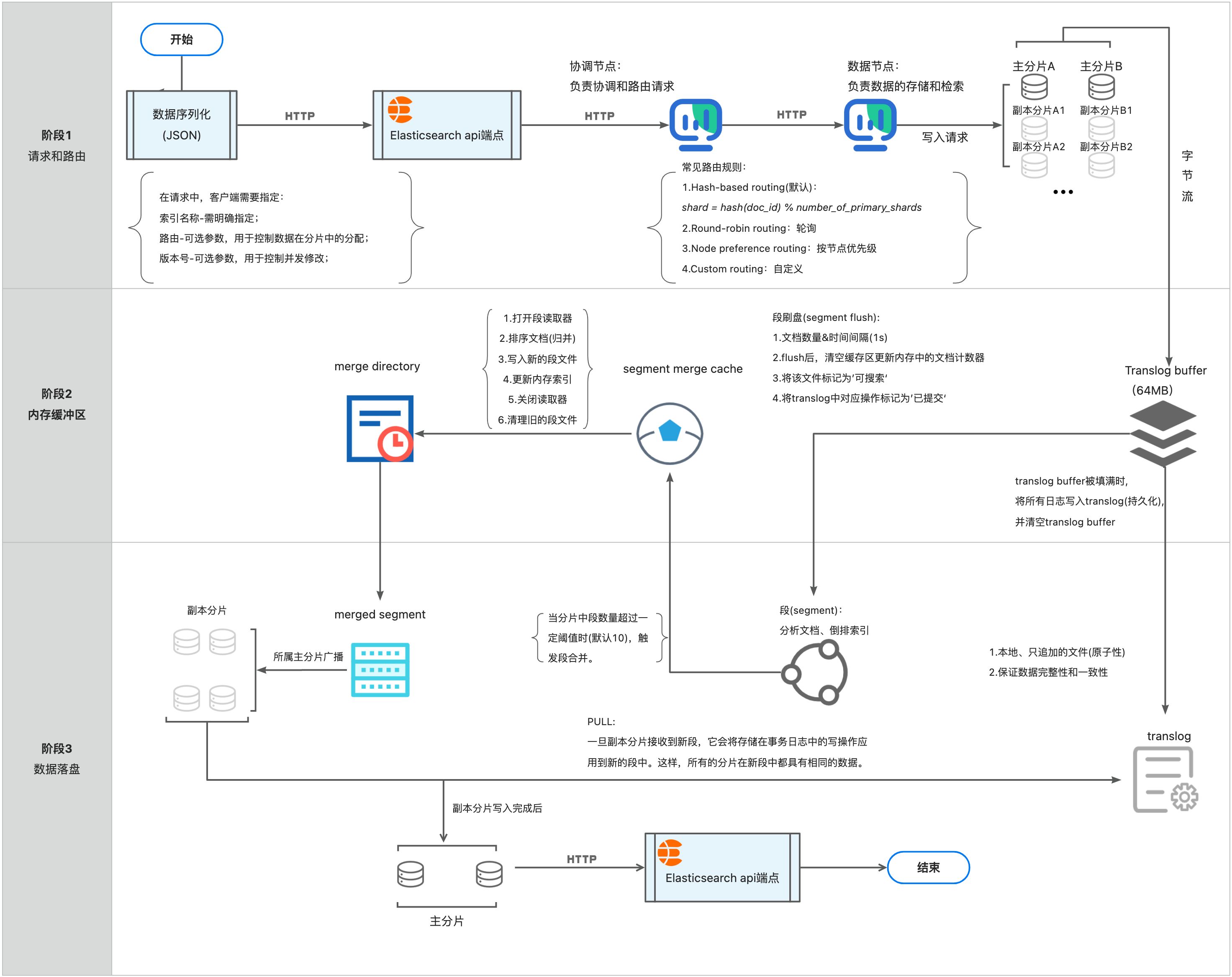
四、Elasticsearch写入流程简述:
-
客户端将数据序列化后以http的方式发送到elasticsearch api端点;
-
elasticsearch api端点以http的方式发送至协调节点;
-
协调节点通过路由规则讲写入请求发送至数据节点;
-
数据节点将写入请求落在主分片上;
-
主分片将序列化之后的数据转成字节流写入translog buffer;
-
当translog buffer被填满时,将所有日志写入translog进行持久化,并清空translog buffer;
-
当文档数量与时间间隔达到规定阈值时,进行flush操作,创建一个新的文件segment,将translog buffer的数写入segment;
-
当分片中segment的数量操作一定阈值时(默认10),当前数据节点会在内存中开辟一个空间,叫做segment merge cache ,会把将要合并的segment的内容读取写入新的段文件,这个段文件存储在merge directory;
-
最终这个merge directory会落盘,叫做merged segment;
-
merged segment所属主分片会进行广播,通知它的副本分片有一个新的段;
-
这些副本分片收到广播后,会检查是否缺少这个新的段,如果缺少,副本分片会将存储在事务日志中的写操作应用到新的段中;
-
待副本分片写入完成后,通知主分片写入完成;
-
主分片以http的方式发送写入完成的信息给elasticsearch api端点;
-
elasticsearch api端点再将结果信息返回给客户端;

