
- 1真正的软件测试实习2_可以实习测试的app
- 2Verilog编程网站学习——门电路、组合电路、时序电路_verilog 组合电路和时序电路
- 3个人自我简介_csdn开篇自我介绍
- 4【用户投稿】Apache SeaTunnel 2.3.3+Web 1.0.0版本安装部署
- 5已经30岁了,到底还能不能转行当程序员?_30岁以上还能干编程吗
- 6Redis与MySQL双写一致性:一场速度与稳定性的较量_mysql的双写机制性能
- 7SpringBoot整合Lombok以及各种使用技巧
- 8Springboot使用kafka事务-生产者方_chainedkafkatransactionmanager
- 9【MySQL数据库原理】MySQL Community安装与配置_mysql installer-community
- 10NLP(10)--TFIDF优劣势及其应用Demo
Stability AI发布Stable Code 3B模型,没有GPU也能本地运行
赞
踩
点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
Column of Computer Vision Institute
Stable Code 3B 的性能优于类似大小的代码模型,并且与 CodeLLaMA 7B 的性能相当,尽管其大小只有 CodeLLaMA 7B 的 40%。

在文生图领域大火的 Stability AI,今天宣布了其 2024 年的第一个新 AI 模型:Stable Code 3B。顾名思义,Stable Code 3B 是一个拥有 30 亿参数的模型,专注于辅助代码任务。
无需专用 GPU 即可在笔记本电脑上本地运行,同时仍可提供与 Meta 的 CodeLLaMA 7B 等大型模型具有竞争力的性能。

2023 年底,Stability AI 便开始推动更小、更紧凑、更强大模型的发展,比如用于文本生成的 StableLM Zephyr 3B 模型。
随着 2024 年的到来,Stability AI 开年便马不停蹄的发布 2024 年第一个大型语言模型 Stable Code 3B,其实这个模型早在去年八月就发布了预览版 Stable Code Alpha 3B,此后 Stability AI 一直在稳步改进该技术。新版的 Stable Code 3B 专为代码补全而设计,具有多种附加功能。
与 CodeLLaMA 7b 相比,Stable Code 3B 大小缩小了 60%,但在编程任务上达到了与前者相媲美的性能。
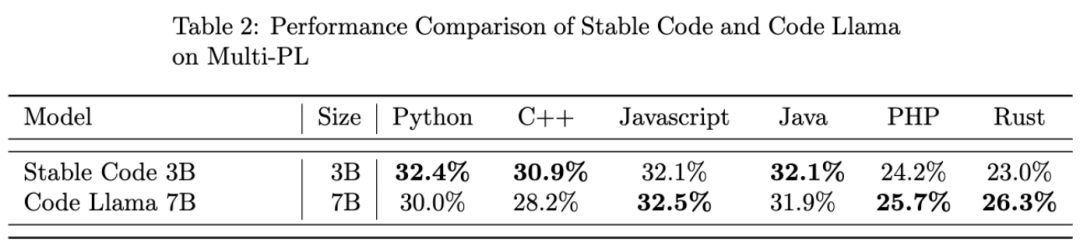
Stable Code 3B 在 MultiPL-E 基准上实现了 SOTA 性能(与类似大小的模型相比),例如 Stable Code 3B 在 Python、C++、JavaScript、Java、PHP 和 Rust 编程语言上的性能优于 StarCoder。
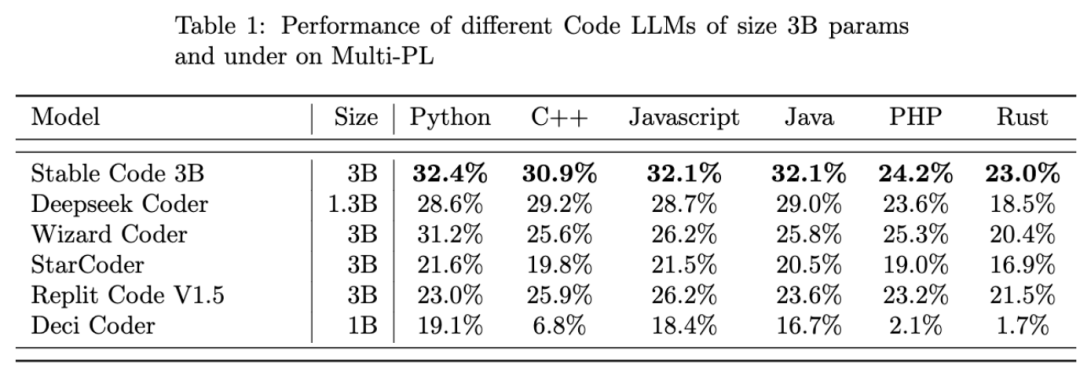
研究介绍
Stable Code 3B 基于 Stable LM 3B 训练而成,而 Stable LM 3B 训练 token 数达到 4 万亿,更进一步的,Stable Code 使用了软件工程中特定的数据(包括代码)进行训练。
Stable Code 3B 提供了更多的特性,即使跨多种语言也表现良好,还兼具其他优势,比如支持 FIM(Fill in the Middle ,一种新的训练技巧)功能,还能扩展上下文大小。基础 Stable Code 在多达 16,384 个 token 序列上进行训练,遵循与 CodeLlama 类似的方法,即采用旋转嵌入(Rotary Embeddings),这种方法可以选择性的允许修改多达 1,000,000 个旋转基(rotary base),进一步将模型的上下文长度扩展到 100k 个 token。
在模型架构方面,Stable Code 3B 模型是一个纯解码器的 transformer,类似于 LLaMA 架构,并进行了以下修改:

位置嵌入:旋转位置嵌入应用于头嵌入维度的前 25%,以提高吞吐量;
Tokenizer:使用 GPTNeoX Tokenizer.NeoX 的修改版本,添加特殊 token 来训练 FIM 功能,例如 < FIM_PREFIX>、<FIM_SUFFIX > 等。
训练
训练数据集
Stable Code 3B 的训练数据集由 HuggingFace Hub 上提供的开源大规模数据集过滤混合组成,包括 Falcon RefinedWeb、CommitPackFT、Github Issues、StarCoder,并进一步用数学领域的数据补充训练。
训练基础设施
硬件:Stable Code 3B 在 Stability AI 集群上使用 256 个 NVIDIA A100 40GB GPU 进行训练。
软件:Stable Code 3B 采用 gpt-neox 的分支,使用 ZeRO-1 在 2D 并行性(数据和张量并行)下进行训练,并依赖 flash-attention、SwiGLU、FlashAttention-2 的旋转嵌入内核。
最后,我们看一下 Stable Code 3B 的性能表现:
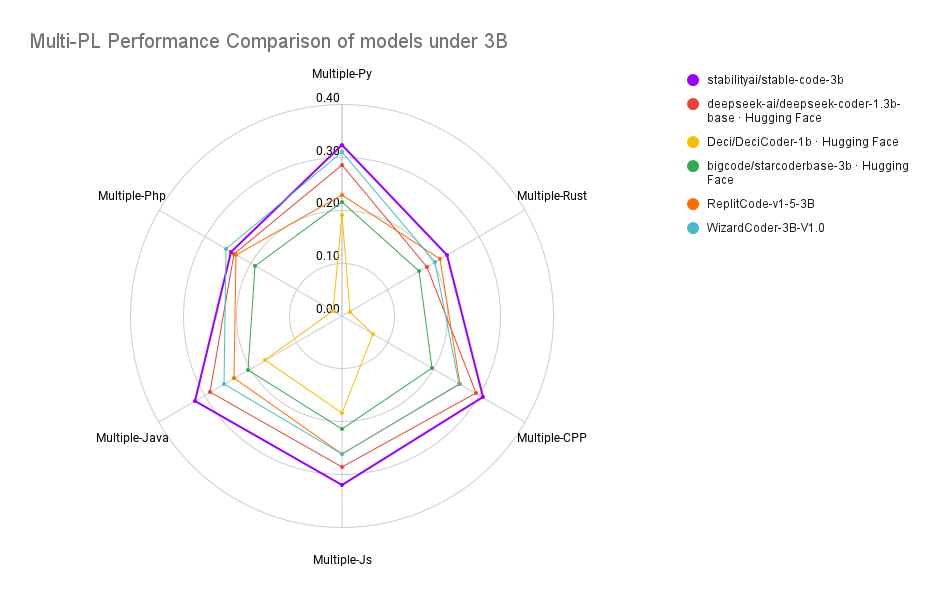
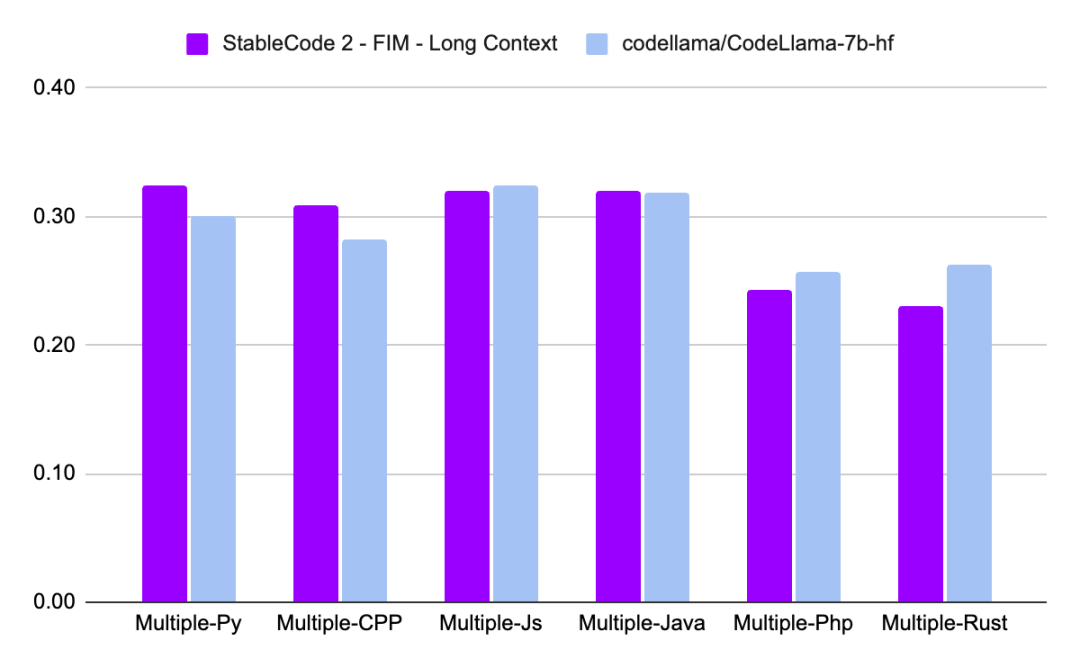
关于 Stable Code 3B 更详细的技术报告会在之后发布,大家可以期待一下。
参考链接:https://stability.ai/news/stable-code-2024-llm-code-completion-release?continueFlag=ff896a31a2a10ab7986ed14bb65d25ea

END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
往期推荐
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

