
- 1单点登录、统一认证_单点登录和统一认证区别
- 2免费的chatgpt网站(包含最新版4.0)_yeschat-chatgpt4v dalle3 claude 3 all in one free
- 3Flink的部署和运行_目前flink部署云端吗
- 4如何在 CentOS 7 上为 Nginx 创建自签名 SSL 证书
- 5Android 10 适配攻略_sdkmanager android 10
- 6树莓派3 基于Ubuntu mate 16.04的调用中文输入法_ubuntu mate 16.04中文shurufa
- 7RTLinux的介绍_rtlinux性能
- 8JUC之ReentrantLock(二)
- 9转载:hive清空外部表的三种方式_hive删除外部表数据
- 10Opentsdb简介
分布式资源管理与任务调度框架Yarn_负责分布式资源调度与管理
赞
踩
Yarn简介
1、Yarn是什么
-
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)
-
一种新的Hadoop资源管理器,一个通用资源管理系统
-
为上层提供统一的资源管理与任务调度及监控,提高了集群管理效率、资源使用率、数据共享效率
2、产生背景
在Hadoop1.x中MapReduce是Master/Slave结构,在集群中的表现形式为:1个JobTracker带多个TaskTracker,我们称之为MRv1。
Master:是整个集群的唯一全局管理者,功能包括:作业管理、状态监控和任务调度等即MapReduce中的JobTracker。
Slave:负责任务的执行和任务状态的汇报,即MapReduce中的TaskTracker。
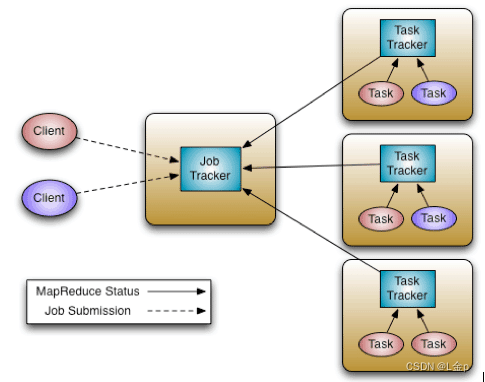
MRv1包括三个部分:运行时环境(JobTracker和TaskTracker)、编程模型(MapReduce)和数据处理引擎(Map任务和Reduce任务)。
JobTracker主要功能:
-
资源管理,协调平衡集群中的计算节点,合理分配。
-
任务调度,一个作业对应多个任务,负责任务调度、状态监控、容错管理等。
TaskTracker主要功能:
-
执行任务,响应JobTracker命令,如启动、停止任务等
-
汇报心跳:汇报节点健康状况、资源使用情况等。汇报任务执行进度、任务运行状态等。
MRv1存在的主要问题:
-
JobTracker单点故障,如果它挂掉,整个系统无法运转
-
JobTracker负载过重,限制了集群扩展,随着节点规模的增大,成为集群的瓶颈
-
仅支持MR计算框架,适合批处理、基于磁盘的计算
-
资源与计算没有很好的解耦设计,一个集群只能使用一个计算框架,如Hadoop&MapReduce集群、Spark集群、Tez集群等。造成管理复杂、资源利用率低的难题
综上所述MRv1有以上缺陷:扩展性受限、单点故障、难以支持MR之外的计算框架。多计算框架各自为战,数据共享困难,资源利用率低。这些因素催生了Yarn的产生。
3、Yarn特点
-
资源管理与计算框架解耦设计,一个集群资源共享给上层各个计算框架,按需分配,大幅度提高资源利用率
-
运维成本显著下降,只需运维一个集群,同时运行满足多种业务需求的计算框架
-
集群内数据共享一致,数据不再需要集群间拷贝转移,达到共享互用
-
避免单点故障、集群资源扩展得到合理解决
4、Yarn应用
需要统一资源管理和任务调度的平台均可以使用,已成为大数据集群的必备组件之一。
Yarn架构设计
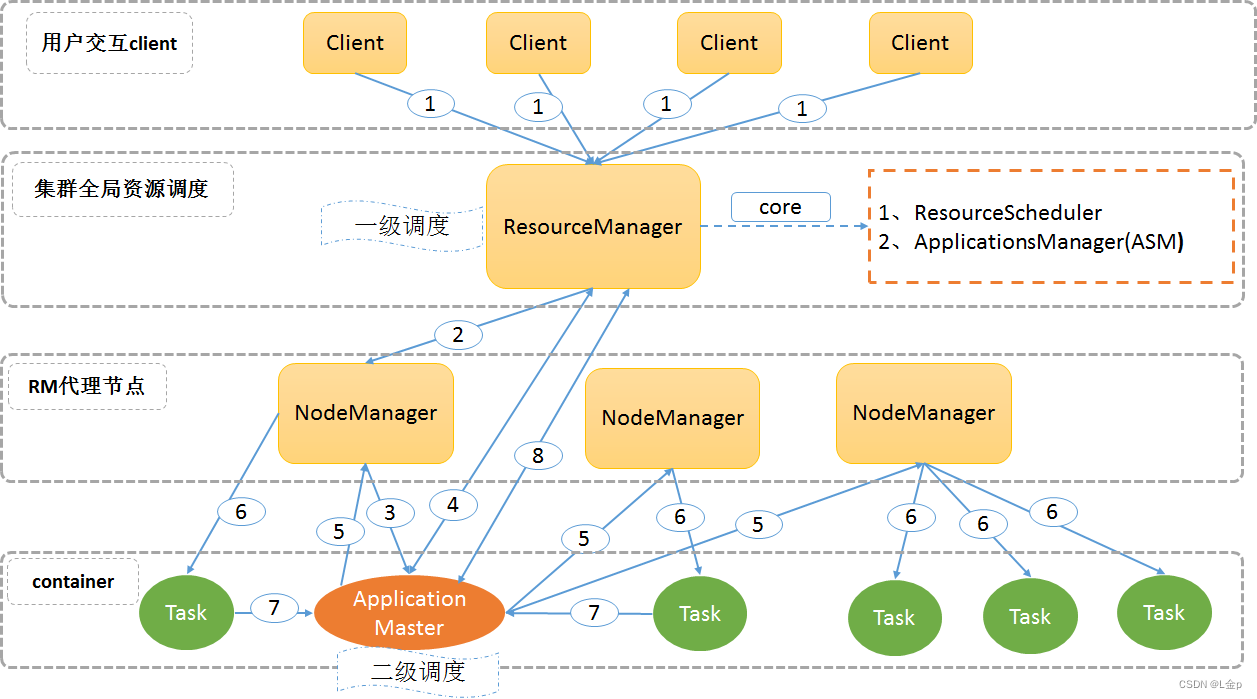
1、架构设计图
Yarn设计的核心思想是将JobTracker的两个主要职责:资源管理和任务调度管理,分别交给两个角色负责。
一个是全局的ResourceManager,一个是每个应用中唯一的ApplicationMaster。
ResourceManager以及每个节点一个的NodeManager构成了新的通用系统,实现以分布式方式管理应用。
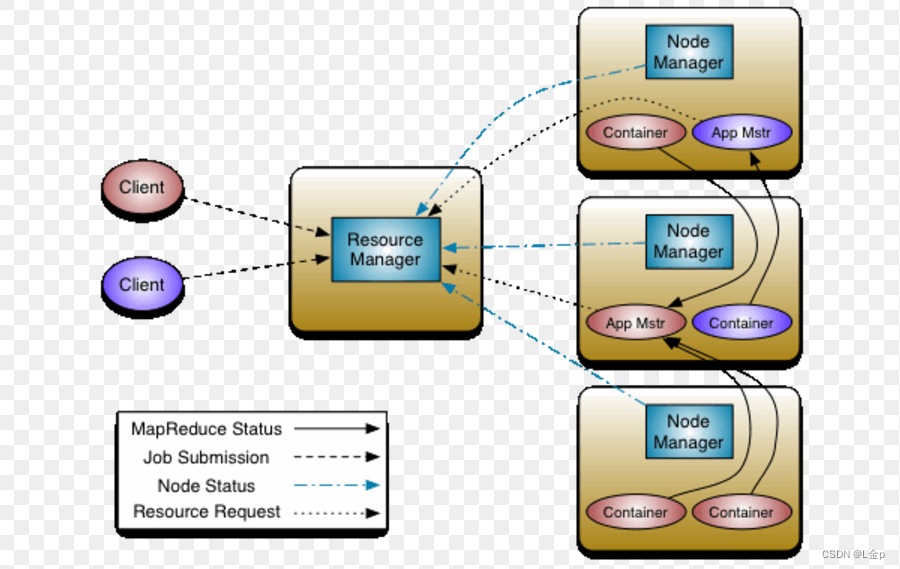
2、基本组成
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave。YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成。
2.1概略介绍
-
Master/Slave结构,1个ResourceManager和多个NodeManager
-
Yarn由Client、ResourceManager、NodeManager、ApplicationMaster组成
-
Client向ResourceManager提交启动任务、杀死任务等命令请求
-
ApplicationMaster由对应的计算框架编写的应用程序完成。每个应用程序对应一个ApplicationMaster,ApplicationMaster向ResourceManager申请资源用于在NodeManager上启动相应的Task
-
NodeManager向ResourceManager通过心跳信息汇报NodeManager监控状况、任务执行状况、领取任务等
2.2详细介绍
-
Client:面向用户提交的Driver代码,作为用户编程的接口,与ResourceManager交互。
-
ResourceManager:整个集群只有一个是存活(active)的,负责集群资源的统一管理和调度
-
负责整个集群的资源分配和调度
-
处理来自客户端的请求,启动、杀死应用程序
-
启动、监控ApplicationMaster,一旦一个AM挂了之后,RM将会在另一个NodeManager上启动该AM
-
监控NodeManager,接收NM的心跳汇报信息,获取NM的资源使用情况和Container运行状态
-
NodeManager:整个集群中有多个,负责单节点资源管理和使用。
-
负责单个节点上的资源管理和任务调度
-
处理来自ApplicationMaster的命令
-
接收并处理来自ResourceManager的Container启动、停止的各种命令,主要是对ApplicationMaster相关的操作。
-
周期性向ResourceManager汇报本节点上的资源使用情况和Container的运行状态
-
ApplicationMaster:每个应用程序特有,负责应用程序的管理
-
数据切分
-
为应用程序/作业向ResourceManager申请资源(Container),并分配给内部任务
-
与NodeManager通信以启动、停止任务
-
任务监控和容错(在任务执行失败时重新为该任务申请资源以重启任务)
-
处理ResourceManager发来的命令,让NodeManager重启任务、杀死Container等
-
Container:对任务运行环境的抽象
-
任务运行资源的抽象,封装了某个节点上的多维度资源,如内存、cpu、磁盘、网络等
-
任务命令启动、停止的执行单元
-
任务运行环境,任务运行在Container中,一个Container中既可以运行ApplicationMaster也可以运行具体的MapReduce、MPI、Spark等任务
3、运行流程
3.1运行流程图:
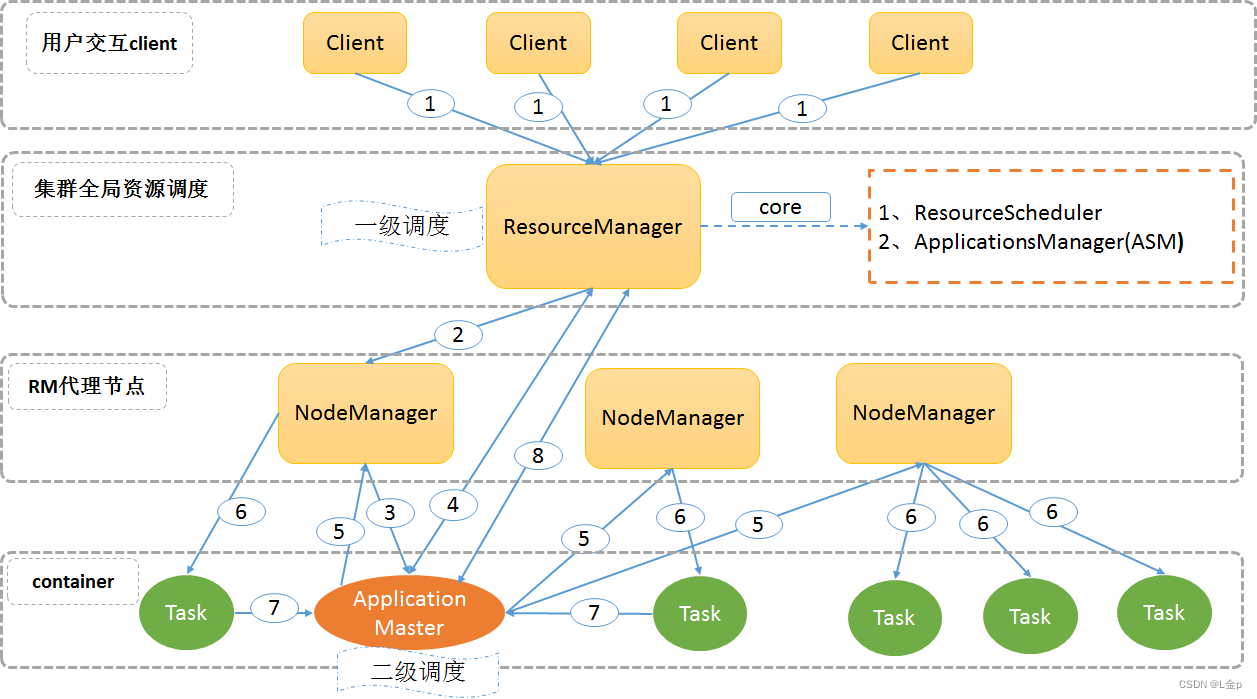
3.2 运行流程详解:
1) 用户向YARN中提交应用程序/作业,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
2) ResourceManager为作业分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动该作业的ApplicationMaster。
3) NodeManager启动一个Container运行ApplicationMaster。
4) ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查询该作业的运行状态;然后它将为各个任务申请资源并监控任务的运行状态。
如果Container没有完全申请到位,则会先使用已经分配到位的部分Container资源进行后续的第5、6、7步骤,其余Container部分由ApplicationMaster采用轮询的方式通过RPC请求向ResourceManager申请和领取资源,直到全部资源分配到位。
5) 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
6) NodeManager执行ApplicationMaster发送的命令,启动Container任务。
7)各个Container通过RPC向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
在作业运行过程中,用户可以随时通过RPC向ApplicationMaster查询作业当前运行状态。
8) 作业完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
Yarn调度策略
1、MRv1的调度方式
集中式调度器,资源调度和应用程序的管理功能集中到单一进程完成,扩展性差。
-
集群规模受限,集群达到一定规模(4000个节点)后,JobTracker压力过大容易发生单点故障
-
新的调度策略难以融入到现有代码中,之前仅支持MapReduce作业,现在要支持Spark等作业,而将新的作业的调度策略加入到集中式调度中是极难的工作
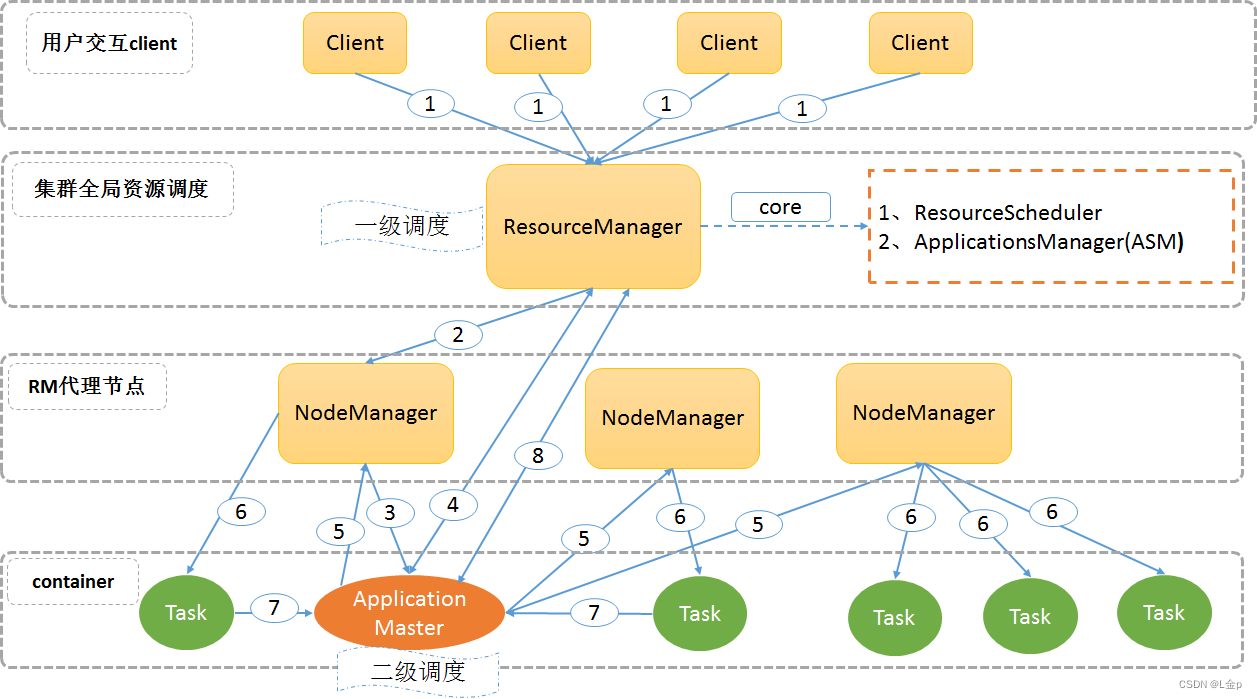
2、Yarn双层调度架构
为了克服集中式调度器的不足,双层调度器是一种很容易被想到的解决之道,它可看作是一种分而治之的机制或者是策略下放机制:双层调度器仍保留一个精简化的集中式资源调度器,但具体任务相关的调度策略则下放到各个应用程序调度器完成。
-
将传统的集中式调度器一分为二,即资源调度器(ResourceManager)和应用程序调度器(ApplicationMaster)
-
ResourceManager即简化了的集中式资源调度器,具体作业的资源调度和管理由应用程序调度器ApplicationMaster负责
3、常用调度策略
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源。在Yarn中,负责给应用分配资源的就是Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,Yarn提供了多种调度器和可配置的策略供我们选择。
3.1 FIFO Scheduler(First In First Out,先进先出)
默认的调度策略,把用户提交的作业顺序排成一个队列,所有用户共享,是一个先进先出的队列。
无法控制用户的资源使用,大的应用可能会占用所有集群资源,导致其他应用被阻塞,造成集群的可用性差,所以不适用于共享集群。一般不在生产环境中使用。
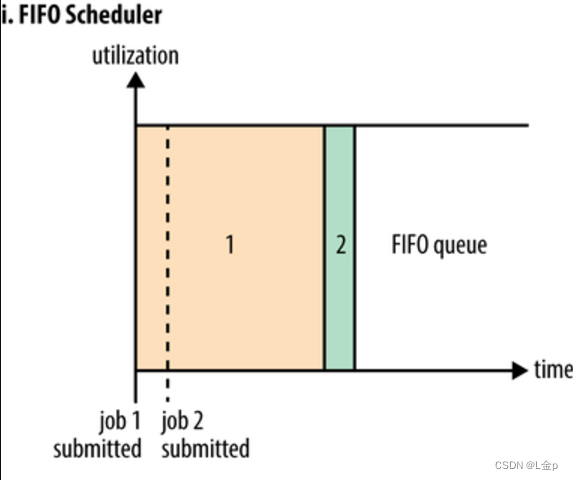
3.2 Capacity Scheduler(容器调度器)
允许多用户共享整个集群,每个用户或组织分配专门的队列,不支持抢占式。队列内部默认使用FIFO,也支持Fair调度。
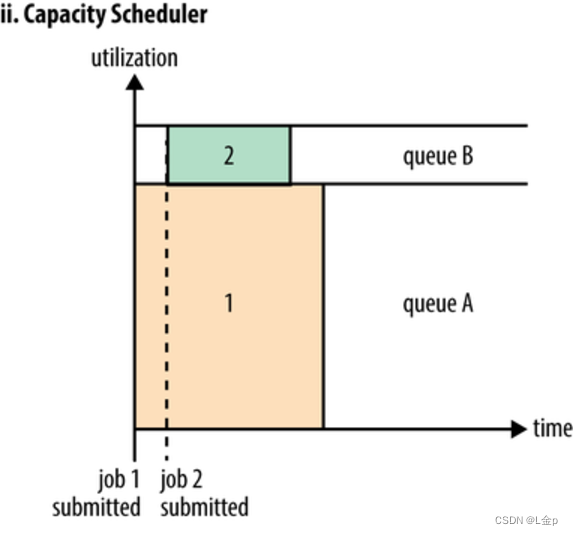
3.3 Fair Scheduler(公平调度器)
目标是为所有用户分配公平的资源。也支持多用户共享集群,也可划分多队列。队列内部不是FIFO,而是采用公平分配的方式。

3.4 总结
| 调度名称 | 特点 |
| FIFO Scheduler | 默认的队列内部调度器,只有一个队列,所有用户共享 ,简单好理解,无法控制用户的资源使用,造成集群的可用性很差。一般不在生产环境使用。 |
| Capacity Scheduler | 多用户、分队列、ACL控制、不支持抢占式,队列内部依然是FIFO,也可以采用Fair |
| Fair Scheduler | 多用户、分队列、ACL控制、支持抢占式,队列内部不是FIFO,而是公平分配的方式 |
Yarn Web UI应用
1、访问Yarn Web UI
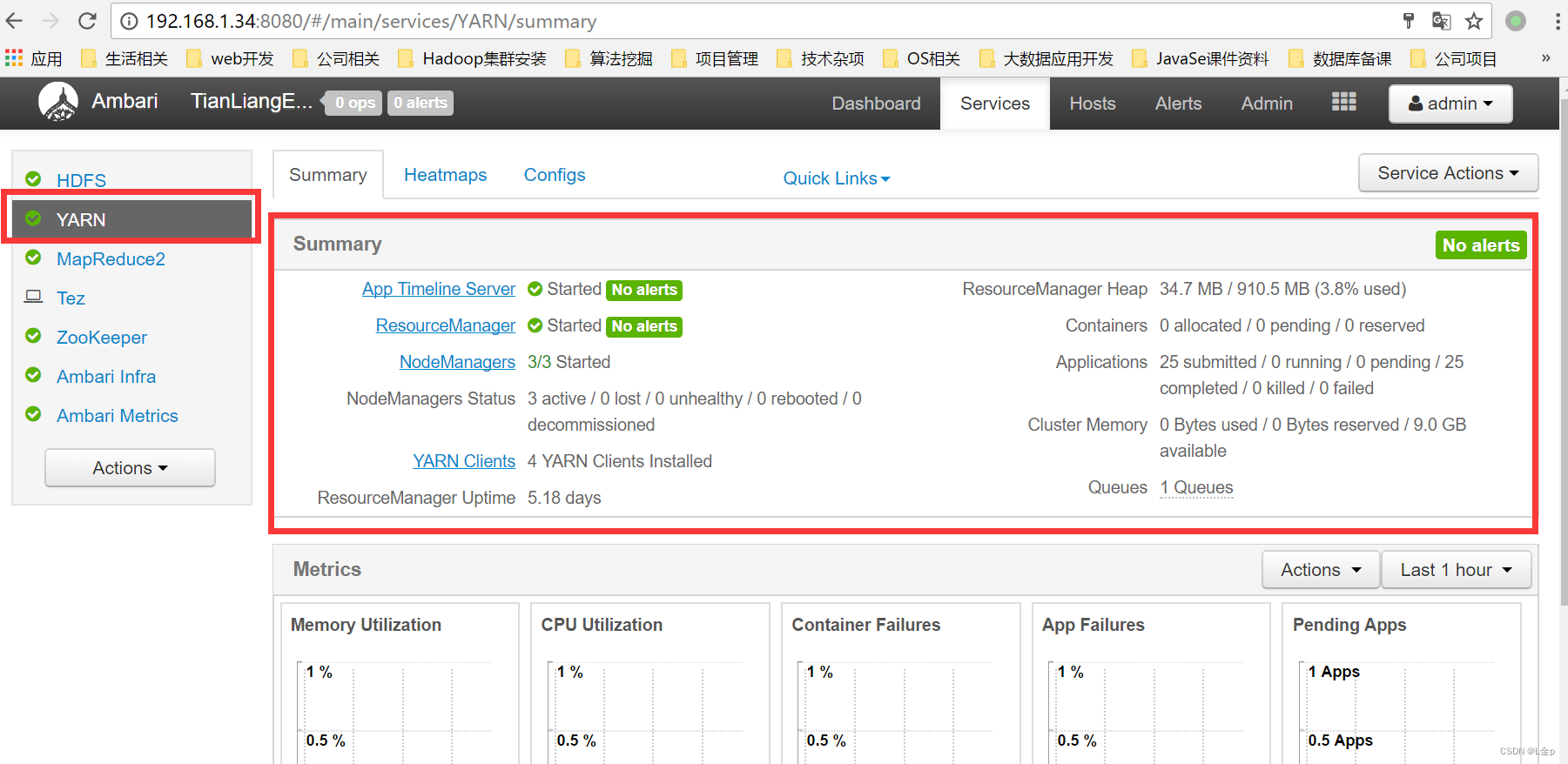
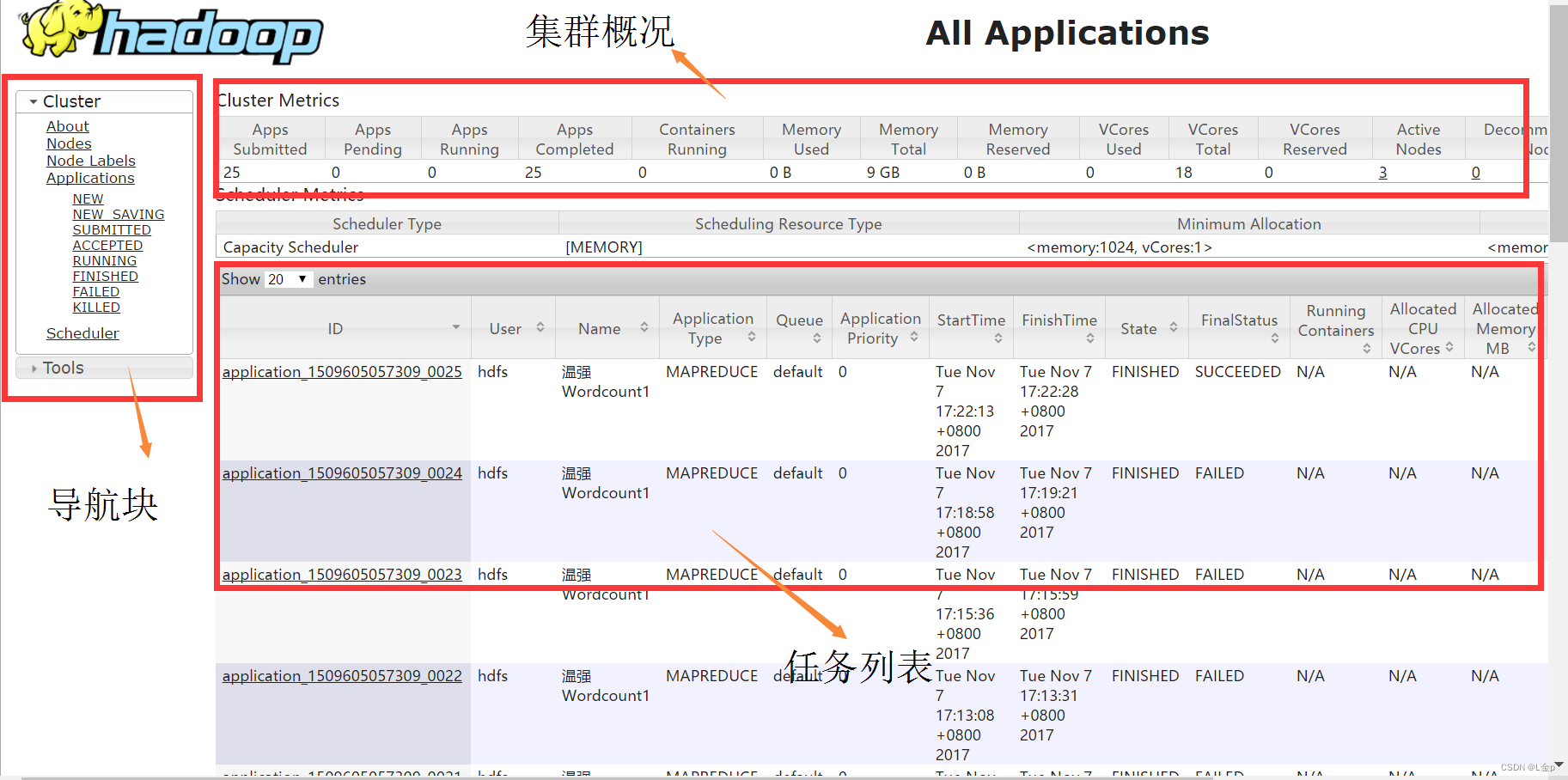
2、访问ResourceManager Web UI

3、ResourceManager Web UI模块解析
Yarn shell应用
1、Yarn命令
Yarn提供了shell环境通过调用bin/yarn脚本文件来执行Yarn的命令。
-
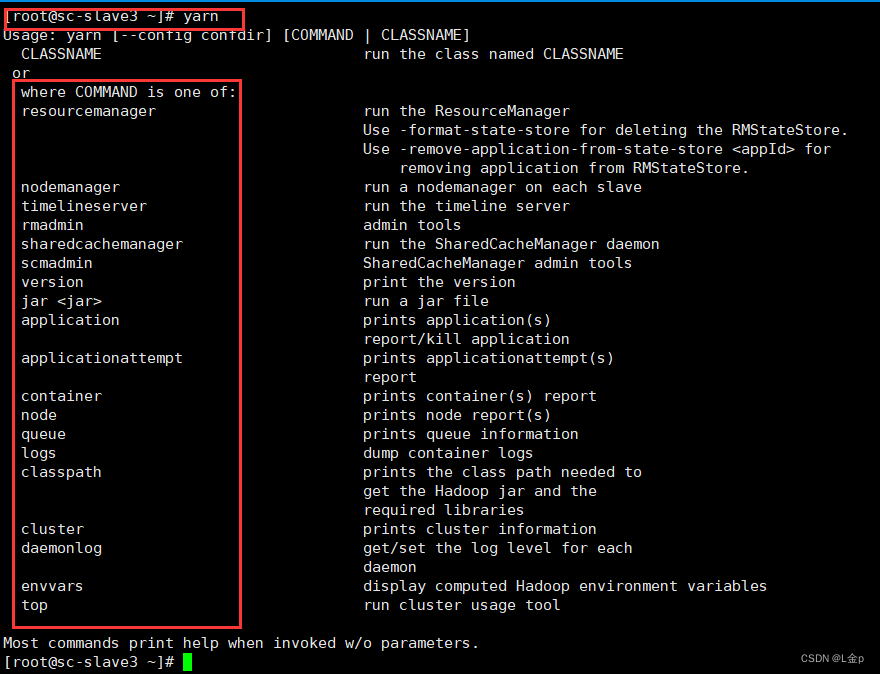
查看Yarn一级命令
直接输入yarn回车即可查看yarn的一级命令:yarn,显示出可用的命令列表
-
查看版本信息
查看版本信息:yarn version

-
Yarn提交jar包
使用yarn命令提交jar包:
yarn jar jarName mainClassPath -Dk1=v1 -Dk2=v2 inputPath outputPath
-
获取yarn运行时的classpath
获取yarn运行时的classpath值:yarn classpath

-
查看所有正在运行的application的列表
查看所有application列表信息:yarn application -list

-
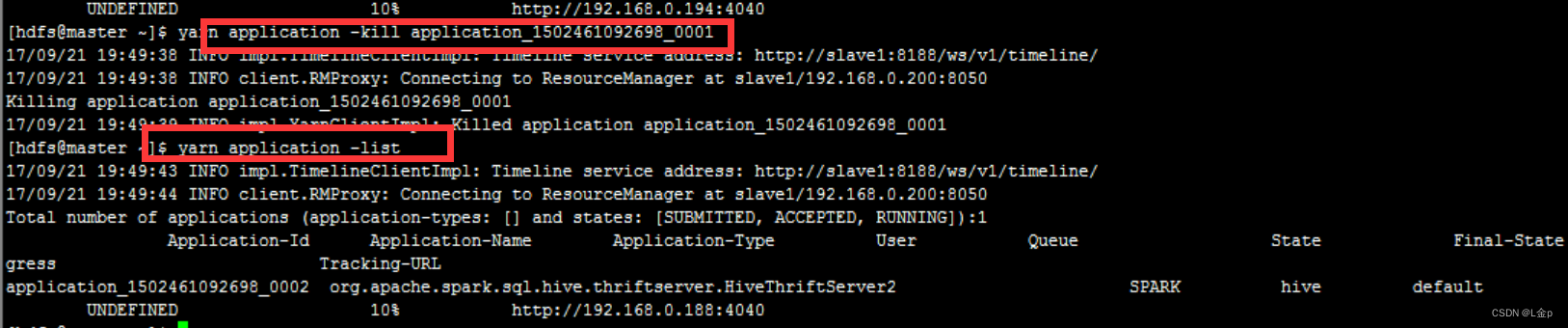
杀掉指定的application
杀掉指定的application,使用命令:yarn application kill app-id
-
查看yarn的资源使用情况
查看yarn的当前资源使用情况:yarn top

2、Yarn shell 应用
使用yarn执行任务,指定任务使用的资源队列名为oncourse。
2.1步骤拆解:
-
新建资源队列oncourse
-
修改MapReduce代码中的Driver代码,使之可以使用yarn命令指定的系统配置参数,如指定所使用的资源队列
-
修改yarn jar指定系统配置参数
-
查看执行结果
-
查看任务使用的资源队列情况
2.2详细执行:
-
新建资源队列,参考上节的配置说明
-
修改MapReduce代码中的Driver代码
新增类GenericOptionsParser:hadoop自带的解析工具类,解析传入的系统配置参数值
-
源代码实现,只需修改Driver类的main方法,如下:
- //启动mr的driver方法
-
- public static void main(String[] args) throws Exception {
-
- //得到集群配置参数
-
- Configuration conf = new Configuration();
-
-
-
- //参数解析器
-
- GenericOptionsParser optionParser = new GenericOptionsParser(conf, args);
-
- String[] remainingArgs = optionParser.getRemainingArgs();
-
- if ((remainingArgs.length != 2)) {
-
- System.err.println("Usage: yarn jar jar_path main_class_path -Dk=v列表 <in> <out>");
-
- System.exit(2);
-
- }
-
- // org.apache.hadoop.io.compress.LzopCodec lc=null;
-
- //设置到本次的job实例中
-
- Job job = Job.getInstance(conf, "天亮WordCountV2");
-
- //指定本次执行的主类是WordCount
-
- job.setJarByClass(WordCountV2.class);
-
- //指定map类
-
- job.setMapperClass(TokenizerMapper.class);
-
- //指定combiner类,要么不指定,如果指定,一般与reducer类相同
-
- job.setCombinerClass(IntSumReducer.class);
-
- //指定reducer类
-
- job.setReducerClass(IntSumReducer.class);
-
- //指定job输出的key和value的类型,如果map和reduce输出类型不完全相同,需要重新设置map的output的key和value的class类型
-
- job.setOutputKeyClass(Text.class);
-
- job.setOutputValueClass(IntWritable.class);
-
- //指定输入数据的路径
-
- FileInputFormat.addInputPath(job, new Path(remainingArgs[0]));
-
- //指定输出路径,并要求该输出路径一定是不存在的
-
- FileOutputFormat.setOutputPath(job, new Path(remainingArgs[1]));
-
- //指定job执行模式,等待任务执行完成后,提交任务的客户端才会退出!
-
- System.exit(job.waitForCompletion(true) ? 0 : 1);
-
- }

-
修改yarn jar指定系统配置参数
yarn jar testhdfs-jar-with-dependencies.jar com.tianliangedu.core.WordCountV2 -Dmapreduce.job.queuename=oncourse /tmp/tianliangedu/input /tmp/tianliangedu/output14
-
查看执行结果:使用hdfs dfs -cat $hdfs_output_path即可,与之前结果一致
-
查看任务使用的资源队列情况
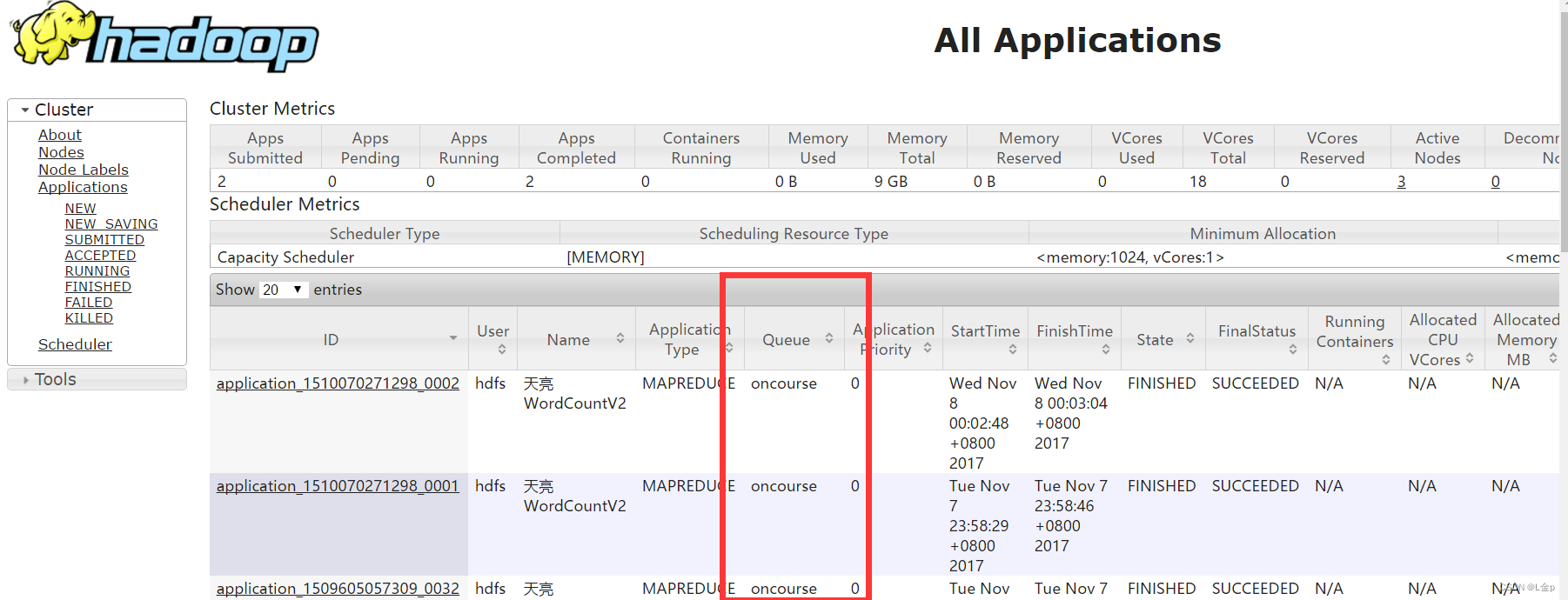
Yarn特征说明
1、统一的资源管理与任务调度框架
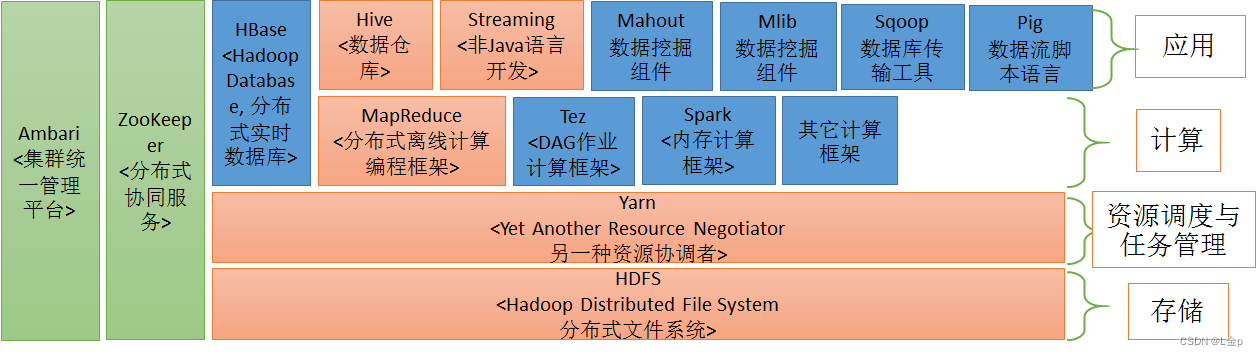
2、双层调度框架
3、容错性说明
-
ResourceManager(RM) Failure
同时启动多个RM,基于Zookeeper实现HA避免单点故障,但同时只有一个是active状态
-
ApplicationMaster(AM) Failure
ApplicationMaster挂掉后,由ResourceManager负责重启。ResourceManager的ApplicationsManager模块会保存已经完成的Task,重启后无需重新运行。ApplicationMaster需要处理内部任务的容错问题,如Task Failure。
-
NodeManager(NM) Failure
若包含Task计算任务执行失败后,ApplicationMaster决定处理方法。若包含AM任务,则由RM重启一个新的Container运行AM。
-
Task Failure
通过心跳把信息反馈给AM,或者心跳超时被AM感知,由AM通过重试恢复Task。
Yarn项目练习
1、从本地构建一个a.txt文本文件,上传至hdfs目录/tmp/tianliangedu/个人用户名目录下。
-
通过yarn jar执行wordcount程序,指定新建队列oncourse,输出目录设置为/tmp/tianliangedu/tianliangedu/个人用户名下的任意指定目录。
-
分别实现在yarn webui和yarn shell中查看任务列表、找到自己所属的任务、查看其执行状态。
-
用yarn shell kill掉该任务,查看任务的最终状态是什么。
2、自学yarn java api(不做要求)
-
通过java代码获取指定yarn app-id的状态信息。
-
通过java代码实现kill指定的app-id的信息。

