
- 1UDP服务器和客户端的实现和IO多路复用_udp怎么使用io多路复用
- 2在ubuntu 24.04上安装xrdp服务器(已验证可用)
- 3【FPGA】高云FPGA之数字钟实验->HC595驱动数码管_fpga数码管
- 4FPGA实现10G万兆网TCP/IP 协议栈,服务器版本,纯VHDL代码编写 提供6套vivado工程源码和技术支持_fpga dhcp实现
- 5Android移动开发-VR全景照片简单实现,计算机应届毕业生面试题_com.google.vr.sdk.widgets.pano.vrpanoramaview
- 6php获取访客IP、UA、操作系统、浏览器等信息_php实现-浏览器ua解析获得手机、系统、浏览器等信息
- 72024最新docker部署gitlab
- 8OPENGL ES 2.0 知识串讲 (9) ——OPENGL ES 详解III(纹理)_regular 2d textures和texture arrays和a cube map arra
- 9大数据分析系统简介,什么是大数据分析系统?
- 10linux CentOS7 使用yum安装mongodb4.4数据库,以及mongodb数据库中新建用户,增删改查,和备份恢复操作_centos7 yum mongodb
基于Yolov8的NEU-DET钢材表面缺陷检测,优化组合新颖程度较高:CVPR2023 PConv和BiLevelRoutingAttention,涨点明显
赞
踩
1.钢铁缺陷数据集介绍
NEU-DET钢材表面缺陷共有六大类,分别为:'crazing','inclusion','patches','pitted_surface','rolled-in_scale','scratches'
每个类别分布为:


2.基于yolov8的训练
原始网络如下:
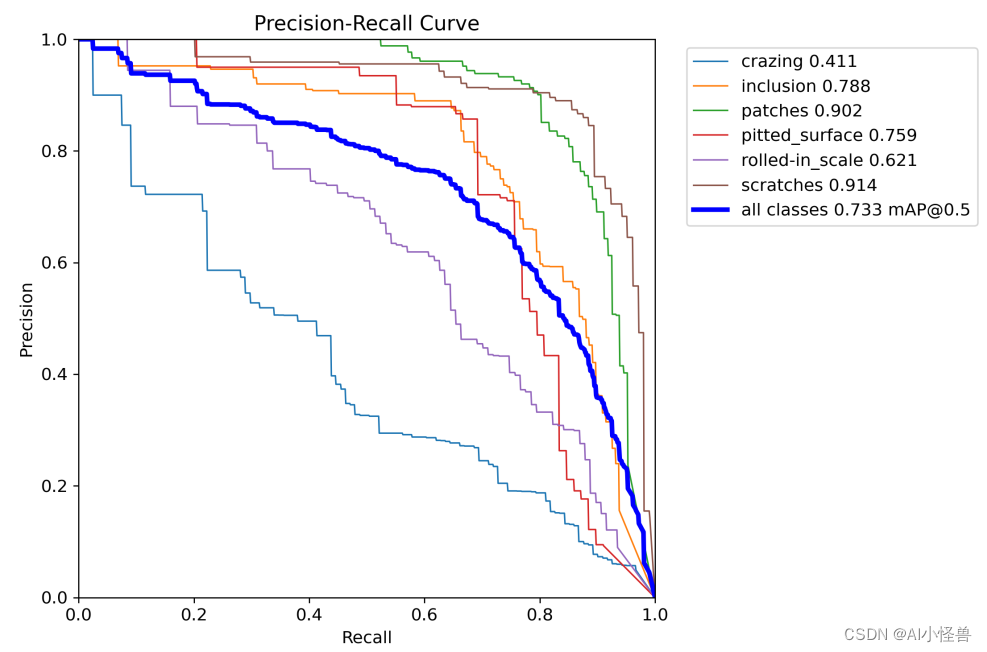
map@0.5为0.733
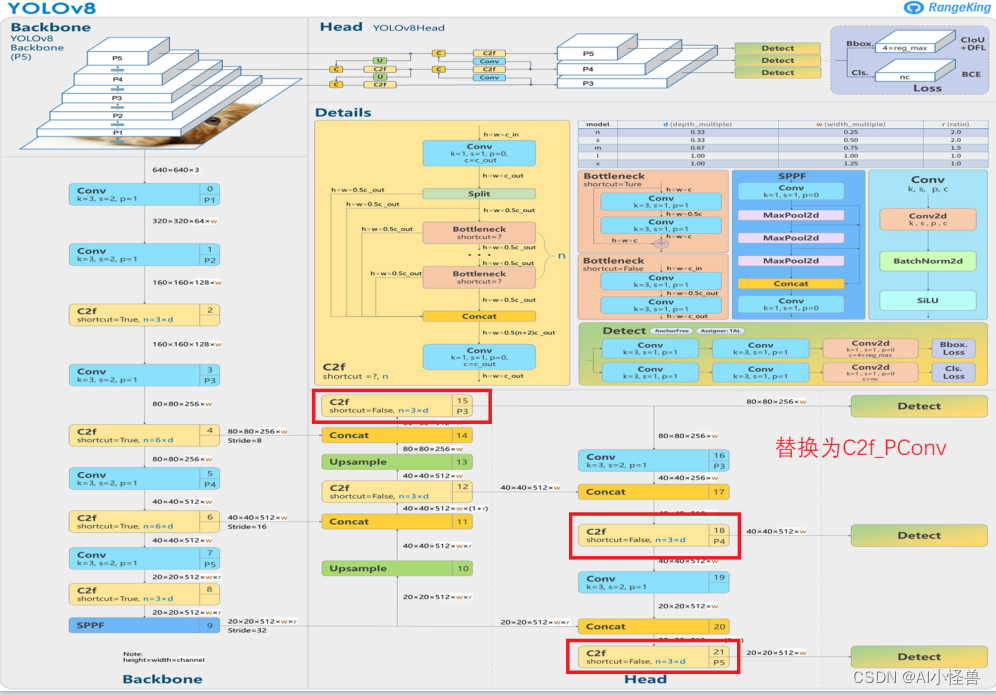
2 PConv
2.1 FasterNet介绍
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。为了实现更快的网络,作者重新回顾了FLOPs的运算符,并证明了如此低的FLOPS主要是由于运算符的频繁内存访问,尤其是深度卷积。因此,本文提出了一种新的partial convolution(PConv),通过同时减少冗余计算和内存访问可以更有效地提取空间特征。
基于PConv进一步提出FasterNet,这是一个新的神经网络家族,它在广泛的设备上实现了比其他网络高得多的运行速度,而不影响各种视觉任务的准确性。例如,在ImageNet-1k上小型FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileVitXXS快3.1倍、3.1倍和2.5倍,同时准确度提高2.9%。
又快又好!本文提出新的Partial卷积(PConv),同时减少冗余计算和内存访问,并进一步提出FasterNet:新的神经网络家族,在多个处理平台上运行速度更快,优于MobileVit等网络;
论文地址:https://arxiv.org/abs/2303.03667
github:GitHub - JierunChen/FasterNet: Code release for PConv and FasterNet
2.2 Partial Convolution
我们提出了一种新的partial卷积(PConv),通过同时减少冗余计算和内存访问,可以更有效地提取空间特征。

map@0.5为0.756

结构示意图:
3 BiLevelRoutingAttention
3.1 BiFormer介绍

论文:https://arxiv.org/pdf/2303.08810.pdf
背景:注意力机制是Vision Transformer的核心构建模块之一,可以捕捉长程依赖关系。然而,由于需要计算所有空间位置之间的成对令牌交互,这种强大的功能会带来巨大的计算负担和内存开销。为了减轻这个问题,一系列工作尝试通过引入手工制作和内容无关的稀疏性到关注力中来解决这个问题,如限制关注操作在局部窗口、轴向条纹或扩张窗口内。
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。
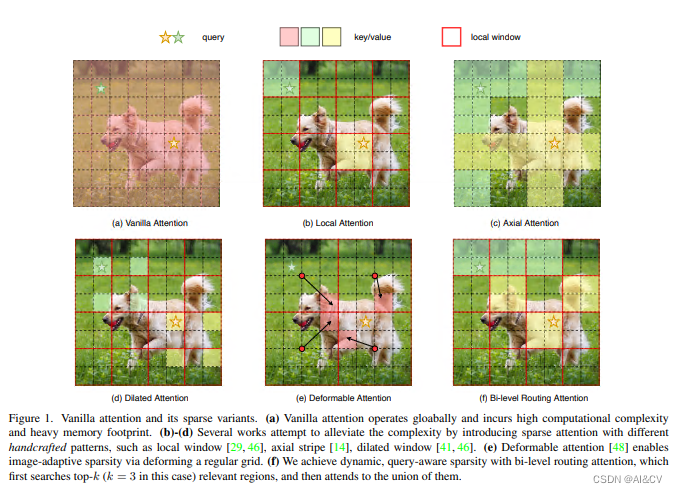
其中图(a)是原始的注意力实现,其直接在全局范围内操作,导致高计算复杂性和大量内存占用;而对于图(b)-(d),这些方法通过引入具有不同手工模式的稀疏注意力来减轻复杂性,例如局部窗口、轴向条纹和扩张窗口等;而图(e)则是基于可变形注意力通过不规则网格来实现图像自适应稀疏性;作者认为以上这些方法大都是通过将 手工制作 和 与内容无关 的稀疏性引入到注意力机制来试图缓解这个问题。因此,本文通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention ),以实现更灵活的计算分配和内容感知,使其具备动态的查询感知稀疏性,如图(f)所示。

map@0.5为0.746

结构示意图:
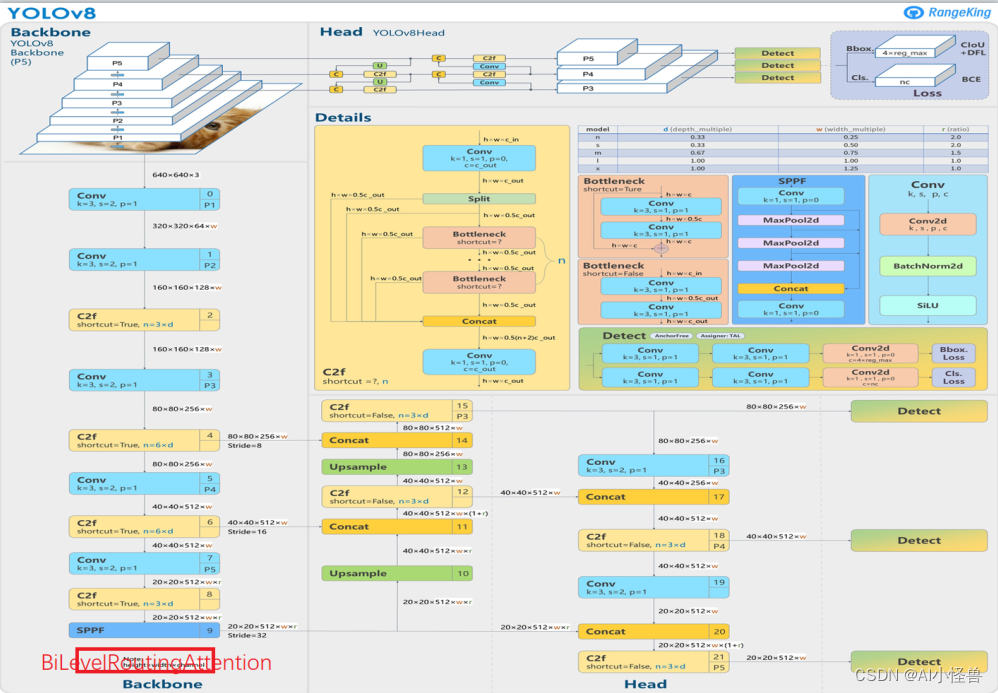
4 PConv+BiLevelRoutingAttention
map@0.5为0.761
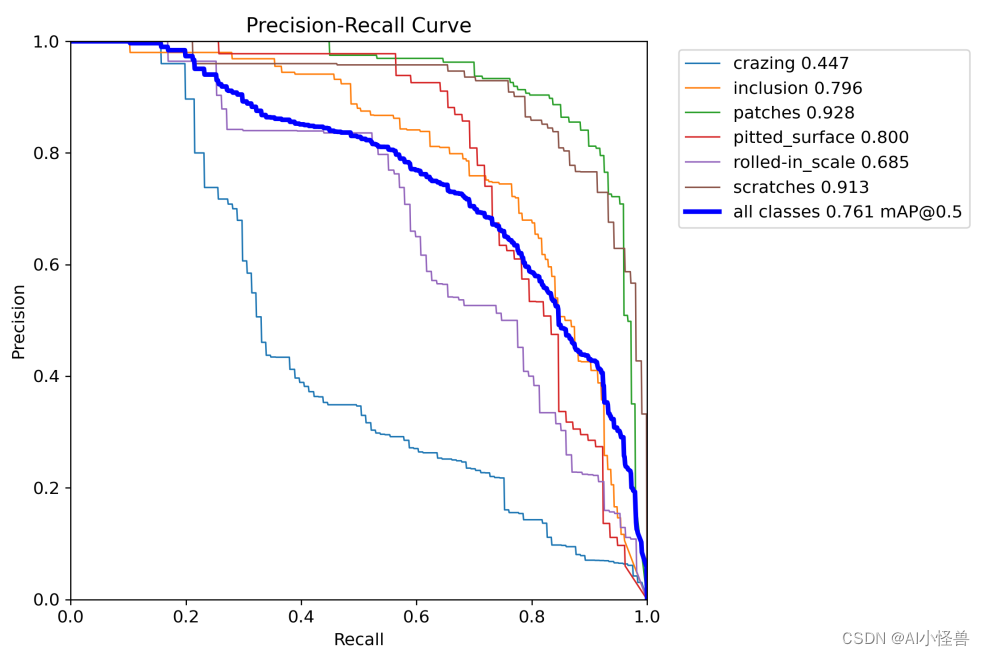
4.总结
通过引入CVPR2023 PConv+BiLevelRoutingAttention思想,在钢铁缺陷中取得涨点,且相比较于发表的一些论文,创新新颖程度好很多,有需要自取可以在自己数据集进行实验,并很有可能发表论文成功哦!!!
5.源码获取
基于Yolov8的NEU-DET钢材表面缺陷检测,优化组合新颖程度较高:CVPR2023 PConv和BiLevelRoutingAttention,涨点明显_AI小怪兽的博客-CSDN博客

