
热门标签
热门文章
- 1Git教程-搭建服务器上GitBlit代码仓库(超详细)_搭建gitblit服务
- 2已解决java.nio.file.FileSystemException文件系统异常的正确解决方法,亲测有效!!!
- 3[网络安全自学篇] 二十五.Web安全学习路线及木马、病毒和防御初探_网络安全文字教程
- 4HTML静态网页作业(HTML+CSS)——外卖平台主题网页设计制作(8个页面)_html加css外卖静态网站
- 5第一篇【传奇开心果系列】Python的PyTorch库技术点案例示例:深度解读PyTorch深度学习在医学领域应用
- 6物联网学习之二:ESP8266 MQTT连接服务器_mqttx链接esp8266
- 7RTL硬件实现 | 定点化_rtl 四舍五入
- 8ImageButton去边框的问题_mfc 设置了背景图片后 按钮有白边
- 9Midjourney角色一致性功能使用方法教程(附今日提示词)_一致性角色 paper
- 10在Node.js中,什么是模块(module)?如何导入和导出模块?_nodejs module
当前位置: article > 正文
sql索引优化实战总结
作者:菜鸟追梦旅行 | 2024-05-22 12:04:29
赞
踩
sql索引优化
sql索引优化实战总结
一、 避免索引失效
-- 最左匹配原则 *
-- 范围条件右边的索引失效
-- 不再索引列上做任何操作 *
-- 使用不等于(!=或者<>)索引失效
-- is not null无法使用索引
-- like以通配符开头(%qw)索引失效 *
-- 字符串不加引号索引失效
-- 使用or连接索引失效
-- 尽量使用覆盖索引
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
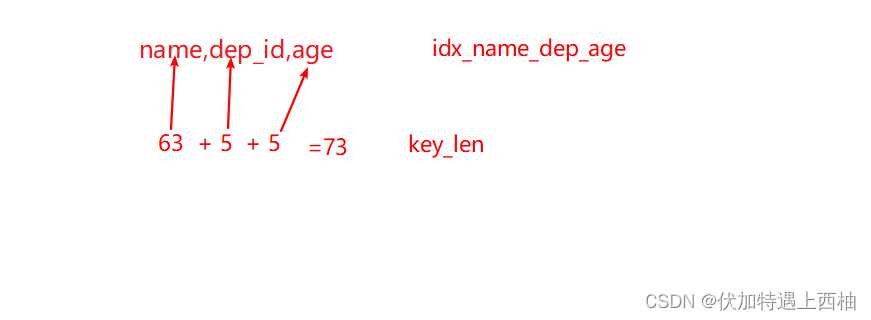
1.1 全值匹配
-- 创建组合索引
create index idx_name_dep_age on employee(name,dep_id,age)
-- 索引字段全部使用上
explain select * from employee where name='鲁班' and dep_id=1 and age=10
- 1
- 2
- 3
- 4

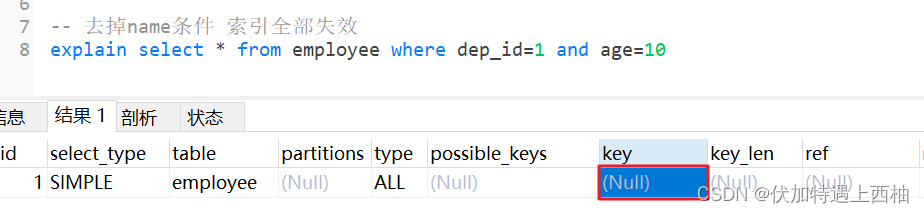
1.2 最左匹配原则
-- 去掉name条件 索引全部失效
explain select * from employee where dep_id=1 and age=10
- 1
- 2
-- 去掉dep_id name索引生效
explain select * from employee where name='鲁班' and age=10
- 1
- 2

-- 顺序错乱不会影响最左匹配
explain select * from employee where dep_id=1 and age=10 and name='鲁班'
- 1
- 2

1.3 不再索引列上做任何操作(注意不严谨)
1.3.1 当查询字段为 * 时索引会失效
TRIM(name)=‘鲁班’ 没法通过索引树方式搜索,只能通过遍历索引方式去找
-- 在name字段上 加上去除空格的函数 索引失效
explain select * from employee where TRIM(name)='鲁班' and dep_id=1 and age=10
- 1
- 2

1.3.1 当查询字段为count(),或者是索引字段 时索引不会失效


使用到了覆盖索引:
count(*),索引字段这些都不需要回表查询,只要遍历索引树就可以得到了。
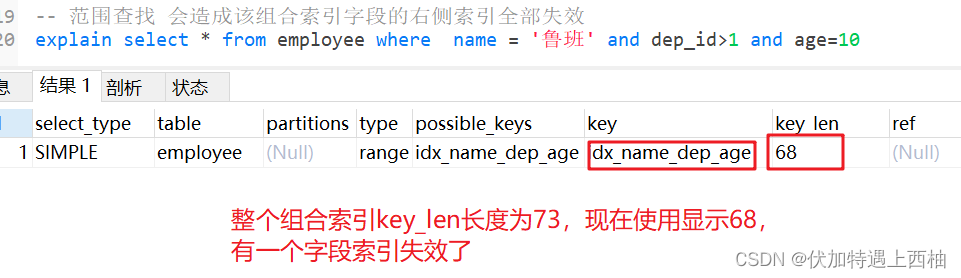
1.4 范围条件右边的索引失效
-- 范围查找 会造成该组合索引字段的右侧索引全部失效
explain select * from employee where name = '鲁班' and dep_id>1 and age=10
- 1
- 2
1.5 mysql在使用不等于(!=或者<>)索引失效
explain select * from employee where age != 10
- 1

1.6 is not null无法使用索引
explain select * from employee where name is not NULL
- 1

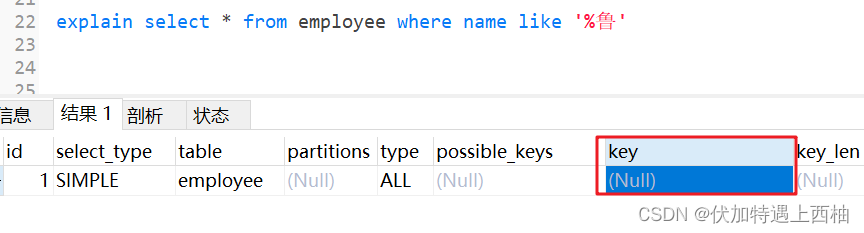
1.7 like以通配符开头(%qw)索引失效
explain select * from employee where name like '%鲁'
- 1
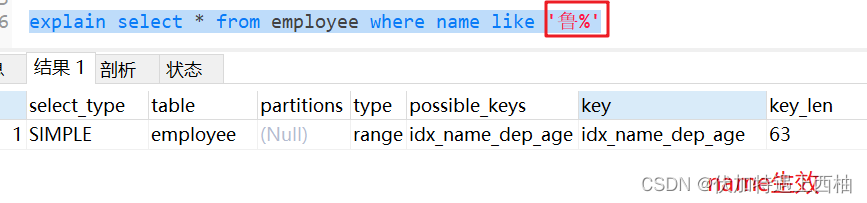
1.8 字符串不加引号索引失效
explain select * from employee where name = 200
- 1
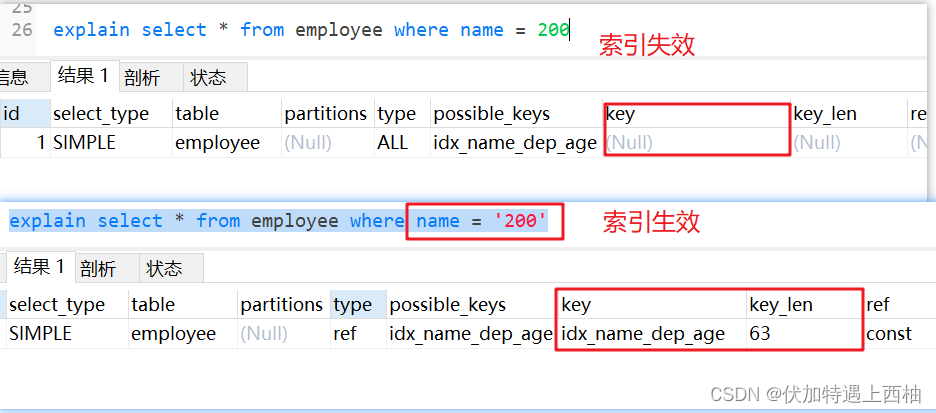
注意:如果是数字类型加上引号,索引不会失效
explain select * from employee where id = '1'
- 1

隐式类型转换规则:
当字符串类型和数字类型进行比较时候,默认字符串转数字
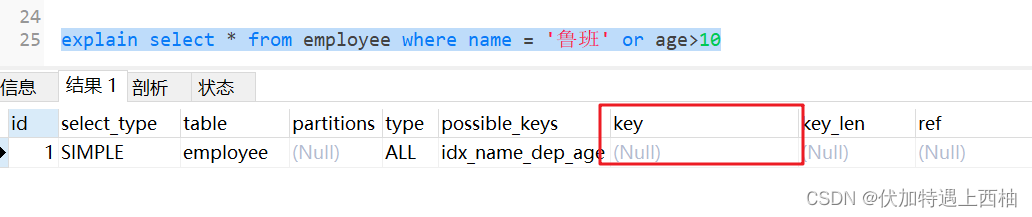
1.9 使用or连接索引失效
explain select * from employee where name = '鲁班' or age>10
- 1
1.10 尽量使用覆盖索引
explain select * from employee where name = '鲁班' or age>10
-- 覆盖索引: 要查询的字段全部是索引字段
-- 上面情况会触发全表扫描,不过若使用了覆盖索引,则会只扫描索引文件
explain select name,dep_id,age from employee where name = '鲁班' or age>10
- 1
- 2
- 3
- 4
二 排序与分组优化
2.1 使用order by出现Using filesort
-- 如果select * 语句未使用到索引,会出现 filesort 可使用覆盖索引解决 或 主键索引
-- 组合索引不满足最左原则 会出现 filesort
-- 组合索引顺序不一致(order by的后面) 会出现 filesort
-- 当索引出现范围查找时 可能会出现 filesort
-- 排序使用一升一降会造成filesort
- 1
- 2
- 3
- 4
- 5
-- 没有使用索引排序,服务器需要额外的为数据进行排序的处理
-- 如果select语句未使用到索引,会出现 filesort
explain select * from employee order by name,dep_id,age
- 1
- 2
- 3

-- 组合索引不满足最左原则 会出现 filesort
explain select * from employee where name='鲁班' order by dep_id,age
explain select * from employee order by dep_id,age
- 1
- 2
- 3

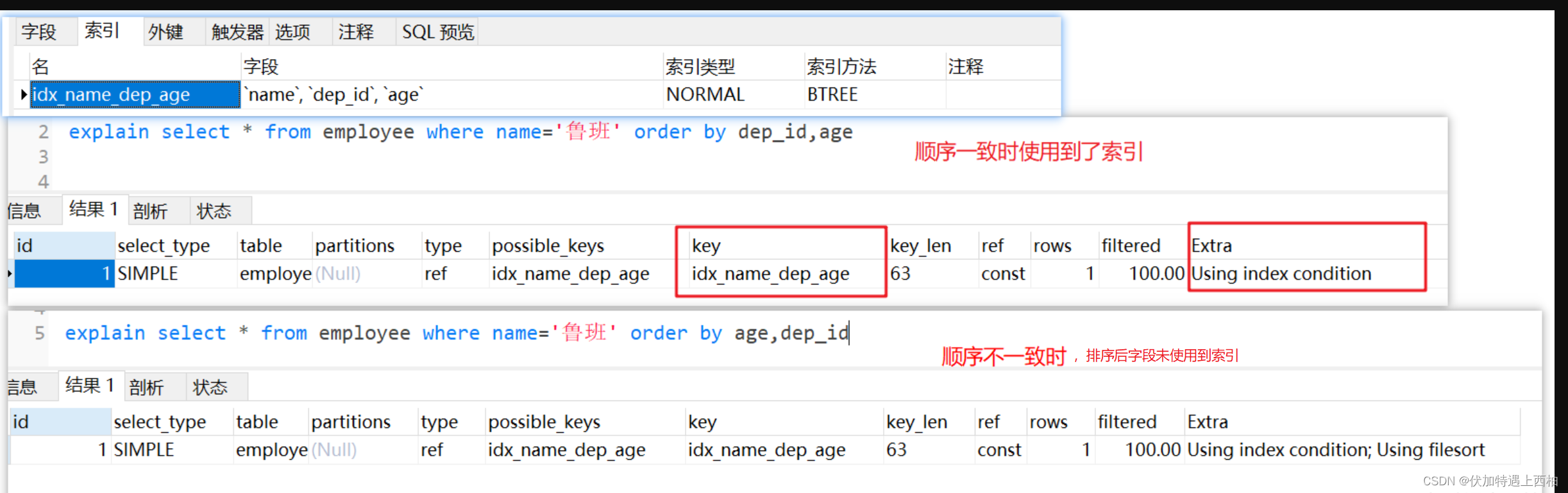
-- 组合索引顺序不一致(order by的后面) 会出现 filesort
explain select * from employee where name='鲁班' order by dep_id,age
explain select * from employee where name='鲁班' order by age,dep_id
- 1
- 2
- 3
-- 当索引出现范围查找时 可能会出现 filesort
explain select * from employee where name='鲁班' and dep_id>1 order by age
- 1
- 2

-- 排序使用一升一降会造成filesort
explain select * from employee where name='鲁班' order by dep_id desc,age
- 1
- 2

2.2 使用group by出现Using temporary
-- 同order by情况类似, 分组必定触发排序
-- 组合索引不满足最左原则 会出现 filesort
-- 组合索引顺序不一致(order by的后面) 会出现 filesort
-- 当索引出现范围查找时 可能会出现 filesort
- 1
- 2
- 3
- 4
三 大数据量分页优化
-- 分页是我们经常使用的功能,在数据量少时单纯的使用limit m,n 不会感觉到性能的影响
-- 但我们的数据达到成百上千万时 , 就会明显查询速度越来越低
- 1
- 2
3.1、数据准备
-- 使用存储过程导入数据
-- 查看是否开启函数功能
show variables like 'log_bin_trust_function_creators';
-- 设置开启函数功能
set global log_bin_trust_function_creators=1;
-- 创建函数用于生成随机字符串
delimiter $$
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(100) default 'qwertyuiopasdfghjklzxcvbnm';
declare return_str varchar(255) default '';
declare i int default 0;
while i<n do
set return_str=concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i=i+1;
end while;
return return_str;
end $$
-- 创建存储过程用于插入数据
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
/*把autocommit设置成0*/
set autocommit= 0;
repeat
set i=i+1;
insert into testemployee(name,dep_id,age,salary,cus_id)
values(rand_string(6),'2',24,3000,6);
until i=max_num end repeat;
commit;
end $$
-- 调用存储过程插入数据
call insert_emp(1,1000000);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
3.2 测试一下分页数据的相应时间
-- limit 0,20 时间: 0.001ms
select * from testemployee limit 0,20
-- limit 10000,20 时间: 0.004ms
select * from testemployee limit 10000,20
-- limit 100000,20 时间: 0.044ms
select * from testemployee limit 100000,20
-- limit 1000000,20 时间: 0.370ms
select * from testemployee limit 1000000,20
-- limit 3000000,20 时间: 1.068ms
select * from testemployee limit 3000000,20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.3 子查询优化
-- 子查询优化
-- 通过Explain发现,之前我们没有利用到索引,这次我们利用索引查询出对应的所有ID
-- 在通过关联查询,查询出对应的全部数据,性能有了明显提升
-- limit 3000000,20 时间: 1.068ms -> 时间: 0.742ms
select * from testemployee e,(select id from testemployee limit 3000000,20) tmp where e.id=tmp.id
-- 自增ID也可以用如下方式
select * from testemployee where id> (select id from testemployee t limit 3000000,1) LIMIT 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用id限定方案
-- 使用id限定方案,将上一页的ID传递过来 根据id范围进行分页查询
-- 通过程序的设计,持续保留上一页的ID,并且ID保证自增
-- 时间: 0.010ms
select * from testemployee where id>3000109 limit 20
-- 虽然使用条件有些苛刻 但效率非常高,可以和方案一组合使用 ,跳转某页使用方案一 下一页使用方案2
- 1
- 2
- 3
- 4
- 5
四 小表驱动大表
4.1 表关联查询
explain select e.id from employee e,department d where e.dep_id=d.id
- 1
MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,
然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
如果小的循环在外层,对于数据库连接来说就只连接5次,进行5000次操作,
如果1000在外,则需要进行1000次数据库连接,从而浪费资源,增加消耗。
这就是为什么要小表驱动大表。
总结:
多表查询中,一定要让小表驱动大表
create index idx_dep_id on testemployee(dep_id)
explain select e.id from testemployee e LEFT JOIN department d on e.dep_id=d.id
explain select e.id from testemployee e RIGHT JOIN department d on e.dep_id=d.id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.2 in和exits查询
使用in 时的explain执行计划 d的数据先被查询出来, 根据d的结果集循环查询a表数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8iP7lhxZ-1653547861343)(assets/1598535713330.png)]
-- 使用in 时间: 3.292ms
A B
select * from employee where dep_id in (select id from department)
使用department表中数据作为外层循环 10次
for( select id from department d)
每次循环执行employee表中的查询
for( select * from employee e where e.dep_id=d.id)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用exits时的explain执行计划 虽然d的查询优先级高,但是当select_type为DEPENDENT_SUBQUERY时,代表当前子查询依赖外部查询,所以可以考到 e表先进行查询
-- 使用exits 时间: 14.771ms
A B
select * from employee e where exists (select 1 from department d where d.id = e.dep_id)
使用employee表中数据作为外层循环 3000000万次
for(select * from employee e)
每次循环执行department表中的查询
for( select 1 from department d where d.id = e.dep_id)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
总结:
当A表数据多于B表中的数据时,这是我们使用in优于Exists
当B表数据多于A表中的数据时,这时我们使用Exists优于in
如果数据量差不多,那么它们的执行性能差不多
Exists子查询只返回true或false,因此子查询中的select * 可以是select 1或其它
- 1
- 2
- 3
- 4
- 5
五 max函数优化
-- 给max函数中的字段添加索引
select max(age) from testemployee
- 1
- 2
案例所用sql脚本
customer表
DROP TABLE IF EXISTS `customer`;
CREATE TABLE `customer` (
`id` int(11) NOT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of customer
-- ----------------------------
INSERT INTO `customer` VALUES (1, 'zs');
SET FOREIGN_KEY_CHECKS = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
employee表
DROP TABLE IF EXISTS `employee`;
CREATE TABLE `employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`dep_id` int(11) NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
`salary` decimal(10, 2) NULL DEFAULT NULL,
`cus_id` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_name_dep_age`(`name`, `dep_id`, `age`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 109 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of employee
-- ----------------------------
INSERT INTO `employee` VALUES (1, '鲁班', 1, 10, 1000.00, 1);
INSERT INTO `employee` VALUES (2, '后裔', 1, 20, 2000.00, 1);
INSERT INTO `employee` VALUES (3, '孙尚香', 1, 20, 2500.00, 1);
INSERT INTO `employee` VALUES (4, '凯', 4, 20, 3000.00, 1);
INSERT INTO `employee` VALUES (5, '典韦', 4, 40, 3500.00, 2);
INSERT INTO `employee` VALUES (6, '貂蝉', 6, 20, 5000.00, 1);
INSERT INTO `employee` VALUES (7, '孙膑', 6, 50, 5000.00, 1);
INSERT INTO `employee` VALUES (8, '蔡文姬', 30, 35, 4000.00, 1);
SET FOREIGN_KEY_CHECKS = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
department表
DROP TABLE IF EXISTS `department`;
CREATE TABLE `department` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`deptName` varchar(30) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`address` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 6 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of department
-- ----------------------------
INSERT INTO `department` VALUES (1, '研发部(RD)', '2层');
INSERT INTO `department` VALUES (2, '人事部(HR)', '3层');
INSERT INTO `department` VALUES (3, '市场部(MK)', '4层');
INSERT INTO `department` VALUES (4, '后勤部(MIS)', '5层');
INSERT INTO `department` VALUES (5, '财务部(FD)', '6层');
SET FOREIGN_KEY_CHECKS = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
testemployee
DROP TABLE IF EXISTS `testemployee`;
CREATE TABLE `testemployee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`dep_id` int(11) NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
`salary` decimal(10, 2) NULL DEFAULT NULL,
`cus_id` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_age`(`age`) USING BTREE,
INDEX `idx_dep_id`(`dep_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2000109 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- 使用存储过程导入数据
-- 查看是否开启函数功能
show variables like 'log_bin_trust_function_creators';
-- 设置开启函数功能
set global log_bin_trust_function_creators=1;
-- 创建函数用于生成随机字符串
delimiter $$
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(100) default 'qwertyuiopasdfghjklzxcvbnm';
declare return_str varchar(255) default '';
declare i int default 0;
while i<n do
set return_str=concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i=i+1;
end while;
return return_str;
end $$
-- 创建存储过程用于插入数据
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
/*把autocommit设置成0*/
set autocommit= 0;
repeat
set i=i+1;
insert into testemployee(name,dep_id,age,salary,cus_id)
values(rand_string(6),'2',24,3000,6);
until i=max_num end repeat;
commit;
end $$
-- 调用存储过程插入数据
call insert_emp(1,1000000);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/608165
推荐阅读
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

