
- 1Android如何防止apk程序被反编译_apk防反编译
- 2大模型时代下的决策范式转变_大模型的统计分析和辅助决策
- 3union all和union的区别以及怎么使用_union all和union的区别用法
- 4oracle的SQL语句中的(+)是干什么用的?
- 5Qt 3D:线框 QML 示例_qml qt3d 画线
- 6SpringBoot升级3.2报错Invalid value type for attribute ‘factoryBeanObjectType‘: java.lang.String_invalid value type for attribute 'factorybeanobjec
- 7七年级上册英语第三单元单词课文翻译_answer是七年级上册第几单元学的
- 8网络编程1 - socket基本函数_socket函数pf
- 9大学生如何选择人生第一份工作
- 10安装g++,在centos上执行yum -y install gcc gcc-c++ libstdc++-devel
调研了下 AI 作曲,顺便做了期视频...快进来听歌!
赞
踩

文 | 白鹡鸰
编 | 小轶
视频 | 白鹡鸰
嗨,大家好!这里是卖萌屋,我是白鹡鸰。今天和大家聊聊人工智能作曲。人工智能在音乐领域的应用已经非常常见了,像听歌识曲、曲风分类、自动扒谱等等,而 利用机器来替代人类作曲 ?这显然也不是新想法了。
核心问题只在于:
现在这个任务被做到了什么程度?
用的是什么方法?
Illiac Suite是历史上第一段在计算机协助下编曲的古典乐,诞生于1956年[1]。
上面这段音乐则来自2020年1月出版的,第一张由神经网络作曲、人工编辑后发行的音乐专辑Nobody's Song。虽然还达不到让人印象深刻的程度,但若是将它混在一张轻音乐歌单当中,应该没有几个人能够发现,这首曲子的作者不是人类。

事实上,音乐区的知名 up 主双琴侠就做过一期视频,请他们的朋友挑选了人类和人工智能作曲的各6首曲子,测试人类能否区分这些音乐之间的差异。结果,两名职业小提琴手的错判率都在50%左右,弹幕中网友的错判率则更高。可见现在人工智能作曲的最佳成果,确实已经能和人类不相上下了。
 原理
原理
既然现在的人工智能作曲的表现已经如此优秀,我们必然要问,这是怎么做到的呢?为了解释这个问题,需要对音乐的数据特征有初步的了解。
首先是音符的概念。常见的五线谱也好,简谱也罢,都是用来记录音符的。音符的要素是音高和音长。音高的本质是指声音的频率,音长则是一个声音持续的时间。显然,没有说一个时刻只能有一个音符,因此就有了和弦;也没有说一个时刻必须至少有一个音符,因此就有了空拍。

第二个概念则是旋律,一串时间序列上的音符,或者是和弦,组成的就是旋律。由多段旋律组成的完整部分则是乐章。
其实,音乐和自然语言、图像都分别有似与不似之处。拿自然语言作比,音符有点像单字,和弦则像单词,旋律是一句话,乐章则是段落;不仅如此,音乐同样也是依赖时序上的变化才能表达完整含义的。但是,自然语言所能传递的信息远比音乐清晰,歧义显然少了很多。音乐在局部表意的模糊性上,倒是和图像更为类似。

当然,我们也可以说,有规律的数据在模式上必然存在一定相似性。总之,在作曲任务上,将NLP、CV领域的学习模型迁移过来使用,可以说是预料之中的事情了。马尔可夫链、遗传算法、VAE、LSTM,这些算法都被尝试过。不过我们还是着重介绍一下目前效果最好的几个模型分别采用的方法吧。
 算法
算法
事先声明,本次讨论中,所谓的“效果最好”完全是由个人喜好判断。如果有不同意见,还请大家自由保留。
Transformer
或许我们不应该感到惊讶,Transformer 又制霸了作曲领域。目前表现最好的谷歌的 Magenta[2],OpenAI 的 Jukebox[3] 都选择了这条道路。不过呢,两个模型在细节上差别很大,它们还恰好代表了现在自动作曲研究的两大风向。
Magenta - Google
Magenta的模型对于Transformer本身没有任何的改动,直接调用了一个自然语言翻译的 Transformer 库 Tensor2Tensor 。它的输入也是作曲任务当中最常用的"类MIDI"格式编码:用编号指代音高,通过占位符(音乐标记中一般用下划线)来表示音长,最下面两行,第一行是指每个占位符在对应一个四分音符中的第几个十六分音符,第二行则是布尔数值,用来标明是否存在延音。大概就是长成这样:
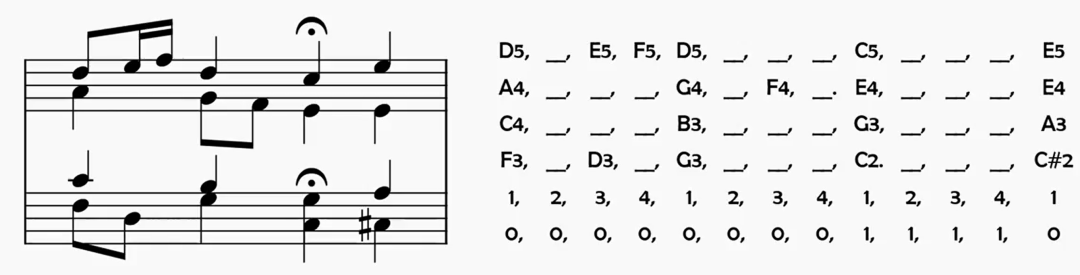
由于目前作曲方面最常用的数据库Bach Chorale从选曲的时候就保证了只会包含最多同时存在四个音符的旋律片段,因此四行就足够记录所有关于音高和音长的信息。这种形式编码的乐谱在可视化的时候可以转换成这样:
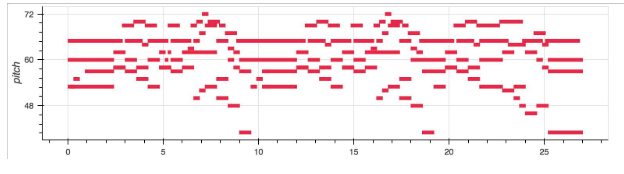
确实能够直观地让人知道整首曲子旋律的变化过程,这也可以证明这种编码方式确实足够高效,难怪会被广泛应用了。Magenta就是把这样一段编码打包成tensor,塞进Transformer里进行训练的。忽略模型没有什么新意的问题,光说效果的话还是不错的。
Jukebox - OpenAI
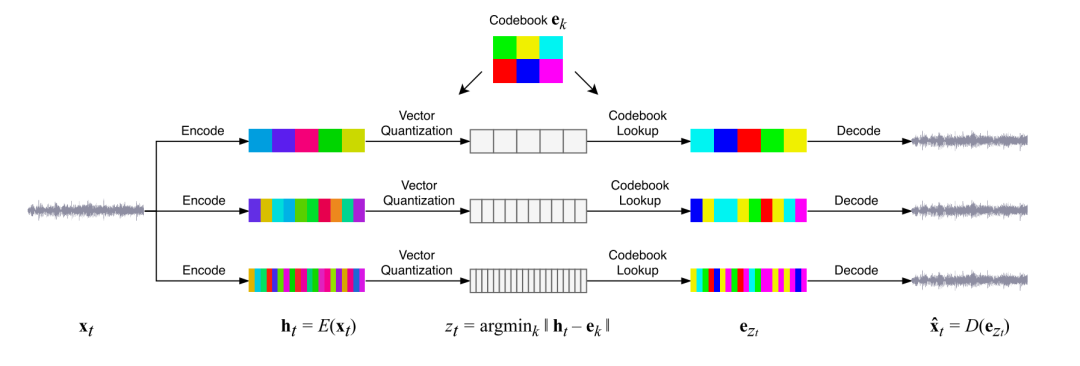
与Magenta不同,Jukebox的目标是在给定旋律开头和歌词内容后,能够生成歌曲。Jukebox的创作者们认为,通过编码音调生成的声音在单个音符上输出的音色没有变化,因此生成的音乐过于死板。为了解决这个问题,他们决定直接从音频层面对输入进行编码。通过VAE对音频进行多个频率层级的采样,然后转为向量形式的量化特征。根据Jukebox的说法,他们在对不同流派的音乐打上标签之后,模型成功学会了生成不同风格的曲目。但作为听众,我的感受是随着曲子推进到后期,风格会越来越难以维持。而且,以音频作为输入、输出格式的模型,不可避免地导致了乐曲变成了全损音质。
Deep RNN
DeepBach[4]
DeepBach 可以说是深度神经网络模型中作曲效果为数不多比较好的。主要理由是,它专注于生成巴赫风格的曲子,而巴赫的曲子总的来说节奏比较规整,在乐理方面也非常守规矩。
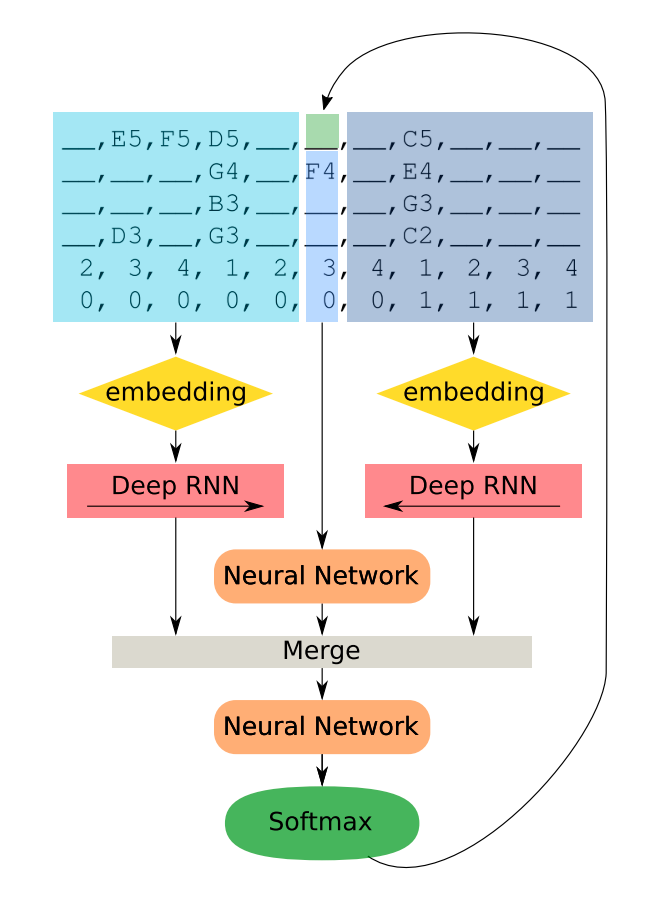
DeepBach的编码方式和现在Magenta的transformer是一样的,模型当中,使用了两个RNN网络,一个用于处理乐谱中过去的旋律,一个用于处理乐谱中将会演奏的旋律,然后和“现在”的音符编码处理好的特征拼接在一起,再经过神经网络。比较有意思的是音乐的生成,在学会了“巴赫的规则”之后,模型就基于伪吉布斯随机采样,用马尔可夫链蒙特卡洛方法随机游走出一条旋律。想想现在你听到的音乐,居然仅仅是基于一些参数由电脑随机生成的,它还这么和谐,这么巴赫,个人而言,感觉非常奇妙。
其他
顺便礼节性地提一句,早年GAN网络、LSTM在自动作曲方面同样有所应用,不过就效果而言现在已经完败于Transformer,所以就不展开了。
 「最佳应用」- AIVA
「最佳应用」- AIVA
除了以上能够较为清楚地了解原理的模型之外,我们还必须提一下世界上的第一位人工智能作曲家,AIVA。AIVA由法国的音乐组织SACEM制作,于2016年2月推出,目前已经发行了五张专辑。我在官网上注册了一个账号,可以看出,它已经能够快速地生成多种风格的音乐旋律。比较可惜的是作为商用软件,在原理方面AIVA并没有公开。根据我个人的猜测,它在模型设计方面未必特别精巧,但是乐理方面人工编写的规则和参数调整比上述模型会更多,网络模型在体量上也会更大。
 小结
小结
在大致感受完一圈目前人工智能作曲的水平之后,相信大家内心都有了各自的评判。视频的最后,还是要老生常谈一下:人工智能作曲会取代人类吗?
我个人对这个问题的回答是:会也不会。
按照现在的进度来看,人工智能作曲可以快速地生成很多听起来挑不出大错的旋律,只要稍加编辑,就可以作为日常的背景音乐使用。因此,在一些需要音乐作为调剂,但对音乐本身质量要求不高的场合,人工智能很可能替代人类进行作曲,批量制造氛围音乐。
然而,人工智能最大的弱点在于,它无法理解情感,而音乐是最纯粹地用于传递情感的艺术类别。即使同一段旋律,速度、强弱上的变化能够造成完全不同的效果,更不要说,还有音色的变化,乐器的选择。因为无法理解情感,人工智能只能简单地模仿已有的乐曲,创造出包含类似情感的片段,输出的乐曲中往往有大量的重复,而且旋律到下一段旋律,表达的情感并不一致。
因此,真正能打动人、值得反复欣赏的旋律,恐怕最终还是需要人类来创作。也就是说,人工智能作曲只是拔高了音乐创作的门槛,它的存在将会督促作曲家们不再制造简单粗糙的声音,而是去更仔细地审视音乐中的细节,钻研该如何用这一媒介更好地来传递情感。
欢迎各位关注卖萌屋 b 站账号~卖萌屋今后也将持续(随缘)更新视频。
卖萌屋 b 站链接:
https://www.bilibili.com/video/BV1XP4y1G7Bt?spm_id_from=333.999.0.0
萌屋作者:白鹡鸰
白鹡鸰(jí líng)是一种候鸟,天性决定了会横跨很多领域。已在上海交大栖息四年,进入了名为博士的换毛期。目前以图像语义为食,但私下也对自然语言很感兴趣,喜欢在卖萌屋轻松不失严谨的氛围里浪~~形~~飞~~翔~~
知乎ID也是白鹡鸰,欢迎造访。
作品推荐:
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1] Hiller Jr, Lejaren A., and Leonard M. Isaacson. "Musical composition with a high speed digital computer." Audio Engineering Society Convention 9. Audio Engineering Society, 1957.1
[2] Huang, Cheng-Zhi Anna, et al. "Music transformer." arXiv preprint arXiv:1809.04281 (2018). https://magenta.tensorflow.org/music-transformer
[3] Dhariwal, Prafulla, et al. "Jukebox: A generative model for music." arXiv preprint arXiv:2005.00341 (2020). https://www.youtube.com/watch?v=BUIrbZS5eXc
[4] Hadjeres, Gaëtan, François Pachet, and Frank Nielsen. "Deepbach: a steerable model for bach chorales generation." International Conference on Machine Learning. PMLR, 2017.


