- 1Python 基础 — 基础语法_python %name %name
- 290后,转行软件测试3年,从月入7000+到月入过万,整理出的这一万字经验分享。_毕业后第二份工作可以转研发嘛
- 3Unity Lighting Window 属性的序列化与反序列化_unity lightingdata.asset 序列化
- 4深入了解Nginx(一):Nginx核心原理
- 5软件测试—接口测试面试题及jmeter面试题_软件测试面试题接口
- 6STM32+WIFI+MQTT+云Mysql数据上报并转存到云数据库_stm32基于云平台的数据库
- 7【C++】详解深浅拷贝的概念及其区别
- 8使用Git 命令行拉取、提交、推送 代码_git命令行推送
- 9智慧水务大数据平台-智慧水务建设方案_智慧水务平台方案
- 10新朋友+1!拓数派 PieCloudDB Database 与 OpenCloudOS、TencentOS Server 完成产品兼容互认证_opencloudos tencentos server
Hadoop伪分布式部署配置及测试示范_hadoop伪分布式搭建检验是否成功
赞
踩
伪分布式是一种在单个节点上模拟分布式环境的配置方式.
在伪分布式模式下,Hadoop的各个组件(如HDFS、YARN和MapReduce)在同一台机器上运行,但它们的配置和功能与真实的分布式环境相似.
由此, 在之前的配置好的本地模式下,我们需要进入${HADOOP_HOME}所在目录下的 etc/hadoop 查看一些相关的配置文件.
Hadoop的配置文件使用XML格式进行编写,主要由
<property>、<name>和<value>等元素组成,具体格式如下:
<configuration>:配置文件的根元素,包含了所有的配置项.<property>:配置项的元素,表示一个具体的配置项.<name>:属性的名称,用于标识配置项.<value>:属性的值,用于指定配置项的具体取值.
Hadoop的核心文件包括以下几个:
1. core-site.xml :这个文件包含了Hadoop的核心配置信息,如HDFS的默认文件系统URL、数据节点的临时目录等.
2. hdfs-site.xml :这个文件包含了HDFS的配置信息,如数据块的大小、副本数量、名称节点和数据节点的地址等.
3. mapred-site.xml :这个文件包含了MapReduce的配置信息,如任务跟踪器和任务运行器的地址、任务重试次数等.
4. yarn-site.xml :这个文件包含了YARN的配置信息,如资源管理器和节点管理器的地址、任务分配策略等.
对于伪分布式配置,MapReduce和YARN通常会使用默认配置,因此不需要单独配置
mapred-site.xml和yarn-site.xml文件.
默认配置将会使用本地模式运行MapReduce作业,并将YARN资源管理器和节点管理器配置为本地主机.
因此本次部署伪分布式需要配置的文件是 core-site.xml和 hdfs-site.xml.
core-site.xml 文件配置内容如下:
- <configuration>
-
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoop-virtual-machine:9820</value>
- <!--将Hadoop的默认文件系统设置为HDFS,并连接到主机名为hadoop-virtual-machine,端口号为9820的节点上
- 注意:Hadoop的版本不同,默认端口也有变化不同
- 对于Hadoop 1.x,默认文件系统的端口是9000. 对于Hadoop 2.x,默认文件系统的端口是8020. 对于Hadoop 3.x,默认文件系统的端口是9820.-->
- </property>
-
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/usr/local/hadoop-3.3.6/tmp</value>
- <!--指定Hadoop的临时目录(Temporary Directory)的基本路径.
- 注意:如果没有指定临时文件的目录,Hadoop可能会将临时文件存储在默认的临时目录中,并在启动时删除这些文件.-->
- </property>
-
- </configuration>

hdfs-site.xml 文件配置内容如下:
- <configuration>
-
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- <!--指定文件在HDFS中的副本数.
- 注意:在伪分布式配置中,只有一个节点可以存储数据,因此将副本数设置为1即可.-->
- </property>
-
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/usr/local/hadoop-3.3.6/tmp/dfs/name</value>
- <!--指定HDFS名称节点的存储目录-->
- </property>
-
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/usr/local/hadoop-3.3.6/tmp/dfs/data</value>
- <!--指定HDFS数据节点的存储目录-->
- </property>
-
- </configuration>
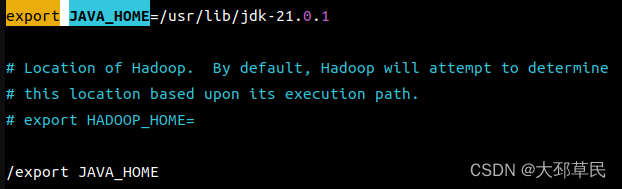
此外,还需对 hadoop-env.sh 进行配置.
查找 export JAVA_HOEM,将其注释删除并指定环境变量具体路径.
如果不进行环境变量配置,可能在下面的后续操作中出现如下错误提示:
JAVA_HOME is not set and could not be found.
接着,执行 hdfs namenode -format 命令进行格式化操作.
hdfs namenode -format 命令用于格式化Hadoop分布式文件系统(HDFS)中的名称节点.
格式化名称节点是在首次启动HDFS之前的必要步骤.
该命令的作用包括:
1. 创建名称节点的文件系统目录: -format 命令会在配置文件中指定的HDFS名称节点的 dfs.namenode.name.dir 目录中创建名称节点的文件系统目录. 这些目录将用于存储HDFS的元数据信息,例如文件和目录的命名空间、块的位置和副本信息等.
2. 初始化名称节点的元数据: -format 命令会初始化名称节点的元数据,包括创建命名空间目录、写入初始版本和时间戳等信息.
3. 清除旧的名称节点数据:在格式化名称节点之前, -format 命令会清除旧的名称节点数据.这将删除之前存在的命名空间和元数据信息,因此在运行该命令之前需要确保不再需要之前的HDFS数据.
此过程进行操作的内容输出会较多.
最终末尾输出的内容如下:

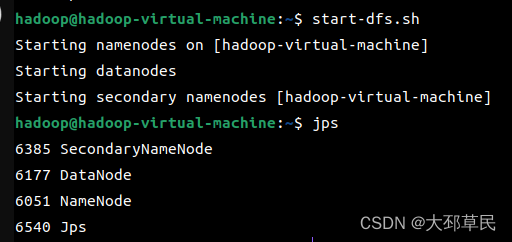
接着,执行 start-dfs.sh 开启 NameNode 和 DataNode 守护进程
start-dfs.sh是一个脚本文件,用于启动Hadoop分布式文件系统(HDFS)的各个组件.
具体来说,start-dfs.sh脚本会启动以下组件:
1. NameNode:HDFS的主节点,负责管理文件系统的命名空间和元数据.
2. SecondaryNameNode(可选):辅助NameNode,定期合并编辑日志并创建检查点.
3. DataNode:HDFS的数据节点,存储实际的数据块.
4. JournalNode(可选):用于提供高可用性的Journal节点,用于记录NameNode的编辑日志.
5. ZKFC(ZooKeeper Failover Controller)(可选):用于监控NameNode的健康状态,并在主节点故障时进行故障转移.可选是要在Hadoop配置文件中明确配置该组件.
通过运行start-dfs.sh脚本,可以启动HDFS集群的各个组件,使其能够正常工作,提供分布式存储和访问文件的功能.
并使用 jps 命令查看进程.
jps命令是Java Virtual Machine Process Status Tool的缩写,用于查看当前系统中所有正在运行的Java进程的信息.
jps命令可以列出当前系统中所有正在运行的Java进程的进程ID(PID)和主类名. 通过查看主类名,可以确定Java进程是哪个应用程序的一部分.
jps命令的常用选项包括:
-l:显示主类的完整包名和类名.
-m:显示主类的完整包名和类名,以及传递给主类main()方法的参数.
-v:显示主类的完整包名和类名,以及传递给主类main()方法的参数和JVM参数.
如果,使用 jps 查看进程没有完全输出以上进程信息.
那么可以按照以下方法来排查错误:
1.DataNode或NameNode无法启动,检查 hdfs-site.xml 中的配置信息是否正确.
2.若DataNode还是无法启动,可以 使用以下指令:
通过停止进程、删除临时文件夹和日志文件,以及重新格式化NameNode,可以清除可能导致问题的错误状态和冲突.重新初始化NameNode可以确保集群在干净的状态下启动,并且之前的数据被清除.
3.SecondaryNameNode无法启动,可以 使用 stop-dfs.sh 关闭进程,然后再次尝试启动.
虽然在伪分布式模式下没有显式配置SecondaryNameNode,但Hadoop仍然会启动一个SecondaryNameNode进程. 这个进程会在后台运行,并执行与检查点相关的任务.
接下来进行伪分布的测试, 与之前的本地模式测试文件的不同, 伪分布式的所需文件要存储在HDFS(Hadoop分布式文件系统)中的.
这里使用 hdfs dfs -put input/ / 指令将本地文件系统中的input/目录下的所有文件和子目录上传到HDFS的根目录(/)中

在进行测试之前我们先浏览器中输入 https://hadoop-virtual-machine:9870
用于打开Hadoop集群中的NameNode的Web界面.
在NameNode的Web界面中, 我们可以查看集群的整体状态、文件系统的摘要信息、数据块的分布情况、节点的健康状况等.
点击Utilities,选择 Browse the file system(浏览文件系统).
这样我们就可以查看上传的 input/目录.
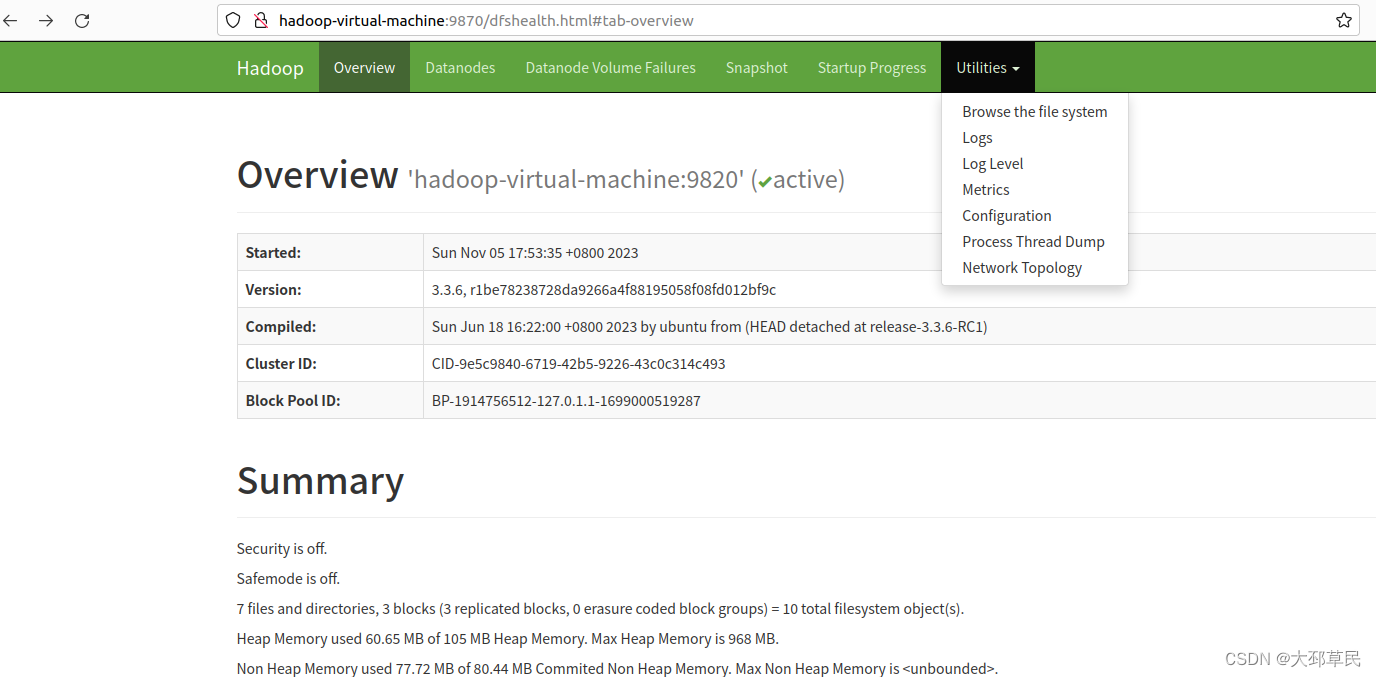
但是这里出现了一个错误提示:
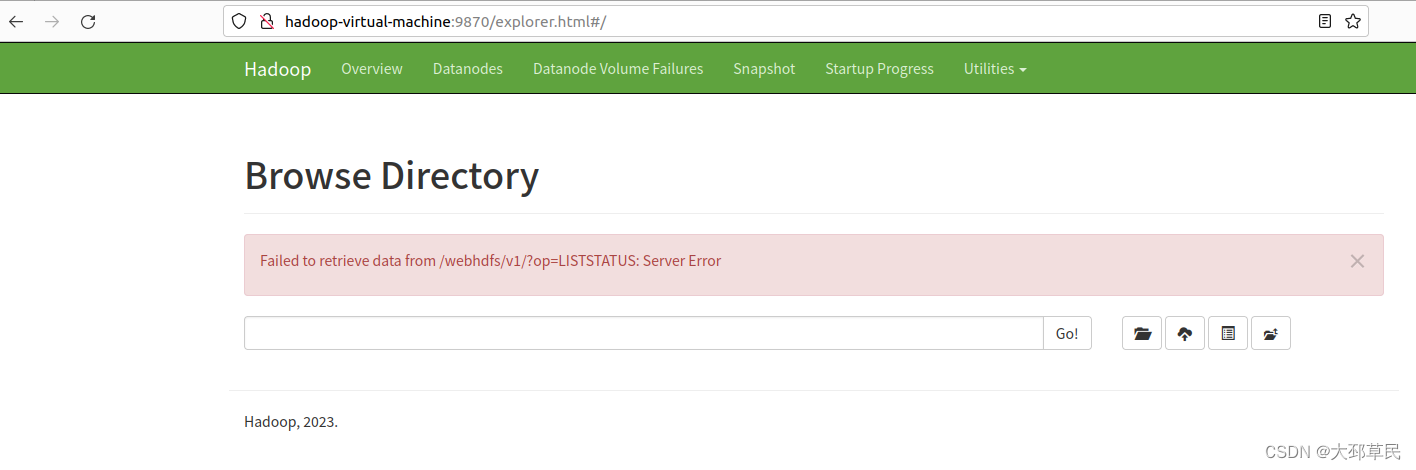
通过ChatGPT的建议并经过我多方面验证,发现并不是由ChatGPT所提到的这些错误所引起的.

后来通过多方面查询有关的博客文章,最终确定是因为与 JDK 的版本不兼容导致的错误.

可以看到之前下载的 JDK 版本过高, Hadoop并不支持.
所以我们还需重新下载一个较低版本的 JDK , 这里下载 JDK 11 版本的(JDK 17 版本的也不支持,通过我的验证).
然后,我们只需在 hadoop-env.sh 文件中,将 JAVA_HOME 指定的路径改为 JDK 11 的路径即可.
此前系统中的 JAVA_HOME 环境变量不需要改动, 这是因为Hadoop启动时所使用的JDK版本是在hadoop-env.sh文件中配置的 JAVA_HOME 环境变量所指定的版本,而不是系统中的环境变量配置的版本.
接着,我们进行测试使用如下指令:
hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /input/ /output
提示:在这个命令中, / 指的是Hadoop分布式文件系统(HDFS)中的根目录
我们可以在Web界面中查看执行的最终结果.

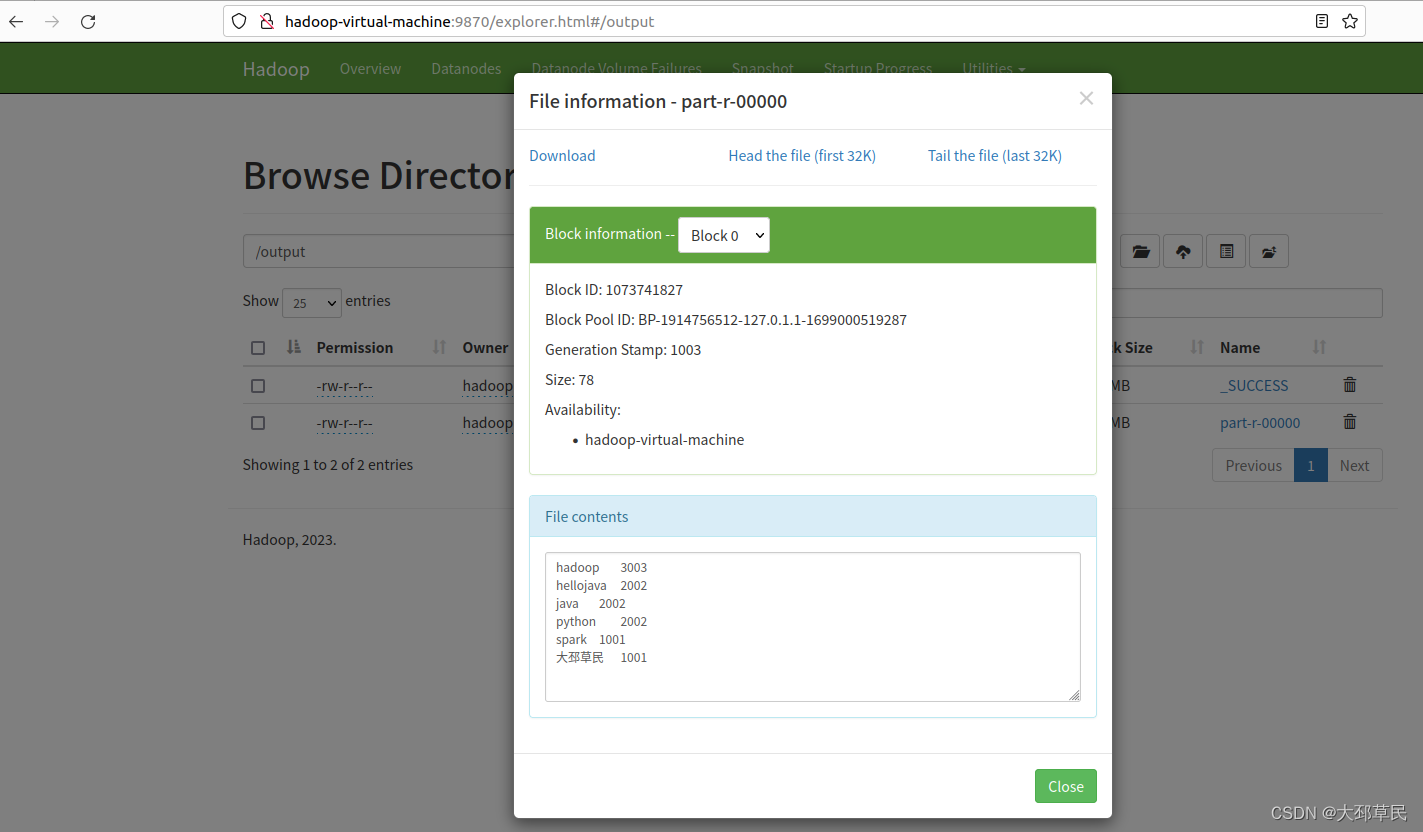
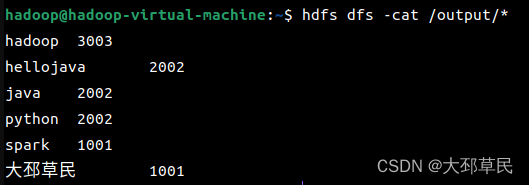
或者在终端中使用如下指令查看: