
- 1使用pip install 时报错:“Fatal error in launcher: Unable to create process using ‘....”_pip install jieba 出现fatal error in launcher
- 2Kafka集群扩容_kafka集群随着扩大之后会发生什么?
- 3职场生存法则和处世之道
- 4使用conda创建虚拟环境,指定python版本,报错,该如何解决_conda create -n python 3.7报错
- 5unity学习笔记 Restsharp 使用心得_unity restsharp
- 6uniapp通过custom-tab-bar 自定义tabbar导航栏(主要用于微信小程序)_uniapp自定义导航栏custom
- 7【UE4 UE5】UE设置屏幕分辨率 全屏、窗口设置的方法_ue5设置分辨率
- 8基于Flink流处理的动态实时电商实时分析系统_基flink的电商销售数据实时分析处理系统的设计与实现
- 9什么是DCMM模型数据管理能力成熟度评估_dcmm数据成熟度模型
- 10狼搜索算法(WSA):利用狼的社交和狩猎策略进行优化_wolf search algorithm
从零开始构建大语言模型(MEAP)_构建语言模型方法
赞
踩
原文:
annas-archive.org/md5/c19a4ef8ab1664a3c5a59d52651430e2译者:飞龙
一、理解大型语言模型
本章包括
-
大型语言模型(LLM)背后的基本概念的高层次解释
-
探索 ChatGPT 类 LLM 源自的 Transformer 架构的深层次解释
-
从零开始构建 LLM 的计划
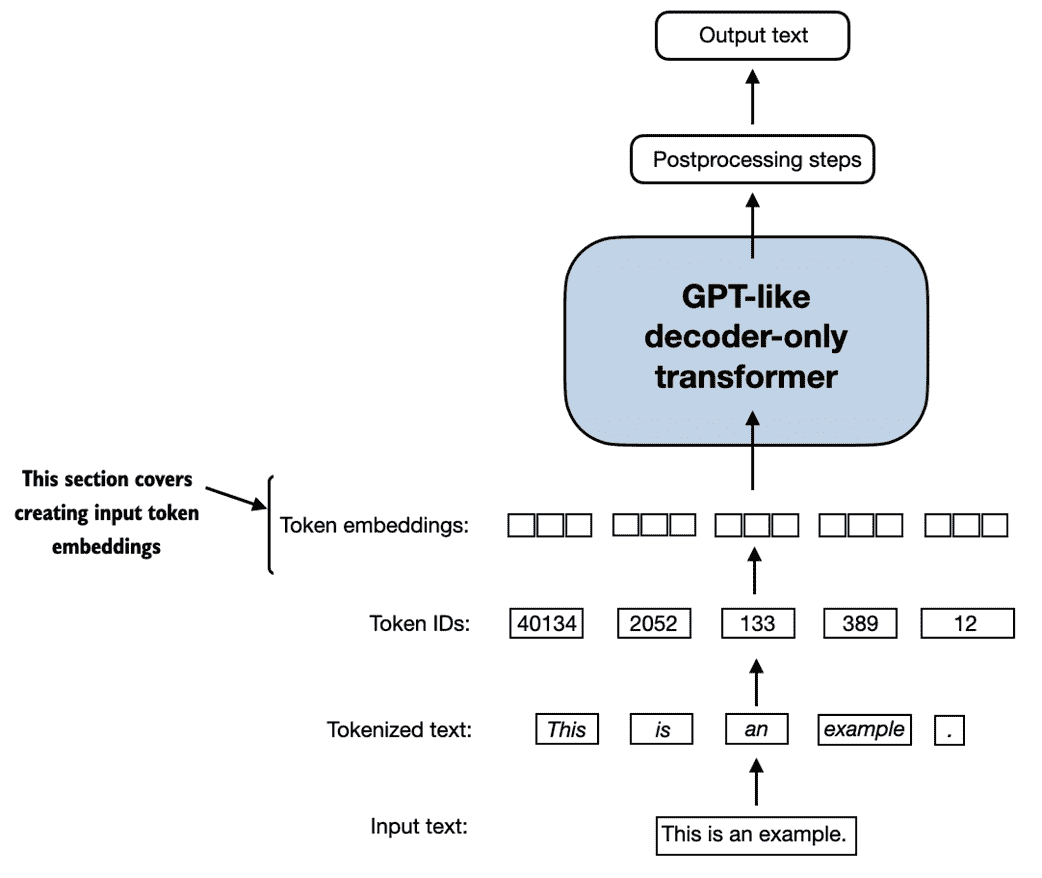
像 ChatGPT 这样的大型语言模型(LLM)是在过去几年中开发的深度神经网络模型。它们引领了自然语言处理(NLP)的新时代。在大型语言模型出现之前,传统方法擅长于分类任务,如电子邮件垃圾分类和可以通过手工制作的规则或简单模型捕获的简单模式识别。然而,在需要复杂理解和生成能力的语言任务方面,例如解析详细说明、进行上下文分析或创建连贯且上下文适当的原始文本时,它们通常表现不佳。例如,以前的语言模型无法根据关键字列表编写电子邮件-这对于当代 LLM 来说是微不足道的任务。
LLM 具有出色的理解、生成和解释人类语言的能力。然而,重要的是澄清,当我们说语言模型“理解”时,我们指的是它们可以以看起来连贯和上下文相关的方式处理和生成文本,而不是它们具有类似人类的意识或理解能力。
在深度学习的推动下,LLM 受益于大量文本数据的训练。这使得 LLM 能够捕获比以前更深层次的语境信息和人类语言的微妙之处。因此,LLM 在各种 NLP 任务中的性能显着提高,包括文本翻译、情感分析、问答等等。
当代 LLM 与早期 NLP 模型之间的另一个重要区别是,后者通常是为特定任务而设计的;而早期的 NLP 模型在其狭窄应用中表现出色,LLM 则在各种 NLP 任务中展示出更广泛的熟练程度。
LLM 背后的成功归功于 Transformer 架构,该架构支撑了许多 LLM,并且 LLM 训练的大量数据,使它们能够捕捉到各种语言细微差别、语境和模式,这些模式是难以手工编码的。
将模型基于 Transformer 架构实现,并使用大型训练数据集来训练 LLM 的这一转变,从根本上改变了 NLP,为理解和与人类语言交互提供了更有能力的工具。
从本章开始,我们为实现本书的主要目标奠定基础:通过逐步在代码中实现基于 Transformer 架构的 ChatGPT 样式 LLM 来理解 LLM。
1.1 什么是 LLM?
LLM,即大型语言模型,是一种设计用于理解、生成和回应类似人类文本的神经网络。这些模型是在大量文本数据上训练的深度神经网络,有时包括互联网上整个可公开获取文本的大部分内容。
"大型"语言模型中的"大"既指模型在参数方面的规模,也指其所训练的庞大数据集。这样的模型通常具有数百亿甚至数百亿个参数,这些参数是网络中的可调权重,在训练过程中进行优化,以预测序列中的下一个词。下一个词的预测是合理的,因为它利用了语言固有的顺序性质来训练模型,使其理解文本中的上下文、结构和关系。然而,这是一个非常简单的任务,许多研究人员会感到惊讶的是,它能够产生如此有能力的模型。我们将在后续章节逐步讨论并实施下一个词的训练过程。
LLMs 利用一种称为transformer的架构(在第 1.4 节中更详细地介绍),使它们在进行预测时能够有选择地关注输入的不同部分,使其特别擅长处理人类语言的细微差别和复杂性。
由于 LLMs 能够生成文本,所以 LLMs 也经常被称为一种生成人工智能(AI)的形式,通常简称为生成 AI或GenAI。如图 1.1 所示,AI 涵盖了创建能够执行需要类似人类智能的任务的机器的更广泛领域,包括理解语言、识别模式和做决策,并包括诸如机器学习和深度学习之类的子领域。
图 1.1 正如这一层次化的关系图所示,LLMs 代表了深度学习技术的一种特定应用,利用它们处理和生成类似人类文本的能力。深度学习是一种专门的机器学习分支,专注于使用多层神经网络。机器学习和深度学习是旨在实现使计算机能够从数据中学习并执行通常需要人类智能的任务的算法领域。人工智能领域如今被机器学习和深度学习主导,但也包括其他方法,例如使用基于规则的系统、遗传算法、专家系统、模糊逻辑或符号推理。
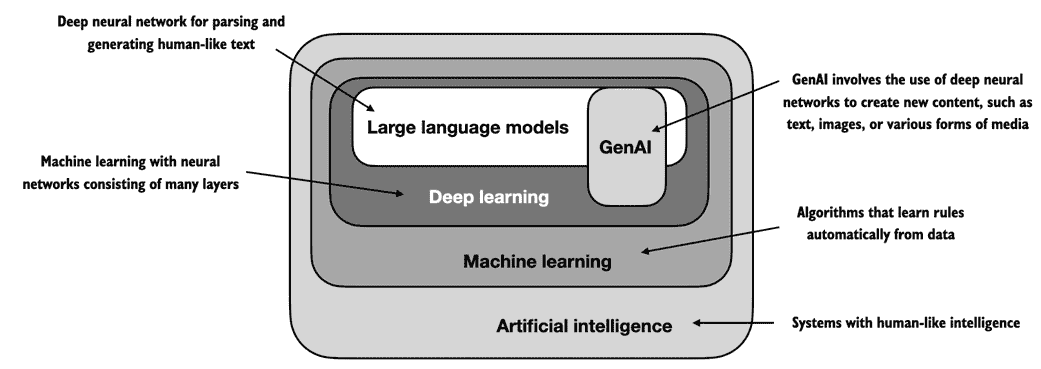
用于实现人工智能的算法是机器学习领域的重点。具体而言,机器学习涉及开发可以从数据中学习并基于数据进行预测或决策而无需明确编程的算法。为了说明这一点,可以将垃圾邮件过滤器作为机器学习的实际应用。与手动编写规则来识别垃圾邮件不同,机器学习算法将被提供标记为垃圾邮件和合法邮件的示例。通过在训练数据集上最小化其预测错误,模型可以学习识别与垃圾邮件相关的模式和特征,从而能够将新邮件分类为垃圾邮件或合法邮件。
深度学习是机器学习的一个子集,专注于利用有三层或更多层的神经网络(也称为深度神经网络)来对数据中的复杂模式和抽象进行建模。与深度学习相反,传统机器学习需要手动提取特征。这意味着人类专家需要识别和选择对模型最相关的特征。
回顾垃圾邮件分类的例子,在传统机器学习中,人类专家可能会从电子邮件文本中手动提取特征,例如特定触发词(“prize”,“win”,“free”)的频率,感叹号的数量,使用全大写单词或怀疑链接的存在。基于这些专家定义的特征创建的数据集将用于训练模型。与传统机器学习相比,深度学习不需要手动提取特征。这意味着人类专家不需要为深度学习模型识别和选择最相关的特征。
接下来的几节将涵盖 LLM(大型语言模型)今天可以解决的一些问题,LLM 解决的挑战,以及我们将在本书中实现的通用 LLM 架构。
1.2 LLM 的应用
由于 LLM 具有解析和理解非结构化文本数据的高级能力,LLM 在各个领域都有广泛的应用。目前,LLM 被应用于机器翻译、生成新颖文本(参见图 1.2)、情感分析、文本摘要和许多其他任务。LLM 最近还用于内容创作,如写小说、文章甚至是计算机代码。
图 1.2 LLM 接口实现了用户和人工智能系统之间的自然语言交流。该截图显示 ChatGPT 根据用户的规格要求写诗。
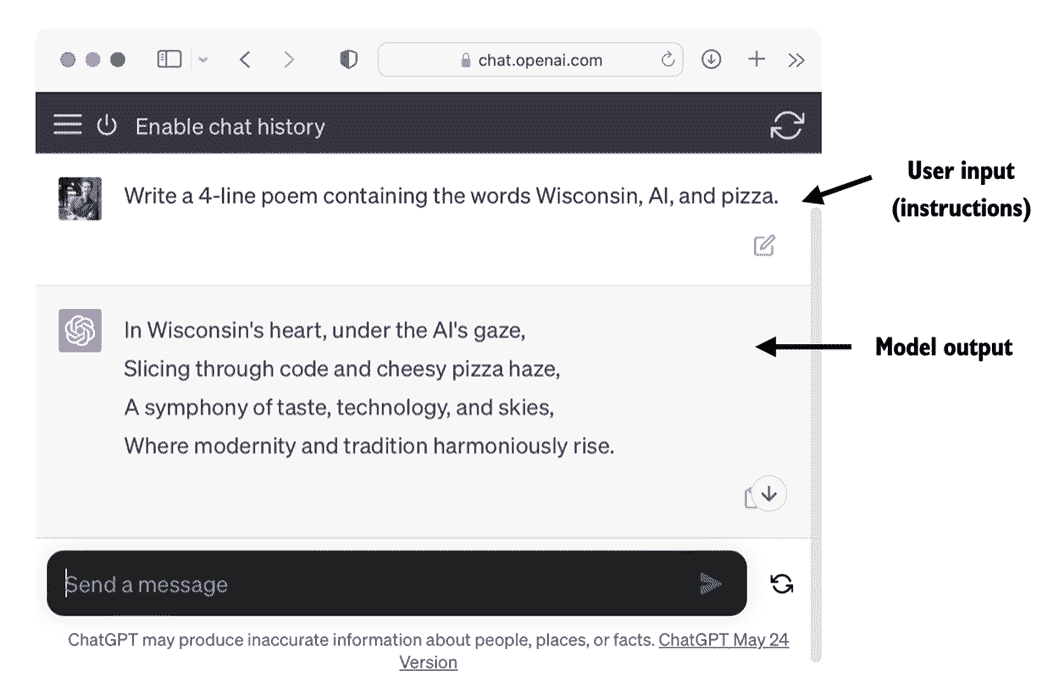
LLM 还可以为复杂的聊天机器人和虚拟助手提供动力,例如 OpenAI 的 ChatGPT 或 Google 的 Bard,它们可以回答用户提问并增强传统搜索引擎(如 Google Search 或 Microsoft Bing)。
此外,LLM 可以用于有效地从专业领域的大量文本中检索知识,如医学或法律。这包括筛选文件、总结长篇文章和回答技术问题。
简而言之,LLM 对于自动化几乎任何涉及解析和生成文本的任务都是无价的。它们的应用几乎是无限的,随着我们不断创新和探索使用这些模型的新方法,很明显,LLM 有潜力重新定义我们与技术的关系,使其更具对话性、直观和可访问性。
在本书中,我们将重点关注从零开始理解 LLM(大型语言模型)的工作原理,编写一个能够生成文本的 LLM。我们还将学习一些技术,使 LLM 能够进行各种查询,从回答问题到总结文本、将文本翻译成不同语言等等。换句话说,在本书中,我们将通过逐步构建一个 LLM 来了解复杂的 LLM 助手(如 ChatGPT)是如何工作的。
1.3 构建和使用 LLM 的阶段
我们为什么要构建自己的 LLM 呢?从零开始编写一个 LLM 是一个很好的练习,可以理解其机制和局限性。此外,这使我们具备了必要的知识,可以对现有的开源 LLM 架构进行预训练或微调,以适应我们自己的领域特定数据集或任务。
研究表明,就建模性能而言,定制的 LLM——针对特定任务或领域定制的 LLM——可能会优于 ChatGPT 等通用 LLM,后者设计用于广泛的应用。其中的例子包括专门用于金融领域的 BloombergGPT,以及专门用于医学问题回答的 LLM(请参阅本章末尾的进一步阅读和参考部分了解更多细节)。
创建 LLM 的一般过程,包括预训练和微调。在“预训练”中的“pre”一词指的是初始阶段,其中像 LLM 这样的模型在大型、多样的数据集上进行训练,以开发对语言的广泛理解。然后,这个预训练模型作为一个基础资源,可以通过微调进一步完善,微调是指模型在更具体于特定任务或领域的较窄数据集上进行专门训练的过程。图 1.3 展示了这个包括预训练和微调的两阶段训练方法。
图 1.3 对 LLM 进行预训练包括对大型未标记文本语料库(原始文本)进行下一个词预测。然后,可以使用较小的标记数据集对预训练的 LLM 进行微调。
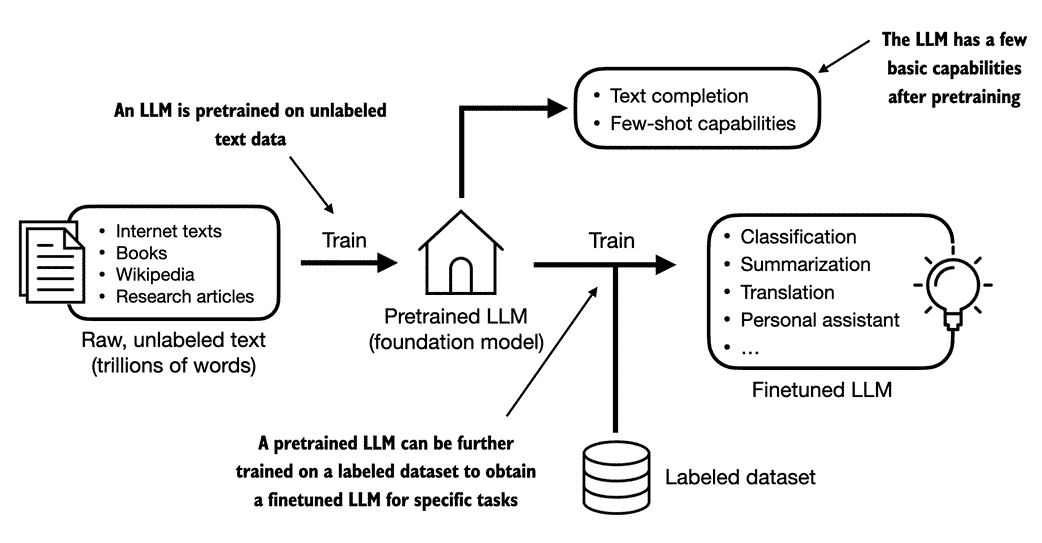
如图 1.3 所示,创建 LLM 的第一步是对大量文本数据进行训练,有时被称为原始文本。这里,“原始”指的是这些数据只是普通文本,没有任何标记信息[1]。(可能会应用过滤,如删除格式字符或未知语言的文档。)
LLM 的第一个训练阶段也称为预训练,创建一个初始的预训练 LLM,通常称为基础模型或基础模型。这种模型的典型例子是 GPT-3 模型(ChatGPT 的前身)。该模型能够完成文本,即完成用户提供的半写句。它还具有有限的 few-shot 能力,这意味着它可以根据少量示例学习执行新任务,而不需要大量训练数据。这在接下来的部分为不同任务使用变换器中进一步阐述。
从在未标记文本上训练的预训练LLM 中获得之后,我们可以进一步在标记数据上训练 LLM,也称为微调。
用于微调 LLM 的两个最流行的类别包括指导微调和用于分类任务的微调。在指导微调中,标记的数据集包括指导和答案对,例如需要翻译文本的查询和正确翻译文本。在分类微调中,标记的数据集包括文本和相关的类别标签,例如与垃圾邮件和非垃圾邮件标签相关联的电子邮件。
在本书中,我们将涵盖预训练和微调 LLM 的代码实现,并且我们会更深入地研究指导微调和分类微调的具体内容,这将在本书中在预训练基础 LLM 后进行。
1.4 为不同任务使用 LLM
大多数现代 LLM 依赖变换器架构,这是一种深度神经网络架构,首次引入于 2017 年的论文Attention Is All You Need。要理解 LLM,我们需要简要回顾原始变换器,它最初用于机器翻译,将英文文本翻译成德语和法语。图 1.4 描述了变换器架构的简化版本。
图 1.4 原始变换器架构的简化描述,这是一个用于语言翻译的深度学习模型。变换器由两部分组成,一个处理输入文本并生成嵌入表示的编码器(捕捉许多不同因素在不同维度中的数字表示)和一个解码器,后者可以使用该表示来逐字生成翻译文本。请注意,该图显示了翻译过程的最终阶段,其中解码器只需生成最终单词(“Beispiel”),给定原始输入文本(“This is an example”)和部分翻译的句子(“Das ist ein”),以完成翻译。图中的编号指示数据处理的顺序,并提供有关最佳阅读图的指导。
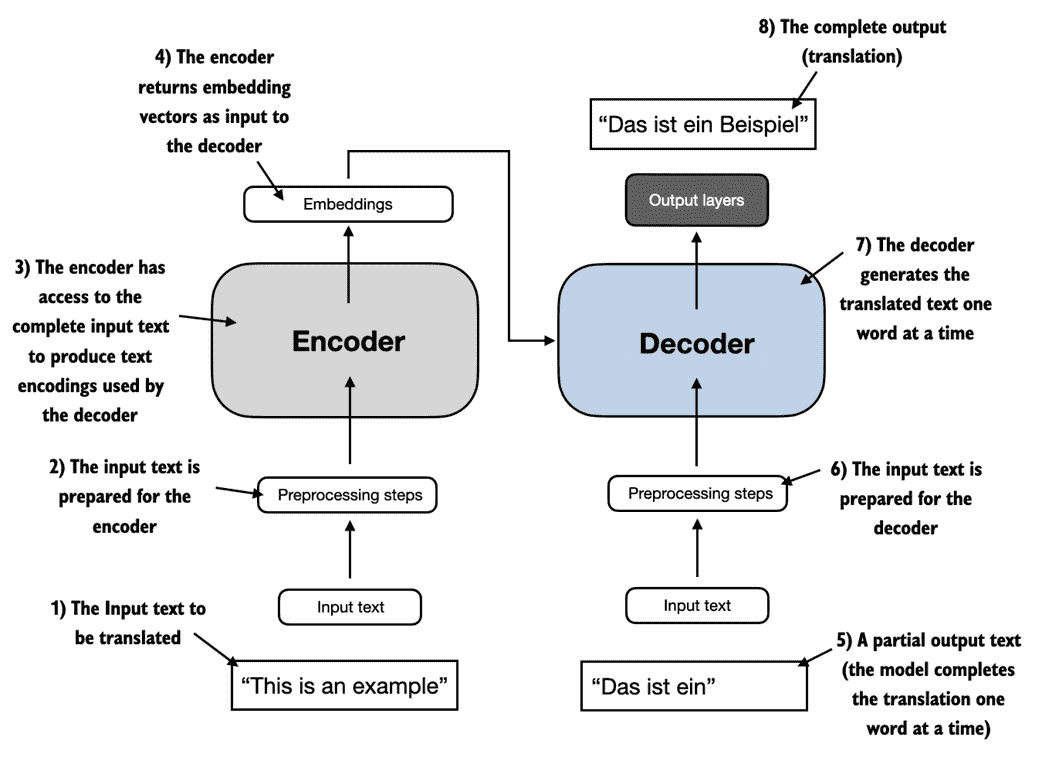
图 1.4 中描绘的 transformer 架构由两个子模块组成,一个编码器和一个解码器。编码器模块处理输入文本并将其编码为一系列捕捉输入上下文信息的数值表示或向量。然后,解码器模块会从这些编码向量中生成输出文本。例如,在翻译任务中,编码器会将源语言的文本编码成向量,解码器则会将这些向量解码为目标语言的文本。编码器和解码器都由许多层连接的所谓自注意机制组成。关于如何预处理和编码输入,你可能有很多问题。这些将在随后的章节中逐步实现中得到解答。
transformer 和 LLMs 的关键组成部分是自注意机制(未显示),它允许模型权衡序列中不同单词或标记的重要性相对于彼此。这一机制使得模型能够捕捉长距离依赖和输入数据中的上下文关系,增强了生成连贯和有上下文相关性输出的能力。然而,由于其复杂性,我们将在第三章详细讨论并逐步实现这一解释。此外,我们还将在《第二章,处理文本数据》中讨论和实现数据预处理步骤来创建模型输入。
后来的变种 transformer 架构,如所谓的 BERT(双向编码器表示来自 transformer)和各种 GPT 模型(生成式预训练 transformer),建立在这一概念上,以适应不同任务的体系结构。 (参考可以在本章结束处的进一步阅读部分找到。)
BERT,它是建立在原始 transformer 编码器子模块基础之上的,与 GPT 在训练方法上有所不同。虽然 GPT 设计用于生成任务,BERT 及其变体专门用于掩码词预测,模型会预测给定句子中的掩码或隐藏单词,如图 1.5 所示。这种独特的训练策略使得 BERT 在文本分类任务中具有优势,包括情绪预测和文档分类。截至目前,Twitter 使用 BERT 来检测有害内容,这是其能力的一个应用。
图 1.5 transformer 的编码器和解码器子模块的可视化表示。在左侧,编码器部分举例说明了类似 BERT 的 LLMs,其专注于掩码词预测,主要用于文本分类等任务。在右侧,解码器部分展示了类似 GPT 的 LLMs,设计用于生成任务并生成连贯的文本序列。

另一方面,GPT 侧重于原始变压器架构的解码器部分,旨在处理需要生成文本的任务。这包括机器翻译、文本摘要、虚构写作、编写计算机代码等。我们将在本章的其余部分更详细地讨论 GPT 架构,并在本书中从头开始实现它。
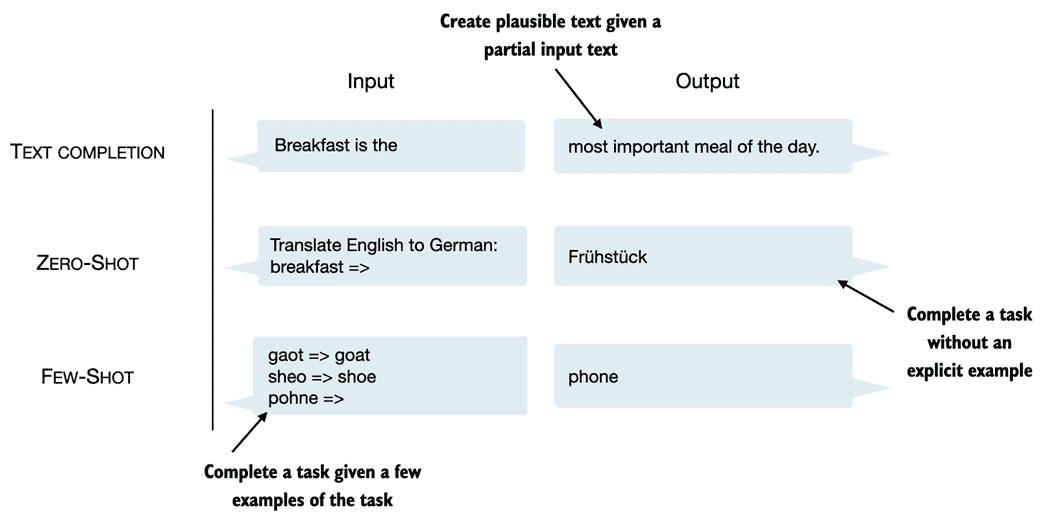
GPT 模型主要设计和训练用于执行文本完成任务,同时在其能力上显示出出色的多功能性。这些模型擅长执行零样本和少样本学习任务。零样本学习指的是在没有任何先前特定示例的情况下对完全不可见任务进行概括的能力。另一方面,少样本学习涉及从用户提供的最少数量示例中学习,如图 1.6 所示。
图 1.6 除了文本完成之外,类似 GPT 的 LLM 可以根据其输入解决各种任务,无需重新训练、微调或特定于任务的模型架构更改。有时,在输入中提供目标示例是有帮助的,这被称为少样本设置。然而,类似 GPT 的 LLM 也能够在没有具体示例的情况下执行任务,这被称为零样本设置。
变压器与 LLM
当前的 LLM 基于前面介绍的变压器架构。因此,在文献中常常将变压器和 LLM 等术语用作同义词。然而,需要注意的是,并非所有的变压器都是 LLM,因为变压器也可以用于计算机视觉。另外,并非所有的 LLM 都是变压器,因为还有基于循环和卷积架构的大型语言模型。这些替代方法背后的主要动机是提高 LLM 的计算效率。然而,这些替代的 LLM 架构是否能与基于变压器的 LLM 的能力竞争,并且它们是否会被实际采用还有待观察。(感兴趣的读者可以在本章末尾的进一步阅读部分找到描述这些架构的文献引用。)
1.5 利用大型数据集
流行的 GPT 和 BERT 等模型的大型训练数据集包含数十亿字的多样化和全面的文本语料库,涵盖了大量主题以及自然语言和计算机语言。为了提供一个具体的例子,表 1.1 总结了用于预训练 GPT-3 的数据集,这为 ChatGPT 的第一个版本提供了基础模型。
表 1.1 流行的 GPT-3 LLM 的预训练数据集
| 数据集名称 | 数据集描述 | 标记数量 | 在训练数据中的比例 |
|---|---|---|---|
| CommonCrawl(经过过滤) | 网络爬虫数据 | 4100 亿 | 60% |
| 网页文本 2 | 网络爬虫数据 | 190 亿 | 22% |
| 图书 1 | 基于互联网的图书语料库 | 120 亿 | 8% |
| 图书 2 | 基于互联网的图书语料库 | 550 亿 | 8% |
| 维基百科 | 高质量文本 | 30 亿 | 3% |
表 1.1 报告了标记的数量,其中一个标记是模型读取的文本单位,数据集中的标记数量大致相当于文本中的单词和标点符号的数量。我们将在下一章更详细地介绍标记化的过程,即将文本转换为标记的过程。
主要的要点是这个训练数据集的规模和多样性,使这些模型在包括语言句法、语义和内容的各种任务上表现良好,甚至包括一些需要一般知识的任务。
GPT-3 数据集详细信息
请注意,表 1.1 中的每个子集都是抽样自 3000 亿个标记,这意味着并非所有数据集都完全被看到,有些甚至被多次看到。除四舍五入之外,比例列加起来为 100%。作为参考,CommonCrawl 数据集中的 4100 亿个标记大约需要 570GB 的存储空间。基于 GPT-3 的后续模型,如 Meta 的 LLaMA,还包括来自 Arxiv 的研究论文(92GB)和来自 StackExchange 的与代码相关的问答(78GB)。
维基百科语料库由英语维基百科组成。虽然 GPT-3 论文的作者没有进一步说明细节,但 Books1 很可能是从古登堡计划(www.gutenberg.org/)中抽样而来,而 Books2 很可能是来自 Libgen(en.wikipedia.org/wiki/Library_Genesis)。CommonCrawl 是 CommonCrawl 数据库的筛选子集(commoncrawl.org/),而 WebText2 是来自帖子中出现过 3 个以上赞的 Reddit 链接的网页文本。
GPT-3 论文的作者没有公开训练数据集,但一个可比较的公开可用的数据集是 The Pile(pile.eleuther.ai/)。不过,这个收集可能包含有版权作品,而且确切的使用条款可能取决于使用案例和国家。有关更多信息,请参阅 HackerNews 上的讨论news.ycombinator.com/item?id=25607809。
这些模型的预训练性使它们在进一步微调下游任务时变得非常灵活,这也是它们被称为基础模型的原因。预训练 LLM 需要大量资源,并且代价非常高昂。例如,据估计 GPT-3 的预训练成本为 460 万美元的云计算费用[2]。
好消息是,许多预训练的 LLM 模型可以作为通用工具用于写作、提取和编辑不属于训练数据的文本,并且这些模型也可以在相对较小的数据集上进行微调,以降低所需的计算资源,并且改善在特定任务上的性能。
在本书中,我们将实现用于预训练的代码,并将其用于教育目的。所有计算都可以在消费者硬件上执行。在实现预训练代码之后,我们将学习如何重用公开可用的模型权重,并将它们加载到我们将要实现的架构中,从而使我们能够在本书后期微调 LLM 时跳过昂贵的预训练阶段。
1.6 更详细地了解 GPT 架构
在本章中之前,我们提到了类似 GPT 模型、GPT-3 和 ChatGPT 的术语。现在让我们更仔细地看一下通用的 GPT 架构。首先,GPT 代表Generative Pretrained Transformer,最初是在以下论文中介绍的:
- 通过生成预训练提高语言理解 (2018) 由 OpenAI 的Radford 等人提出,
cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
GPT-3 是该模型的一个规模扩大版本,具有更多的参数,并且是在一个更大的数据集上训练的。而最初的 ChatGPT 模型是通过对 GPT-3 在一个大型指导数据集上进行微调而创建的,使用了 OpenAI 的 InstructGPT 论文中的一种方法,我们将在第八章,通过人类反馈微调以遵循指示中详细介绍这种方法。正如我们在图 1.6 中早期看到的那样,这些模型是称职的文本补全模型,并且可以执行其他任务,比如拼写校正、分类或语言翻译。鉴于 GPT 模型是在一个相对简单的下一个单词预测任务上进行预训练的,正如图 1.7 所示,这实际上是非常了不起的。
图 1.7 在 GPT 模型的下一个单词预训练任务中,系统通过查看之前出现过的单词来预测句子中即将出现的单词。这种方法有助于模型理解单词和短语在语言中通常是如何配合使用的,形成一个可以应用于各种其他任务的基础。

下一个单词预测任务是一种自监督学习形式,是一种自我标记形式。这意味着我们不需要显式地为训练数据收集标签,而是可以利用数据本身的结构:我们可以使用句子或文档中的下一个单词作为模型要预测的标签。由于这个下一个单词预测任务允许我们"即兴"地创建标签,所以可以利用大规模的未标记文本数据集来训练 LLM,如前面第 1.5 节中所讨论的。
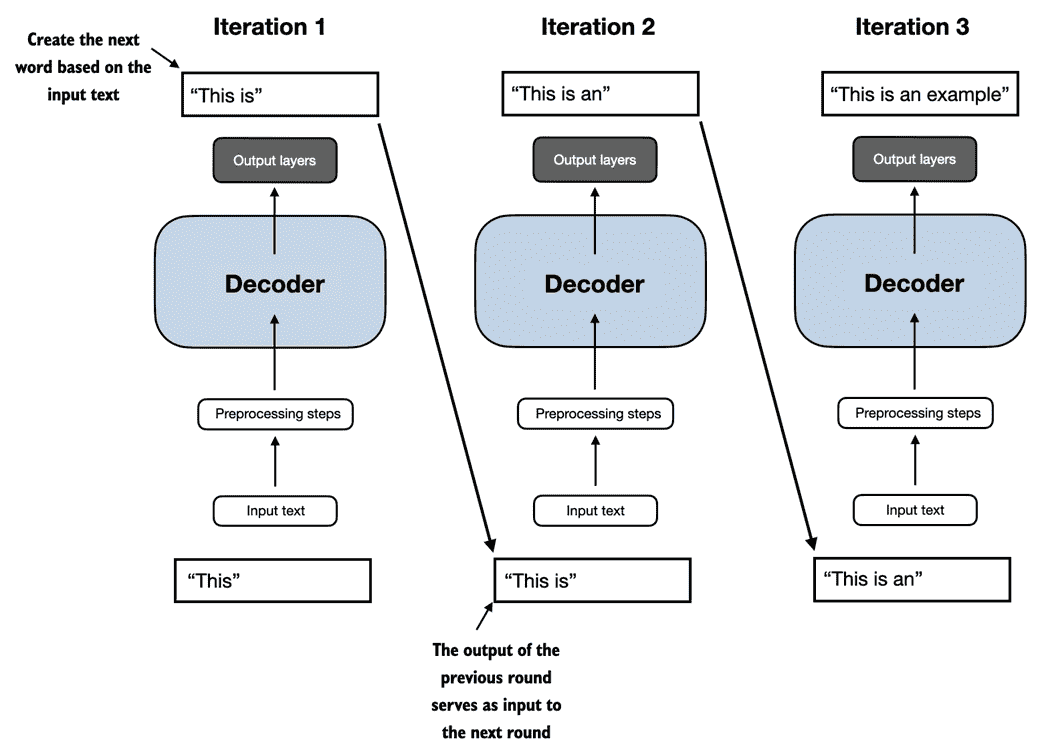
与我们在第 1.4 节中介绍的原始 Transformer 架构相比,使用 LLM 执行不同任务,通用 GPT 架构相对简单。从本质上讲,它只是解码器部分,没有编码器,如图 1.8 所示。由于像 GPT 这样的解码器样式模型通过逐字预测文本生成文本,因此它们被认为是一种自回归模型。
诸如 GPT-3 之类的架构也比原始的 transformer 模型要大得多。例如,原始的 transformer 将编码器和解码器块重复六次。GPT-3 共有 96 个 transformer 层和 1750 亿个参数。
图 1.8 GPT 架构仅使用原始 transformer 的解码器部分。它被设计为单向从左到右的处理,非常适合文本生成和下一个单词预测任务,以逐步生成一次一个单词的文本。
GPT-3 是在 2020 年推出的,从深度学习和 LLM 发展的标准来看,这已经是很久之前了,而像 Meta 的 Llama 模型这样更近期的架构仍然基于相同的基本概念,只是进行了一些细微的修改。因此,理解 GPT 仍然像以往一样重要,而本书侧重于实现 GPT 背后突出的架构,并提供指向替代 LLMs 使用的具体调整。
最后,有趣的是,尽管原始的 transformer 模型明确设计用于语言翻译,但 GPT 模型——尽管其更大但更简单的架构旨在进行下一个单词的预测——也能够执行翻译任务。这种能力最初对研究人员来说是意外的,因为它源自一个主要训练于下一个单词预测任务上的模型,而这是一个并不专门针对翻译的任务。
模型能够执行其未明确接受训练的任务称为“新兴属性”。这种能力在训练期间并未得到明确教导,但是作为模型暴露于各种多语言环境下的大量数据的自然结果而出现。事实上,GPT 模型可以“学习”语言之间的翻译模式,并执行翻译任务,即使它们并没有针对此进行专门训练,这显示了这些大规模生成语言模型的优势和能力。我们可以执行各种任务而无需为每个任务使用不同的模型。
1.7 构建大型语言模型
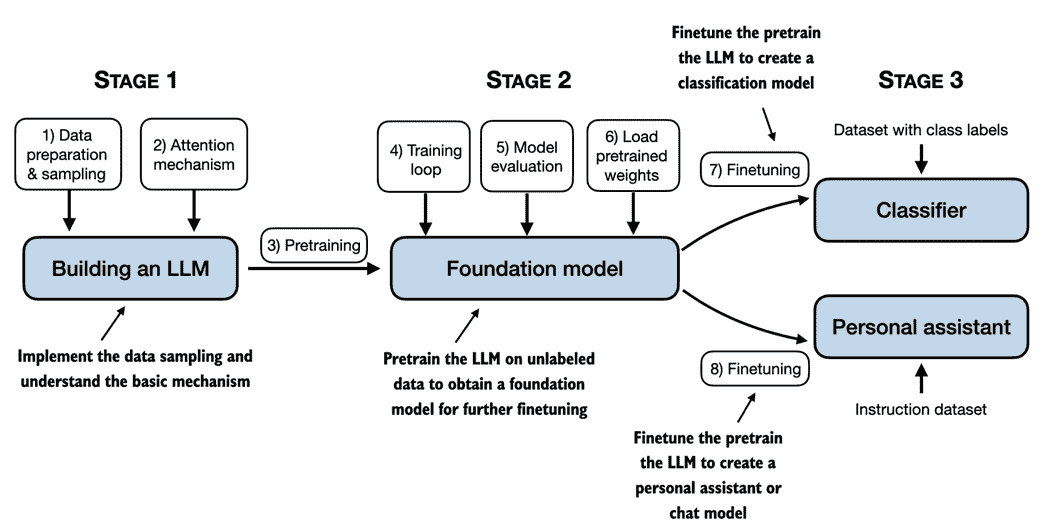
在本章中,我们为理解 LLMs 奠定了基础。在本书的剩余部分中,我们将从头开始编写一个 LLM。我们将以 GPT 背后的基本思想作为蓝本,并按照图 1.9 中的概述分三个阶段来解决这个问题。
图 1.9 本书涵盖的构建 LLMs 的阶段包括实现 LLM 架构和数据准备过程,预训练 LLM 以创建基础模型,以及对基础模型进行微调以成为个人助理或文本分类器。
首先,我们将学习基本的数据预处理步骤,并编写是每个 LLM 核心的注意力机制。
接下来,在第 2 阶段,我们将学习如何编码和预训练一个类似 GPT 的 LLM,能够生成新的文本。并且我们还将深入研究评估 LLMs 的基础知识,这对于开发功能强大的自然语言处理系统至关重要。
请注意,从零开始预训练大型 LLM 是一项重大工作,在 GPT-like 模型的计算成本中需要数千到数百万美元。因此,第 2 阶段的重点是利用小型数据集进行教育目的的训练实施。此外,本书还将提供加载公开可用模型权重的代码示例。
最后,在第 3 阶段,我们将获取一个预训练的 LLM,并对其进行微调,以遵循诸如回答查询或分类文本等指令–这是许多现实应用和研究中最常见的任务。
希望您期待着踏上这段令人兴奋的旅程!
1.8 总结
-
LLMs 已经改变了自然语言处理领域,之前依赖于显式基于规则的系统和更简单的统计方法。LLMs 的出现引入了新的深度学习驱动方法,推动了对人类语言的理解、生成和翻译的进步。
-
现代 LLMs 的训练主要分为两个步骤。
-
首先,它们通过使用句子中下一个单词的预测作为"标签",在大型未标记文本语料库上进行预训练。
-
然后,它们在较小的、标记的目标数据集上进行微调,以遵循指令或执行分类任务。
-
LLMs 基于 Transformer 架构。Transformer 架构的关键思想是一个注意力机制,在逐词生成输出时,给予 LLM 对整个输入序列的选择性访问。
-
原始的 Transformer 架构包括一个用于解析文本的编码器和一个用于生成文本的解码器。
-
用于生成文本和遵循指令的 LLMs,如 GPT-3 和 ChatGPT,仅实现解码器模块,简化了架构。
-
由数十亿字组成的大型数据集对于 LLMs 的预训练至关重要。在本书中,我们将实现并训练 LLMs 以用于教育目的的小型数据集,还将了解如何加载公开可用的模型权重。
-
尽管 GPT-like 模型的一般预训练任务是预测句子中的下一个单词,但这些 LLMs 展现出"新兴"属性,如分类、翻译或总结文本的能力。
-
一旦 LLM 被预训练,产生的基础模型可以更高效地针对各种下游任务进行微调。
-
使用定制数据集进行微调的 LLMs 可以在特定任务上胜过通用 LLMs。
1.9 参考和进一步阅读
由于一支彭博团队展示的 LLMs 在金融数据上从零开始预训练的 GPT 版本,定制 LLMs 能够在金融任务上胜过 ChatGPT,同时在通用 LLM 基准测试中表现良好:
-
BloombergGPT:一种用于金融的大型语言模型 (2023)由吴等人撰写,
arxiv.org/abs/2303.17564 -
现有的 LLM 也可以被调整和微调,以表现出优于一般 LLM 的潜力,谷歌研究组和谷歌 DeepMind 团队在医疗领域展示了这一点:
-
通过大型语言模型实现专业水平医学问答 (2023)由辛哈尔等人撰写,
arxiv.org/abs/2305.09617 -
提出原始变压器架构的论文:
-
注意力机制就是一切 (2017)由瓦斯瓦尼等人撰写,
arxiv.org/abs/1706.03762 -
原始的编码器式变压器,称为 BERT:
-
BERT:深度双向变压器进行语言理解的预训练 (2018)由德夫林等人撰写,
arxiv.org/abs/1810.04805。 -
描述解码器式 GPT-3 模型的论文,这激发了现代 LLM 的开发,并将被用作在本书中从头开始实现 LLM 的模板:
-
语言模型是少样本学习者 (2020)由布朗等人撰写,
arxiv.org/abs/2005.14165。 -
用于分类图像的原始视觉变压器,说明变压器架构不仅限于文本输入:
-
一幅图等于 16x16 个字:大规模图像识别的变压器 (2020)由多索维茨基等人撰写,
arxiv.org/abs/2010.11929 -
两种实验性(但较不流行)的 LLM 架构作为示例,说明不是所有的 LLM 都必须基于变压器架构:
-
RWKV:为变压器时代重新设计 RNN (2023)由彭等人撰写,
arxiv.org/abs/2305.13048 -
*鬣狗等级结构:向更大的卷积语言模型迈进(2023 年)*由波利等人撰写,
arxiv.org/abs/2302.10866 -
Meta AI 的模型是一个流行的 GPT 样式模型的实现,与 GPT-3 和 ChatGPT 相比是开放可用的:
-
Llama 2:开放基础和微调的聊天模型 (2023)由特文等人撰写,
arxiv.org/abs/2307.092881 -
对于对第 1.5 节中提到的数据集引用感兴趣的读者,这篇论文描述了由 Eleuther AI 策划的公开可用的The Pile数据集:
-
堆叠:一份包含多样文本的 800GB 数据集用于语言建模 (2020)由高等人撰写,
arxiv.org/abs/2101.00027。 -
训练语言模型遵循人类反馈指令 (2022)由欧阳等人撰写,
arxiv.org/abs/2203.02155
[1] 有机器学习背景的读者可能会注意到,传统机器学习模型和通过传统监督学习范式训练的深度神经网络通常需要标签信息。但是,这并不适用于 LLM 的预训练阶段。在这个阶段,LLM 利用自监督学习,模型从输入数据中生成自己的标签。这个概念稍后在本章中会有介绍
[2] GPT-3,460 万美元的语言模型,www.reddit.com/r/MachineLearning/comments/h0jwoz/d_gpt3_the_4600000_language_model/
二、使用文本数据
本章涵盖内容
-
为大型语言模型训练准备文本
-
将文本分割成单词和子单词标记
-
字节对编码作为一种更高级的文本标记化方式
-
使用滑动窗口方法对训练样本进行抽样
-
将标记转换为输入大型语言模型的向量
在上一章中,我们深入探讨了大型语言模型(LLMs)的一般结构,并了解到它们在大量文本上进行了预训练。具体来说,我们关注的是基于变压器架构的解码器专用 LLMs,这是 ChatGPT 和其他流行的类 GPT LLMs 的基础。
在预训练阶段,LLM 逐个单词处理文本。利用亿万到数十亿参数的 LLM 进行下一个词预测任务的训练,可以产生具有令人印象深刻能力的模型。然后可以进一步微调这些模型以遵循一般指示或执行特定目标任务。但是,在接下来的章节中实施和训练 LLM 之前,我们需要准备训练数据集,这是本章的重点,如图 2.1 所示
图 2.1 LLM 编码的三个主要阶段的心理模型,LLM 在一般文本数据集上进行预训练,然后在有标签的数据集上进行微调。本章将解释并编写提供 LLM 预训练文本数据的数据准备和抽样管道。
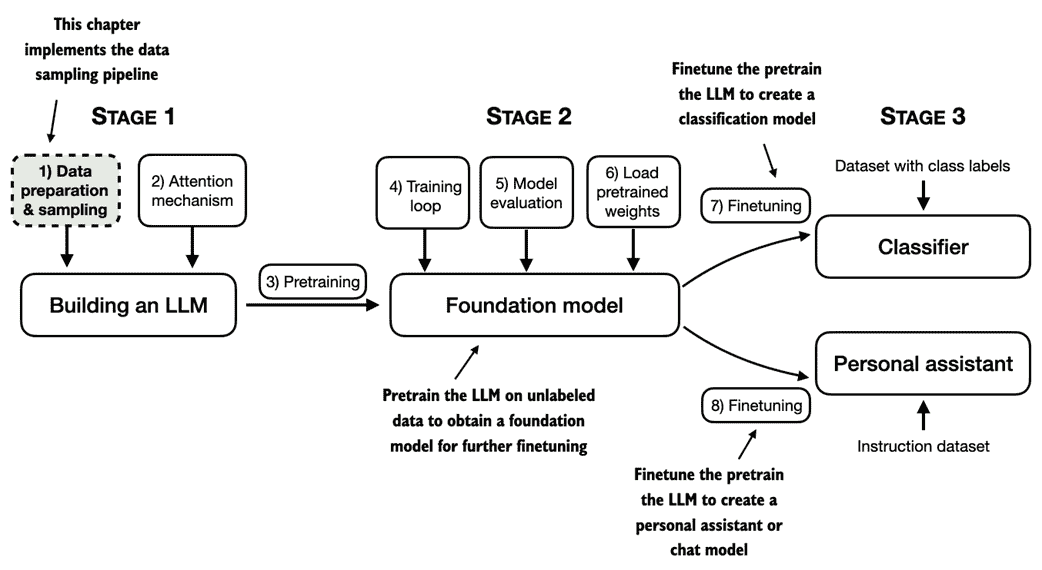
在本章中,您将学习如何准备输入文本以进行 LLM 训练。这涉及将文本拆分为单独的单词和子单词标记,然后将其编码为 LLM 的向量表示。您还将学习有关高级标记方案,如字节对编码,这在像 GPT 这样的流行 LLM 中被使用。最后,我们将实现一种抽样和数据加载策略,以生成后续章节中训练 LLM 所需的输入-输出对。
2.1 理解词嵌入
深度神经网络模型,包括 LLM,无法直接处理原始文本。由于文本是分类的,所以它与用于实现和训练神经网络的数学运算不兼容。因此,我们需要一种将单词表示为连续值向量的方式。(不熟悉计算上下文中向量和张量的读者可以在附录 A,A2.2 理解张量中了解更多。)
将数据转换为向量格式的概念通常被称为嵌入。使用特定的神经网络层或其他预训练的神经网络模型,我们可以嵌入不同的数据类型,例如视频、音频和文本,如图 2.2 所示。
图 2.2 深度学习模型无法直接处理视频、音频和文本等原始格式的数据。因此,我们使用嵌入模型将这些原始数据转换为深度学习架构可以轻松理解和处理的稠密向量表示。具体来说,这张图说明了将原始数据转换为三维数值向量的过程。需要注意的是,不同的数据格式需要不同的嵌入模型。例如,专为文本设计的嵌入模型不适用于嵌入音频或视频数据。

在其核心,嵌入是从离散对象(如单词、图像,甚至整个文档)到连续向量空间中的点的映射——嵌入的主要目的是将非数值数据转换为神经网络可以处理的格式。
虽然单词嵌入是文本嵌入的最常见形式,但也有针对句子、段落或整个文档的嵌入。句子或段落嵌入是检索增强生成的流行选择。检索增强生成结合了生成(如生成文本)和检索(如搜索外部知识库)以在生成文本时提取相关信息的技术,这是本书讨论范围之外的技术。由于我们的目标是训练类似 GPT 的 LLMs,这些模型学习逐词生成文本,因此本章重点介绍了单词嵌入。
有几种算法和框架已被开发用于生成单词嵌入。其中一个较早和最流行的示例是Word2Vec方法。Word2Vec 训练神经网络架构以通过预测给定目标词或反之亦然的单词的上下文来生成单词嵌入。Word2Vec 背后的主要思想是在相似上下文中出现的单词往往具有相似的含义。因此,当投影到二维单词嵌入进行可视化时,可以看到相似术语聚集在一起,如图 2.3 所示。
图 2.3 如果单词嵌入是二维的,我们可以在二维散点图中绘制它们进行可视化,如此处所示。使用单词嵌入技术(例如 Word2Vec),与相似概念对应的单词通常在嵌入空间中彼此靠近。例如,不同类型的鸟类在嵌入空间中彼此比国家和城市更接近。

单词嵌入的维度可以有不同的范围,从一维到数千维不等。如图 2.3 所示,我们可以选择二维单词嵌入进行可视化。更高的维度可能捕捉到更加微妙的关系,但会牺牲计算效率。
虽然我们可以使用诸如 Word2Vec 之类的预训练模型为机器学习模型生成嵌入,但 LLMs 通常产生自己的嵌入,这些嵌入是输入层的一部分,并在训练过程中更新。优化嵌入作为 LLM 训练的一部分的优势,而不是使用 Word2Vec 的优势在于,嵌入被优化为特定的任务和手头的数据。我们将在本章后面实现这样的嵌入层。此外,LLMs 还可以创建上下文化的输出嵌入,我们将在第三章中讨论。
不幸的是,高维度嵌入给可视化提出了挑战,因为我们的感知和常见的图形表示固有地受限于三个或更少维度,这就是为什么图 2.3 展示了在二维散点图中的二维嵌入。然而,当使用 LLMs 时,我们通常使用比图 2.3 中所示的更高维度的嵌入。对于 GPT-2 和 GPT-3,嵌入大小(通常称为模型隐藏状态的维度)根据特定模型变体和大小而变化。这是性能和效率之间的权衡。最小的 GPT-2(117M 参数)和 GPT-3(125M 参数)模型使用 768 维度的嵌入大小来提供具体的例子。最大的 GPT-3 模型(175B 参数)使用 12288 维的嵌入大小。
本章的后续部分将介绍准备 LLM 使用的嵌入所需的步骤,包括将文本分割为单词,将单词转换为标记,并将标记转换为嵌入向量。
2.2 文本分词
本节介绍了如何将输入文本分割为单个标记,这是为了创建 LLM 嵌入所必需的预处理步骤。这些标记可以是单独的单词或特殊字符,包括标点符号字符,如图 2.4 所示。
图 2.4 在 LLM 上下文中查看本节涵盖的文本处理步骤。在这里,我们将输入文本分割为单个标记,这些标记可以是单词或特殊字符,如标点符号字符。在即将到来的部分中,我们将把文本转换为标记 ID 并创建标记嵌入。
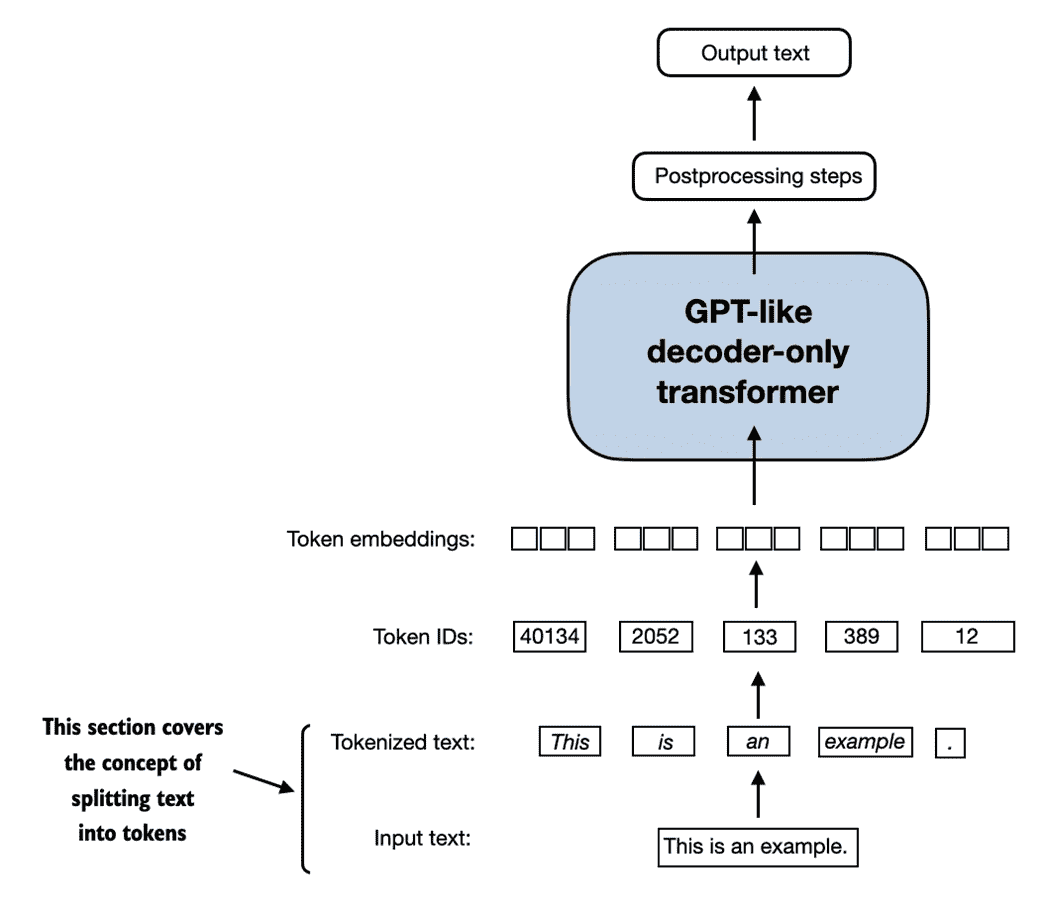
我们将用于 LLM 训练的文本是 Edith Wharton 的短篇小说《The Verdict》,该小说已进入公有领域,因此可以用于 LLM 训练任务。文本可在 Wikisource 上获得,网址为en.wikisource.org/wiki/The_Verdict,您可以将其复制粘贴到文本文件中,我将其复制到一个名为"the-verdict.txt"的文本文件中,以便使用 Python 的标准文件读取实用程序加载:
列表 2.1 将短篇小说作为文本示例读入 Python
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])
- 1
- 2
- 3
- 4
或者,您可以在本书的 GitHub 存储库中找到此"the-verdict.txt"文件,网址为github.com/rasbt/LLMs-from-scratch/tree/main/ch02/01_main-chapter-code。
打印命令打印出字符的总数,然后是文件的前 100 个字符,用于说明目的:
Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
- 1
- 2
我们的目标是将这篇短篇小说的 20,479 个字符标记成单词和特殊字符,然后将其转换为 LLM 训练的嵌入。
文本样本大小
请注意,在处理 LLM 时,处理数百万篇文章和数十万本书——许多吉字节的文本——是很常见的。但是,出于教育目的,使用小型文本样本,如一本书,就足以说明文本处理步骤背后的主要思想,并且可以在消费类硬件上合理的时间内运行。
我们如何最好地分割这段文本以获得标记列表? 为此,我们进行了小小的探索,并使用 Python 的正则表达式库re进行说明。 (请注意,您无需学习或记忆任何正则表达式语法,因为我们将在本章后面过渡到预构建的标记器。)
使用一些简单的示例文本,我们可以使用re.split命令及以下语法来在空格字符上拆分文本:
import re
text = "Hello, world. This, is a test."
result = re.split(r'(\s)', text)
print(result)
- 1
- 2
- 3
- 4
结果是一系列单词、空格和标点字符:
['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']
- 1
请注意,上述简单分词方案通常可将示例文本分隔成单词,但是有些单词仍然与我们希望作为单独列表项的标点字符连接在一起。
让我们修改在空格(\s)和逗号、句号([,.])上的正则表达式分割:
result = re.split(r'([,.]|\s)', text)
print(result)
- 1
- 2
我们可以看到单词和标点字符现在是作为我们想要的分开的列表条目:
['Hello', ',', '', ' ', 'world.', ' ', 'This', ',', '', ' ', 'is', ' ', 'a', ' ', 'test.']
- 1
一个小问题是列表仍然包括空白字符。可选地,我们可以安全地按如下方式删除这些多余的字符:
result = [item.strip() for item in result if item.strip()]
print(result)
- 1
- 2
去除空格字符后的输出如下:
['Hello', ',', 'world.', 'This', ',', 'is', 'a', 'test.']
- 1
是否去除空白
在开发简单的标记器时,是否将空白字符编码为单独的字符或仅将其删除取决于我们的应用程序和其要求。去除空格减少了内存和计算需求。但是,如果我们训练的模型对文本的精确结构敏感(例如,对缩进和间距敏感的 Python 代码),保留空格可能会有用。在这里,为了简化标记化输出的简洁性,我们移除空白。稍后,我们将转换为包括空格的标记方案。
我们上面设计的标记方案在简单的示例文本上运行良好。让我们进一步修改它,使其还可以处理其他类型的标点符号,例如问号,引号以及我们在 Edith Wharton 的短篇小说的前 100 个字符中先前看到的双破折号,以及其他额外的特殊字符。
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)
- 1
- 2
- 3
- 4
结果输出如下:
['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']
- 1
根据总结在图 2.5 中的结果,我们的标记方案现在可以成功处理文本中的各种特殊字符。
图 2.5 我们目前实施的标记化方案将文本分割为单个单词和标点字符。在本图所示的特定示例中,样本文本被分割成 10 个单独的标记。

现在我们已经有了一个基本的标记器工作,让我们将其应用到爱迪丝·沃顿的整个短篇小说中:
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(len(preprocessed))
- 1
- 2
- 3
上面的打印语句输出了4649,这是这段文本(不包括空格)中的标记数。
让我们打印前 30 个标记进行快速的视觉检查:
print(preprocessed[:30])
- 1
结果输出显示,我们的标记器似乎很好地处理了文本,因为所有单词和特殊字符都被很好地分开了:
['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']
- 1
2.3 将标记转换为标记 ID
在上一节中,我们将爱迪丝·沃顿的短篇小说标记化为单个标记。在本节中,我们将这些标记从 Python 字符串转换为整数表示,以生成所谓的标记 ID。这种转换是将标记 ID 转换为嵌入向量之前的中间步骤。
要将之前生成的标记映射到标记 ID 中,我们必须首先构建一个所谓的词汇表。这个词汇表定义了我们如何将每个唯一的单词和特殊字符映射到一个唯一的整数,就像图 2.6 中所示的那样。
图 2.6 我们通过对训练数据集中的整个文本进行标记化来构建词汇表,将这些单独的标记按字母顺序排序,并移除唯一的标记。然后将这些唯一标记聚合成一个词汇表,从而定义了从每个唯一标记到唯一整数值的映射。为了说明的目的,所示的词汇表故意较小,并且不包含标点符号或特殊字符。
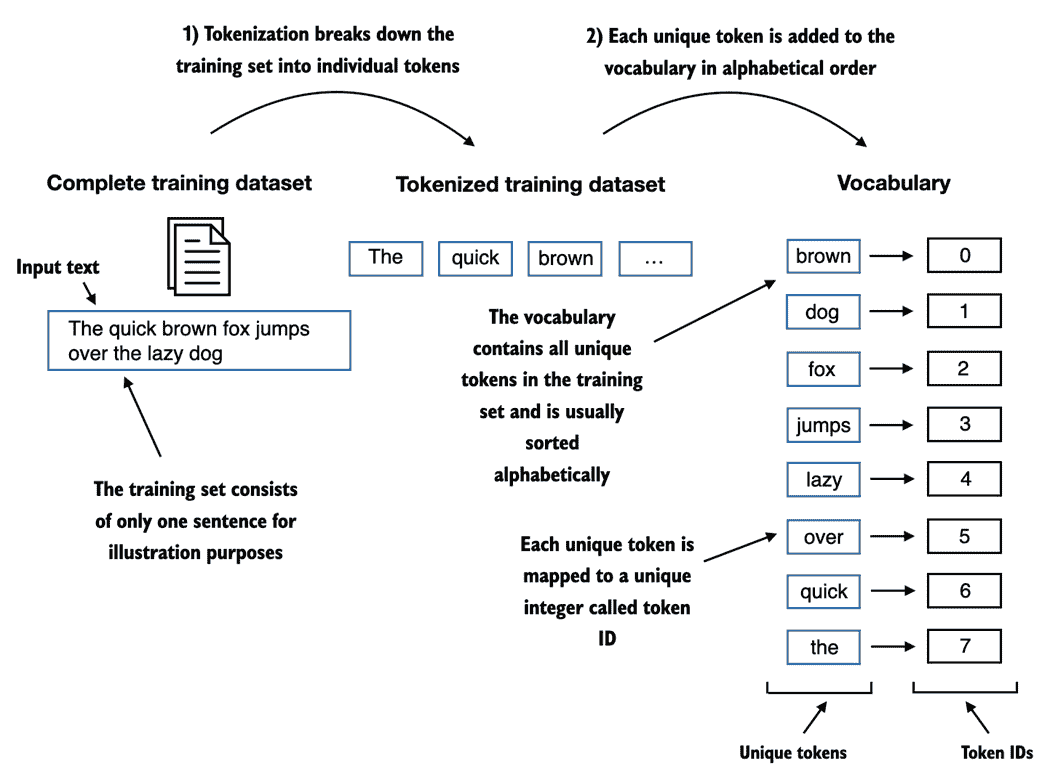
在前一节中,我们标记化了爱迪丝·沃顿的短篇小说,并将其分配给了一个名为preprocessed的 Python 变量。现在让我们创建一个包含所有唯一标记并按字母顺序排列的列表,以确定词汇表的大小:
all_words = sorted(list(set(preprocessed)))
vocab_size = len(all_words)
print(vocab_size)
- 1
- 2
- 3
通过上面的代码确定词汇表的大小为 1,159 后,我们创建词汇表,并打印其前 50 个条目以作说明:
列表 2.2 创建词汇表
vocab = {token:integer for integer,token in enumerate(all_words)}
for i, item in enumerate(vocab.items()):
print(item)
if i > 50:
break
- 1
- 2
- 3
- 4
- 5
输出如下:
('!', 0)
('"', 1)
("'", 2)
...
('Has', 49)
('He', 50)
- 1
- 2
- 3
- 4
- 5
- 6
如上面的输出所示,字典包含与唯一整数标签相关联的单独标记。我们的下一个目标是将这个词汇表应用到新文本中,以将其转换为标记 ID,就像图 2.7 中所示的那样。
图 2.7 从新的文本样本开始,我们对文本进行标记化,并使用词汇表将文本标记转换为标记 ID。词汇表是从整个训练集构建的,并且可以应用于训练集本身以及任何新的文本样本。为了简单起见,所示的词汇表不包含标点符号或特殊字符。
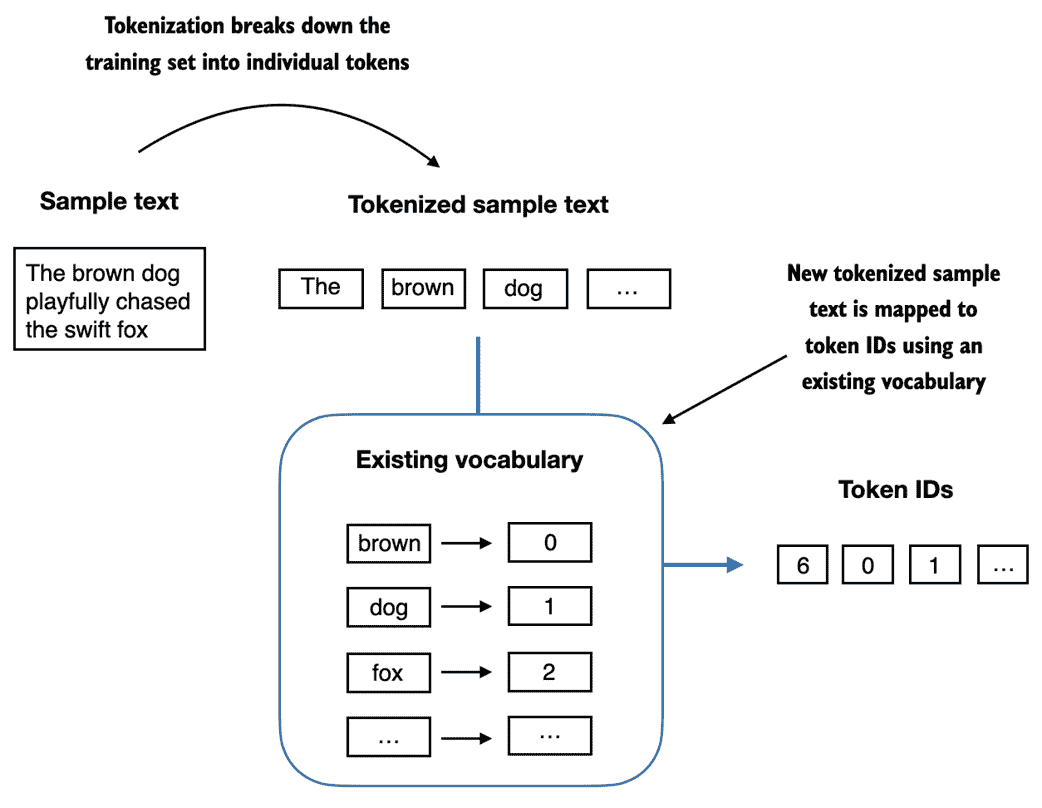
在本书的后面,当我们想要将 LLM 的输出从数字转换回文本时,我们还需要一种将标记 ID 转换成文本的方法。为此,我们可以创建词汇表的反向版本,将标记 ID 映射回相应的文本标记。
让我们在 Python 中实现一个完整的标记器类,它具有一个encode方法,将文本分割成标记,并通过词汇表进行字符串到整数的映射,以产生标记 ID。另外,我们实现了一个decode方法,进行反向整数到字符串的映射,将标记 ID 转回文本。
这个标记器实现的代码如下所示,如列表 2.3 所示:
列表 2.3 实现一个简单的文本标记器
class SimpleTokenizerV1: def __init__(self, vocab): self.str_to_int = vocab #A self.int_to_str = {i:s for s,i in vocab.items()} #B def encode(self, text): #C preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text) preprocessed = [item.strip() for item in preprocessed if item.strip()] ids = [self.str_to_int[s] for s in preprocessed] return ids def decode(self, ids): #D text = " ".join([self.int_to_str[i] for i in ids]) text = re.sub(r'\s+([,.?!"()\'])', r'\1', text) #E return text

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
使用上述的SimpleTokenizerV1 Python 类,我们现在可以通过现有词汇表实例化新的标记对象,然后可以用于编码和解码文本,如图 2.8 所示。
图 2.8 标记器实现共享两个常见方法:一个是编码方法,一个是解码方法。编码方法接受示例文本,将其拆分为单独的标记,并通过词汇表将标记转换为标记 ID。解码方法接受标记 ID,将其转换回文本标记,并将文本标记连接成自然文本。
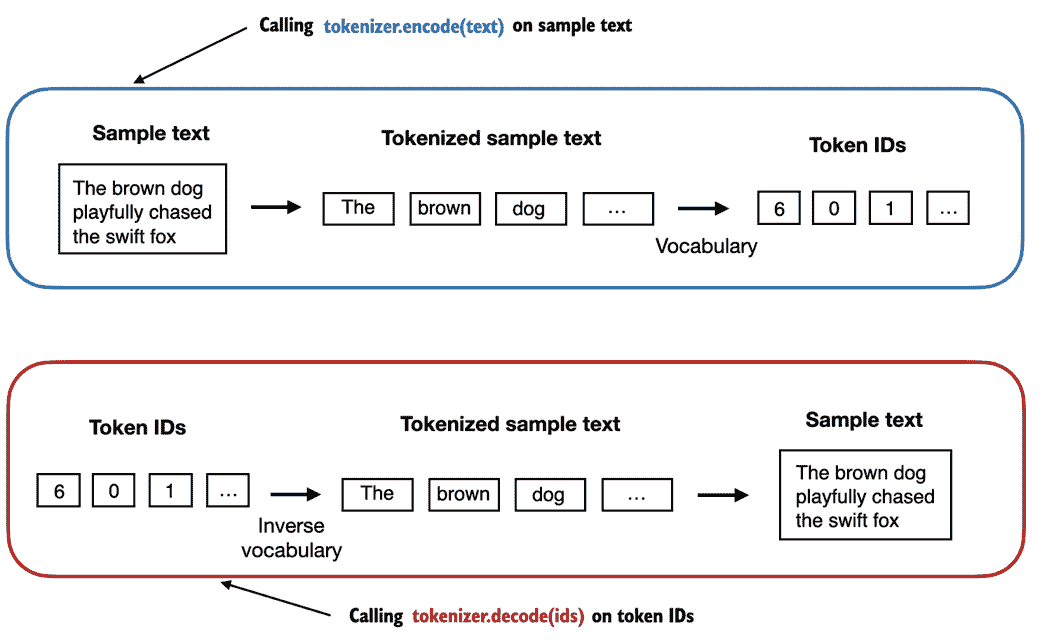
让我们从SimpleTokenizerV1类中实例化一个新的标记对象,并对爱迪丝·沃顿的短篇小说中的段落进行分词,以尝试实践一下:
tokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know," Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)
- 1
- 2
- 3
- 4
- 5
上面的代码打印了以下标记 ID:
[1, 58, 2, 872, 1013, 615, 541, 763, 5, 1155, 608, 5, 1, 69, 7, 39, 873, 1136, 773, 812, 7]
- 1
接下来,让我们看看是否可以使用解码方法将这些标记 ID 还原为文本:
tokenizer.decode(ids)
- 1
这将输出以下文本:
'" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'
- 1
根据上面的输出,我们可以看到解码方法成功地将标记 ID 转换回原始文本。
目前为止,我们已经实现了一个能够根据训练集中的片段对文本进行标记化和解标记化的标记器。现在让我们将其应用于训练集中不包含的新文本样本:
text = "Hello, do you like tea?"
tokenizer.encode(text)
- 1
- 2
执行上面的代码将导致以下错误:
...
KeyError: 'Hello'
- 1
- 2
问题在于“Hello”这个词没有在The Verdict短篇小说中出现过。因此,它不包含在词汇表中。这突显了在处理 LLMs 时需要考虑大量和多样的训练集以扩展词汇表的需求。
在下一节中,我们将进一步测试标记器对包含未知单词的文本的处理,我们还将讨论在训练期间可以使用的额外特殊标记,以提供 LLM 更多的上下文信息。
2.4 添加特殊上下文标记
在上一节中,我们实现了一个简单的标记器,并将其应用于训练集中的一个段落。在本节中,我们将修改这个标记器来处理未知单词。
我们还将讨论使用和添加特殊上下文标记的用法,这些标记可以增强模型对文本中上下文或其他相关信息的理解。这些特殊标记可以包括未知单词和文档边界的标记,例如。
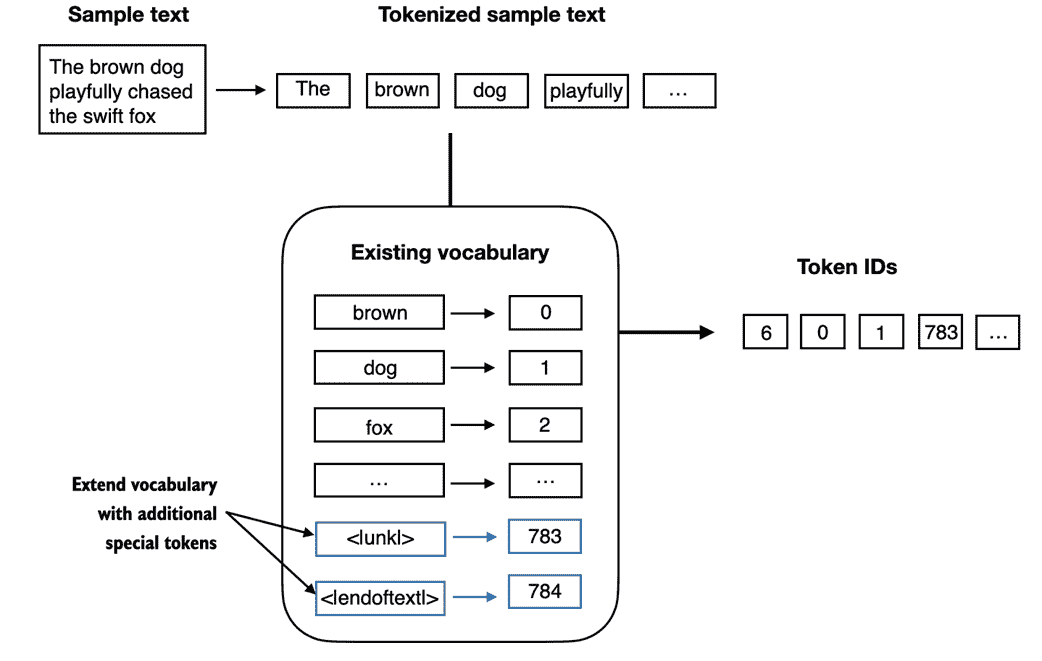
具体来说,我们将修改上一节中实现的词汇表和标记器 SimpleTokenizerV2,以支持两个新的标记<|unk|>和<|endoftext|>,如图 2.8 所示。
图 2.9 我们向词汇表中添加特殊标记来处理特定上下文。 例如,我们添加一个<|unk|>标记来表示训练数据中没有出现过的新单词,因此不是现有词汇表的一部分。 此外,我们添加一个<|endoftext|>标记,用于分隔两个无关的文本源。
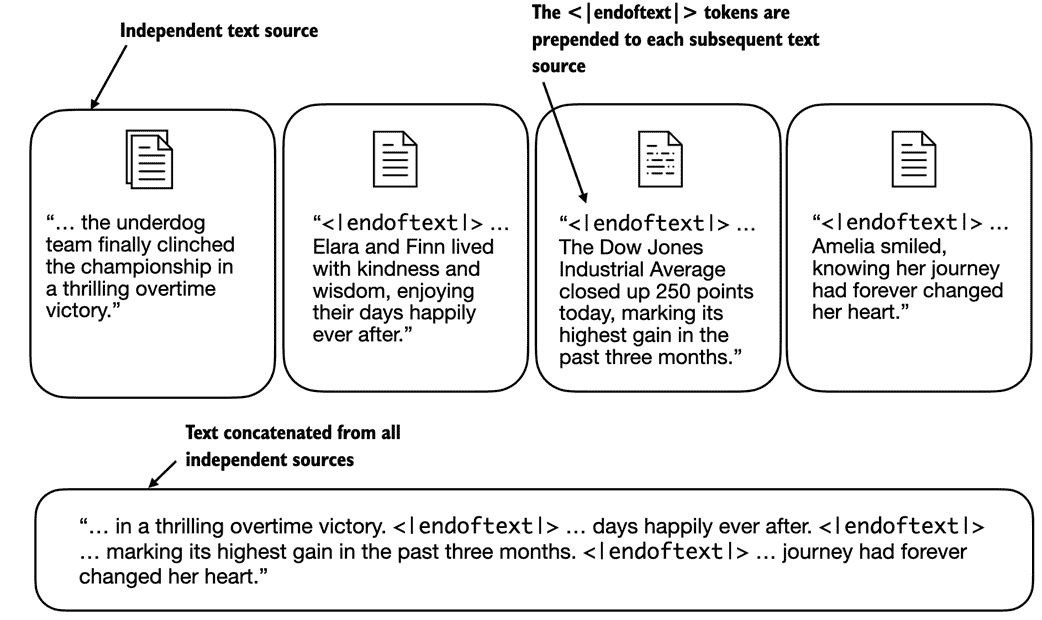
如图 2.9 所示,我们可以修改标记器,在遇到不在词汇表中的单词时使用<|unk|>标记。 此外,我们在无关的文本之间添加一个标记。 例如,在训练多个独立文档或书籍的 GPT-like LLM 时,通常会在每个文档或书籍之前插入一个标记,用于指示这是前一个文本源的后续文档或书籍,如图 2.10 所示。 这有助于 LLM 理解,尽管这些文本源被连接起来进行训练,但实际上它们是无关的。
图 2.10 当处理多个独立的文本源时,我们在这些文本之间添加<|endoftext|>标记。 这些<|endoftext|>标记充当标记,标志着特定段落的开始或结束,让 LLM 更有效地处理和理解。
现在让我们修改词汇表,以包括这两个特殊标记<unk>和<|endoftext|>,通过将它们添加到我们在上一节中创建的所有唯一单词列表中:
all_words.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token:integer for integer,token in enumerate(all_tokens)}
print(len(vocab.items()))
- 1
- 2
- 3
根据上述打印语句的输出,新的词汇表大小为 1161(上一节的词汇表大小为 1159)。
作为额外的快速检查,让我们打印更新后词汇表的最后 5 个条目:
for i, item in enumerate(list(vocab.items())[-5:]):
print(item)
- 1
- 2
上面的代码打印如下所示:
('younger', 1156)
('your', 1157)
('yourself', 1158)
('<|endoftext|>', 1159)
('<|unk|>', 1160)
- 1
- 2
- 3
- 4
- 5
根据上面的代码输出,我们可以确认这两个新的特殊标记确实成功地融入到了词汇表中。 接下来,我们根据代码清单 2.3 调整标记器,如清单 2.4 所示:
清单 2.4 处理未知词的简单文本标记器
class SimpleTokenizerV2: def __init__(self, vocab): self.str_to_int = vocab self.int_to_str = { i:s for s,i in vocab.items()} def encode(self, text): preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text) preprocessed = [item.strip() for item in preprocessed if item.strip()] preprocessed = [item if item in self.str_to_int #A else "<|unk|>" for item in preprocessed] ids = [self.str_to_int[s] for s in preprocessed] return ids def decode(self, ids): text = " ".join([self.int_to_str[i] for i in ids]) text = re.sub(r'\s+([,.?!"()\'])', r'\1', text) #B return text
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
与我们在上一节代码清单 2.3 中实现的SimpleTokenizerV1相比,新的SimpleTokenizerV2将未知单词替换为<|unk|>标记。
现在让我们尝试实践这种新的标记器。 为此,我们将使用一个简单的文本示例,该文本由两个独立且无关的句子串联而成:
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
print(text)
- 1
- 2
- 3
- 4
输出如下所示:
'Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.'
- 1
接下来,让我们使用SimpleTokenizerV2对样本文本进行标记:
tokenizer = SimpleTokenizerV2(vocab)
print(tokenizer.encode(text))
- 1
- 2
这打印了以下令牌 ID:
[1160, 5, 362, 1155, 642, 1000, 10, 1159, 57, 1013, 981, 1009, 738, 1013, 1160, 7]
- 1
从上面可以看到,令牌 ID 列表包含 1159 个<|endoftext|>分隔符令牌,以及两个用于未知单词的 160 个令牌。
让我们对文本进行反标记,做一个快速的检查:
print(tokenizer.decode(tokenizer.encode(text)))
- 1
输出如下所示:
'<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.'
- 1
根据上述去标记化文本与原始输入文本的比较,我们知道埃迪斯·沃顿(Edith Wharton)的短篇小说The Verdict训练数据集中不包含单词“Hello”和“palace”。
到目前为止,我们已经讨论了分词作为将文本处理为 LLMs 输入的基本步骤。根据 LLM,一些研究人员还考虑其他特殊标记,如下所示:
-
[BOS](序列开始):该标记标志着文本的开始。它向 LLM 表示内容的开始位置。 -
[EOS](序列结束):该标记位于文本末尾,当连接多个不相关的文本时特别有用,类似于<|endoftext|>。例如,当合并两篇不同的维基百科文章或书籍时,[EOS]标记指示一篇文章的结束和下一篇文章的开始位置。 -
[PAD](填充):当使用大于一的批次大小训练 LLMs 时,批次可能包含不同长度的文本。为确保所有文本具有相同长度,较短的文本将使用[PAD]标记进行扩展或“填充”,直到批次中最长文本的长度。
请注意,用于 GPT 模型的分词器不需要上述提到的任何这些标记,而仅使用<|endoftext|>标记简化。<|endoftext|>类似于上述的[EOS]标记。此外,<|endoftext|>也用于填充。然而,在后续章节中,当在批量输入上训练时,我们通常使用掩码,意味着我们不关注填充的标记。因此,所选择的特定填充标记变得不重要。
此外,用于 GPT 模型的分词器也不使用<|unk|>标记来表示词汇表中没有的单词。相反,GPT 模型使用字节对编码分词器,将单词拆分为子词单元,我们将在下一节中讨论。
2.5 字节对编码
我们在前几节中实现了一个简单的分词方案,用于说明目的。本节介绍基于称为字节对编码(BPE)的概念的更复杂的分词方案。本节介绍的 BPE 分词器用于训练 LLMs,如 GPT-2、GPT-3 和 ChatGPT。
由于实现 BPE 可能相对复杂,我们将使用一个名为tiktoken(github.com/openai/tiktoken)的现有 Python 开源库,该库基于 Rust 中的源代码非常有效地实现了 BPE 算法。与其他 Python 库类似,我们可以通过 Python 的终端上的pip安装程序安装 tiktoken 库:
pip install tiktoken
- 1
本章中的代码基于 tiktoken 0.5.1。您可以使用以下代码检查当前安装的版本:
import importlib
import tiktoken
print("tiktoken version:", importlib.metadata.version("tiktoken"))
- 1
- 2
- 3
安装完成后,我们可以如下实例化 tiktoken 中的 BPE 分词器:
tokenizer = tiktoken.get_encoding("gpt2")
- 1
此分词器的使用方式类似于我们之前通过encode方法实现的 SimpleTokenizerV2:
text = "Hello, do you like tea? <|endoftext|> In the sunlit terraces of someunknownPlace."
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)
- 1
- 2
- 3
上述代码打印以下标记 ID:
[15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 286, 617, 34680, 27271, 13]
- 1
然后,我们可以使用解码方法将标记 ID 转换回文本,类似于我们之前的SimpleTokenizerV2:
strings = tokenizer.decode(integers)
print(strings)
- 1
- 2
上述代码打印如下:
'Hello, do you like tea? <|endoftext|> In the sunlit terraces of someunknownPlace.'
- 1
基于上述标记 ID 和解码文本,我们可以得出两个值得注意的观察结果。首先,<|endoftext|>标记被分配了一个相对较大的标记 ID,即 50256。事实上,用于训练诸如 GPT-2、GPT-3 和 ChatGPT 等模型的 BPE 分词器具有总共 50257 个词汇,其中<|endoftext|>被分配了最大的标记 ID。
第二,上述的 BPE 分词器可以正确地对未知单词进行编码和解码,例如"someunknownPlace"。BPE 分词器可以处理任何未知单词。它是如何在不使用<|unk|>标记的情况下实现这一点的?
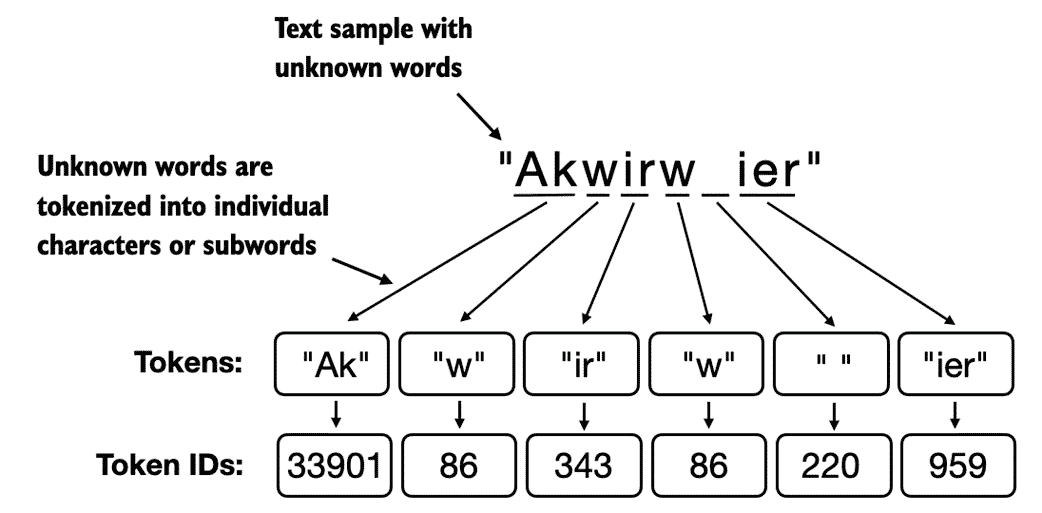
BPE 算法的基础是将不在其预定义词汇表中的单词分解为更小的子词单元甚至是单个字符,使其能够处理词汇表之外的词汇。因此,多亏了 BPE 算法,如果分词器在分词过程中遇到陌生的单词,它可以将其表示为一系列子词标记或字符,如图 2.11 所示。
图 2.11 BPE 分词器将未知单词分解为子词和单个字符。这样,BPE 分词器可以解析任何单词,无需用特殊标记(如<|unk|>)替换未知单词。
如图 2.11 所示,将未知单词分解为单个字符的能力确保了分词器以及随之训练的 LLM 可以处理任何文本,即使其中包含了其训练数据中未出现的单词。
练习 2.1 未知单词的字节对编码
尝试从 tiktoken 库中使用 BPE 分词器对未知单词"Akwirw ier",并打印各个标记的 ID。然后,在此列表中的每个生成的整数上调用解码函数,以重现图 2.1 中显示的映射。最后,在标记 ID 上调用解码方法以检查是否可以重建原始输入,即"Akwirw ier"。
本书不讨论 BPE 的详细讨论和实现,但简而言之,它通过迭代地将频繁出现的字符合并为子词和频繁出现的子词合并为单词来构建其词汇表。例如,BPE 从将所有单个字符添加到其词汇表开始(“a”,“b”,…)。在下一阶段,它将经常一起出现的字符组合成子词。例如,“d"和"e"可能会合并成子词"de”,在许多英文单词中很常见,如"define",“depend”,“made"和"hidden”。合并是由频率截止确定的。
2.6 滑动窗口数据采样
前一节详细介绍了标记化步骤以及将字符串标记转换为整数标记 ID 之后,我们最终可以为 LLM 生成所需的输入-目标对,以用于训练 LLM。
这些输入-目标对是什么样子?正如我们在第一章中学到的那样,LLMs 是通过预测文本中的下一个单词来进行预训练的,如图 2.12 所示。
图 2.12 给定一个文本样本,提取作为 LLM 输入的子样本的输入块,并且在训练期间,LLM 的预测任务是预测跟随输入块的下一个单词。在训练中,我们屏蔽所有超过目标的单词。请注意,在 LLM 可处理文本之前,此图中显示的文本会进行 tokenization;但为了清晰起见,该图省略了 tokenization 步骤。
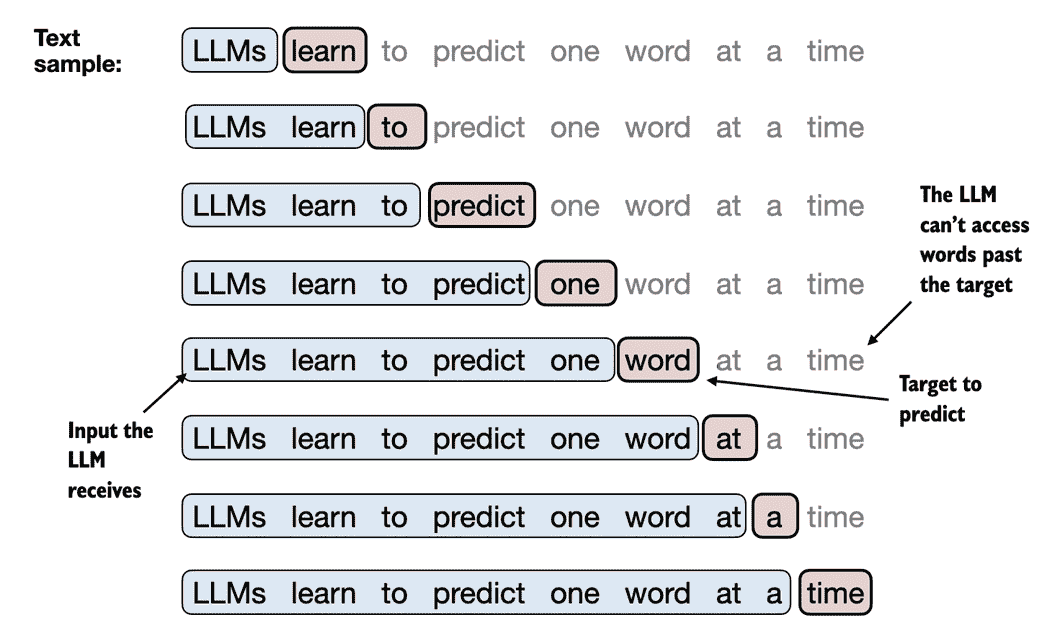
在此部分中,我们实现了一个数据加载器,使用滑动窗口方法从训练数据集中提取图 2.12 中所示的输入-目标对。
为了开始,我们将使用前面介绍的 BPE tokenizer 对我们之前使用的《裁决》短篇小说进行标记化处理:
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
enc_text = tokenizer.encode(raw_text)
print(len(enc_text))
- 1
- 2
- 3
- 4
- 5
执行上述代码将返回 5145,应用 BPE tokenizer 后训练集中的总标记数。
接下来,为了演示目的,让我们从数据集中删除前 50 个标记,因为这会使接下来的文本段落稍微有趣一些:
enc_sample = enc_text[50:]
- 1
创建下一个单词预测任务的输入-目标对最简单直观的方法之一是创建两个变量,x 和 y,其中 x 包含输入标记,y 包含目标,即将输入向后移动一个位置的输入:
context_size = 4 #A x = enc_sample[:context_size] y = enc_sample[1:context_size+1] print(f"x: {x}") print(f"y: {y}")
- 1
运行上述代码会打印以下输出:
x: [290, 4920, 2241, 287]
y: [4920, 2241, 287, 257]
- 1
- 2
处理输入以及目标(即向后移动了一个位置的输入),我们可以创建如图 2.12 中所示的下一个单词预测任务:
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(context, "---->", desired)
- 1
- 2
- 3
- 4
上述代码会打印以下内容:
[290] ----> 4920
[290, 4920] ----> 2241
[290, 4920, 2241] ----> 287
[290, 4920, 2241, 287] ----> 257
- 1
- 2
- 3
- 4
形如箭头 (---->) 左侧的所有内容指的是 LLM 收到的输入,箭头右侧的标记 ID 表示 LLM 应该预测的目标标记 ID。
为了说明目的,让我们重复之前的代码但将标记 ID 转换为文本:
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(tokenizer.decode(context), "---->", tokenizer.decode([desired]))
- 1
- 2
- 3
- 4
以下输出显示输入和输出以文本格式的样式:
and ----> established
and established ----> himself
and established himself ----> in
and established himself in ----> a
- 1
- 2
- 3
- 4
我们现在已经创建了输入-目标对,可以在接下来的章节中用于 LLM 训练。
在我们可以将标记转换为嵌入之前,还有最后一个任务,正如我们在本章开头所提到的:实现一个高效的数据加载器,迭代输入数据集并返回 PyTorch 张量作为输入和目标。
特别是,我们有兴趣返回两个张量:一个包含 LLM 看到的文本的输入张量,以及一个包含 LLM 预测目标的目标张量,如图 2.13 所示。
图 2.13 为了实现高效的数据加载器,我们将输入都收集到一个张量 x 中,其中每一行代表一个输入上下文。第二个张量 y 包含对应的预测目标(下一个单词),它们是通过将输入向后移动一个位置来创建的。

虽然图 2.13 展示了字符串格式的 token 以进行说明,但代码实现将直接操作 token ID,因为 BPE 标记器的 encode 方法执行了 tokenization 和转换为 token ID 为单一步骤。
对于高效的数据加载器实现,我们将使用 PyTorch 内置的 Dataset 和 DataLoader 类。有关安装 PyTorch 的更多信息和指导,请参阅附录 A 的A.1.3,安装 PyTorch一节。
数据集类的代码如图 2.5 所示:
图 2.5 一批输入和目标的数据集
import torch from torch.utils.data import Dataset, DataLoader class GPTDatasetV1(Dataset): def __init__(self, txt, tokenizer, max_length, stride): self.tokenizer = tokenizer self.input_ids = [] self.target_ids = [] token_ids = tokenizer.encode(txt) #A for i in range(0, len(token_ids) - max_length, stride): #B input_chunk = token_ids[i:i + max_length] target_chunk = token_ids[i + 1: i + max_length + 1] self.input_ids.append(torch.tensor(input_chunk)) self.target_ids.append(torch.tensor(target_chunk)) def __len__(self): #C return len(self.input_ids) def __getitem__(self, idx): #D return self.input_ids[idx], self.target_ids[idx]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
图 2.5 中的GPTDatasetV1类基于 PyTorch 的Dataset类,定义了如何从数据集中获取单独的行,其中每一行都包含一系列基于max_length分配给input_chunk张量的 token ID。target_chunk张量包含相应的目标。我建议继续阅读,看看当我们将数据集与 PyTorch 的DataLoader结合使用时,这个数据集返回的数据是什么样的——这将带来额外的直觉和清晰度。
如果您对 PyTorch 的Dataset类的结构(如图 2.5 所示)是新手,请阅读附录 A 的A.6,设置高效的数据加载器一节,其中解释了 PyTorch 的Dataset和DataLoader类的一般结构和用法。
以下代码将使用GPTDatasetV1通过 PyTorch 的DataLoader来批量加载输入:
图 2.6 用于生成带输入对的批次的数据加载器
def create_dataloader(txt, batch_size=4, max_length=256, stride=128):
tokenizer = tiktoken.get_encoding("gpt2") #A
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride) #B
dataloader = DataLoader(dataset, batch_size=batch_size) #C
return dataloader
- 1
- 2
- 3
- 4
- 5
让我们测试dataloader,将一个上下文大小为 4 的 LLM 的批量大小设为 1,以便理解图 2.5 的GPTDatasetV1类和图 2.6 的create_dataloader函数如何协同工作。
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
dataloader = create_dataloader(raw_text, batch_size=1, max_length=4, stride=1)
data_iter = iter(dataloader) #A
first_batch = next(data_iter)
print(first_batch)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
执行前面的代码将打印以下内容:
[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]
- 1
first_batch变量包含两个张量:第一个张量存储输入 token ID,第二个张量存储目标 token ID。由于max_length设置为 4,这两个张量每个都包含 4 个 token ID。值得注意的是,输入大小为 4 相对较小,仅用于说明目的。通常会用至少 256 的输入大小来训练 LLMs。
为了说明stride=1的含义,让我们从这个数据集中获取另一个批次:
second_batch = next(data_iter)
print(second_batch)
- 1
- 2
第二批的内容如下:
[tensor([[ 367, 2885, 1464, 1807]]), tensor([[2885, 1464, 1807, 3619]])]
- 1
如果我们比较第一批和第二批,我们会发现相对于第一批,第二批的 token ID 向后移动了一个位置(例如,第一批输入中的第二个 ID 是 367,这是第二批输入中的第一个 ID)。stride设置规定了输入在批次之间移动的位置数,模拟了一个滑动窗口的方法,如图 2.14 所示。
图 2.14 在从输入数据集创建多个批次时,我们在文本上滑动一个输入窗口。如果将步幅设置为 1,则在创建下一个批次时,将输入窗口向右移动 1 个位置。如果我们将步幅设置为等于输入窗口大小,我们可以防止批次之间的重叠。
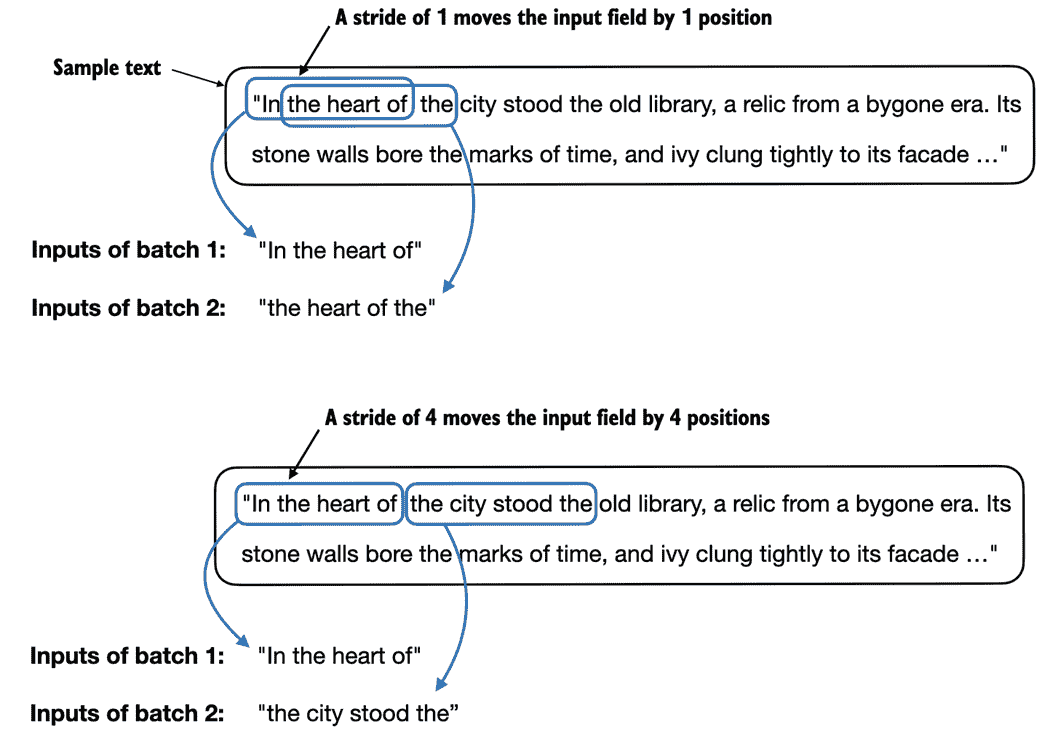
练习 2.2 具有不同步幅和上下文大小的数据加载器
要更好地理解数据加载器的工作原理,请尝试以不同设置运行,如 max_length=2 和 stride=2 以及 max_length=8 和 stride=2。
与我们到目前为止从数据加载器中抽样的批次大小为 1 一样,这对于说明目的非常有用。如果您有深度学习的经验,您可能知道,较小的批次大小在训练期间需要更少的内存,但会导致更多的噪声模型更新。就像在常规深度学习中一样,批次大小是一个需要在训练 LLM 时进行实验的权衡和超参数。
在我们继续本章的最后两个重点部分,这些部分侧重于从标记 ID 创建嵌入向量之前,让我们简要了解如何使用数据加载器进行批量大小大于 1 的抽样:
dataloader = create_dataloader(raw_text, batch_size=8, max_length=4, stride=5)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Inputs:\n", inputs)
print("\nTargets:\n", targets)
- 1
- 2
- 3
- 4
- 5
- 6
这将输出以下内容:
Inputs: tensor([[ 40, 367, 2885, 1464], [ 3619, 402, 271, 10899], [ 257, 7026, 15632, 438], [ 257, 922, 5891, 1576], [ 568, 340, 373, 645], [ 5975, 284, 502, 284], [ 326, 11, 287, 262], [ 286, 465, 13476, 11]]) Targets: tensor([[ 367, 2885, 1464, 1807], [ 402, 271, 10899, 2138], [ 7026, 15632, 438, 2016], [ 922, 5891, 1576, 438], [ 340, 373, 645, 1049], [ 284, 502, 284, 3285], [ 11, 287, 262, 6001], [ 465, 13476, 11, 339]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
请注意,我们将步幅增加到 5,这是最大长度+1。这是为了充分利用数据集(我们不跳过任何单词),同时避免批次之间的任何重叠,因为更多的重叠可能导致过拟合增加。例如,如果我们将步幅设置为与最大长度相等,那么每行中最后一个输入标记 ID 的目标 ID 将成为下一行中第一个输入标记 ID。
在本章的最后两个部分中,我们将实现将标记 ID 转换为连续向量表示的嵌入层,这将作为 LLM 的输入数据格式。
2.7 创建标记嵌入
为准备 LLM 训练的输入文本的最后一步是将标记 ID 转换为嵌入向量,如图 2.15 所示,这将是本章最后两个剩余部分的重点。
图 2.15 准备 LLM 输入文本涉及对文本进行标记化、将文本标记转换为标记 ID 和将标记 ID 转换为向量嵌入向量。在本节中,我们考虑前几节中创建的标记 ID 以创建标记嵌入向量。
连续向量表示,或嵌入,是必要的,因为类似 GPT 的 LLM 是使用反向传播算法训练的深度神经网络。如果您不熟悉神经网络如何使用反向传播进行训练,请阅读附录 A 中的第 A.4 节,简化的自动微分。
让我们用一个实际例子说明标记 ID 到嵌入向量转换是如何工作的。假设我们有以下三个带有 ID 5、1、3 和 2 的输入标记:
input_ids = torch.tensor([5, 1, 3, 2])
- 1
为了简单起见和说明目的,假设我们只有一个小的词汇表,其中只有 6 个单词(而不是 BPE 标记器词汇表中的 50,257 个单词),我们想创建大小为 3 的嵌入(在 GPT-3 中,嵌入大小为 12,288 维):
vocab_size = 6
output_dim = 3
- 1
- 2
使用 vocab_size 和 output_dim,我们可以在 PyTorch 中实例化一个嵌入层,设置随机种子为 123 以便进行再现性:
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
print(embedding_layer.weight)
- 1
- 2
- 3
在上述代码示例中的打印语句打印了嵌入层的底层权重矩阵:
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们可以看到嵌入层的权重矩阵包含了小型的随机值。这些值在 LLM 训练过程中作为 LLM 优化的一部分而被优化,我们将在后续章节中看到。此外,我们可以看到权重矩阵有六行和三列。词汇表中的每个可能的标记都有一行。这三个嵌入维度中的每个维度都有一列。
在我们实例化嵌入层之后,现在让我们将其应用到一个标记 ID 上以获取嵌入向量:
print(embedding_layer(torch.tensor([3])))
- 1
返回的嵌入向量如下:
tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)
- 1
如果我们将标记 ID 3 的嵌入向量与先前的嵌入矩阵进行比较,我们会看到它与第四行完全相同(Python 从零索引开始,所以它是与索引 3 对应的行)。换句话说,嵌入层本质上是一个查找操作,它通过标记 ID 从嵌入层的权重矩阵中检索行。
嵌入层与矩阵乘法
对于那些熟悉独热编码的人来说,上面的嵌入层方法实质上只是实施独热编码加上全连接层中的矩阵乘法更高效的一种方式,这在 GitHub 上的补充代码中进行了说明 github.com/rasbt/LLMs-from-scratch/tree/main/ch02/03_bonus_embedding-vs-matmul。因为嵌入层只是一个更高效的等效实现,等同于独热编码和矩阵乘法方法,它可以看作是一个可以通过反向传播进行优化的神经网络层。
在之前,我们已经看到如何将单个标记 ID 转换为三维嵌入向量。现在让我们将其应用到我们之前定义的四个输入 ID 上 (torch.tensor([5, 1, 3, 2])):
print(embedding_layer(input_ids))
- 1
打印输出显示,结果是一个 4x3 的矩阵:
tensor([[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010],
[-0.4015, 0.9666, -1.1481],
[ 1.2753, -0.2010, -0.1606]], grad_fn=<EmbeddingBackward0>)
- 1
- 2
- 3
- 4
此输出矩阵中的每一行都是通过从嵌入权重矩阵中进行查找操作得到的,正如图 2.16 所示。
图 2.16 嵌入层执行查找操作,从嵌入层的权重矩阵中检索与标记 ID 对应的嵌入向量。例如,标记 ID 5 的嵌入向量是嵌入层权重矩阵的第六行(它是第六行而不是第五行,因为 Python 从 0 开始计数)。

本节介绍了如何从标记 ID 创建嵌入向量。本章的下一节也是最后一节,将对这些嵌入向量进行一些小的修改,以编码文本中标记的位置信息。
2.8 编码词的位置
在前一节中,我们将标记 ID 转换为连续的向量表示,即所谓的标记嵌入。从原则上讲,这对于 LLM 来说是一个合适的输入。然而,LLM 的一个小缺陷是,它们的自我注意机制(将详细介绍于第三章中)对于序列中的标记没有位置或顺序的概念。
先前介绍的嵌入层的工作方式是,相同的标记 ID 始终被映射到相同的向量表示,无论标记 ID 在输入序列中的位置如何,如图 2.17 所示。
图 2.17 嵌入层将标记 ID 转换为相同的向量表示,无论其在输入序列中的位置如何。例如,标记 ID 5,无论是在标记 ID 输入向量的第一个位置还是第三个位置,都会导致相同的嵌入向量。

从原则上讲,标记 ID 的确定性、位置无关的嵌入对于可重现性目的很好。然而,由于 LLM 的自我注意机制本身也是位置不可知的,向 LLM 注入额外的位置信息是有帮助的。
为了实现这一点,位置感知嵌入有两个广泛的类别:相对位置嵌入和绝对位置嵌入。
绝对位置嵌入与序列中的特定位置直接相关联。对于输入序列中的每个位置,都会添加一个唯一的嵌入,以传达其确切位置。例如,第一个标记将具有特定的位置嵌入,第二个标记是另一个不同的嵌入,依此类推,如图 2.18 所示。
图 2.18 位置嵌入被添加到标记嵌入向量中,用于创建 LLM 的输入嵌入。位置向量的维度与原始标记嵌入相同。为简单起见,标记嵌入显示为值 1。

相对位置嵌入不是关注一个标记的绝对位置,而是关注标记之间的相对位置或距离。这意味着模型学习的是关于“有多远”而不是“在哪个确切位置”。这里的优势在于,即使模型在训练期间没有看到这样的长度,它也能更好地概括不同长度的序列。
这两种位置嵌入的目标都是增强 LLM 理解标记之间的顺序和关系的能力,确保更准确和能够理解上下文的预测。它们之间的选择通常取决于特定的应用和正在处理的数据的性质。
OpenAI 的 GPT 模型使用的是在训练过程中进行优化的绝对位置嵌入,而不是像原始 Transformer 模型中的位置编码一样是固定或预定义的。这个优化过程是模型训练本身的一部分,我们稍后会在本书中实现。现在,让我们创建初始位置嵌入以创建即将到来的章节的 LLM 输入。
在本章中,我们之前专注于非常小的嵌入尺寸以进行举例说明。现在我们考虑更现实和有用的嵌入尺寸,并将输入令牌编码为 256 维向量表示。这比原始的 GPT-3 模型使用的要小(在 GPT-3 中,嵌入尺寸是 12,288 维),但对于实验仍然是合理的。此外,我们假设令牌 ID 是由我们先前实现的 BPE 标记器创建的,其词汇量为 50,257:
output_dim = 256
vocab_size = 50257
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
- 1
- 2
- 3
使用上面的token_embedding_layer,如果我们从数据加载器中取样数据,我们将每个批次中的每个令牌嵌入为一个 256 维的向量。如果我们的批次大小为 8,每个有四个令牌,结果将是一个 8x4x256 的张量。
让我们先从第 2.6 节“使用滑动窗口进行数据抽样”中实例化数据加载器:
max_length = 4
dataloader = create_dataloader(
raw_text, batch_size=8, max_length=max_length, stride=5)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Token IDs:\n", inputs)
print("\nInputs shape:\n", inputs.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
前面的代码打印如下输出:
Token IDs:
tensor([[ 40, 367, 2885, 1464],
[ 3619, 402, 271, 10899],
[ 257, 7026, 15632, 438],
[ 257, 922, 5891, 1576],
[ 568, 340, 373, 645],
[ 5975, 284, 502, 284],
[ 326, 11, 287, 262],
[ 286, 465, 13476, 11]])
Inputs shape:
torch.Size([8, 4])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
如我们所见,令牌 ID 张量是 8x4 维的,这意味着数据批次由 8 个文本样本组成,每个样本有 4 个令牌。
现在让我们使用嵌入层将这些令牌 ID 嵌入到 256 维的向量中:
token_embeddings = token_embedding_layer(inputs)
print(token_embeddings.shape)
- 1
- 2
前面的打印函数调用返回以下内容:
torch.Size([8, 4, 256])
- 1
根据 8x4x256 维张量的输出,我们可以看出,现在每个令牌 ID 都嵌入为一个 256 维的向量。
对于 GPT 模型的绝对嵌入方法,我们只需要创建另一个具有与token_embedding_layer相同维度的嵌入层:
block_size = max_length
pos_embedding_layer = torch.nn.Embedding(block_size, output_dim)
pos_embeddings = pos_embedding_layer(torch.arange(block_size))
print(pos_embeddings.shape)
- 1
- 2
- 3
- 4
如前面的代码示例所示,pos_embeddings 的输入通常是一个占位符向量torch.arange(block_size),其中包含一个数字序列 1、2、…、直到最大输入长度。block_size是代表 LLM 的支持输入尺寸的变量。在这里,我们选择它类似于输入文本的最大长度。在实践中,输入文本可能比支持的块大小更长,在这种情况下,我们必须截断文本。文本还可以比块大小短,在这种情况下,我们填充剩余的输入以匹配块大小的占位符令牌,正如我们将在第三章中看到的。
打印语句的输出如下所示:
torch.Size([4, 256])
- 1
如我们所见,位置嵌入张量由四个 256 维向量组成。我们现在可以直接将它们添加到令牌嵌入中,PyTorch 将会将 4x256 维的pos_embeddings张量添加到 8 个批次中每个 4x256 维的令牌嵌入张量中:
input_embeddings = token_embeddings + pos_embeddings
print(input_embeddings.shape)
- 1
- 2
打印输出如下:
torch.Size([8, 4, 256])
- 1
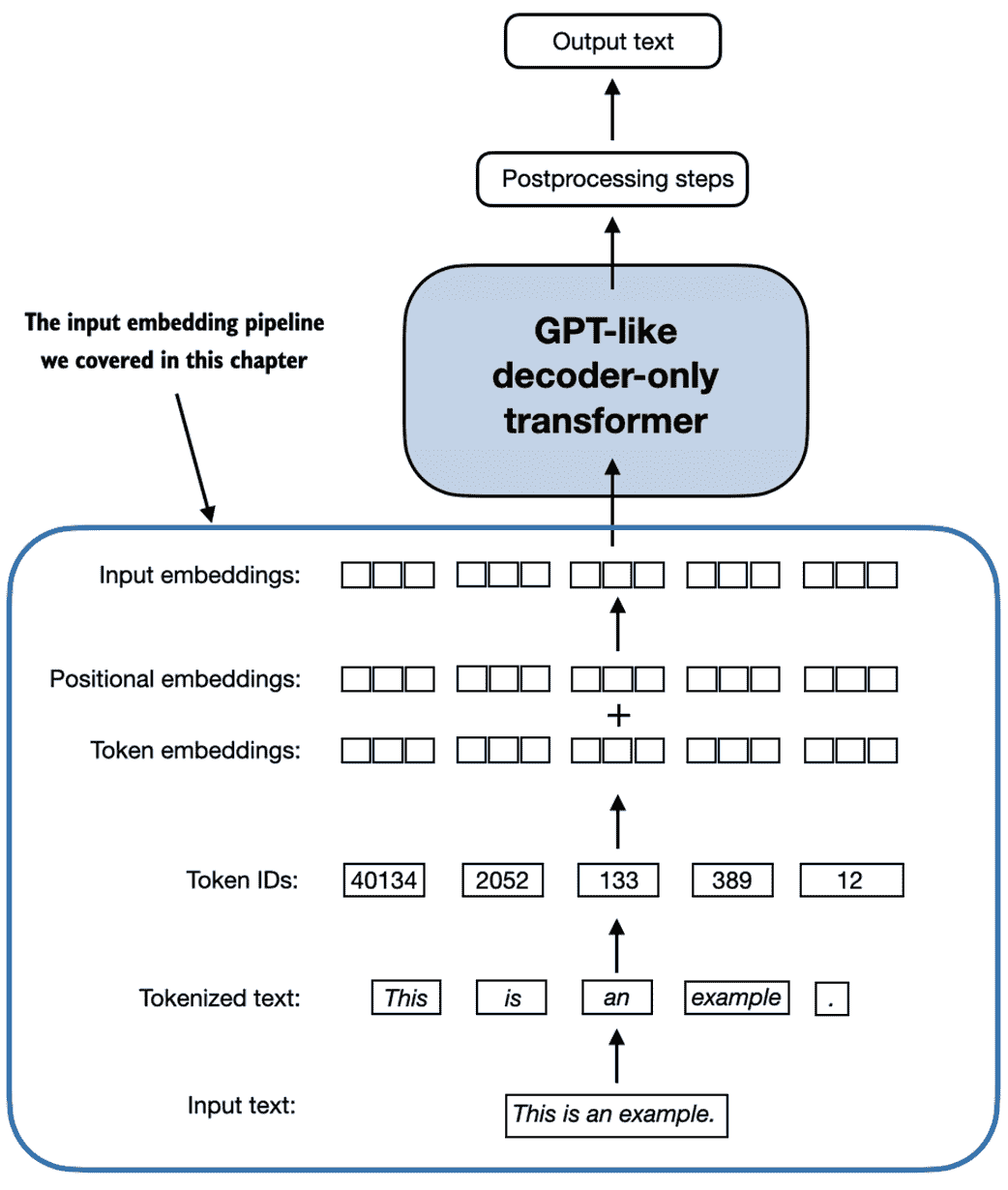
我们创建的input_embeddings,如图 2.19 所总结的,是嵌入的输入示例,现在可以被主 LLM 模块处理,我们将在第三章中开始实施它
图 2.19 作为输入处理流程的一部分,输入文本首先被分解为单独的标记。然后这些标记使用词汇表转换为标记 ID。标记 ID 转换为嵌入向量,与类似大小的位置嵌入相加,产生用作主 LLM 层输入的输入嵌入。
2.9 总结
-
由于 LLM 不能处理原始文本,所以需要将文本数据转换为数字向量,这些向量被称为嵌入。嵌入将离散数据(如文字或图像)转换为连续的向量空间,使其与神经网络操作兼容。
-
作为第一步,原始文本被分解为标记,这些标记可以是单词或字符。然后,这些标记被转换为整数表示,称为标记 ID。
-
特殊标记,比如
<|unk|>和<|endoftext|>,可以增强模型的理解并处理各种上下文,比如未知单词或标记无关文本的边界。 -
用于像 GPT-2 和 GPT-3 这样的 LLM 的字节对编码(BPE)分词器可以通过将未知单词分解为子词单元或单个字符来高效地处理未知单词。
-
我们在标记化数据上使用滑动窗口方法生成用于 LLM 训练的输入-目标对。
-
PyTorch 中的嵌入层作为查找操作,检索与标记 ID 相对应的向量。结果嵌入向量提供了标记的连续表示,这对于训练像 LLM 这样的深度学习模型至关重要。
-
虽然标记嵌入为每个标记提供了一致的向量表示,但它缺乏对标记在序列中位置的感知。为了纠正这一点,存在两种主要类型的位置嵌入:绝对和相对。OpenAI 的 GPT 模型利用绝对位置嵌入,这些嵌入被加到标记嵌入向量中,并在模型训练过程中进行优化。
2.10 参考资料和进一步阅读
对嵌入空间和潜空间以及向量表达的一般概念感兴趣的读者,可以在我写的书《机器学习 Q 和 AI》的第一章中找到更多信息:
-
机器学习 Q 和 AI (2023) 由 Sebastian Raschka 著作,
leanpub.com/machine-learning-q-and-ai -
以下论文更深入地讨论了字节对编码作为分词方法的使用:
-
《稀有词的子词单元神经机器翻译》(2015) 由 Sennrich 等人编写,
arxiv.org/abs/1508.07909 -
用于训练 GPT-2 的字节对编码分词器的代码已被 OpenAI 开源:
-
github.com/openai/gpt-2/blob/master/src/encoder.py -
OpenAI 提供了一个交互式 Web UI,以说明 GPT 模型中的字节对分词器的工作原理:
-
platform.openai.com/tokenizer -
对于对研究其他流行 LLMs 使用的替代分词方案感兴趣的读者,可以在 SentencePiece 和 WordPiece 论文中找到更多信息:
-
SentencePiece:一种简单且语言无关的子词分词器和去分词器,用于神经文本处理(2018),作者 Kudo 和 Richardson,
aclanthology.org/D18-2012/ -
快速 WordPiece 分词(2020),作者 Song 等人,
arxiv.org/abs/2012.15524
2.11 练习答案
练习答案的完整代码示例可以在补充的 GitHub 仓库中找到:github.com/rasbt/LLMs-from-scratch
练习 2.1
您可以通过一个字符串逐个提示编码器来获得单个标记 ID:
print(tokenizer.encode("Ak"))
print(tokenizer.encode("w"))
# ...
- 1
- 2
- 3
这将打印:
[33901]
[86]
# ...
- 1
- 2
- 3
然后,您可以使用以下代码来组装原始字符串:
print(tokenizer.decode([33901, 86, 343, 86, 220, 959]))
- 1
这将返回:
'Akwirw ier'
- 1


