
- 1Jmeter工具简介_jmeter工具介绍
- 2Gitee 码云与Git 交互_idea git连接码云
- 3JVM——查看full gc频率(jstat -gc)_查看full gc次数
- 4开源表单流程设计器有哪几个突出的优势特点?
- 5-bash:mysql:command not found 详解_-bash: mysql: command not found
- 6使用 CapCut 实现免费使用文生图 AI 功能_capcut ai
- 7【EFCore学习】EFCore梳理
- 82025南京理工大学计算机考研信息汇总
- 9android缩放动画背景图片,Android更改背景图像,淡入/淡出动画_android_开发99编程知识库...
- 10基于Springboot框架新闻信息管理系统设计与实现
让天下没有难Tuning的大模型-PEFT(参数效率微调)技术简介_参数高效微调 peft
赞
踩
https://www.yuque.com/meta95/hmc3l4/ozgy13dx4akv7v17?singleDoc# 《让天下没有难Tuning的大模型-PEFT技术简介》
最近,深度学习的研究中出现了许多大型预训练模型,例如GPT-3、BERT等,这些模型可以在多种自然语言处理任务中取得优异的性能表现。而其中,ChatGPT模型因为在对话生成方面的表现而备受瞩目,成为了自然语言处理领域的热门研究方向。
然而,这些大型预训练模型的训练成本非常高昂,需要庞大的计算资源和大量的数据,一般人难以承受。这也导致了一些研究人员难以重复和验证先前的研究成果。为了解决这个问题,研究人员开始研究Parameter-Efficient Fine-Tuning (PEFT)技术。PEFT技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。因此,PEFT技术可以在提高模型效果的同时,大大缩短模型训练时间和计算成本,让更多人能够参与到深度学习研究中来。下面我们将深入探讨PEFT的一些主要做法。
常用的PEFT(参数效率微调)方法
Adapter Tuning
谷歌的研究人员首次在论文《Parameter-Efficient Transfer Learning for NLP》提出针对BERT的PEFT微调方式,拉开了PEFT研究的序幕。他们指出,在面对特定的下游任务时,如果进行Full-fintuning(即预训练模型中的所有参数都进行微调),太过低效;而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。
于是他们设计了如下图所示的Adapter结构,将其嵌入Transformer的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将Adapter设计为这样的结构:首先是一个down-project层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个up-project结构将低维特征映射回原来的高维特征;同时也设计了skip-connection结构,确保了在最差的情况下能够退化为identity。
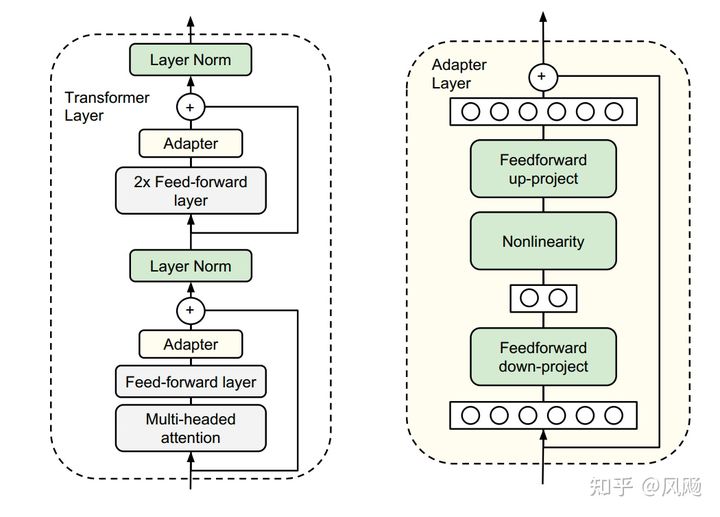
从实验结果来看,该方法能够在只额外对增加的3.6%参数规模(相比原来预训练模型的参数量)的情况下取得和Full-finetuning接近的效果(GLUE指标在0.4%以内)。

Prefix Tuning

Prefix Tuning方法由斯坦福的研究人员提出,与Full-finetuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。
实验结果也说明了Prefix Tuning的方式可以取得不错的效果。

除此之外,作者还做了一系列的消融实验说明该方法的有效性:
-
- Prefix长度的影响
- 不同的任务所需要的Prefix的长度有差异
- Prefix长度的影响

-
- Full vs Embedding-only
- 作者对比了Embedding-only(只有最上层输入处的Embedding作为参数更新,后续的参数固定)和Full(每一层的Prefix相关的参数都训练)的方式的效果
- Prefixing vs Infixing
- 对比了[PREFIX; x; y] 方式与[x; INFIX; y] 方式的差异,还是Prefix方式最好
- Full vs Embedding-only

-
- Initialization
- 用任务相关的Prompt去初始化Prefix能取得更好的效果
- Initialization

Prompt Tuning
论文《The Power of Scale for Parameter-Efficient Prompt Tuning》
我给这篇文章取了个新名字:Scale is All You Need,总的来说就是,只要模型规模够大,简单加入Prompt tokens进行微调,就能取得很好的效果。
该方法可以看作是Prefix Tuning的简化版本,只在输入层加入prompt tokens,并不需要加入MLP进行调整来解决难训练的问题,主要在T5预训练模型上做实验。似乎只要预训练模型足够强大,其他的一切都不是问题。作者也做实验说明随着预训练模型参数量的增加,Prompt Tuning的方法会逼近Fine-tune的结果。


实验

作者做了一系列对比实验,都在说明:随着预训练模型参数的增加,一切的问题都不是问题,最简单的设置也能达到极好的效果。
- a) Prompt长度影响:模型参数达到一定量级时,Prompt长度为1也能达到不错的效果,Prompt长度为20就能达到极好效果。
- b) Prompt初始化方式影响:Random Uniform方式明显弱于其他两种,但是当模型参数达到一定量级,这种差异也不复存在。
- c) 预训练的方式:LM Adaptation的方式效果好,但是当模型达到一定规模,差异又几乎没有了。
- d) 微调步数影响:模型参数较小时,步数越多,效果越好。同样随着模型参数达到一定规模,zero shot也能取得不错效果。
P-Tuning
V1
P-Tuning方法的提出主要是为了解决这样一个问题:大模型的Prompt构造方式严重影响下游任务的效果。

P-Tuning提出将Prompt转换为可以学习的Embedding层,只是考虑到直接对Embedding参数进行优化会存在这样两个挑战:
- Discretenes: 对输入正常语料的Embedding层已经经过预训练,而如果直接对输入的prompt embedding进行随机初始化训练,容易陷入局部最优。
- Association:没法捕捉到prompt embedding之间的相关关系。

作者在这里提出用MLP+LSTM的方式来对prompt embedding进行一层处理

与Prefix-Tuning的区别
这篇文章(2021-03)和Prefix-Tuning(2021-01)差不多同时提出,做法其实也有一些相似之处,主要区别在
- Prefix Tuning是将额外的embedding加在开头,看起来更像是模仿Instruction指令;而P-Tuning的位置则不固定。
- Prefix Tuning通过在每个Attention层都加入Prefix Embedding来增加额外的参数,通过MLP来初始化;而P-Tuning只是在输入的时候加入Embedding,并通过LSTM+MLP来初始化。
V2
论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
从标题就可以看出这篇文章的野心,P-Tuning v2的目标就是要让Prompt Tuning能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌Fine-tuning的结果。
那也就是说当前Prompt Tuning方法未能在这两个方面都存在局限性。
- 不同模型规模:Prompt Tuning和P-tuning这两种方法都是在预训练模型参数规模够足够大时,才能达到和Fine-tuning类似的效果,而参数规模较小时效果则很差。

- 不同任务类型:Prompt Tuning和P-tuning这两种方法在sequence tagging任务上表现都很差。
主要结构
相比Prompt Tuning和P-tuning的方法, P-tuning v2方法在多层加入了Prompts tokens作为输入,带来两个方面的好处:
- 带来更多可学习的参数(从P-tuning和Prompt Tuning的0.1%增加到0.1%-3%),同时也足够parameter-efficient。
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
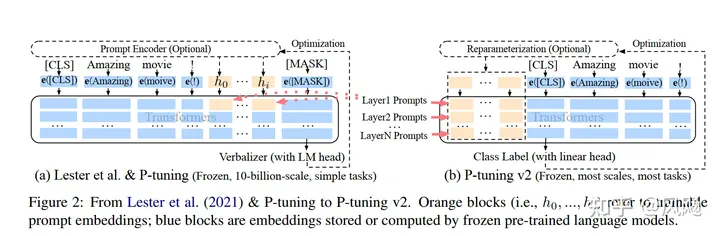
几个关键设计因素
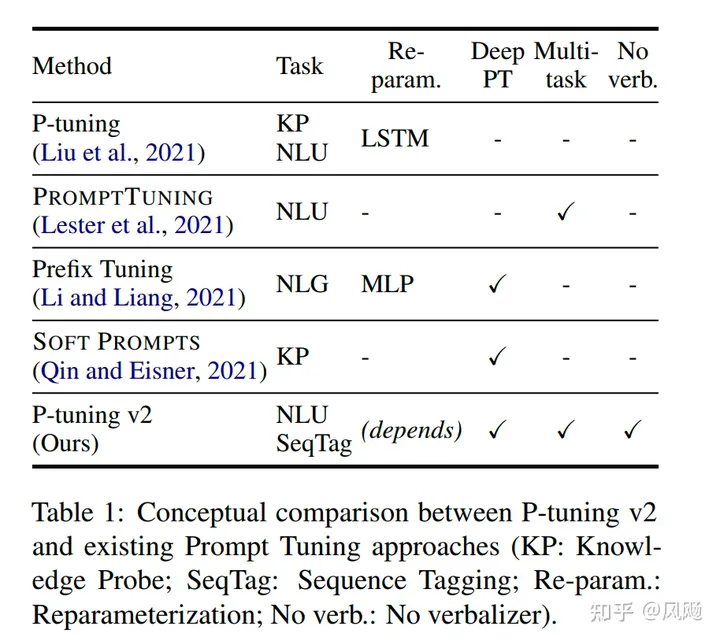
- Reparameterization:Prefix Tuning和P-tuning中都有MLP来构造可训练的embedding。本文发现在自然语言理解领域,面对不同的任务以及不同的数据集,这种方法可能带来完全相反的结论。
- Prompt Length: 不同的任务对应的最合适的Prompt Length不一样,比如简单分类任务下length=20最好,而复杂的任务需要更长的Prompt Length。
- Multi-task Learning 多任务对于P-Tuning v2是可选的,但可以利用它提供更好的初始化来进一步提高性能。
- Classification Head 使用LM head来预测动词是Prompt Tuning的核心,但我们发现在完整的数据设置中没有必要这样做,并且这样做与序列标记不兼容。P-tuning v2采用和BERT一样的方式,在第一个token处应用随机初始化的分类头。
实验结果
- 不同预训练模型大小下的表现,在小模型下取得与Full-finetuning相近的结果,并远远优于P-Tuning。
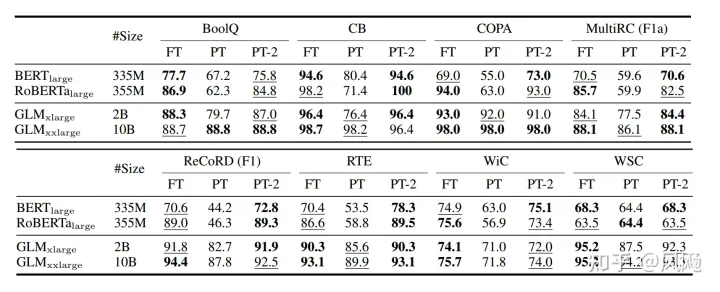
- 不同任务下的P-Tuning v2效果都很好,而P-Tuning和Prompt Learning效果不好;同时,采用多任务学习的方式能在多数任务上取得最好的结果。
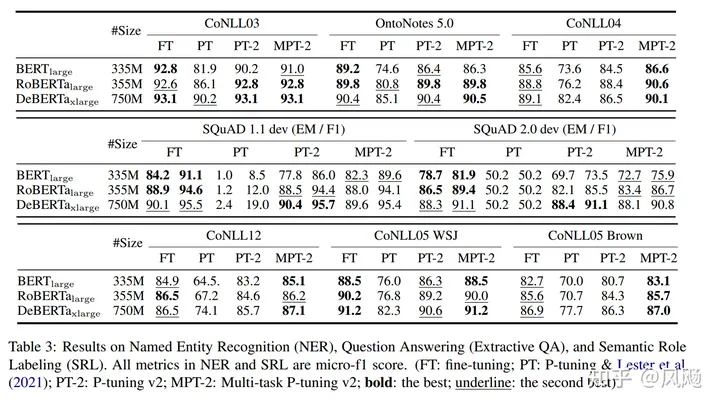
- Verbalizer with LM head v.s. [CLS] label with linear head,两种方式没有太明显的区别

- Prompt depth,在加入相同层数的Prompts前提下,往更深层网络加效果优于往更浅层网络(只有BoolQ中17-24反而低于1-8是例外)。

LoRA
微软和CMU的研究者指出,现有的一些PEFT的方法还存在这样一些问题:
-
- 由于增加了模型的深度从而额外增加了模型推理的延时,如Adapter方法
- Prompt较难训练,同时减少了模型的可用序列长度,如Prompt Tuning、Prefix Tuning、P-Tuning方法
- 往往效率和质量不可兼得,效果差于full-finetuning。
有研究者对语言模型的参数进行研究发现:语言模型虽然参数众多,但是起到关键作用的还是其中低秩的本质维度(low instrisic dimension)。本文受到该观点的启发,提出了Low-Rank Adaption(LoRA),设计了如下所示的结构,在涉及到矩阵相乘的模块,引入A、B这样两个低秩矩阵模块去模拟Full-finetune的过程,相当于只对语言模型中起关键作用的低秩本质维度进行更新。

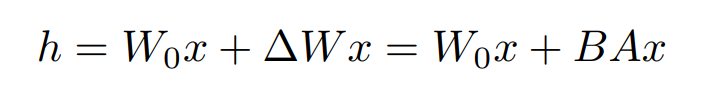
这么做就能完美解决以上存在的3个问题:
-
- 相比于原始的Adapter方法“额外”增加网络深度,必然会带来推理过程额外的延迟,该方法可以在推理阶段直接用训练好的A、B矩阵参数与原预训练模型的参数相加去替换原有预训练模型的参数,这样的话推理过程就相当于和Full-finetune一样,没有额外的计算量,从而不会带来性能的损失。
- 由于没有使用Prompt方式,自然不会存在Prompt方法带来的一系列问题。
- 该方法由于实际上相当于是用LoRA去模拟Full-finetune的过程,几乎不会带来任何训练效果的损失,后续的实验结果也证明了这一点。
在实验中,研究人员将这一LoRA模块与Transformer的attention模块相结合,在RoBERTa 、DeBERTa、GPT-2和GPT-3 175B这几个大模型上都做了实验,实验结果也充分证明了该方法的有效性。


UniPELT
Towards a Unified View of PETL
这篇ICLR2022的文章研究了典型的PEFT方法,试图将PEFT统一到一个框架下,找出它们起作用的具体原因,并进行改进。主要研究了三个问题:
- 典型的PEFT方法有什么联系?
- 典型的PEFT方法中是哪些关键模块在起作用?
- 能否对这些关键模块进行排列组合,找出更有用的PEFT方法?
通用形式
通过对Prefix Tuning的推导,得出了和Adapter Tuning以及LoRA形式一致的形式。


包括这几大要素:
- 的形式
- 嵌入Transformer结构的方式(分为Parrell和Sequential两种。Parallel指的是在输入层嵌入,这样与原有结构可以并行计算;Sequential指的是在输出层嵌入,相当于增加了网路的深度,与原有结构存在依赖关系)
- 修改的表示层(主要指对attention层的修改还是对ffn层的修改)
- 组合方式。怎么与原有的参数组合,包括简单相加(Adapter)、门控式(Prefix Tuning)、缩放式(LoRA)三种)
根据这个统一的框架,还另外设计了三种变体Parallel Adapter、Multi-head Parallel Adapter、Scaled Parallel Adapter。
一些实验
哪种嵌入形式更好:Parallel or Sequencial?
答案是:Parallel更好

对哪块结构做修改更好?Attention or FFN?
-
- 当微调的参数量较多时,从结果来看,对FFN层进行修改更好。一种可能的解释是FFN层学到的是任务相关的文本模式,而Attention层学到的是成对的位置交叉关系,针对新任务并不需要进行大规模调整。

-
- 当微调参数量较少(0.1%)时,对Attention进行调整效果更好。

哪种组合方式效果更好?
从结果来看,缩放式的组合效果更好。

结论
基于以上的经验,
- Scaled parallel adapter is the best variant to modify FFN
- FFN can better utilize modification at larger capacities
- modifying head attentions like prefix tuning can achieve strong performance with only 0.1% parameters
研究者设计出最新的结构MAM Adapter,取得了最好的效果:
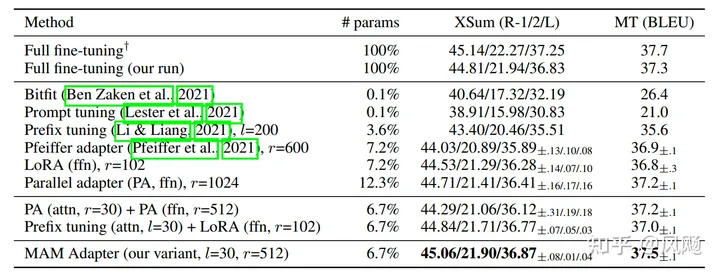
案例
典型应用
- https://github.com/mymusise/ChatGLM-Tuning 一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune
- https://github.com/tloen/alpaca-lora
PEFT实现
- https://github.com/huggingface/peft huggingface PEFT
- https://github.com/jxhe/unify-parameter-efficient-tuning
参考
- Parameter-Efficient Transfer Learning for NLP
- Prefix-Tuning: Optimizing Continuous Prompts for Generation
- The Power of Scale for Parameter-Efficient Prompt Tuning
- BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
- GPT Understands, Too
- TOWARDS A UNIFIED VIEW OF PARAMETER-EFFICIENT TRANSFER LEARNING
- UNIPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
- Ladder Side-Tuning:预训练模型的“过墙梯”
- INTRINSIC DIMENSIONALITY EXPLAINS THE EFFECTIVENESS OF LANGUAGE MODEL FINE-TUNING
- Prompt-Tuning——深度解读一种新的微调范式
- P-tuning:自动构建模版,释放语言模型潜能
- P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks

