
热门标签
热门文章
- 1阿里云部署MySQL、Redis、RocketMQ,附超全教程文档_rocketmq如何配置连接数据库
- 2【项目管理】敏捷和Scrum_scrum敏捷项目管理
- 3Gopsutil/Process常用进程监控资源信息
- 4RocketMQ与Kafka深度对比:消息中间件的选择之战_kafka和rocketmq对比
- 5AI家居设备的未来:智能家庭的下一个大步_未来还会实现的家庭人工智能
- 6【开题报告】基于微信小程序的情侣互动小程序的设计与实现_微信小程序研究方法
- 7鼠人传(第四十九集,2024/4/27)
- 8Linux进程的优先级&&环境变量&&上下文切换&&优先级队列_查看进程的优先级
- 9git基础教程(41)repo仓库管理工具介绍_repo工具
- 10JDBC连接MySql数据库并查询数据_dbeavermysql查询语句
当前位置: article > 正文
LLM-05 大模型 15分钟 FineTuning 微调 ChatGLM3-6B(微调实战1) 官方案例 3090 24GB实战 需22GB显存 LoRA微调 P-TuningV2微调_glm fine-tuning 要多久
作者:IT小白 | 2024-05-31 01:59:25
赞
踩
glm fine-tuning 要多久
续接上节
我们的流程走到了,环境准备完毕。
装完依赖之后,上节结果为:
介绍LoRA
LoRA原理
LoRA的核心思想是在保持预训练模型的大部分权重参数不变的情况下,通过添加额外的网络层来进行微调。这些额外的网络层通常包括两个线性层,一个用于将数据从较高维度降到较低维度(称为秩),另一个则是将其从低维度恢复到原始维度。这种方法的关键在于,这些额外的低秩层的参数数量远少于原始模型的参数,从而实现了高效的参数使用。
LoRA优势
- 参数效率高:LoRA通过仅微调少量额外参数而不是整个模型,显著减少了微调所需的计算资源和存储空间。
- 避免灾难性遗忘:由于大部分预训练模型的参数保持不变,LoRA可以减轻在全参数微调过程中可能出现的灾难性遗忘问题。
- 适应性强:LoRA不仅适用于语言模型,还可以扩展到其他类型的模型,如稳定扩散模型等,显示出良好的灵活性和适应性。
配置文件
在fintuning_demo目录下的 config
ds_zereo_2/ds_zereo_3.json:deepspeed配置文件。lora.yaml/ptuning.yaml/sft.yaml: 模型不同方式的配置文件,包括模型参数、优化器参数、训练参数等。
这里选择LoRA,配置文件中的参数描述如下:

训练模式
这里主要使用 finetune_hf.py 该文件进行微调操作。其中的参数
- 第一个参数:数据集的路径
- 第二个参数:模型的路径
- 第三个参数:微调配置文件
单机多卡
同多机多卡
多机多卡
OMP_NUM_THREADS=1 torchrun --standalone --nnodes=1 --nproc_per_node=8 finetune_hf.py data/AdvertiseGen/ THUDM/chatglm3-6b configs/lora.yaml
- 1
单机单卡
python finetune_hf.py data/AdvertiseGen/ THUDM/chatglm3-6b configs/lora.yaml
- 1
参数配置
官方微调目录:/root/autodl-tmp/ChatGLM3/finetune_demo
配置文件目录:/root/autodl-tmp/ChatGLM3/finetune_demo/configs,当中我们关注lora.yaml
官方数据
训练的话,参数中需要一个:数据集的路径
下载数据
官方推荐的数据集是:AdvertiseGen,我们需要对其进行一些转换,才可以适配 ChatGLM3-6B
下载方式:
数据一览
{"conversations": [{"role": "user", "content": "类型#裙*裙长#半身裙"}, {"role": "assistant", "content": "这款百搭时尚的仙女半身裙,整体设计非常的飘逸随性,穿上之后每个女孩子都能瞬间变成小仙女啦。料子非常的轻盈,透气性也很好,穿到夏天也很舒适。"}]}
- 1
数据处理
官方提供了一个脚本来支持我们进行转换,运行下面的脚本。
import json from typing import Union from pathlib import Path def _resolve_path(path: Union[str, Path]) -> Path: return Path(path).expanduser().resolve() def _mkdir(dir_name: Union[str, Path]): dir_name = _resolve_path(dir_name) if not dir_name.is_dir(): dir_name.mkdir(parents=True, exist_ok=False) def convert_adgen(data_dir: Union[str, Path], save_dir: Union[str, Path]): def _convert(in_file: Path, out_file: Path): _mkdir(out_file.parent) with open(in_file, encoding='utf-8') as fin: with open(out_file, 'wt', encoding='utf-8') as fout: for line in fin: dct = json.loads(line) sample = {'conversations': [{'role': 'user', 'content': dct['content']}, {'role': 'assistant', 'content': dct['summary']}]} fout.write(json.dumps(sample, ensure_ascii=False) + '\n') data_dir = _resolve_path(data_dir) save_dir = _resolve_path(save_dir) train_file = data_dir / 'train.json' if train_file.is_file(): out_file = save_dir / train_file.relative_to(data_dir) _convert(train_file, out_file) dev_file = data_dir / 'dev.json' if dev_file.is_file(): out_file = save_dir / dev_file.relative_to(data_dir) _convert(dev_file, out_file) convert_adgen('data/AdvertiseGen', 'data/AdvertiseGen_fix')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
最终数据输出到:data/AdvertiseGen_fix 中。下面我们开始微调。
测试训练
下面我们使用命令来进行微调:
CUDA_VISIBLE_DEVICES=0 /root/.pyenv/shims/python finetune_hf.py /root/autodl-tmp/data/AdvertiseGen_fix THUDM/chatglm3-6b configs/lora.yaml
- 1
正常训练
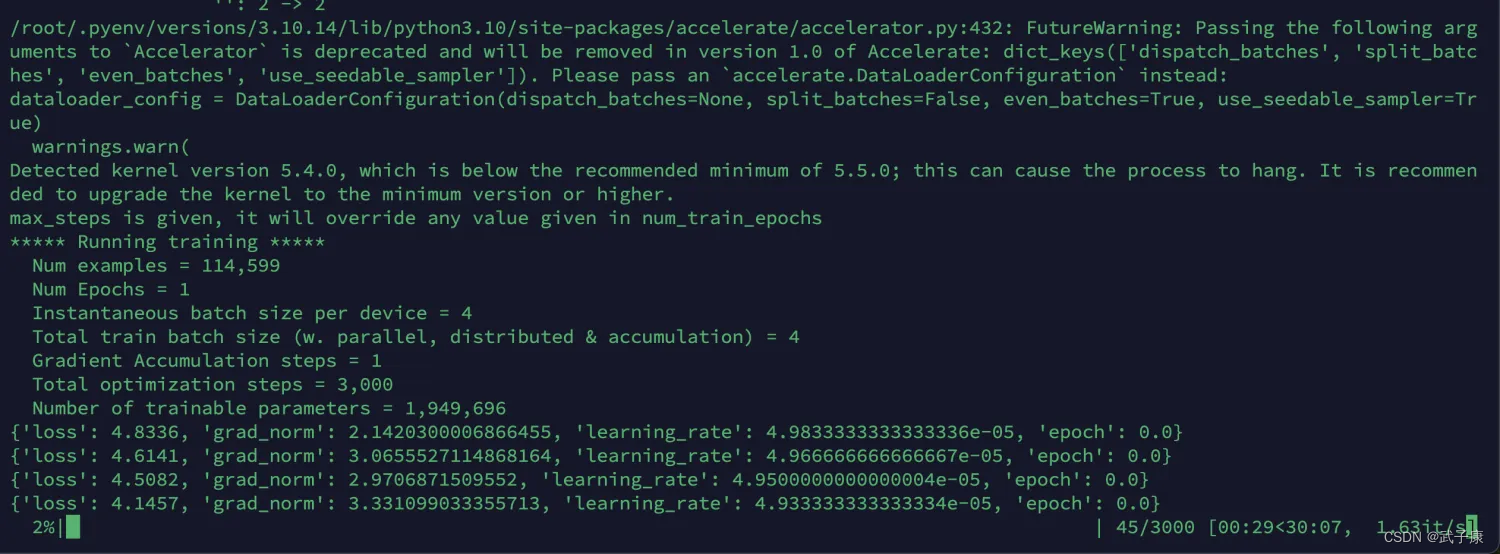
训练结束
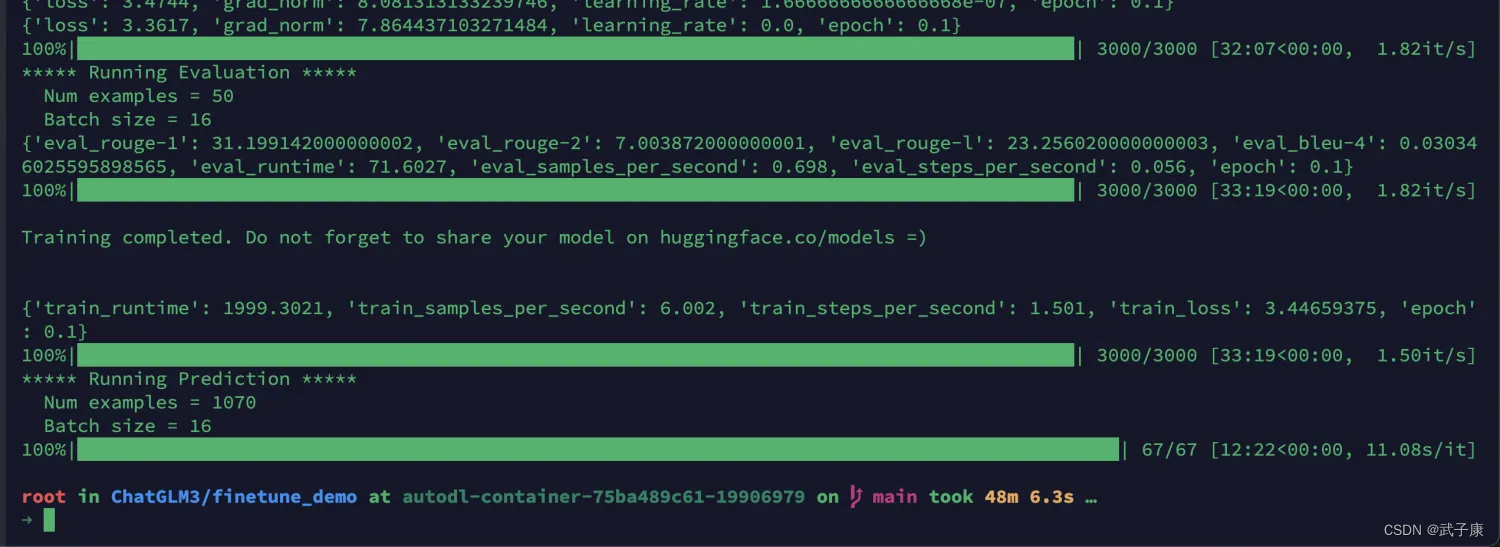
测试结果
CUDA_LAUNCH_BLOCKING=1 CUDA_VISIBLE_DEVICES=0 /root/.pyenv/shims/python inference_hf.py output/checkpoint-2000/ --prompt "类型#裙*版型#显瘦*材质#网纱* 风格#性感*裙型#百褶*裙下摆#压褶*裙长#连衣裙*裙衣门襟#拉链*裙衣门襟#套头*裙款式#拼接*裙款式#拉链*裙款式#木耳边*裙款式#抽褶*裙款式# 不规则"
- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/649804
推荐阅读
相关标签

