
- 1Linux系统审计与服务安全,打补丁_linux服务器需要打补丁吗
- 2C语言基础——预处理命令_c语言中的预处理命令
- 3【Xilinx FPGA】DDR3 IP 的学习与调试记录_xilinx sdk调试ddr
- 4【Java基础教程】(三十)Java新特性篇 · 第十讲: Stream流——释放流式编程的效率与优雅,狂肝万字只为透彻讲清 Stream流!~_parallelstream应用场景
- 5代码随想录训练营第56天|LeetCode 583. 两个字符串的删除操作、72. 编辑距离
- 6Android 切换手势和按键、底部recent键事件传递_android 手势导航快速切换应用流程
- 7pycharm中加了断点却无法调试,直接执行到程序结束怎么解决_pycharm断点调试失效
- 8qt无标题栏 模态对话框_qt 弹出无标题文本框
- 9完全解读低通滤波,并且用其C语言实现_低通滤波器c代码
- 10头歌—Hive的安装与配置_hive的安装与配置头歌答案第一关_头歌hive的安装与配置答案
基于Spark的学情日志数据分析可视化系统_基于spark的数据分析系统
赞
踩
摘 要
在如今教育环境中,学校日志数据具有潜在的宝贵信息。这些数据包括学生的登录记录、课程浏览历史、作业提交时间、在线测试成绩等待。通过深入分析和可视化这些数据,可以找出学生学习、生活、身体和心理等各方面的成长情况。通过分析学生学习行为和模式,教育者可以更好地了解每个学生的需求和学术紧张,从而提供个性化支持,改善学术成绩和学习体验。通过数据分析可视化,教育者和管理者可以更好地了解课程教育效果和学生的参与情况,这有助于制定教育改进策略和优化资源分配,从而提高教学质量[1]。
为了贴近生活实际,本系统使用java语言模拟学生的日常行为数据如在校消费记录,图书馆借阅信息,校园内打卡记录等信息,将模拟好的数据使用消息队列模型Kafka来进行存储[2]。模拟数据的同时使用Spark streaming实时计算框架消费kafka消息队列中学生的行为数据[17],进行实时的分析计算,将计算结果存储到mysql数据库中,使用spring boot的web框架系统读取mysql数据库中的结果数据以图表进行实时展示,方便学校老师及时了解学生的实时信息[6]。
传统的学生管理等系统只能进行离线的学生信息统计分析[16],本系统能够实时地对学生信息进行追踪。
关键词:在线教务;数据分析;数据可视化
ABSTRACT
In today's educational environment, school log data has the potential for valuable information. These data include student login records, course browsing history, homework submission time, online test scores, etc. By analyzing and visualizing these data in depth, we can identify the growth situation of students in various aspects such as learning, life, physical and psychological well-being. By analyzing student learning behavior and patterns, educators can better understand each student's needs and academic tension, thereby providing personalized support, improving academic performance and learning experience. Through data analysis and visualization, educators and managers can better understand the effectiveness of curriculum education and student participation, which helps to develop educational improvement strategies and optimize resource allocation, thereby improving teaching quality.
Key words: Online Academic Affairs; Data Analysis; Data Visualization
第一章 引言
1.1 背景
中国目前高等教育现状分析随着我国社会主义市场经济体制和政治体制的不断完善和发展,我国的高等教育体制也面临着新的发展阶段。一方面,在体制改革方面取得了累累硕果,人们对先进文化的需求得到了更好的满足,从而促进了社会的发展。另一方面,教育体制问题层出不穷,严重束缚了人才自由全面的发展。教育体制问题亟待解决。
一.现就中国目前高等教育现状分析如下:
我国高等教育的发展历程清晰地显示,在我国这样一个人口众多的发展中国家,在有限的情况下,必然要维持一段时间的“穷国办大教育”的局面,且这种背景下的高等教育质量是很难保证的。另外中国的总人口数中,我国受教育的人口较低,受高等教育的人口更少,这已严重的影响了我国特色社会主义市场经济的健康发展和高等教育水平的发展。自20世纪90年代以来,我国高等教育无论在办学规模、办学质量、办学理念、办学方式,还是在师资水平、学生人数、高教投资、管理监控上都得到较快的发展,但仍低于发展中国家的平均水平,远远未能适当超前于社会发展和经济发展。改革开放以来,我国经济保持了平均8%的较快增长率,富裕起来的中国人,在经济上具备了 “接收更好更高教育”的经济能力,并且在心理上也产生了对高等教育的更迫切的需求。然而现有的高等教育的供给无论在数量上,还是在质量上都显得严重不足。当今我国高等教育面临的诸多问题,如果不加以探讨并尽可能提出相应的对策,对于实现我国高等教育发展新阶段的目标极为不利。
二.目前我国高等教育面临的问题
高等教育的生存与竞争问题
我国高等教育发端的严重滞后,发轫后的不连续性发展历程,以及一个多世纪高等教育投入的严重不足,是我国高等教育在总体实力上远低于欧美等国高等教育的总体实力。使得我国在WTO的框架和游戏规则内,在与欧美高等教育的生存竞争中处于“历史性的弱势地位”。可以说这是在我国高等教育存在的整个历史阶段中,挑战最为严重的时期,同时也是我国高等教育面临的首要问题。
高等教育的公平与效率问题
当前,我国高等教育无论是从起点、过程之中,还是从结果上都是不公平的。如果处理不好,就可能给高等教育的健康发展带来不可预见的损失。而高等教育资源利用效率的低下,也无疑加剧了有限的高等教育的资源紧张和匮乏程度;另一方面,在公平第一还是效率第一的争论上,还没一个很好的定论,也是高等教育发展不稳的一个诱因。
高等教育大众化与质量监控问题
高等教育质量问题总是伴随着高等教育发展的大众化而不断被人们关注,质量是高等教育发展过程中一个永恒的主题。当前,我国高等教育正逐渐由精英化教育向大众化教育方向发展。同时高等教育的“扩招”所言生的高等教育的“量”的扩张与“质”的稳定和提高的问题凸显出来。如果不能把教育的“量”的扩张与“质”的稳定和提高有机结合,必然成为制约高等教育发展的重要问题。如果不能处
理好由于高等教育的大众化导致的质量监控问题,我国高等教育的发展就有可能冲走别人走过的弯路。
教育部门的发展目标盲目追求高层次,偏离了社会需求。 高等教育人才培养与社会人才需求不相适应,培养与需求相脱节,本科生比例过大,挤占了专科生的就业市场;而专科生所学则过于理论化,不能胜任高级技工的工作。一方面,本科毕业生的工资水平下跌,接近普通的蓝领熟练工的工资。另一方面许多专科生找不到工作。目前高校毕业生就业难问题已成为社会关注的焦点。进而引发了人们对教育的怀疑,对社会的不满,甚至上升到对改革的抱怨。更让人担心的是这种负面影响逐渐蔓延到义务教育阶段,一些边远地区、贫困地区新的读书无用论正在抬头。影响了民族整体素质的提高,也间接地影响了社会的文明、道德、公平,加大了城乡之间的差距以及解决三农问题的难度。是政策导向、社会价值观导向、人才培养结构出了问题。不是大学生太多了,是从政府到教育系统自身乃至全社会对孩子们的成长与发展关心太少了。
是高等教育自身的道德与科学精神问题。
一教育者方面,学术造假及学术腐败问题折射其背后的学术道德水准下降、科学精神缺失的状态,这种负面作用将直接影响到在校学生,进而影响到整个未来社会的道德水准及社会诚信。另外,近几年高等教育自身也出现了一些背离科学精神的做法,如:过于频繁的各种评审、评优与评奖;过于量化的各种指标评价体系等。这些带有较强行政主导色彩和功利驱动背景的做法催生了学术浮躁和急功近利,
弱化了学术道德与科学精神。二学生方面,校园暴力事件频繁发生,学生思想道德水平不断下降,法律意识淡薄,综合素质不高。影响学生的身心健康,在社会上造成不良影响。
在如今教育环境中,学校日志数据具有潜在的宝贵信息[2]。这些数据包括学生的登录记录、课程浏览历史、作业提交时间、在线测试成绩等,通过SparkStreaming等实时技术来存储消费,对学生日志信息进行实时分析[8]。通过深入分析和可视化这些数据,可以找出学生学习、生活、身体和心理等各方面的成长情况。通过分析学生学习行为和模式,教育者可以更好地了解每个学生的需求和学术紧张,从而提供个性化支持,改善学术成绩和学习体验。通过数据分析可视化,教育者和管理者可以更好地了解课程教育效果和学生的参与情况,这有助于制定教育改进策略和优化资源分配,从而提高教学质量。
1.2 研究的目的和意义
中国高等教育目前所面临的问题,其本质仍然是生产关系不适应生产力的发展。由政府财政支撑的国立高等教育体系难以满足人民群众日益增长的强烈需求。解决这一问题的根本方法仍然是变革生产关系,解放生产力。
完善我国高等教育网网络体系,增强他在世界的影响力和辐射力,及高等教育的体系化和网络化:开展中外强强合作办学,努力打造以一流大学和学科,加快国际认证和我国高等教育的国际准入,及高等教育的国际化和开放化;加强高等教育符合国际标准的法规建设和遵循国际通行的学术规范,及高等教育的法制化和规范化;发展职业教育和数字教育,建立终身学习观念,及高等教育的数字化和终身化。从而是我国高等教育首先从质量上达到或保持在高水平的运作平台上,以质量求的发展的机遇。
追求相对公平是社会主义制度和社会主义高等教育的本质规定和内在要求,社会主义高等教育必须坚持公平原则。首先应完善助学保障制度,建立相对合理的奖、贷、助、减制度,尽可能保证亲困学生不因经济困难而失去接受高等教育的机会;其次,建立对弱势群体的“补偿利益”制度,包括对地区弱势、经济弱势、身心弱势的群体的利益补偿,及高等教育向这些弱势群体倾斜。最后,针对不同高
校的发展起点的不同所衍生的二次不公平问题,可以建立对弱势高等教育机构的资助制度,鼓励如是高等教育的机构投资主体的多元化和多渠道。
要保证高等教育大众化的适应性和质量的延续性,就必须建立高等教也质量的监控机制。具体地说,一是高等教育质量观的多样化,即学术上的质量观、满足社会需求的质量观和整体性质量关;二是树立牢固的质量意识,把质量与法制观念紧密结合起来,做到依法治教,依法保质;三是建立内控质量监控机制和外控质量监控机制,即内部建立校、院、系、班四级教学质量管理体系和规章制度,外部应建立政府、社会和相对独立的评价机构三方互动有互不干涉的质量监控机制。四是建立与国际接轨的高等教育质量监控的标准化和数字化,从而使中国的高等教育达到世界的教育标准。
教育的过度发展与“知识型劳动力过剩”的互动必然造成教育资源的配臵不当和投资效率低下。为了解决高等教育人才培养与社会人才需求不相适应的问题,一方面要改进教学内容、教学方式、培养模式另一方面加大求职辅导的力度,提高毕业生核心就业竞争力——工作能力,提高就业率、薪资、社会满意度,为宣传高校吸引生源提供第三方公正和专业性权威依据。
教育者方面,应加强自身的文化和道德修养,强化法律意识,起到积极表率作用。学生方面,认真学习科学文化知识,崇尚科学与法律,不断提高自身修养,做一个有理想、有道德、有文化、有纪律的合格的新时代大学生。
本日志分析与可视化系统采用数据模拟的方式,使用sparkstreaming kafka框架实时模拟学生访问学校教务处等网站的日志记录,推送到kafka消息队列中,然后使用SparkStreaming实时消费kafka中的日志记录,分析统计学生的各种操作,然后将分析结果存储到mysql数据库中,最后使用SpringBoot框架结合echarts框架进行数据的可视化。
主要内容
1)数据模拟,通过java程序实时模拟学生访问学校教务处等网站的日志记录,推送到kafka消息队列中。
2)数据分析处理,使用sparkstreaming框架实时消费kafka中的日志信息,进行各项指标分析。
3)数据可视化,使用SpringBoot和echarts框架对分析的结果数据进行大屏展示,例如柱状图,折线图,饼状图,散点图等。
第二章 技术简介
2.1 技术摘要
基于Spark的学情日志数据分析可视化系统开发工具采用IntelliJ IDEA进行开发。使用maven进行工程jar包管理[9]。
2.1.1idea开发工具简介
IDEA 全称 IntelliJ IDEA,是java编程语言的集成开发环境。IntelliJ在业界被公认为最好的java开发工具,尤其在智能代码助手、代码自动提示、重构、JavaEE支持、各类版本工具(git、svn等)、JUnit、CVS整合、代码分析、 创新的GUI设计等方面的功能可以说是超常的。
InteliJ IDEA曾在2015年的官网上这样介绍自己:
Excel at enterprise, mobile and web development with Java, Scala and Groovy,with all the latest modern technologies and frameworks available out of the box.
简译: IntelliJ IDEA主要用于支持Java、 Scala、 Groovy 等语言的开发工具,同时具备支持目前主流的技术和框架,擅长于企业应用、移动应用和Web应用的开发。
2.1.2 maven项目构建管理工具简介
Maven这个单词来自于意第绪语(犹太语),意为知识的积累,最初在Jakata Turbine项目中用来简化构建过程。
Maven是一个项目管理工具它包含了一个项目对象模型 (Project Object Model),反应在配置中,就是pom.xml文件,另外就是一组标准集合,一个项目生命周期(Project Lifecycle),一个依赖管理系统(Dependency Management System),和用来运行定义在生命周期阶段(phase)中插件(plugin)目标(goal)的逻辑。当使用Maven的时候,可以用一个明确定义的项目对象模型来描述你的项目,即pom.xml文件,然后Maven可以应用横切的逻辑,这些逻辑来自一组共享的(或者自定义的)插件。
2.2开发环境
软件开发环境(Software Development Environment,SDE)是指在基本硬件和数字软件的基础上,为支持系统软件和应用软件的工程化开发和维护而使用的一组软件,简称SDE。它由软件工具和环境集成机制构成,前者用以支持软件开发的相关过程、活动和任务,后者为工具集成和软件的开发、维护及管理提供统一的支持。本系统在本地电脑操作系统进行开发,操作系统及各类开发软件版本如下:
操作系统:WINDOWS 10
JDK:1.8
IDEA:IntelliJ IDEA 2020.1.1
VMWARE:15.5pro
HADOOP:3.2.2
SPARK:3.1.2
KAFKA:3.3.1
2.3开发技术
2.3.1 kafka简介
Apache kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速、可扩展、可持久化的特点。它现在是Apache旗下的一个开源系统,作为hadoop生态系统的一部分,被各种商业公司广泛应用。它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/spark流式处理引擎。
Kafka的特性
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
2.3.2 SpringBoot及layui简介
Spring Boot是一个基于Spring框架的快速开发脚手架,它简化了Spring应用的初始化和搭建过程,提供了众多便利的功能和特性,比如自动配置、嵌入式Tomcat等,让开发人员可以更加专注于业务逻辑的实现。
Spring Boot还提供了强大的插件体系和广泛的集成,可以轻松地与其他技术栈集成,比如Thymeleaf模板、JPA、MyBatis、Redis、MongoDB等,同时也支持对微服务的开发和管理。
Spring Boot 是一种基于 Spring Framework 的快速应用程序开发工具,它有以下优点:
快速开发:Spring Boot 提供了快速、简单的开发方式,自动配置 Spring 和其他第三方库,使开发人员专注于业务逻辑的编写,从而极大地提高了开发速度。
微服务支持:Spring Boot 自带微服务开发核心组件(如 Spring Cloud),提供了一套完整的微服务开发和部署方案,使开发人员可以轻松构建和部署大型、复杂的分布式应用程序。
轻量级:Spring Boot 的特性是精简、灵活、模块化的,应用程序的运行时开销较小,能够快速响应用户请求,同时减少了开发和部署的成本。
易于部署和管理:Spring Boot 应用程序可以打成 jar 或 war 包,可以很方便地部署到云平台或容器中,例如 Docker、Kubernetes 等,并且还有一些常用的管理工具,例如 Actuator,可以监控、管理应用程序。
多数据源支持:Spring Boot 提供了多种数据库的支持,包括关系型数据库和非关系型数据库,开发人员可以根据自己的需要方便地进行配置和使用。
安全性:Spring Boot 提供了各种安全功能和特性,如 SSL/TLS、OAuth2、JWT 等,可以保障应用程序的安全性。
总的来说,Spring Boot 的优点包括快速开发、微服务支持、轻量级、易于部署和管理、多数据源支持和安全性等方面,这些优点使得 Spring Boot 成为目前非常流行的 Java 应用程序开发框架。
总之,Spring Boot 是一个 Spring 构架的开发框架,用于简化 Spring 应用程序的开发过程。它使应用程序开发速度更快,更容易部署和管理,并且可以与现有的 Spring 生态基础设施集成,使得开发人员能够快速地构建和部署应用程序。
2.3.3 Spark简介
Spark是基于内存的分布式计算框架。在迭代计算的场景下,数据处理过程中的数据可以存储在内存中,提供了比MapReduce高10到100倍的计算能力。Spark可以使用HDFS作为底层存储,使用户能够快速地从MapReduce切换到Spark计算平台上去。Spark提供一站式数据分析能力,包括小批量流式处理、离线批处理、SQL查询、数据挖掘等,用户可以在同一个应用中无缝结合使用这些能力。Spark2x的开源新特性请参考Spark2x开源新特性。
Spark的特点如下:
•通过分布式内存计算和DAG(无回路有向图)执行引擎提升数据处理能力,比MapReduce性能高10倍到100倍。
•提供多种语言开发接口(Scala/Java/Python),并且提供几十种高度抽象算子,可以很方便构建分布式的数据处理应用。
•结合SQL、Streaming等形成数据处理栈,提供一站式数据处理能力。
•完美契合Hadoop生态环境,Spark应用可以运行在Standalone、Mesos或者YARN上,能够接入HDFS、HBase、Hive等多种数据源,支持MapReduce程序平滑转接。
Spark架构图如下:
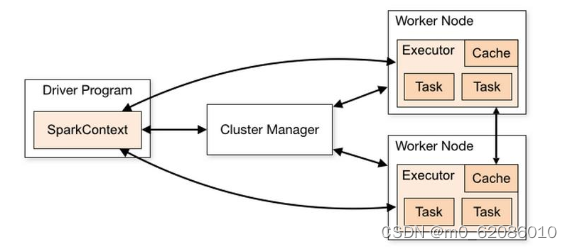
Spark基本概念说明
| 模块 | 说明 |
| Cluster Manager | 集群管理器,管理集群中的资源。Spark支持多种集群管理器,Spark自带的Standalone集群管理器、Mesos或YARN。华为Spark集群默认采用YARN模式。 |
| Application | Spark应用,由一个Driver Program和多个Executor组成。 |
| Deploy Mode | 部署模式,分为cluster和client模式。cluster模式下,Driver会在集群内的节点运行;而在client模式下,Driver在客户端运行(集群外)。 |
| Driver Program | 是Spark应用程序的主进程,运行Application的main()函数并创建SparkContext。负责应用程序的解析、生成Stage并调度Task到Executor上。通常SparkContext代表Driver Program。 |
| Executor | 在Work Node上启动的进程,用来执行Task,管理并处理应用中使用到的数据。一个Spark应用一般包含多个Executor,每个Executor接收Driver的命令,并执行一到多个Task。 |
| Worker Node | 集群中负责启动并管理Executor以及资源的节点。 |
| Job | 一个Action算子(比如collect算子)对应一个Job,由并行计算的多个Task组成。 |
| Stage | 每个Job由多个Stage组成,每个Stage是一个Task集合,由DAG分割而成。 |
| Task | 承载业务逻辑的运算单元,是Spark平台中可执行的最小工作单元。一个应用根据执行计划以及计算量分为多个Task。 |
2.3.4 SparkStreaming简介
Spark Streaming是一种构建在Spark上的实时计算框架,扩展了Spark处理大规模流式数据的能力。当前Spark支持两种数据处理方式:Direct Streaming和Receiver方式。
Direct Streaming计算流程
Direct Streaming方式主要通过采用Direct API对数据进行处理。以Kafka Direct接口为例,与启动一个Receiver来连续不断地从Kafka中接收数据并写入到WAL中相比,Direct API简单地给出每个batch区间需要读取的偏移量位置。然后,每个batch的Job被运行,而对应偏移量的数据在Kafka中已准备好。这些偏移量信息也被可靠地存储在checkpoint文件中,应用失败重启时可以直接读取偏移量信息。
需要注意的是,Spark Streaming可以在失败后重新从Kafka中读取并处理数据段。然而,由于语义仅被处理一次,重新处理的结果和没有失败处理的结果是一致的。
因此,Direct API消除了需要使用WAL和Receivers的情况,且确保每个Kafka记录仅被接收一次,这种接收更加高效。使得Spark Streaming和Kafka可以很好地整合在一起。总体来说,这些特性使得流处理管道拥有高容错性、高效性及易用性,因此推荐使用Direct Streaming方式处理数据。
Receiver计算流程
在一个Spark Streaming应用开始时(也就是Driver开始时),相关的StreamingContext(所有流功能的基础)使用SparkContext启动Receiver成为长驻运行任务。这些Receiver接收并保存流数据到Spark内存中以供处理。用户传送数据的生命周期如图5所示:
图5 数据传输生命周期
1.接收数据(蓝色箭头)
Receiver将数据流分成一系列小块,存储到Executor内存中。另外,在启用预写日志(Write-ahead Log,简称WAL)以后,数据同时还写入到容错文件系统的预写日志中。
2.通知Driver(绿色箭头)
接收块中的元数据(Metadata)被发送到Driver的StreamingContext。这个元数据包括:
•定位其在Executor内存中数据位置的块Reference ID。
•若启用了WAL,还包括块数据在日志中的偏移信息。
3.处理数据(红色箭头)
对每个批次的数据,StreamingContext使用Block信息产生RDD及其Job。StreamingContext通过运行任务处理Executor内存中的Block来执行Job。
4.周期性地设置检查点(橙色箭头)
5.为了容错的需要,StreamingContext会周期性地设置检查点,并保存到外部文件系统中。
容错性
Spark及其RDD允许无缝地处理集群中任何Worker节点的故障。鉴于Spark Streaming建立于Spark之上,因此其Worker节点也具备了同样的容错能力。然而,由于Spark Streaming的长正常运行需求,其应用程序必须也具备从Driver进程(协调各个Worker的主要应用进程)故障中恢复的能力。使Spark Driver能够容错是件很棘手的事情,因为可能是任意计算模式实现的任意用户程序。不过Spark Streaming应用程序在计算上有一个内在的结构:在每批次数据周期性地执行同样的Spark计算。这种结构允许把应用的状态(亦称Checkpoint)周期性地保存到可靠的存储空间中,并在Driver重新启动时恢复该状态。
对于文件这样的源数据,这个Driver恢复机制足以做到零数据丢失,因为所有的数据都保存在了像HDFS这样的容错文件系统中。但对于像Kafka和Flume等其他数据源,有些接收到的数据还只缓存在内存中,尚未被处理,就有可能会丢失。这是由于Spark应用的分布操作方式引起的。当Driver进程失败时,所有在Cluster Manager中运行的Executor,连同在内存中的所有数据,也同时被终止。为了避免这种数据损失,Spark Streaming引进了WAL功能。
WAL通常被用于数据库和文件系统中,用来保证任何数据操作的持久性,即先将操作记入一个持久的日志,再对数据施加这个操作。若施加操作的过程中执行失败了,则通过读取日志并重新施加前面预定的操作,系统就得到了恢复。下面介绍了如何利用这样的概念保证接收到的数据的持久性。
Kafka数据源使用Receiver来接收数据,是Executor中的长运行任务,负责从数据源接收数据,并且在数据源支持时还负责确认收到数据的结果(收到的数据被保存在Executor的内存中,然后Driver在Executor中运行来处理任务)。
当启用了预写日志以后,所有收到的数据同时还保存到了容错文件系统的日志文件中。此时即使Spark Streaming失败,这些接收到的数据也不会丢失。另外,接收数据的正确性只在数据被预写到日志以后Receiver才会确认,已经缓存但还没有保存的数据可以在Driver重新启动之后由数据源再发送一次。这两个机制确保了零数据丢失,即所有的数据或者从日志中恢复,或者由数据源重发。
如果需要启用预写日志功能,可以通过如下动作实现:
•通过“streamingContext.checkpoint”(path-to-directory)设置checkpoint的目录,这个目录是一个HDFS的文件路径,既用作保存流的checkpoint,又用作保存预写日志。
•设置SparkConf的属性“spark.streaming.receiver.writeAheadLog.enable”为“true”(默认值是“false”)。
在WAL被启用以后,所有Receiver都获得了能够从可靠收到的数据中恢复的优势。建议缓存RDD时不采取多备份选项,因为用于预写日志的容错文件系统很可能也复制了数据。
2.3.5 SparkSql简介
Spark SQL的架构,在Shark原有的架构上重写了逻辑执行计划的优化部分,解决了Shark存在的问题。Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。
Spark SQL增加了SchemaRDD(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以来自Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-92规范。从Spark1.2 升级到Spark1.3以后,Spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API。
Spark SQL可以很好地支持SQL查询,一方面,可以编写Spark应用程序使用SQL语句进行数据查询,另一方面,也可以使用标准的数据库连接器(比如JDBC或ODBC)连接Spark进行SQL查询,这样,一些市场上现有的商业智能工具(比如Tableau)就可以很好地和Spark SQL组合起来使用,从而使得这些外部工具借助于Spark SQL也能获得大规模数据的处理分析能力。
第3章:系统分析
3.1可行性分析
基于Spark的学情日志数据分析可视化系统主要目标是实现对学生在校日志信息的管理与分析等。本分析可视化系统可以在浏览器中访问,现在web服务器都可以运行。而且平台中的技术也是自身所具有的,也是现在比较流行的技术之一,开发平台中的开发环境和配置都可以自行安装,平台所采用的IDEA开发工具,使用现在流行的MySQL数据库来存储平台中的所有数据,根据技术语言对数据库进行维护和扩展,这样可以使网站更加稳定和安全,最终开发出一个完美的平系统。该系统的设计到开发完成都是自己完成的,而且使用的都是普遍容易操作且常见的技术,在整个开发过程以及后续使用中,都不需要购买他人的技术软件或者花钱请教他人指导使用方法。在平台投入使用后,日常的维护也可以自动更新,因此该系统的研发具有经济可行性。
3.2需求分析
传统的学生管理等系统只能进行离线的学生信息统计分析,本系统能够实时地对学生信息进行追踪。
3.2.1管理员需求分析
1.系统管理
系统管理功能,主要为系统正常运行做支撑,主要包括用户管理、系统管理员管理等功能。
(1)用户管理:主要是对系统内的用户进行增删改查及日常维护。
(2)系统管理员管理:系统管理员在系统中只有一个,是对自己账号的信息更新和系统的日常维护。
2.老师管理
老师管理:添加、修改和删除老师信息
3.院系管理
院系管理分为学院的管理,专业管理,年级管理,是为了学院内信息修改更新做保障。
3.2.2老师需求分析
1.院系管理
在老师的功能图中,院系管理中分为班级管理、年级管理和学生管理。
(1)在班级管理中分为班级的成绩排名和班级奖惩查询,为的是查询班级中成绩优异的同学的成绩和班级内学生的奖惩情况。
(2)在年级管理中分为年级排名、年级选择、年级奖惩查询,年级排名是为了查询年级中成绩优异的学生成绩,年级奖惩查询可以看出年级中的奖惩情况,对情节严重的同学加以提醒,年级选择为选择各个年级,分别查看各年级的排名情况和奖惩情况。
(3)学生管理中分为学生静态信息管理和学生动态信息管理,学生静态信息管理主要是为了管理学生的成绩、学生的个人信息、学生的奖惩情况和学生的考勤情况。学生动态信息管理是为了通过学生校园行动的查询、学生图书借阅情况和学生的消费情况对学生的成绩进行分析,分析学生各个维度,查看学生整体学习情况、查看学生的个人学习情况,来进行相关的分析。
3.2.3功能分析
登录注册功能分析
用户注册:系统管理员通过系统预置生成,系统内的老师用户需要通过管理员来进行添加,系统内的学生需要通过老师来添加。
用户登录:在登录页面用户输入账号和密码点击登录,系统自动识别当前登录的用户是管理员还是老师或是学生,并根据登录的用户角色不同进入到不同的页面。
数据模拟功能分析
系统通过java程序,每隔2秒模拟生成一次学生信息,包含学生校园内的消费日志数据,校园图书借阅日志数据以及校园内行动轨迹日志数据,并将模拟生成的数据发送到kafka的不同topic中进行存储。
数据分析功能分析
系统使用SparkStreaming实时计算框架实时消费读取模拟程序发送到kafka的topic中的数据,进行指标实时分析统计。
数据可视化功能分析
系统数据可视化,使用springboot+echarts进行动态的图形展示。
3.2.4非功能性分析
系统性能分析
为了能够让用户可以顺利的使用基于Spark的学情日志数据分析可视化系统,平台中设置了响应指标,通过响应指标来判断平台的好坏,如果响应时间比较短,那么说明平台处理数据信息比较有效,并且提高工作人员的工作效率。平台设计中,必须要有一定的安全性和稳定性,从而保证平台正常的运转。
(1)平台功能完整性:将平台中的各个功能模块进行分析,并且分析后通过文字、表格的方式展示出来。
(2)平台运行分析:将平台中的各个模块运行情况进行分析,然后采用数据的方式进行展示。
(3)界面设计:在设计平台界面时一定要保持整洁,而且保证功能模块能够正常运转,最终保证整个平台的运行。
第4章:技术实现
4.1系统结构设计
系统先通过数据模拟生成学生日志信息,将数据发送到kafka队列中,使用sparkstreaming消费kafka队列中的日志数据进行分析,使用spark sql分析框架使用函数count进行指标统计求和,groupby函数进行分组统计,orderby函数对分析计算结果排序。最后将spark结果dataframe数据使用write函数按照overwrite模式进行写出到数据库mysql中,分析结果用数据表存储到数据库中,然后使用SpringBoot+echarts对分析结果进行图形可视化。
图4.1 系统结构图
4.1.1 图书借阅信息模拟
首先在kafka中创建名为borrow的topic用于接收模拟生成学生借阅信息;构建Properties对象分别设置kafka集群ip和端口以及kafka消息模拟为ACK为all防止消息丢失。然后创建KafkaProducer生产者对象,使用循环遍历的方式每5秒生成一次学生图书借阅信息,借阅信息包含:图书编号、书名、借阅学生学号、借阅学生姓名、图书状态(归还、借阅)、借阅开始时间、还书时间各个字段之间使用英文逗号分割。最后调用send方法向borrow主题中发送生成的图书借阅信息。
主要代码如下
//创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
while (true) {
Map<String, String> sno = null;
try {
sno = Utils.getSno();
Set<String> set = sno.keySet();
for (String no : set) {
int dd = (int) (Math.random() * 10000);
List<String> times = Utils.getTime();
int index = (int) (Math.random() * borrow.size());
String message = "B" + dd + "," + "图书" + dd + "," + no + "," + sno.get(no) + "," + (int) (Math.random() * 2) % 2 + "," + times.get(0) + "," + times.get(1);
System.out.println(message);
producer.send(new ProducerRecord<String, String>(topic, message));
System.out.println("图书借阅生产信息" + ":" + message);
}
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
//等待5秒
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
4.1.2 学生消费信息模拟
首先在kafka中创建名为consume的topic用于接收模拟生成的学生消费信息;构建Properties对象分别设置kafka集群ip和端口以及kafka消息模拟为ACK为all防止消息丢失。然后创建KafkaProducer生产者对象,使用循环遍历的方式每5秒生成一次学生消费信息,学生消费信息包含:消费标题、学生学号、学生姓名、消费金额、消费地点、消费时间各个字段之间使用英文逗号分割。最后调用send方法向consume主题中发送生成的学生消费信息。
主要代码如下
//创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
while (true) {
Map<String, String> sno = null;
try {
sno = Utils.getSno();
Set<String> set = sno.keySet();
for (String no : set) {
List<String> times = Utils.getTime();
int index = (int) (Math.random() * address.length);
String message = address[index] + "消费购物" + "," + no + "," + sno.get(no) + "," + Math.random() * 100 + "," + address[index] + "," + times.get(0);
System.out.println(message);
producer.send(new ProducerRecord<String, String>(topic, message));
System.out.println("学生消费生产信息" + ":" + message);
}
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
//等待5秒
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
4.1.3 学生行为轨迹模拟
首先在kafka中创建名为trace的topic用于接收模拟生成的学生行为轨迹信息;构建Properties对象分别设置kafka集群ip和端口以及kafka消息模拟为ACK为all防止消息丢失。然后创建KafkaProducer生产者对象,使用循环遍历的方式每5秒生成一次学生行为轨迹信息,学生行为轨迹信息包含:学生学号、学生姓名、到达时间、离开时间、地点各个字段之间使用英文逗号分割。最后调用send方法向trace主题中发送生成的学生行为轨迹信息。
//创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
while (true) {
Map<String, String> sno = null;
try {
sno = Utils.getSno();
Set<String> set = sno.keySet();
for (String no : set) {
List<String> times = Utils.getTime();
int index = (int) (Math.random() * trace.length);
String message = no + "," + sno.get(no) + "," + times.get(0) + "," + times.get(1) + "," + trace[index];
System.out.println(message);
producer.send(new ProducerRecord<String, String>(topic, message));
System.out.println("行为轨迹生产信息" + ":" + message);
}
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
//等待5秒
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
4.1.4 学生借阅信息实时消费
使用scala语言创建BorrowSparkStreamingConsumer类,在类中创建sparkconf对象设置master为local[2],调用setAppName设置任务名称为“spark stream borrow consumer”;
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("spark stream consumer")
然后创建StreamingContext流对象,流间隔设置为5秒;
val ssc = new StreamingContext(sparkConf, Seconds(5))
使用KafkaUtils.createDirectStream方式创建SparkStreaming流对象绑定kafka的borrow主题进行实时消费。
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> KafkaConf.broker_list,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "my_group1"
)
val topics = Array(KafkaConf.borrow_topic)
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
使用map将消费到的数据使用split(“,”)将消费到的kafka中的图书借阅信息进行切分得到各个字段的数据。最后使用foreachRdd的方式对每个partition中的数据使用insert into语句写入到mysql的borrow表中。
val result = stream.map(record => (record.key, record.value)).map(_._2.split(",").toList)
//将spark streaming消费的数据存到mysql中
result.foreachRDD(partitions => {
partitions.foreachPartition(records => {
val conn = getConn()
records.foreach(record => {
val sql = "insert into borrow (book_no,book_name,stu_no, stu_name,flg,begin,end) values (?,?,?,?,?,?,?)"
val p = conn.prepareStatement(sql)
p.setString(1, record(0))
p.setString(2, record(1))
p.setString(3, record(2))
p.setString(4, record(3))
p.setString(5, record(4))
p.setString(6, record(5))
p.setString(7, record(6))
p.execute()
})
conn.close()
})
})
ssc.start()
ssc.awaitTermination()
4.1.5 学生消费信息实时消费
使用scala语言创建ConsumeSparkStreamingConsumer类,在类中创建sparkconf对象设置master为local[2],调用setAppName设置任务名称为“spark stream consume consumer”;然后创建StreamingContext流对象,流间隔设置为5秒;使用KafkaUtils.createDirectStream方式创建SparkStreaming流对象绑定kafka的consume主题进行实时消费。使用map将消费到的数据使用split(“,”)将消费到的kafka中的学生消费信息进行切分得到各个字段的数据。最后使用foreachRdd的方式对每个partition中的数据使用insert into语句写入到mysql的consume表中。
4.1.6 学生行为轨迹信息实时消费
使用scala语言创建ConsumeSparkStreamingConsumer类,在类中创建sparkconf对象设置master为local[2],调用setAppName设置任务名称为“spark stream trace consumer”;然后创建StreamingContext流对象,流间隔设置为5秒;使用KafkaUtils.createDirectStream方式创建SparkStreaming流对象绑定kafka的trace主题进行实时消费。使用map将消费到的数据使用split(“,”)将消费到的kafka中的学生行为轨迹信息进行切分得到各个字段的数据。最后使用foreachRdd的方式对每个partition中的数据使用insert into语句写入到mysql的trace表中。
4.1.7 年级班级奖罚统计
使用scala语言创建AwdpstCount类,在类中构建SparkSession对象并设置master为local[*],构建properties对象设置mysql的连接账号及密码;使用read.format(‘jdbc’)的方式读取mysql数据库表中的数据进行分析统计。首先读取clazz班级表内容,使用inner join关联学生表student,年级表year,奖罚表awdpst,连接条件班级id等于学生的班级id,班级的年级id等于年级的id,奖罚中学号等于学生学号,使用group by按照年级,班级,学号进行分组统计每个年级每个班级各个学生的奖罚结果,最后使用write.mode(‘overwrite’)的方式将分析统计结果写入到mysql表中。
4.1.8 年级班级成绩统计
使用scala语言创建ScoreCount类,在类中构建SparkSession对象并设置master为local[*],构建properties对象设置mysql的连接账号及密码;使用read.format(‘jdbc’)的方式读取mysql数据库表中的数据进行分析统计。首先读取clazz班级表内容,使用inner join关联学生表student,年级表year,成绩表score,连接条件班级id等于学生的班级id,班级的年级id等于年级的id,成绩表中学号等于学生学号,使用group by按照年级,班级,学号进行分组统计每个年级每个班级各个学生的成绩结果,使用sum()函数计算学生总分,使用avg()函数计算学生平均分,最后使用write.mode(‘overwrite’)的方式将分析统计结果写入到mysql表中。
4.2数据库设计
通过平台功能设计和功能模块划分来看,此次设计的基于Spark的学情日志数据分析可视化系统涉及到了多个数据表。以下是几个主要数据库表的设计结构后功能数据库表:
(1)管理员表,保存管理员信息
管理员表字段(ID,姓名,登录账号,性别,邮箱,电话,地址)
(2)学生考勤表,保存学生考勤记录
学生考勤表字段(ID,课程名,学号,学生姓名,上课时间,学生签到时间,是否签到)
(3)学生奖罚表,保存学生奖罚信息
学生奖罚表字段(ID,奖罚主题,学号,学生姓名,奖罚详情,奖/罚)
(4)学生奖罚统计表,保存学生奖罚按年级、班级、学生统计的汇总结果
学生奖罚统计表字段(年级,班级,学生姓名,学号,奖罚主题,奖罚详情,奖/罚)
(5)借阅信息表,保存学生图书借阅信息
借阅信息表字段(ID,书籍编号,书籍名称,学号,学生姓名,借阅时间,归还时间,奖/罚)
(6)班级表,保存学校所有班级信息
班级表字段(ID,班级名称,人数,班主任id,年级id,班级简介)
(7)学院表,保存学校所有学院信息
学院表字段(ID,学院名称,学院主任id,学院简介)
(8)学生消费信息表,保存学生在校消费记录
学生消费信息表(ID,标题,学号,姓名,消费时间,地点,消费金额)
(9)专业表,保存学校所有专业信息
专业表字段(ID,专业名称,所属学院id,专业简介)
(10)学生成绩表,保存学生所有科目成绩
学生成绩表字段(ID,学号,姓名,科目,分数)
(11)学生成绩统计表,按年级、班级、学生统计总成绩和平均分
学生成绩统计表字段(年级名称,班级名称,学生名称,学号,总分,平均分)
(12)学生信息表,保存学生的基本信息
学生信息表字段(ID,所属班级id,学号,姓名,性别,邮箱,电话,地址)
(13)教师信息表,保存学校所有教师信息
教师信息表字段(ID,所属班级id,工号,姓名,性别,邮箱,电话,地址)
(14)学生行为轨迹计表,保存学生在校的行动记录
学生行为轨迹表字段(ID,学号,姓名,性别,到达时间,离开时间,地点)
(15)用户账号表,保存所有角色的账号密码
用户账号表字段(ID,登录账号,姓名,密码,角色)
(16)年级表,保存学校所有年级信息
年级表字段(ID,年级名称,年级主任id,所属专业id,年级主任邮箱,年级主任电话,年级简介)
对应的英文表示如下:
admin(id,name,login_name,gender,email,tel,address)
attend(id,name,stu_no,stu_name,flg,begin,times)
awdpst (id,name,stu_no,stu_name,des,flg,)
awdpstcount (yname,cname,sname,sno,title,des,flg)
borrow (id,book_no,book_name,stu_no,stu_name,flg,begin,end)
clazz (id,name,number,teacher_id,year_id,des)
college (id,name,teacher_id,des)
consume (id,name,stu_no,stu_name,money,address,times)
major (id,name,college_id,des)
score (id,stu_no,name,kemu,score)
scorecount (yname,cname,sname,sno,sum,avg)
student (id,clazz_id,stu_no,name,gender,email,tel,address)
teacher (id,clazz_id,work_no,name,gender,email,tel,address,)
trace (id,stu_no,stu_name,in_time,out_time,address)
user (id,login_name,name,password,role)
year (id,name,teacher_id,major_id,email,tel,des)
本系统使用MySql数据库管理软件进行数据库的实现,设计数据库物理结构如下表所示,同时为了便捷的管理相关信息,增设了一些中间关系表,使得查询时更加便捷,也便于索引的创建。
表 1 管理员表(admin)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| name | varchar | 10 | N | |||
| login_name | varchar | 255 | N | |||
| gender | varchar | 2 | N | |||
| | varchar | 50 | N | |||
| tel | varchar | 15 | N | |||
| address | text | 0 | N |
表 2 学生考勤表(attend)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| name | varchar | 10 | N | |||
| stu_no | varchar | Y | 20 | N | ||
| stu_name | varchar | 50 | N | |||
| flg | int | 20 | N | 0/1 | ||
| begin | varchar | 255 | N | |||
| times | varchar | 255 | N |
表 3 学生奖罚表(awdpst)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| name | varchar | 10 | N | |||
| stu_no | varchar | Y | 20 | N | ||
| stu_name | varchar | 50 | N | |||
| des | text | 0 | N | |||
| flg | int | 20 | N | 0/1 |
表 4 学生奖罚统计表(awdpstcount)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| yname | text | 0 | N | |||
| cname | text | 0 | N | |||
| sname | text | 0 | N | |||
| sno | text | Y | 0 | N | ||
| title | text | 0 | N | |||
| des | text | 0 | N | |||
| flg | int | 11 | N | 0/1 |
表 5 学生借阅表(borrow)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| book_no | varchar | 10 | N | |||
| book_name | varchar | 255 | N | |||
| stu_no | varchar | Y | 20 | N | ||
| stu_name | varchar | 50 | N | |||
| flg | int | 20 | N | 0/1 | ||
| begin | varchar | 255 | N | |||
| end | varchar | 255 | N |
表 6 班级表(clazz)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| name | varchar | 10 | N | |||
| number | int | 3 | N | |||
| teacher_id | bigint | Y | 20 | N | ||
| year_id | bigint | Y | 20 | N | ||
| des | text | 0 | N |
表 7 学院表(college)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| name | varchar | 10 | N | |||
| teacher_id | bigint | Y | 20 | N | ||
| des | text | 0 | N |
表 8学生消费表(consume)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| name | varchar | 20 | N | |||
| stu_no | varchar | Y | 20 | N | ||
| stu_name | varchar | 50 | N | |||
| money | double | 20 | N | |||
| address | varchar | 255 | N | |||
| times | varchar | 255 | N |
表 9 专业表(major)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| name | varchar | 10 | N | |||
| college_id | bigint | Y | 20 | N | ||
| des | text | 0 | N |
表 10 学生成绩表(score)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| stu_no | bigint | Y | 20 | N | ||
| name | varchar | 255 | N | |||
| kemu | varchar | 255 | N | |||
| score | int | 11 | N |
表 11 学生成绩统计表(scorecount)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| yname | text | 0 | N | |||
| cname | text | 0 | N | |||
| sname | text | 0 | N | |||
| sno | text | Y | 0 | N | ||
| sum | decimal | 32 | N | |||
| avg | decimal | 14 | N |
表 12 学生信息表(student)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| clazz_id | bigint | Y | 20 | N | ||
| stu_no | varchar | 255 | N | |||
| name | varchar | 10 | N | |||
| gender | varchar | 2 | N | |||
| | varchar | 50 | N | |||
| tel | varchar | 15 | N | |||
| address | text | 0 | N |
表 13 教师信息表(teacher)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| clazz_id | bigint | Y | 20 | N | ||
| work_no | varchar | 255 | N | |||
| name | varchar | 10 | N | |||
| gender | varchar | 2 | N | |||
| | varchar | 50 | N | |||
| tel | varchar | 15 | N | |||
| address | text | 0 | N |
表 14 学生行为轨迹表(trace)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| stu_no | varchar | Y | 20 | N | ||
| stu_name | varchar | 50 | N | |||
| in_time | varchar | 255 | N | |||
| out_time | varchar | 255 | N | |||
| address | varchar | 10 | N |
表 15 用户信息表(user)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| login_name | varchar | Y | 255 | N | ||
| name | varchar | 255 | N | |||
| password | varchar | 255 | N | |||
| role | varchar | 255 | N |
表 16 年级表(year)
| 字段名称 | 数据类型 | 主键 | 外键 | 字段长度 | 是否为空 | 数据范围 |
| id | bigint | Y | 20 | N | ||
| name | varchar | 10 | N | |||
| teacher_id | bigint | 20 | N | |||
| major_id | bigint | 20 | N | |||
| | varchar | 50 | N | |||
| tel | varchar | 15 | N |
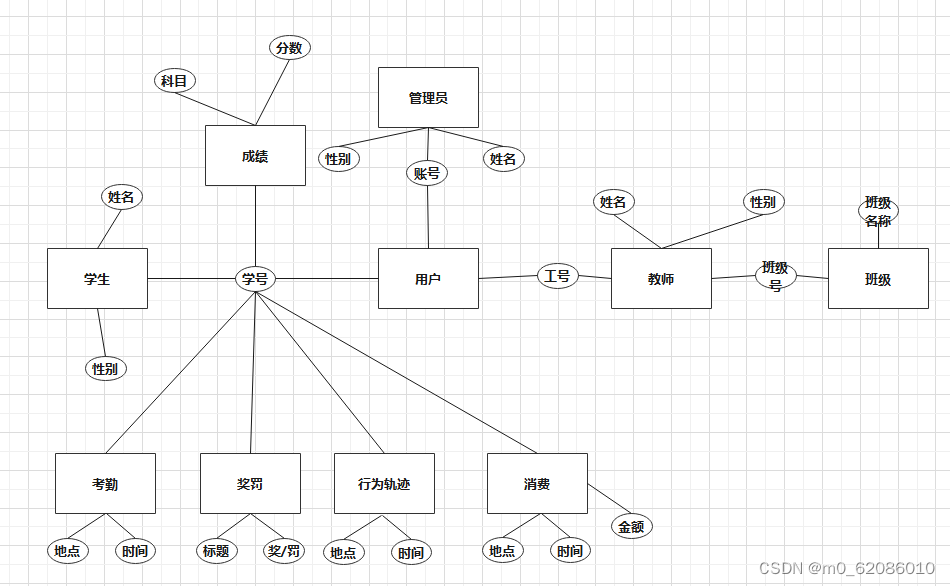
数据设计整体ER图如下
图4.2-1 系统ER图
第5章:系统实现
5.1系统主要功能设计
登录注册模块功能设计
用户输入账号密码,点击页面登录按钮进行登录,如果没有账号则联系管理员或老师进行添加。
数据模拟功能设计
本模块主要使用java语言开发,使用kafka消息队列来存储接受学生的消费信息,学生的借阅信息,学生的行为轨迹信息,然后使用SparkStreaming实时计算框架来消费kafka消息队列中的数据将数据实时存储到MySQL数据表中功能结构图如下:
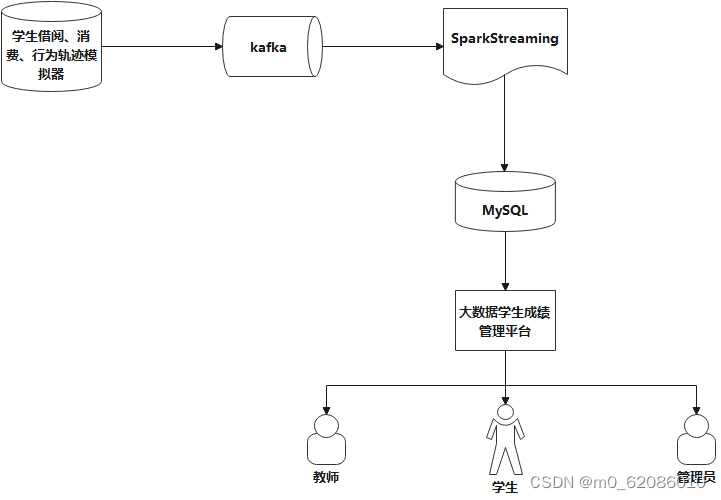
图5.1 学生日志信息模拟结构图
5.2数据处理
系统内的部分数据需要管理员和教师角色手动录入系统。
学生动态信息通过java结合kafka和SparkStreaming计算框架实时生成。
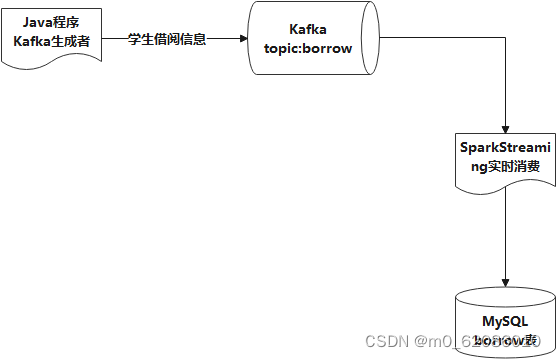
图5.2 学生日志记录处理流程图
5.3数据存储
由于本系统采用关系型数据库和分布式文件系统做为系统的存储工具。
5.4.1 分布式消息队列系统
本系统中的静态数据和基础数据通过管理员和教师来录入到MySQL关系数据库中。动态数据通过分布式消息队列Kafka来存储。
5.4.2 关系型数据库设计
本系统的业务数据存储到关系型数据库MySql中,具体设计方案如下:
1、概念结构设计
(1)确定实体集
依据分析,本系统中的用户、管理员、教师、学生、班级、专业、年级、学院、学生成绩、学生消费、学生奖罚、学生行为轨迹、学生考勤实体。各实体集与候选码对应如下图所示:
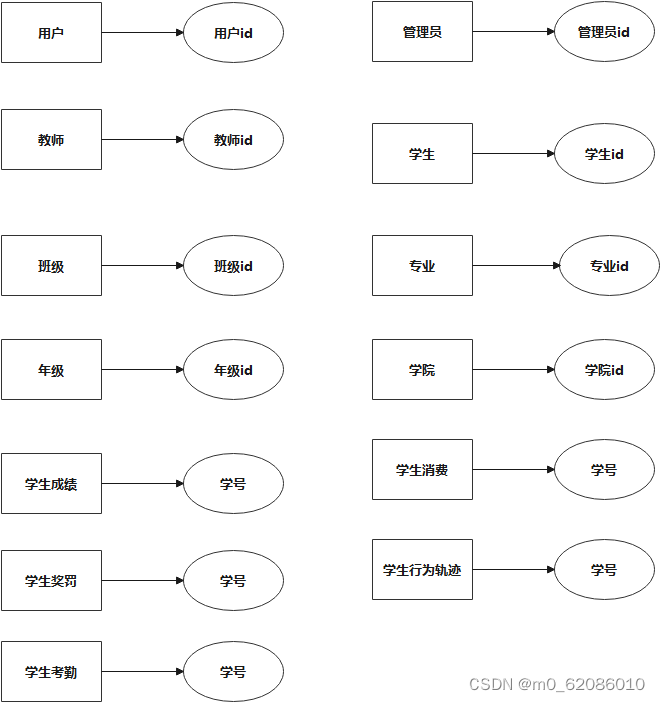
图5.4.2 实体图
5.4数据分析
使用sparkstreaming从kafka消息队列topic borrow中实时消费学生从图书馆借阅图书信息,并将消费结果存储到mysql数据库的borrow表中;使用SparkStreaming从kafka消息队列topic consume中实时消费学生在校园消费的数据,并将消费的结果存储到mysql的数据库的consume表中;使用SparkStreaming从kafka消息队列topic trace中实时消费学生在校园内的行动轨迹,并将消费到的数据存储到mysql数据库的trace表中。
使用sparksql对各年级各班级和各学生的奖惩信息进行统计分析得到年级,班级,学生,学号,奖罚项目汇总信息,将分析结果存储到awdpscount表中。
使用sparksql读取数据库中班级表、学生信息表、年级表和学生成绩表,对各年级,各班级,每个学生的总成绩和平均成绩进行分析汇总,并将结果存储到scorecount表中。
5.5数据可视化
数据可视化的主要目的在于通过动态表格的形式将分析结果以更直观、更易于理解的方式呈现出来,从而发现数据的规律和特征,辅助人们的推理决策。
班级成绩排名,老师登录系统后可以在班级成绩排名中查看各年级、各班级以及各个学生的总成绩和平均成绩的排名情况。排名结果使用table表格的形式来展示。
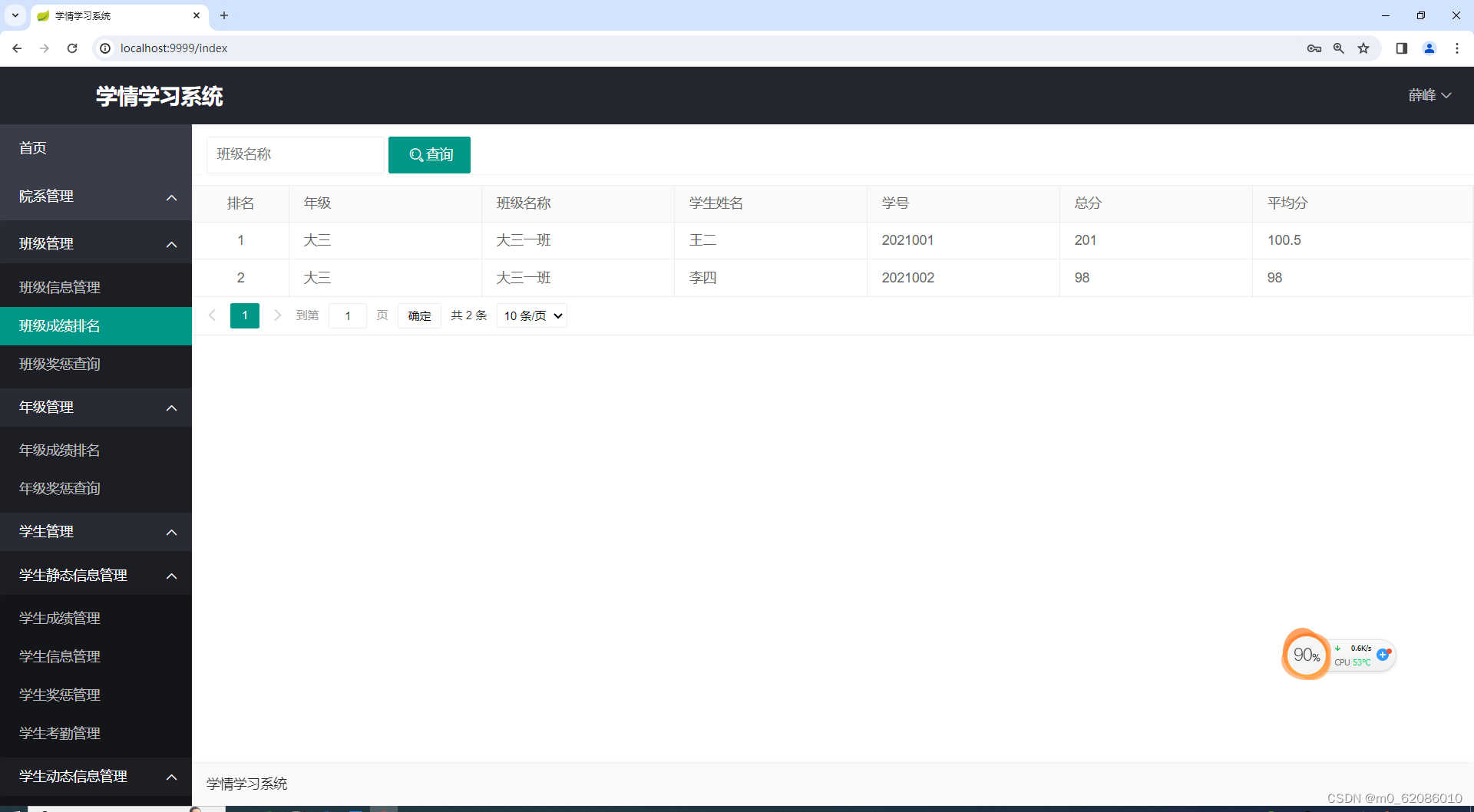
图5.5-1 班级成绩排名
班级奖惩查询,老师登录系统后可以在班级奖惩查询功能中查看各年级、各班级以及各个学生获奖和处罚情况。获奖或处罚结果使用table动态数据表格的形式来展示。
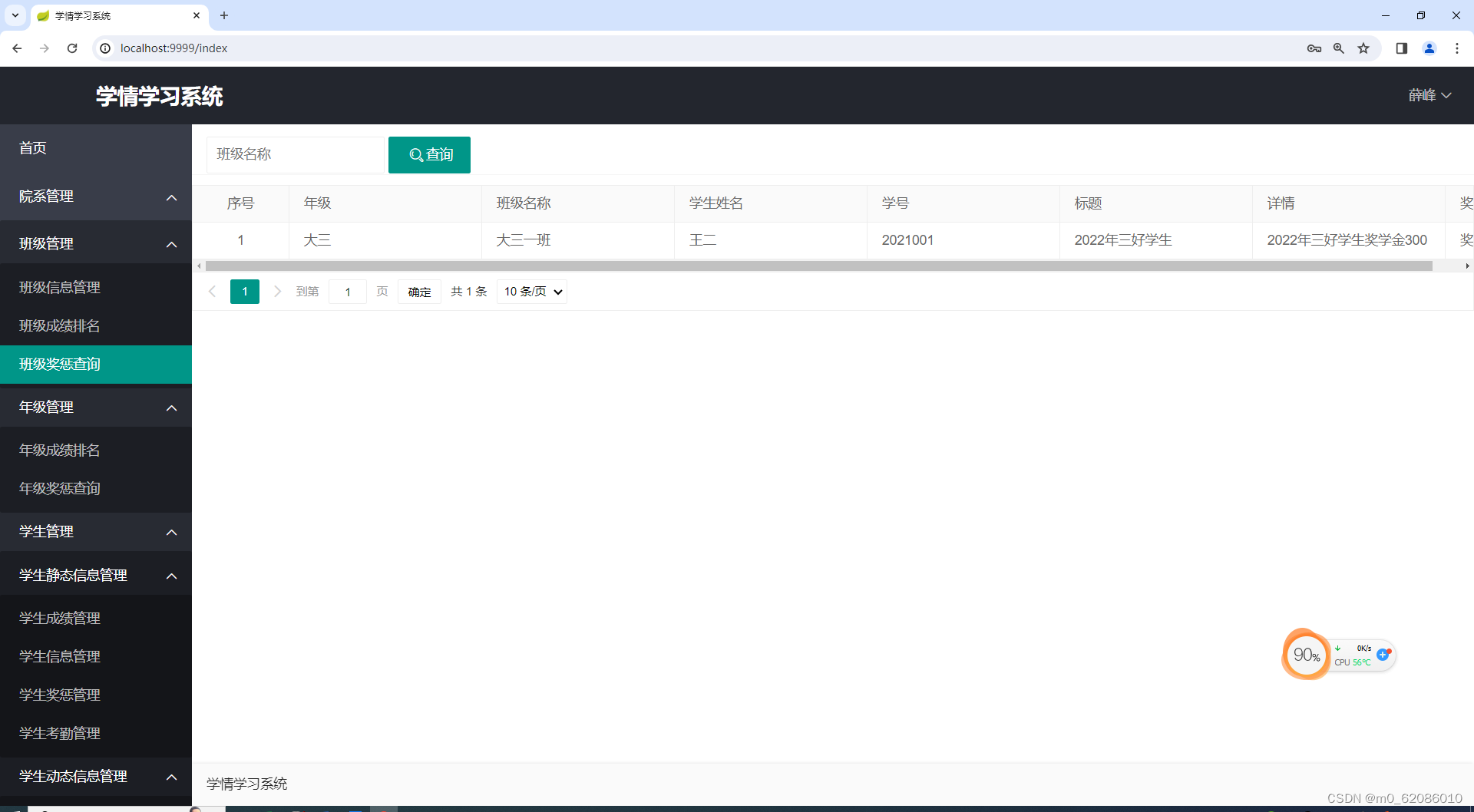
图5.5-2 班级奖罚查询图
年级成绩排名,老师登录系统后可以在年级成绩排版中查看每个年级中每个班级的成绩排名情况,排名按照班级的平均分进行排序。排名结果使用table动态数据表格来展示各个年级中每个班级的排名情况。
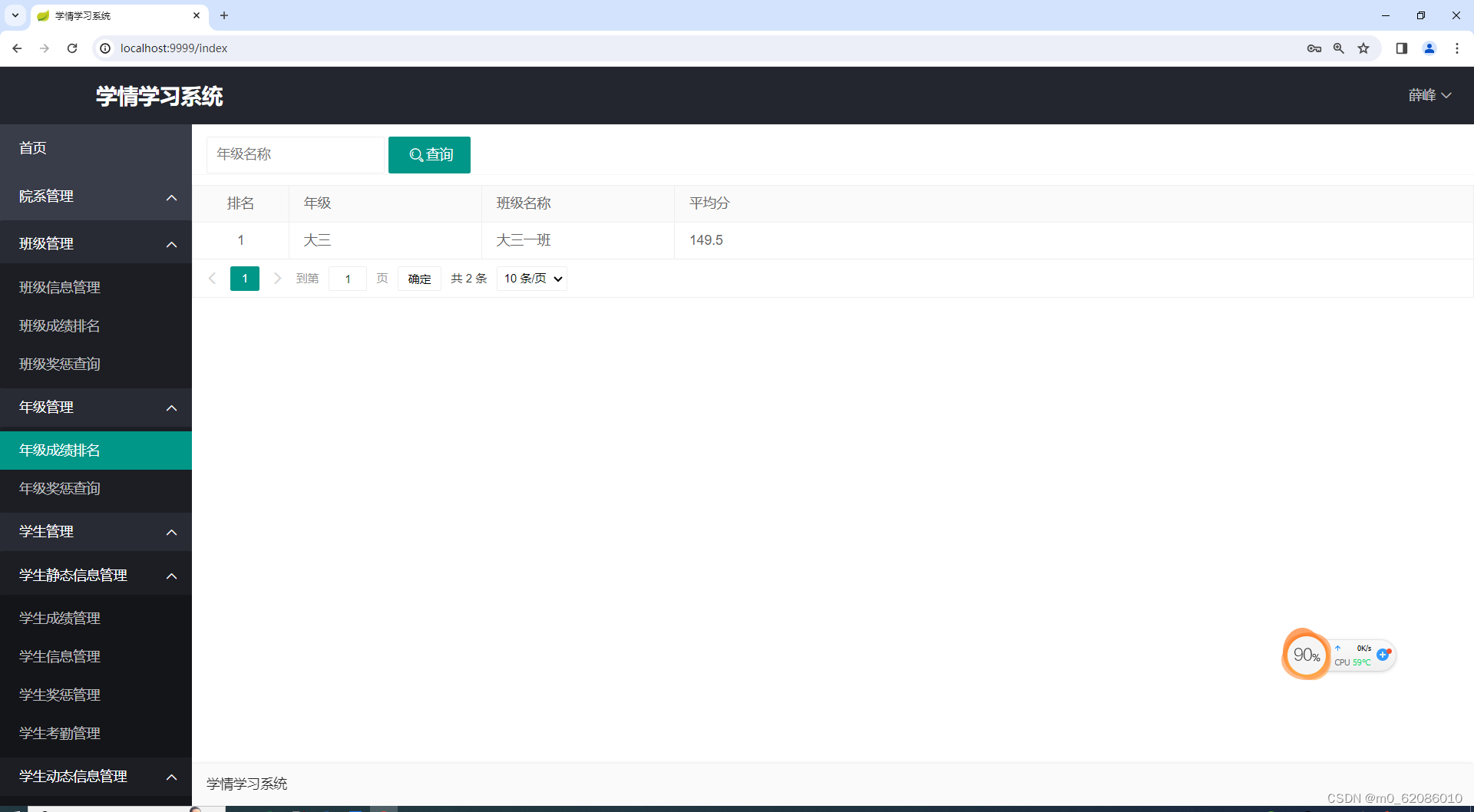
图5.5-3 年级成绩排名图
学生行为轨迹可视化,老师登录系统后在学生行为轨迹功能中可以根据学生学号查看学生各个时间段所在地。
学生借阅信息可视化,老师登录系统后在学生借阅查询功能中可以根据学生学号来查询学生在学校图书馆借阅图书的信息,以及图书是否归还等。
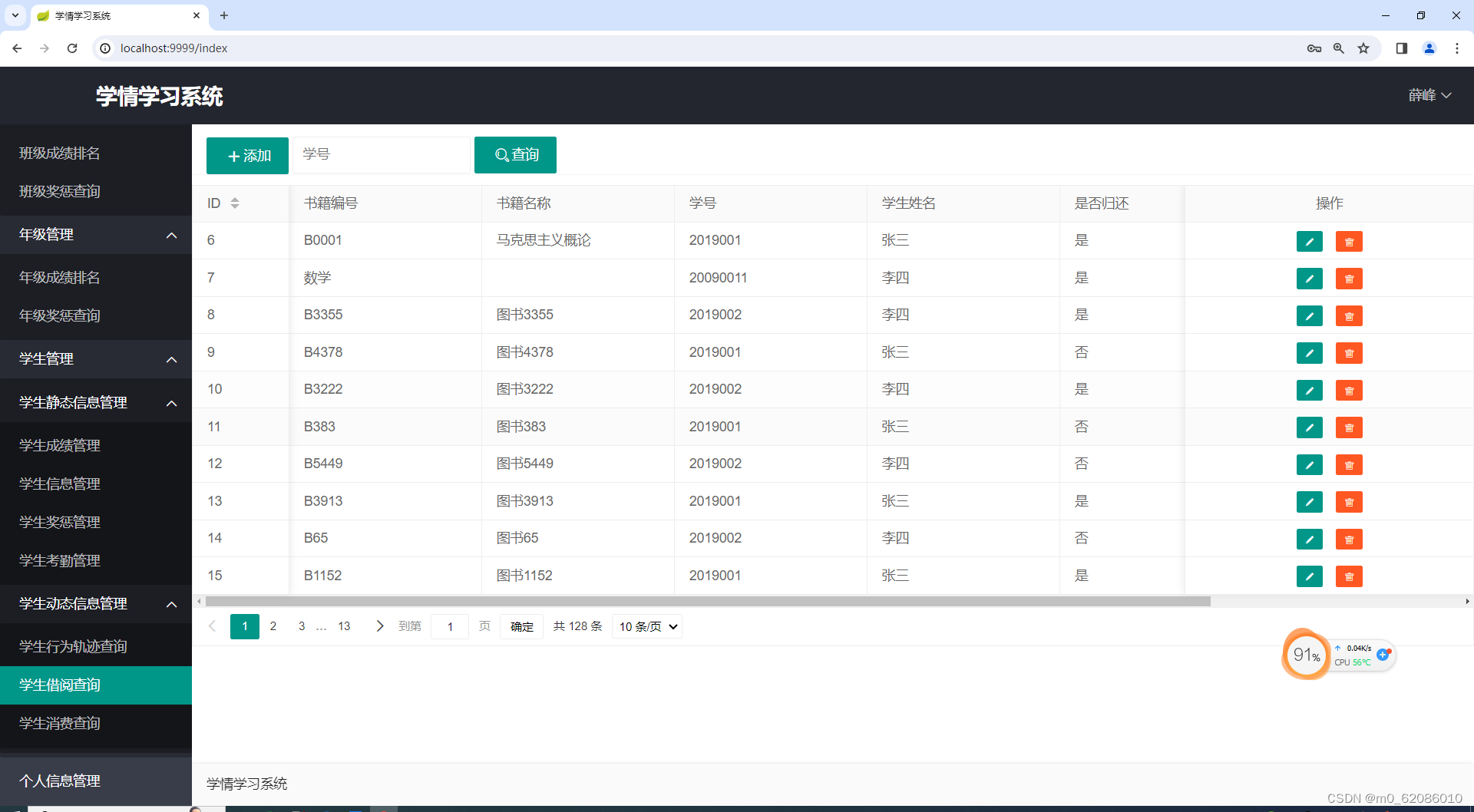
图5.5-4 学生借阅查询图
学生消费信息可视化,老师登录系统后在学生消费查询功能中可以根据学生学号来查询学生在学校内的消费金额以及消费地点。
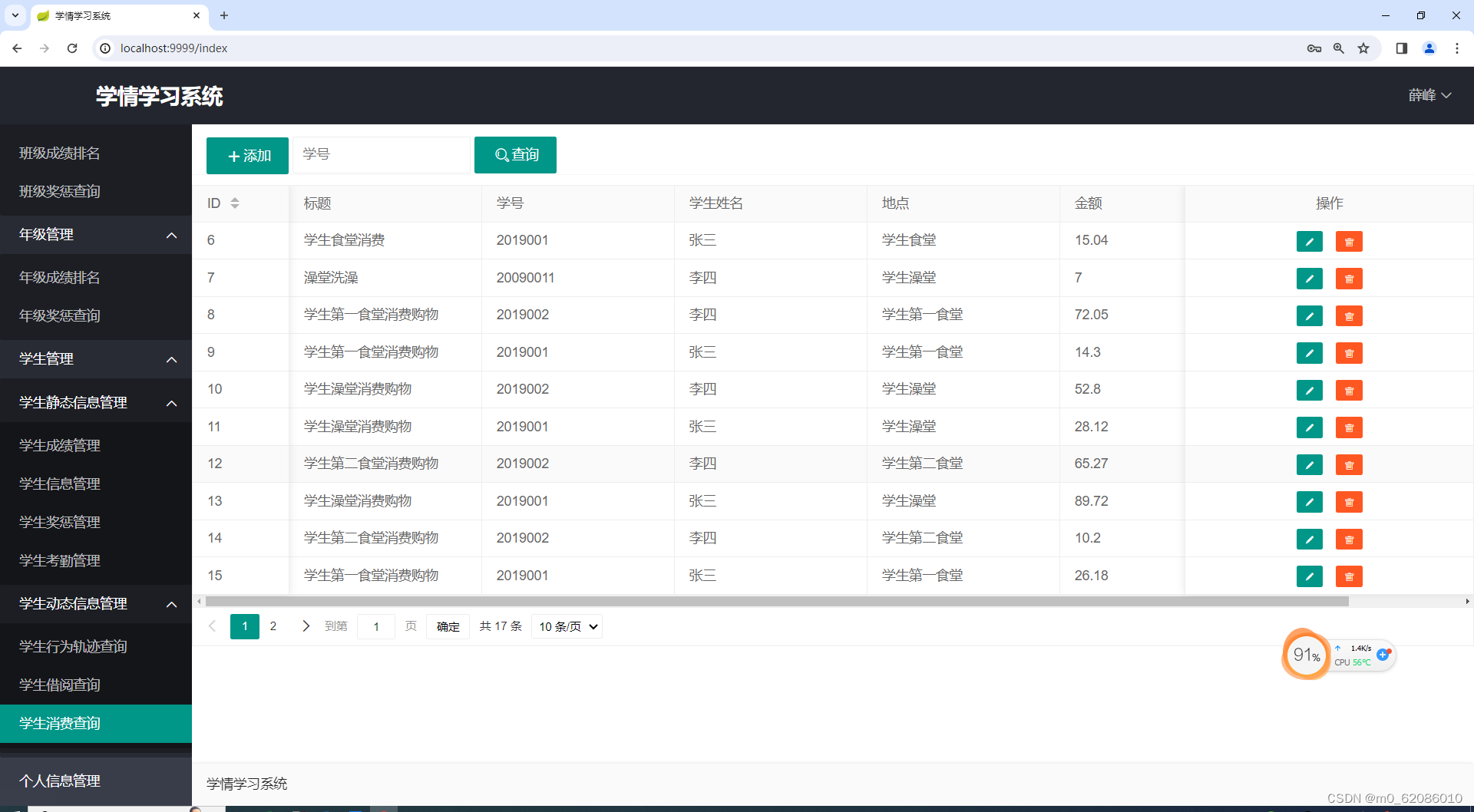
图5.5-5 学生消费查询图
其他数据可视化,包含班级数据管理,学生成绩管理,学生信息管理,学生奖罚管理,学生考勤管理。
图5.5-6 班级信息管理图
图5.5-7 学生奖罚管理理图
第6章:系统测试
6.1测试意义
平台测试主要是通过设定一些条件,用会提前输入数据,然后平台会出现相对应的效果和数据。本平台的测试主要是对基于Spark的学情日志数据分析可视化系统功能和性能进行测试,平台测试目的是对已经设置开发出的基于Spark的学情日志数据分析可视化系统的功能是否能够正常运行,所以平台开发中平台的测试是非常重要的一步,需要在平台测试时进行严格的操作,通过平台测试用可以减少后期维护成本,如果在平台开始之初没有进行平台测试,会在后期的开发和使用的过程中造成很大的问题,如果想要让开发的程序与预期达到一致,可以通过平台测试来减少问题。平台测试的方法主要包括白盒测试和黑盒测试。
6.2测试用例设计
测试用例
| 测试内容 | 输入 | 预期输出 | 实际输出 | 测试结果 |
| 用户登录 | 管理员账号或者教师工号或者学号和密码 | 账号登录成功,并根据角色展示不同的菜单 | 账号登录成功,并根据角色展示不同的菜单 | 通过 |
| 用户管理 | 管理员登录系统,点击左侧用户管理 | 页面跳转到用户管理页,管理员可进行用户删除操作 | 页面跳转到用户管理页,管理员可进行用户删除操作 | 通过 |
| 系统管理员管理 | 管理员登录系统,点击左侧系统管理员管理 | 页面跳转到系统管理员管理页,管理员可进行管理员查看、添加、修改、删除操作 | 页面跳转到系统管理员管理页,管理员可进行管理员查看、添加、修改、删除操作 | 通过 |
| 教师管理 | 管理员登录系统,点击左侧教师管理 | 页面跳转到教师管理页,管理员可进行教师查看、添加、修改、删除操作 | 页面跳转到教师管理页,管理员可进行教师查看、添加、修改、删除操作 | 通过 |
| 学院管理 | 管理员登录系统,点击左侧学院管理 | 页面跳转到学院管理页,管理员可进行学院查看、添加、修改、删除操作 | 页面跳转到学院管理页,管理员可进行学院查看、添加、修改、删除操作 | 通过 |
| 专业管理 | 管理员登录系统,点击左侧专业管理 | 页面跳转到专业管理页,管理员可进行专业查看、添加、修改、删除操作 | 页面跳转到专业管理页,管理员可进行专业查看、添加、修改、删除操作 | 通过 |
| 年级管理 | 管理员登录系统,点击左侧年级管理 | 页面跳转到年级管理页,管理员可进行年级查看、添加、修改、删除操作 | 页面跳转到年级管理页,管理员可进行年级查看、添加、修改、删除操作 | 通过 |
| 个人信息管理 | 管理员登录系统,点击左侧个人信息管理 | 页面跳转到个人信息管理页,可以进行修改密码,修改其他信息 | 页面跳转到个人信息管理页,可以进行修改密码,修改其他信息 | 通过 |
| 学生行为轨迹数据模拟分析 | 启动TraceSparkStreamingConsumer程序实时消费kafka的trace topic中的数据分析 | 学生行为轨迹数据成功消费,并且topic中的数据存储到mysql的trace数据表中。 | 学生行为轨迹数据成功消费,并且topic中的数据存储到mysql的trace数据表中。 | 通过 |
| 学生消费数据模拟分析 | 启动ConsumeSparkStreamingConsumer程序实时消费kafka的consume topic中的数据分析 | 学生消费数据成功消费,并且topic中的数据存储到mysql的consume数据表中。 | 学生消费数据成功消费,并且topic中的数据存储到mysql的consume数据表中。 | 通过 |
| 学生借阅数据模拟分析 | 启动BorrowSparkStreamingConsumer程序实时消费kafka的borrow topic中的数据分析 | 学生借阅数据成功消费,并且topic中的数据存储到mysql的borrow数据表中。 | 学生借阅数据成功消费,并且topic中的数据存储到mysql的borrow数据表中。 | 通过 |
6.3测试结论
经过细心反复测试,此次开发的基于Spark的学情日志数据分析可视化系统是一个性能全面,使用简单方便的平台,有助于用户能够得心应手的使用,也是一个可以被用户推广的平台,功能非常齐全,用户可以放心使用。通过测试让平台能够与数据库信息进行正常的交互,确保平台交互的数据完整性和成功率,运行更流畅,让性能平台通过测试保证平台的运行更顺利。
第7章:总结
xxxxxxxxx

