
- 1在多线程中如何保证集合的安全
- 2Git和TortoiseGit安装过程中遇到的问题_tortoise git 2.15.0.0 安装失败
- 3国企央企OFFER收割全攻略 | 银行篇之行业整体介绍_应届生银行求职全攻略
- 4快速排序算法详细图解
- 5q learning简单理解_如何用简单例子讲解 Q learning 的具体过程?
- 6【Go语言入门学习笔记】Part3.指针和运算符、以及基本输入
- 7安装 QuartusII 10.1 软件_quartus ii10.0下载
- 8苹果手机的ios系统ipa应用app文件怎么安装手机上_ipa文件如何在iphone手机上安装
- 9强烈推荐:2024 年12款 Visual Studio 亲测、好用、优秀的工具,AI插件等_vs2022好用的插件
- 10在Git存储库中查找并恢复已删除的文件_为什么推送到git远程仓库的文件会显示被delete了
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
赞
踩
相关博客
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】Chain of Thought:从大模型中引导出推理能力
【自然语言处理】【ChatGPT系列】InstructGPT:遵循人类反馈指令来训练语言模型
【自然语言处理】【ChatGPT系列】大模型的涌现能力
ChatGPT \text{ChatGPT} ChatGPT火了!作为开放域对话系统, ChatGPT \text{ChatGPT} ChatGPT展示出了出乎意料的智能。在人们惊讶 ChatGPT \text{ChatGPT} ChatGPT效果的同时,其"胡编乱造"的结果也让人担忧。
ChatGPT \text{ChatGPT} ChatGPT到底"只是"一个闲聊系统,还是意味着新的变革?如果只从使用者的角度分析,显然无法回答这个问题。不妨从"技术"的角度看看, ChatGPT \text{ChatGPT} ChatGPT到底是现有技术的极限还是新技术的起点?
一、 InstructGPT \text{InstructGPT} InstructGPT
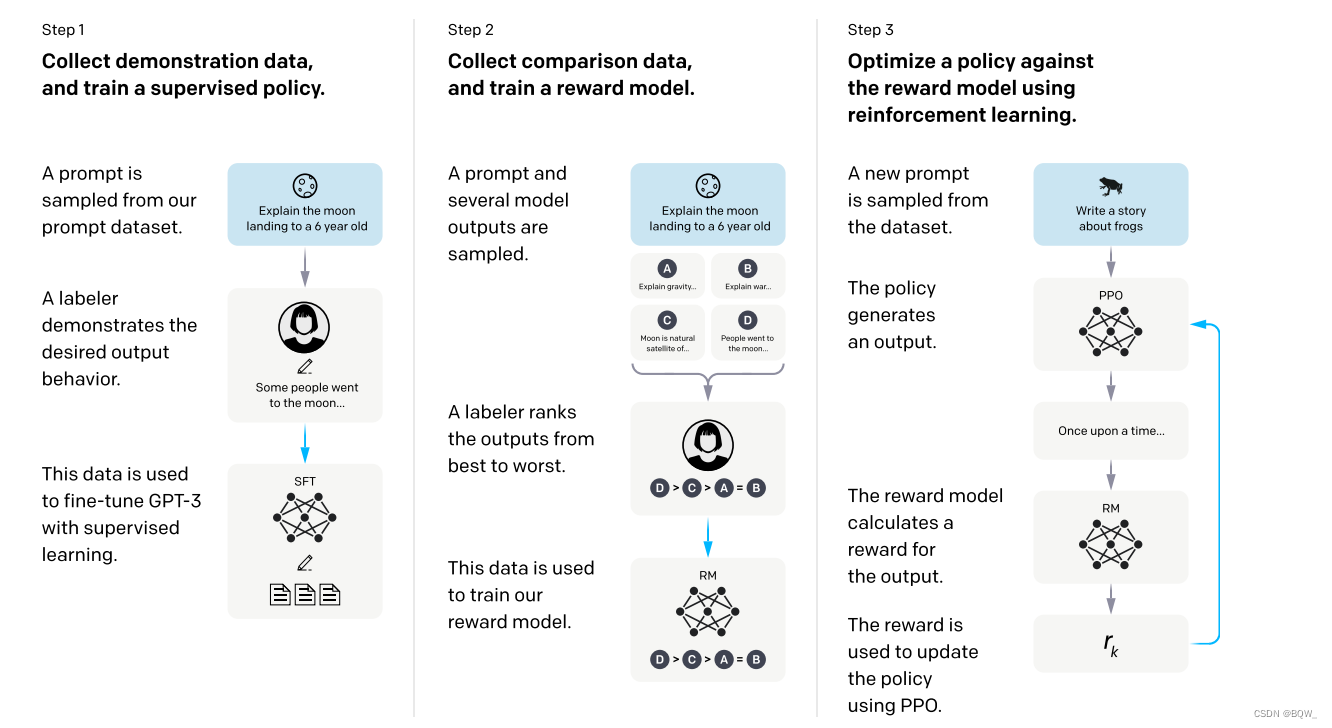
chatGPT \text{chatGPT} chatGPT是 OpenAI \text{OpenAI} OpenAI开发的开发域对话系统,目标还没有论文。但是根据官方的说法,其基本原理同 OpenAI \text{OpenAI} OpenAI今年早些时候的 InstructGPT \text{InstructGPT} InstructGPT。所以,这里先简单对 InstructGPT \text{InstructGPT} InstructGPT的原理进行简单的介绍。
1. 目的
训练大语言模型
(Large Language Model,LLM)
\text{(Large Language Model,LLM)}
(Large Language Model,LLM)通常是用上下文来预测部分token,而在使用
LLM
\text{LLM}
LLM时却希望其能够生成诚实的、无毒性的且对用户有帮助的内容。显然,语言模型并没有与用户的意图对齐。
InstructGPT
\text{InstructGPT}
InstructGPT的目标是通过人类的反馈微调语言模型,令语言模型与用户意图对齐。(通过基于人类反馈的强化学习,引导出大模型的能力)。
2. 方法
2.1 步骤1: prompt \text{prompt} prompt微调
该步骤中需要人工先标注一个
prompt
\text{prompt}
prompt数据集。简单来说,
prompt
\text{prompt}
prompt数据集中的单个样本是由一对文本组成,例如:
Prompt: 使用自然语言处理造一个句子。
Demonstration:自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。
使用
prompt
\text{prompt}
prompt数据集以监督学习的方式来微调
GPT-3
\text{GPT-3}
GPT-3。
2.2 步骤2:训练奖励模型 (Reward modeling,RM) \text{(Reward modeling,RM)} (Reward modeling,RM)
该步骤会先收集比较数据。如果了解
Learning to rank
\text{Learning to rank}
Learning to rank的话,比较数据就是一个排序的数据。具体来说,标注员需要模型针对同一输入的不同输出进行排序。举例来说,
Prompt: 使用自然语言处理造一个句子。
Demonstration1:自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。
Demonstration2:自然语言处理是一个名词。
在上面的例子中,模型生成了
Demonstration1
\text{Demonstration1}
Demonstration1和
Demonstration2
\text{Demonstration2}
Demonstration2。显然,标注人员需要标注
Demonstration1
\text{Demonstration1}
Demonstration1相较于
Demonstration2
\text{Demonstration2}
Demonstration2更好。
奖励模型将
prompt
\text{prompt}
prompt和模型生成的结果作为输入,然后输出一个标量的奖励值。具体来说,对于单个输入会将模型的
K
K
K个输出交给标注者进行排序 。这
K
K
K个答案共有
(
k
2
)
loss
(
θ
)
=
−
1
(
k
2
)
E
(
x
,
y
w
,
y
l
)
∼
D
[
log
(
σ
(
r
θ
(
x
,
y
w
)
−
r
θ
(
x
,
y
l
)
)
)
]
\text{loss}(\theta)=-\frac{1}{
其中
r
θ
(
x
,
y
)
r_\theta(x,y)
rθ(x,y)表示对于
prompt x
\text{prompt x}
prompt x和模型生成结果
y
y
y作为输入,奖励模型输出的奖励值;
y
w
,
y
l
y_w,y_l
yw,yl是模型生成的输出,标注者认为
y
w
y_w
yw比
y
l
y_l
yl更受欢迎;
D
D
D是整个比较数据集。
2.3 步骤3:强化学习
前两个步骤分别会得到微调好的 GPT-3 \text{GPT-3} GPT-3和一个奖励模型。但是,如何将这两个模型和人类组合到一个动态的环境中,然后逐步利用人类的反馈来优化这个循环?这里使用了强化学习方法 PPO \text{PPO} PPO。
3. 分析
总的来说, InstructGPT \text{InstructGPT} InstructGPT可以总结为三部分:1. 微调的预训练语言模型;2. 结果排序模型; 3. 强化学习将人和模型统一至动态的环境。预训练语言模型的微调是 NLP \text{NLP} NLP中常见的技术,结果排序模型在推荐、搜索、问答等场景中也很常见。基于人类反馈的强化学习虽然不常见,但根本是将人加入到强化学习环境中。
基于人类反馈的强化学习,构建了一个动态反馈的系统,能够使 InstructGPT(chatGPT) \text{InstructGPT(chatGPT)} InstructGPT(chatGPT)随着人类的反馈逐步改善。但是使用过 chatGPT \text{chatGPT} chatGPT都知道,其表现出的智能远远不是上面三部分能够体现出来的。
chatGPT \text{chatGPT} chatGPT所表现出的智能到底来自哪里?答案是大模型的涌现能力。
二、大模型的涌现能力
自然语言处理从业者都使用过 BERT \text{BERT} BERT这样的预训练语言模型,虽然其能为广泛的下游任务带来效果的提升,但是使用这样的模型不太能够构建出 chatGPT \text{chatGPT} chatGPT那样的智能对话系统(包括对话、代码、逻辑推理能力)。那么完全没使用更加新的技术,只是在模型规模和使用数据量上高多个数量级的 GPT-3 \text{GPT-3} GPT-3就能实现吗?答案是肯定的。
来自Google的文章
《Emergent Abilities of Large Language Models》
《\text{Emergent Abilities of Large Language Models}》
《Emergent Abilities of Large Language Models》系统的说明了这一点。该文章的核心简单来说就是,
量变带来质变,大模型与小模型不是一个物种。
\text{量变带来质变,大模型与小模型不是一个物种。}
量变带来质变,大模型与小模型不是一个物种。
该文章通过实验说明了大模型中的一种"涌现"的现象。
1. few-shot \text{few-shot} few-shot能力的涌现
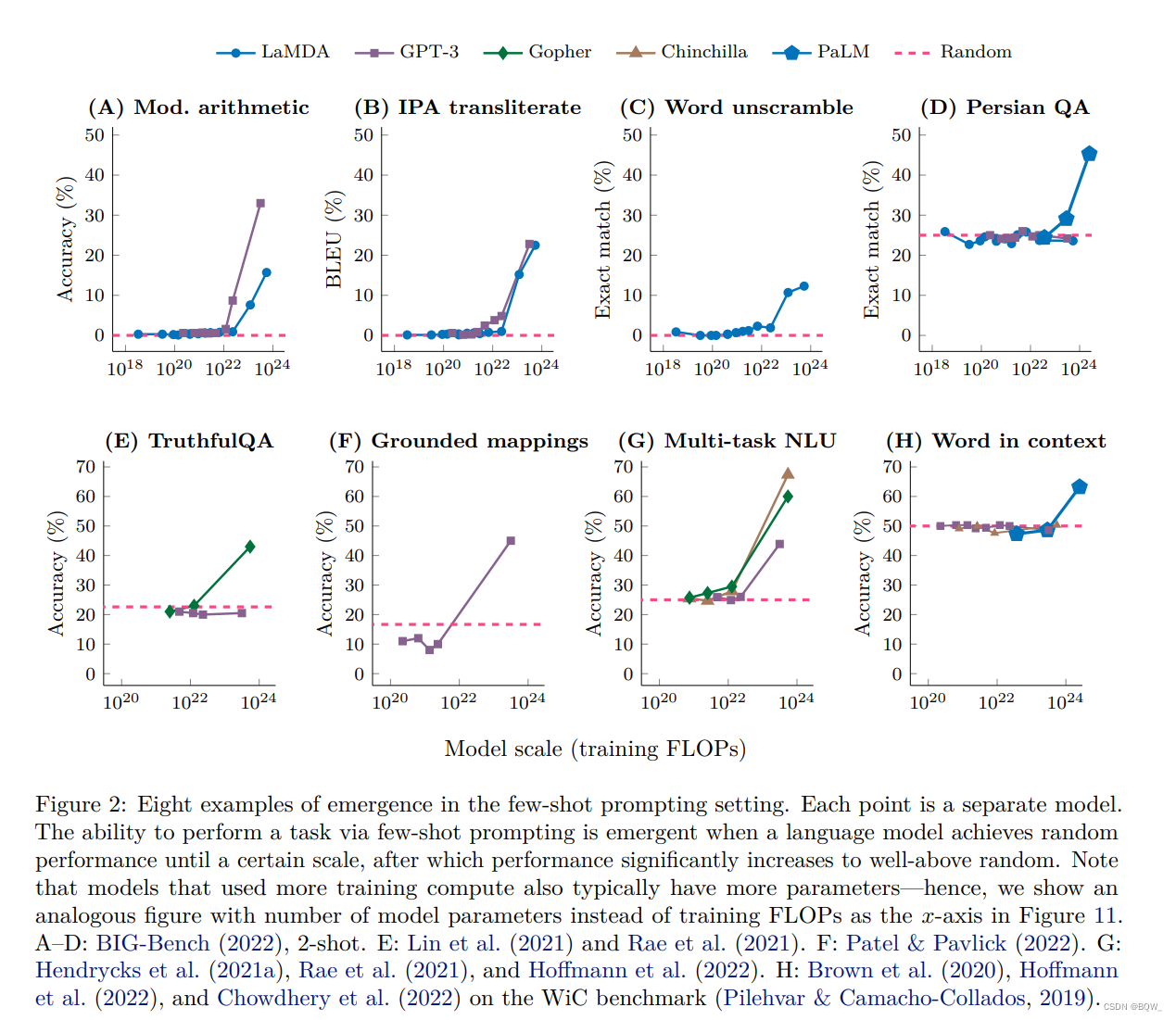
简单来说,上面8个图的横坐标是模型的规模(参数量或者训练量),纵坐标是各类任务上的效果。观察这8个任务,都具有同一种模式:模型规模在小于某个阈值之前,效果基本等于随机;当超过该阈值后,模型效果有一个飞跃。
上图(A)表示一个3位数加减法和2位数乘法的任务,模型 GPT-3 \text{GPT-3} GPT-3在达到 13B \text{13B} 13B参数量时突然具有了算术的能力。
上图(E)是一个衡量模型诚实回答问题的基准 TruthfulQA \text{TruthfulQA} TruthfulQA,模型 Gopher \text{Gopher} Gopher在达到 280B \text{280B} 280B时突然有了高于随机的效果。
2. 技术的涌现
若一项 prompt \text{prompt} prompt技术在小模型上没有效果,但是在模型达到某个规模后突然有效,则该技术是一种涌现能力。
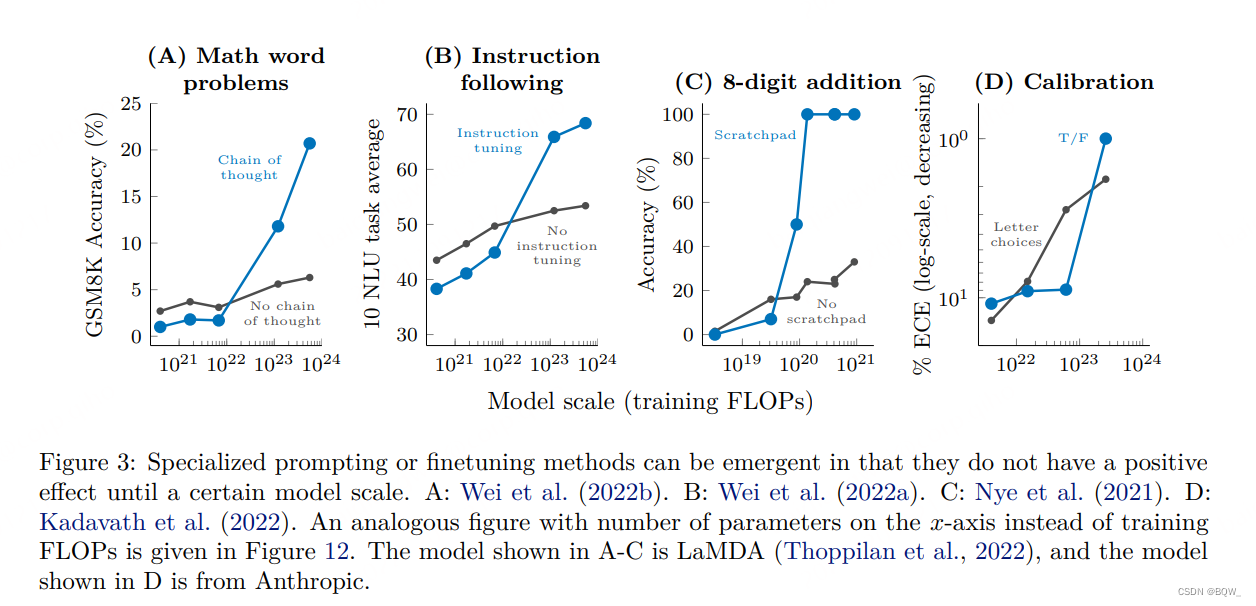
上图是4种技术的涌现。以上图(A)为例,其是一个数学应用题的基准,需要模型 chain of thought \text{chain of thought} chain of thought实现多步推理能力才能在该基准上实现好的效果。可以看到,当模型达到 ∼ 100B \sim\text{100B} ∼100B时, chain of thought \text{chain of thought} chain of thought技术突然开始有效,并能够在数学应用题上实现好的效果。
3. 智能的来源:模型规模
显然 chatGPT \text{chatGPT} chatGPT智能的来源是大模型的涌现能力。不妨畅想一下:
- 目前 chatGPT \text{chatGPT} chatGPT的缺点也许会随着模型在参数量、训练数据量的进一步扩大下得以解决;
- 随着预训练技术和模型结构的改进,也许在更小的模型上能够实现相同的效果;
- 范式"大数据+大模型+无监督预训练=涌现能力"不只是能够运用到语言上,在其他领域也许能够带来意想不到的效果;
三、引导大模型智能的技术
OpenAI \text{OpenAI} OpenAI在2020年就已经发布了 GPT-3 \text{GPT-3} GPT-3,而 ChatGPT \text{ChatGPT} ChatGPT则是在2022年底才发布。**既然研究表明大模型具有各种涌现的能力,那么为何两者发布时间相差2年多?答案是引导大模型智能的技术。**这里简单介绍一下赋予大模型推理能力的 chain of thought \text{chain of thought} chain of thought技术,以及为大模型带来 zero-shot \text{zero-shot} zero-shot能力的 instruction tuning \text{instruction tuning} instruction tuning技术。通过理解这两项技术,能够更好的理解 ChatGPT \text{ChatGPT} ChatGPT的智能来源于大模型。
1. 引导推理能力: chain of thought \text{chain of thought} chain of thought
这里介绍一种赋予大模型多步推理的技术
chain of thought
\text{chain of thought}
chain of thought,该技术很好的展示了大模型的神奇之处。这里用一句话总结该技术,
通过例子告诉模型做应用题要写步骤,而不是直接给答案。
\text{通过例子告诉模型做应用题要写步骤,而不是直接给答案。}
通过例子告诉模型做应用题要写步骤,而不是直接给答案。
详细细节见《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》。
单纯增加语言模型的规模并不能使其在算术、常识推理和符号推理表现的更好。
下面是一个标准的
prompt
\text{prompt}
prompt:
prompt: Jane有12朵花,2朵给妈妈,3朵给爸爸,那么她还有多少朵?
answer: Jane还有7朵花
通过上面的
prompt
\text{prompt}
prompt进行
few-shot learning
\text{few-shot learning}
few-shot learning,模型在数学应用题上的表现很差。
下面是一个
chain of thought
\text{chain of thought}
chain of thought:
prompt: Jane有12朵花,2朵给妈妈,3朵给爸爸,那么她还有多少朵?
answer: Jane将2朵花送给她妈妈后还剩10朵...然后再送给她爸爸3朵后还有7朵...所以答案是7
通过
chain of thought prompt
\text{chain of thought prompt}
chain of thought prompt进行
few-shot learning
\text{few-shot learning}
few-shot learning后,模型的效果显著提高。
直观的来说,让模型别瞎猜答案,把步骤写上再写答案。
2. 引导 zero-shot \text{zero-shot} zero-shot能力: instruction tuning \text{instruction tuning} instruction tuning
文章 《Finetuned Language Models are Zero-shot Learners》 \text{《Finetuned Language Models are Zero-shot Learners》} 《Finetuned Language Models are Zero-shot Learners》中介绍了一种微调大模型的方法: instruction tuning \text{instruction tuning} instruction tuning。在介绍 instruction tuning \text{instruction tuning} instruction tuning之前,先了看看自然语言推理任务 (Natural language inference,NLI) \text{(Natural language inference,NLI)} (Natural language inference,NLI)的通常做法。
自然语言推理任务是判断两个句子在语义是否为蕴含
(Entailment)
\text{(Entailment)}
(Entailment)、矛盾
(Contradiction)
\text{(Contradiction)}
(Contradiction)或者中立
(Neutral)
\text{(Neutral)}
(Neutral)三种关系的一种。例如:
Premise: 多名男子正在踢足球。
Hypothesis:一些男子正在做运动。
显然,
Premise
\text{Premise}
Premise蕴含
Hypothesis
\text{Hypothesis}
Hypothesis。一种常见的做法是将该任务转换为"句子对分类任务",分类的标签就是三种关系。下面是一个示例图:
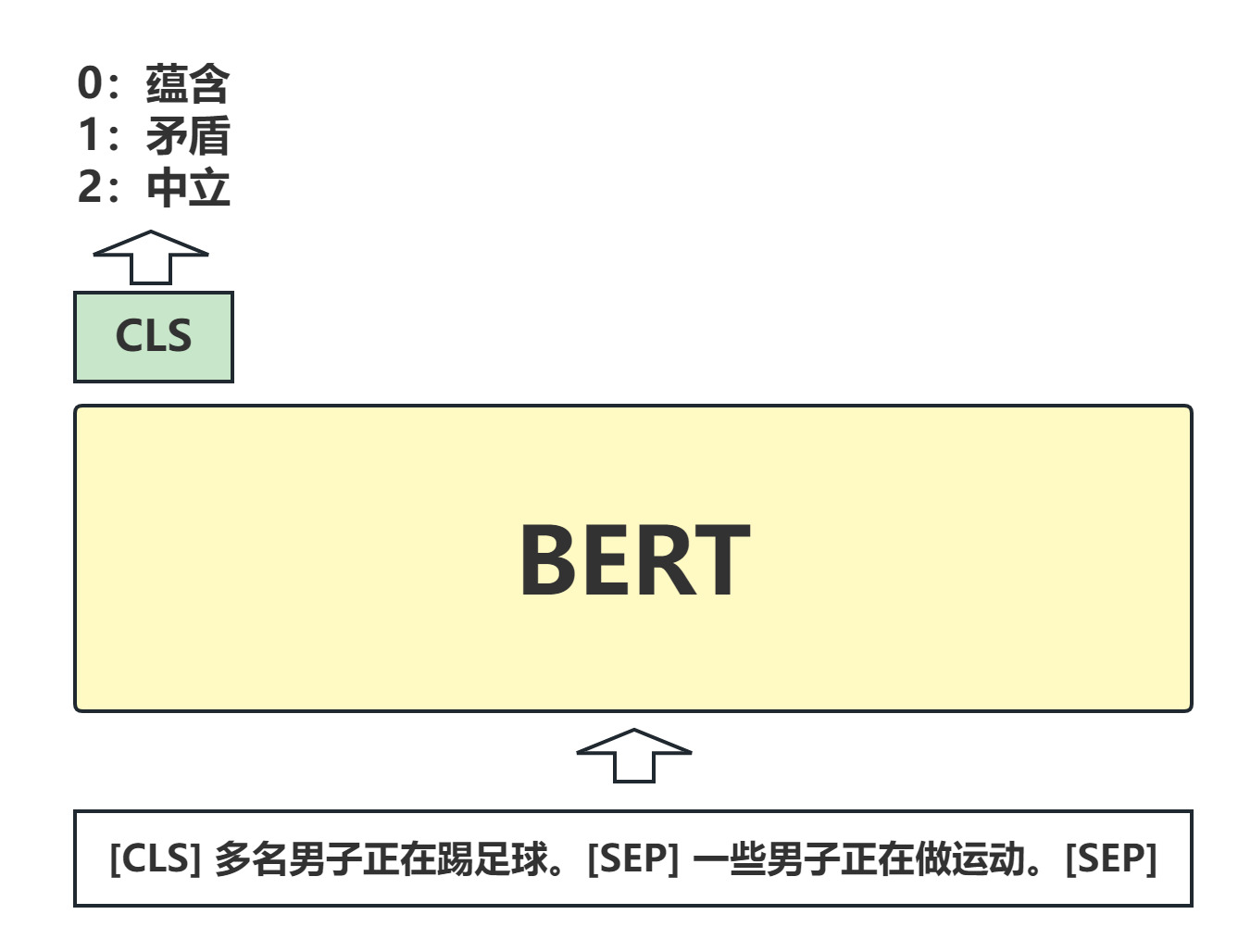
将两个句子拼接起来送入语言模型,然后对该句子对进行三分类。
下面来看自然语言推理任务上使用
instruction tuning
\text{instruction tuning}
instruction tuning的方式。将
Premise
\text{Premise}
Premise和
Hypothesis
\text{Hypothesis}
Hypothesis按某个自然语言的模板进行组装,并得到样本
多名男子正在踢足球。
基于上面的段落,是否可以得出结论:
一些男子正在做运动。
选项:是、否
将上面这段文本送入大模型,并使用监督的方式进行微调。这就是所谓的
instruction tuning
\text{instruction tuning}
instruction tuning。
具体来说,论文中将12类任务的62个数据集按照上面的方式转换,然后微调大模型。最终的实验结果是:通过上面的 instruction tuning \text{instruction tuning} instruction tuning的大模型,能够在完全未见过类型的任务上取得好的效果。
通过 instruction tuning \text{instruction tuning} instruction tuning的介绍可以更好的理解为什么 ChatGPT \text{ChatGPT} ChatGPT能够完成各种各样的任务。
四、漫谈
以下仅是个人的看法。
1. 对现有 NLP \text{NLP} NLP的影响
现有 NLP \text{NLP} NLP技术的主要困境仍然是标注成本,这个成本可以从两个方面来看:人力成本和时间成本。对于特定的场景,通常需要几千甚至上万的数据才能达到很好的效果。当然,如果能够明确的知道标注多少样本就能够达到预期的效果,通常项目也可以经过人力成本评估后确定是否继续。但是,真正影响 NLP \text{NLP} NLP技术落地的是时间成本,即经过一段时间的标注后可能效果无法达到预期,那么项目可能面临推迟或者终止的风险。
大模型将会改变这一现状。大模型具有 few-shot \text{few-shot} few-shot能力,并且能够通过 instruction tuning \text{instruction tuning} instruction tuning获得 zero-shot \text{zero-shot} zero-shot的能力。因此,大模型可以仅使用少量的样本就能够在指定任务上达到非常好的效果,也将极大的降低人力成本和时间成本。但是,大模型的推理速度和推理成本是阻碍其广泛应用的主要问题,并且近期可能都无法将其小型化至合理的范围。所以,大模型很可能作为一个"超级教师模型"。经过少量标注样本微调后,大模型可以自动产生高质量的标注样本,然后使用这些样本来微调小模型。
一种可能的发展路径是:(1) 少量样本微调大模型;(2) 大模型产生大量标注数据;(3) 通过标注数据将大模型的知识蒸馏至小模型。通过这条路径,将会为 NLP \text{NLP} NLP技术在各类项目和产品中的落地提供极大的支持。
2. 下一步的方向
柏拉图在《理想国》中提到了"洞穴寓言",大意是:
有一群囚徒被困在地下洞穴里,他们手、脚和脖子都被拷住,无法动弹,只能看到面前的墙壁。这些人的背后有一堆火,外界的所有事物都是通过墙壁上的阴影展示给这些囚徒。那么这些囚徒只能通过阴影来观察和想想真实的世界。
自然语言也是真实世界的"阴影",或者说自然语言是高维真实世界的低维表示。显然,通过自然语言这些低维信息来学习高维真实世界是存在信息丢失的。举例来说,语言描述苹果可能是"红的"、“圆的”,而真实的苹果并不是严格的“圆”且颜色也不是严格的"红",而是有着自己的纹理。所以,通过将视觉、声音等多个模态结合可能会带来更加智能的模型。
另一方面,现有模型更多的是"被动的"接收信息并作出应答,而且无法通过与周围进行交互来获得更多的知识,从而提高本身的"智能"。 OpenAI \text{OpenAI} OpenAI提出的 WebGPT \text{WebGPT} WebGPT、 InstructGPT \text{InstructGPT} InstructGPT和 ChatGPT \text{ChatGPT} ChatGPT都是尝试让模型与环境进行交互,从而提高模型的"智能"。相信随着多模态大模型的发展,模型与环境的交互方式也会越来越多样(例如:通过视觉传感器进行交互),展示出来的"智能"也会越来越强大。
3. 超越语言模型
ChatGPT \text{ChatGPT} ChatGPT的“智能”主要来源于范式:“大数据+大模型+无监督预训练=涌现能力”。但这个范式并不是必须局限于语言,在任何存在大量数据的领域,通过设计合适的无监督预训练方式都可能会带来质的改变。因此,大模型的技术在不久的将来可能会对 AI for Science \text{AI for Science} AI for Science、自动驾驶等领域带来巨大的改变。
4. 局限性
ChatGPT \text{ChatGPT} ChatGPT一个最为人诟病的缺点是:你无法确信它给的答案是正确的。也就是说, ChatGPT \text{ChatGPT} ChatGPT可能是胡编乱造的。但是, OpenAI \text{OpenAI} OpenAI的另一个工作 WebGPT \text{WebGPT} WebGPT则是尝试让模型自己浏览网页,并将浏览的结果合成最终的答案。显然, WebGPT \text{WebGPT} WebGPT生成的答案是有依据的,那么真实性也就更高。论文《Large Language Models Can Self-Improve》中证明了大模型不需要标注样本就可以通过自己生成的样本完成性能的提升。
那么一个可能改善 ChatGPT \text{ChatGPT} ChatGPT的方法是:使用 WebGPT \text{WebGPT} WebGPT作为真实性的评估模型或者指导模型,通过 WebGPT \text{WebGPT} WebGPT与 ChatGPT \text{ChatGPT} ChatGPT之间的交互来改善 ChatGPT \text{ChatGPT} ChatGPT的真实性问题。也就是,两个模型通过相互博弈来不断改进。

