
- 1Android中的anr定位指导与建议_android anr如何定位
- 2不来看看?通过Python实现贪吃蛇小游戏_python贪吃蛇研究背景
- 3Android问题笔记十三:实战解决Studio出现Direct local .aar file dependencies are not supported when building an AAR
- 4CentOS7.4中Docker以rw方式挂载volume报Permission denied的解决思路_centos7 root用户 报错:permission denied
- 5QT项目使用CMake_qt如何使用cmake
- 612 款做Java后台管理系统的项目,超级无敌好用!
- 7基于Transformers微调helsinki-NLP/opus-mt-en-ar模型进行阿拉伯语机器翻译
- 82023年06月CCF-GESP编程能力等级认证Python编程一级真题解析
- 9hive 数据仓库_hive insert into local
- 10深度学习论文: YOLOv10: Real-Time End-to-End Object Detection
Logistic回归(逻辑回归)实战案例分析_逻辑回归实验案例
赞
踩
Lgistic回归也叫逻辑回归,是广义线性回归的一种,通常用于解决二分类问题。
表达式如下:
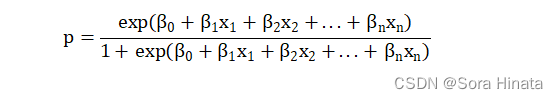
经过logit变换,则可以写成广义线性表达式
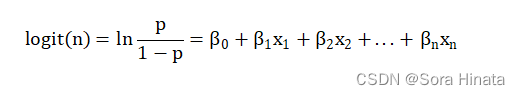
通常做回归是用其广义线性表达式,且logistic回归的结果概率表现为S型曲线,一般以小于0.5的样本都分类为0,大于0.5的样本都分类为1。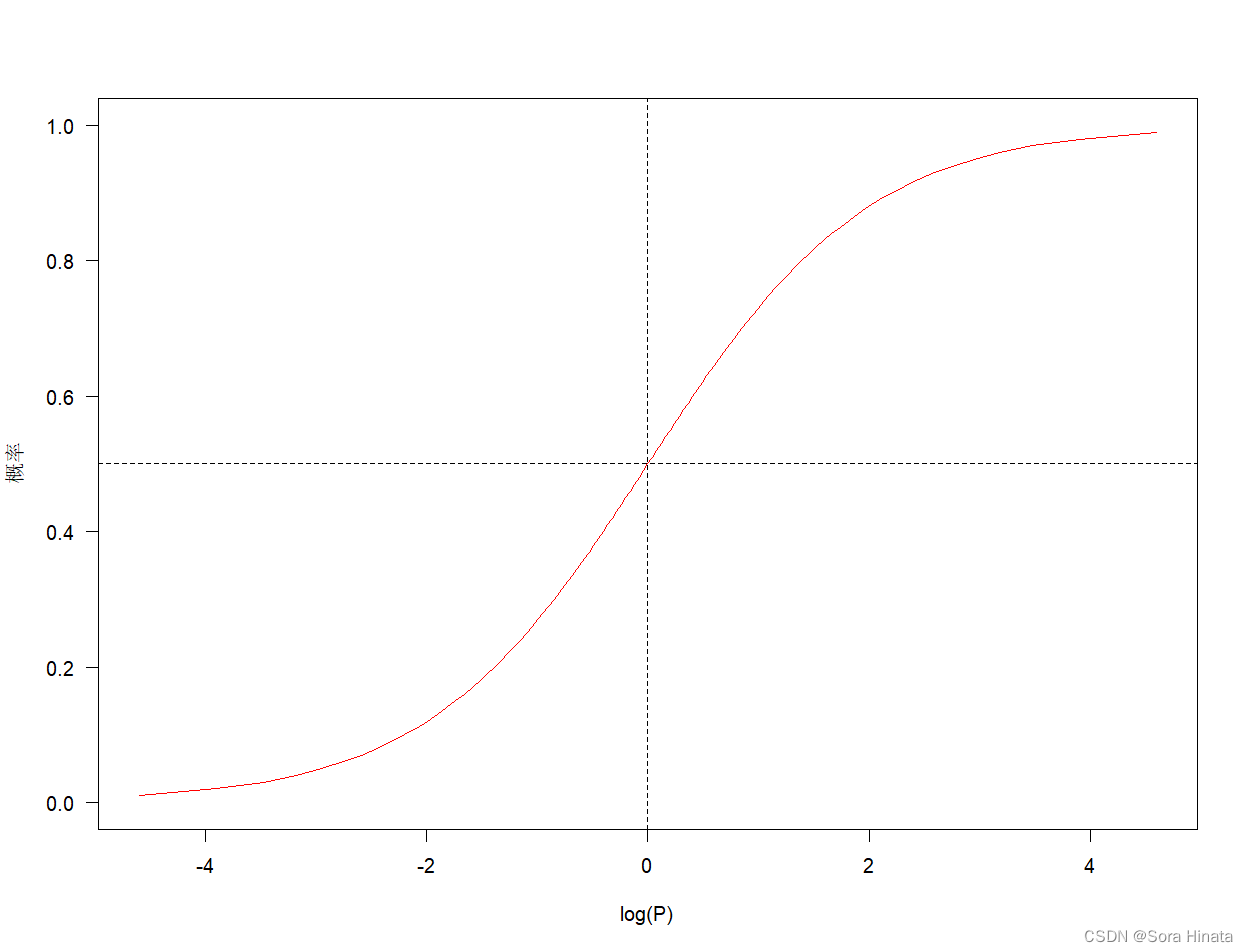
logistic回归是简单的二分类算法之一,但是其应用非常广,支持向量机(SVM)中也有其相关运用。
案例1:根据发出的声音判断性别
voice.csv数据集介绍:创建该数据库是为了根据声音和语音的声学特性将声音识别为男性或女性。该数据集由3168个记录的语音样本组成,这些样本来自男性和女性说话者。使用seewave和tuneR软件包,通过R中的声学分析对语音样本进行预处理,分析的频率范围为0hz-280hz(人声范围)。(详细介绍看代码注释)
- ######## Logitic回归(逻辑回归) ########
- ## logistic回归经常广泛应用于二分类问题,其本质上属于线性回归的一种。
-
- #### 案例1:根据发出的声音判断性别####
- ## voice.csv数据集介绍:创建该数据库是为了根据声音和语音的声学特性将声音识别为男性或女性。该数据集
- ## 由3168个记录的语音样本组成,这些样本来自男性和女性说话者。使用seewave和tuneR软件包,通
- ## 过R中的声学分析对语音样本进行预处理,分析的频率范围为0hz-280hz(人声范围)。
- ## meanfreq:平均频率(kHz)
- ## sd:频率的标准偏差
- ## median:中位数频率(kHz)
- ## Q25:第一个分位数(kHz)
- ## Q75:第三个分位数(kHz)
- ## IQR: 分位数间范围(kHz)
- ## skew: 偏斜(请参见specprop描述中的注释)
- ## kurt: 峰度(请参阅specprop描述中的注释)
- ## sp.ent: 谱熵
- ## sfm: 光谱平坦度
- ## mode:模式频率
- ## centroid:频率质心(请参见specprop)
- ## peakf: 峰值频率(具有最高能量的频率)
- ## meanfun: 声学信号测量的基频的平均值
- ## minfun: 声学信号测量的最小基频
- ## maxfun: 声学信号测量的最大基频
- ## meandom: 声学信号测量的主频的平均值
- ## mindom: 声学信号测量的主频的最小值
- ## maxdom: 声学信号测量的主频的最大值
- ## dfrange:声学信号测量的主频范围
- ## modindx: 调制指数。计算为基频相邻测量值之间的累积绝对差除以频率r
- ## label:性别:男/女
- ##(PS:可能有翻译不准确的位置自己看原网站:https://www.kaggle.com/primaryobjects/voicegender/home)
- getwd()##寻找默认工作目录,将voice.csv文件放入该目录下。
- data_voice<-read.csv("voice.csv")
- summary(data_voice)
-
- library(caret)
- library(ROCR)
- library(tidyr)
- library(corrplot)
- ## 作热力图观察变量之间的关联性
- str(data_voice)##观察数据类型
- ## label为字符串性数据,无法做热力图进行分析。
- voice_cor <- cor(data_voice[,1:20])##选取前20个数据
- corrplot.mixed(voice_cor,tl.col="black",tl.pos = "d",number.cex = 0.8)
- ## 换一种热力图作法
- library(ggcorrplot)
- ggcorrplot(voice_cor,method = "square",lab = TRUE)+
- theme(axis.text.x = element_text(size = 10),
- axis.text.y = element_text(size = 10))
- ## 不难观察得到,大部分变量之间都存在明显的关联性。

- ## 作不同性别的概率密度图
- plotdata <- gather(data_voice,key="variable",value="value",c(-label))
- ggplot(plotdata,aes(fill = label))+ ##aes(fill = label)是设置不同性别作密度图
- theme_bw()+geom_density(aes(value),alpha = 0.5)+
- facet_wrap(~variable,scales = "free")
- ## 在这里,作密度图的意义在于分析不同性别下,自变量之间的差异。对于二分类问题,自变量差异越大,说明有分类的价值。
- ## 拿刚刚作的密度图进行说明,不同性别下,变量centroid之间的阴影面积和面积峰几乎重叠,可以初步说明meanfreq不是分类
- ## 性别的特征变量。相反,变量meanfun之间的阴影面积只有很小部分重叠,且面积峰明显错开,说明meanfun是分类性别的特征变量。
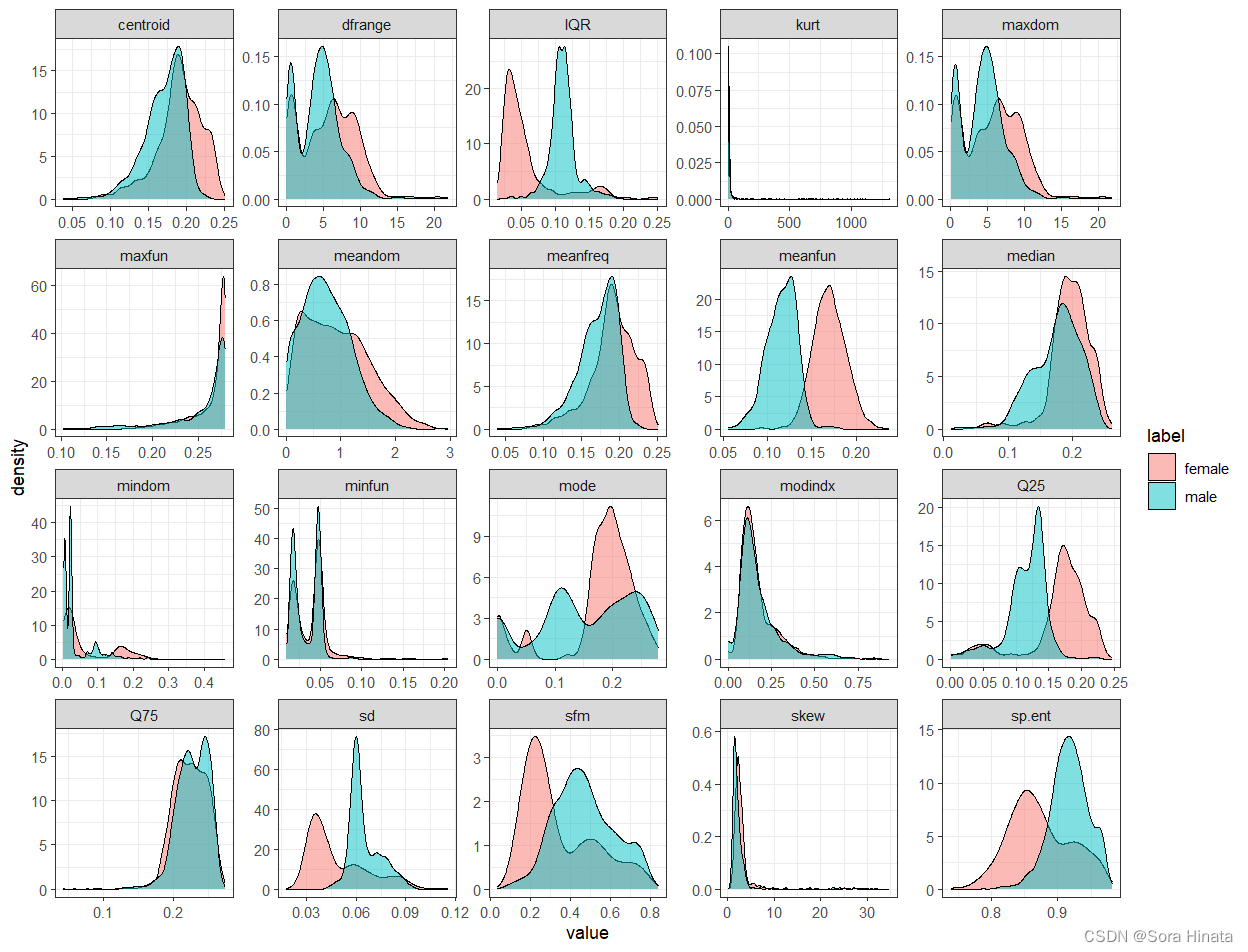
在这里,热力图判断自变量和因变量是否存在明显的关联性;作密度图的意义在于分析不同性别下,自变量之间的差异。对于二分类问题,自变量差异越大,说明有分类的价值。拿刚刚作的密度图进行说明,不同性别下,变量centroid之间的阴影面积和面积峰几乎重叠,可以初步说明meanfreq不是分类性别的特征变量。相反,变量meanfun之间的阴影面积只有很小部分重叠,且面积峰明显错开,说明meanfun是分类性别的特征变量。
一般在解决分类问题之前,我个人喜欢先作热力图和概率密度,来初步判断变量是否适合建立logistic回归模型。
- ## logistic回归模型的建立
- data_voice_1<-data_voice
- data_voice_1$label<-factor(data_voice_1$label,levels = c("male","female"),labels = c(0,1))
- ## 因为性别为字符串变量,对于回归来说,字符串变量无法进行回归,必须转换为数值或者因子型变量。
- ## 这里将男性设为0,女性设为1。
-
- ## 切分数据集,将70%作为训练集,30%作为测试集。
- set.seed(123)##设置随机树种子,保证抽样规则一致。
- index<-createDataPartition(data_voice_1$label,p=0.7)
- voice_train<-data_voice_1[index$Resample1,]
- voice_test<-data_voice_1[-index$Resample1,]
- ##将训练集用于建立模型
- voicelm<-glm(label~.,data = voice_train,family = "binomial")## family 设置回归类型,"binomial"为logistic回归。
- summary(voicelm)##查看模型效果
- ## 在变量当作,出现NA的情况,说明变量存在数据奇异性问题,需要剔除奇异值变量回归。
- ## 对此可以在logistic回归的基础上使用逐步回归来剔除异常值变量。
Call:
glm(formula = label ~ ., family = "binomial", data = voice_train)
Coefficients: (3 not defined because of singularities)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 8.556022 10.744209 0.796 0.425836
meanfreq 12.045555 51.514330 0.234 0.815118
sd -15.472537 37.677639 -0.411 0.681325
median 2.195323 14.469067 0.152 0.879404
Q25 47.471119 13.517168 3.512 0.000445 ***
Q75 -56.484041 22.053767 -2.561 0.010431 *
IQR NA NA NA NA
skew -0.026557 0.223570 -0.119 0.905445
kurt 0.003084 0.006654 0.463 0.643009
sp.ent -32.726213 11.688042 -2.800 0.005111 **
sfm 9.398132 2.797458 3.360 0.000781 ***
mode -2.580223 2.421720 -1.065 0.286672
centroid NA NA NA NA
meanfun 153.305351 9.025130 16.986 < 2e-16 ***
minfun -39.635374 10.188926 -3.890 0.000100 ***
maxfun 7.534931 7.810598 0.965 0.334692
meandom -0.536030 0.487689 -1.099 0.271715
mindom 1.298543 2.585901 0.502 0.615553
maxdom 0.024416 0.074818 0.326 0.744163
dfrange NA NA NA NA
modindx 2.137605 1.837304 1.163 0.244648
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 3074.8 on 2217 degrees of freedom
Residual deviance: 453.2 on 2200 degrees of freedom
AIC: 489.2
Number of Fisher Scoring iterations: 8
直接建立logistic回归模型的结果见上,变量中回归系数出现NA的情况,说明数据存在数据奇异性问题,变量之间存在多重共线性,这里使用逐步回归来对模型进行优化。
- ## 对逻辑回归模型进行逐步回归,来筛选变量
- voicelmstep <- step(voicelm,direction = "both")
- summary(voicelmstep)
- ## 相比逐步回归前AIC=489.2,逐步回归后模型的AIC=474.79,有着略微的下降,但是建立模型选取的变量由20个减小到8个,
- ## 模型的稳定性有着大幅度提高。
Call:
glm(formula = label ~ Q25 + Q75 + kurt + sp.ent + sfm + meanfun +
minfun, family = "binomial", data = voice_train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 8.356798 7.671468 1.089 0.27601
Q25 54.099322 5.359296 10.094 < 2e-16 ***
Q75 -53.123182 5.959363 -8.914 < 2e-16 ***
kurt 0.002569 0.001571 1.635 0.10196
sp.ent -30.436396 9.262956 -3.286 0.00102 **
sfm 8.536318 2.070361 4.123 3.74e-05 ***
meanfun 154.989620 8.875816 17.462 < 2e-16 ***
minfun -45.642737 8.180361 -5.580 2.41e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 3074.80 on 2217 degrees of freedom
Residual deviance: 458.79 on 2210 degrees of freedom
AIC: 474.79
Number of Fisher Scoring iterations: 8
相比逐步回归前AIC=489.2,逐步回归后模型的AIC=474.79,有着略微的下降,但是建立模型选取的变量由20个减小到8个,模型的稳定性有着大幅度提高。
可视化逐步回归剔除无关变量的过程。
- ## 可视化逐步回归AIC值变化的过程。
- ## 可视化在剔除变量过程中AIC的变化
- stepanova <- voicelmstep$anova
- stepanova$Step <- as.factor(stepanova$Step)
- ggplot(stepanova,aes(x = reorder(Step,-AIC),y = AIC))+
- theme_bw(base_size = 12)+
- geom_point(colour = "red",size = 2)+
- geom_text(aes(y = AIC-1,label = round(AIC,2)))+
- theme(axis.text.x = element_text(angle = 30,size = 12))+
- labs(x = "删除的特征")
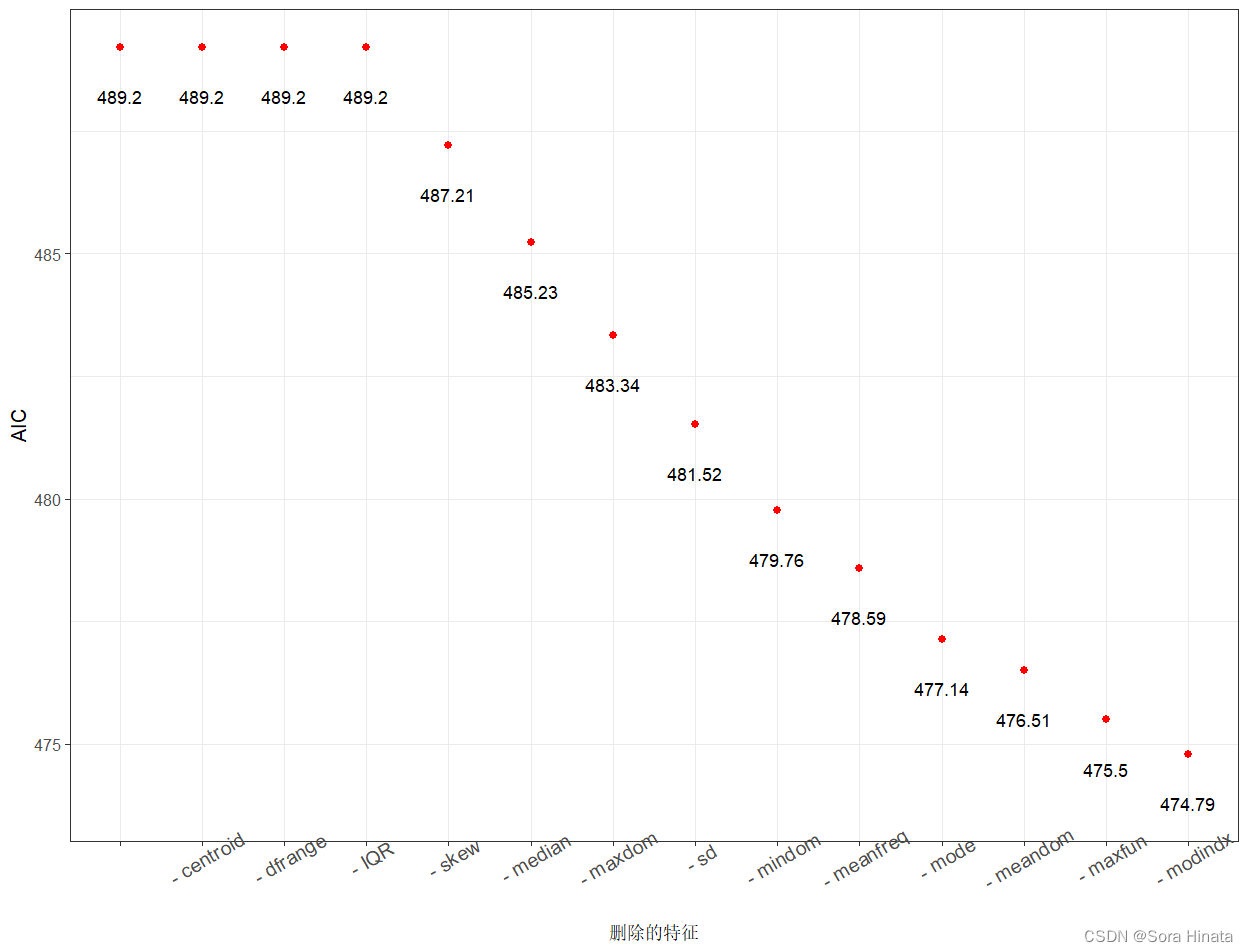
计算逐步回归前后模型的精度。
- ## 对比逐步回归前后两个模型逐步回归前后的在测试集上预测的精度
- library(Metrics)##accuracy()计算精度的函数在Metrics包里面
- voicelmpre <- predict(voicelm,voice_test,type = "response")##这个报错可以不用理,不影响结果。
- voicelmpre2 <- as.factor(ifelse(voicelmpre > 0.5,1,0))
- voicesteppre <- predict(voicelmstep,voice_test,type = "response")
- voicesteppre2 <- as.factor(ifelse(voicesteppre > 0.5,1,0))
- sprintf("逻辑回归模型的精度为:%f",accuracy(voice_test$label,voicelmpre2))##优化前
- sprintf("逐步逻辑回归模型的精度为:%f",accuracy(voice_test$label,voicesteppre2))##优化后
- ## 不难观察得到,优化前逐步回归的精度为0.981053,优化后的逐步回归精度为0.983158。
- ## 综合来看AIC值降低,在测试集上检验的模型精度提高,说明剔除不显著变量有利于提高模型的精度。
观察得到,优化前逐步回归的精度为0.981053,优化后的逐步回归精度为0.983158。综合来看AIC值降低,在测试集上检验的模型精度提高,说明剔除不显著变量有利于提高模型的精度。
下列代码可输出模型的结果
- ## 模型结果
- library(epiDisplay)
- logistic.display(voicelmstep)
- ## write.csv(logistic.display(voicelmstep)$table,file = "model_result.csv")##输出模型结果为表格
案例2:新生婴儿体重判别
该数据是R语言MASS包中birthwt出生数据帧具有189行和10列。这些数据是1986年在马萨诸塞州斯普林菲尔德的贝州医疗中心收集的。
- #### 案例2:新生婴儿体重判断 ####
- ## MASS包中birthwt出生数据帧具有189行和10列。这些数据是1986年在马萨诸塞州斯普林菲尔德的贝州医疗中心收集的。
- ## low:出生体重小于2.5公斤的指标:体重小于2.5kg的婴儿为1,大于2.5kg为0。
- ## age:母亲的年龄,单位:年
- ## lwt:母亲最后一次月经时的体重(磅)
- ## race:母亲的种族(1=白人,2=黑人,3=其他)
- ## smoke:怀孕期间的吸烟状况。
- ## ptl:以前过早分娩的次数。
- ## ht:高血压病史。
- ## ui:子宫易激惹。
- ## ftv:妊娠早期的医生就诊次数。
- ## bwt:出生体重,单位:克。
- library(caret)
- library(ROCR)
- library(tidyr)
- library(corrplot)
- library(ggcorrplot)
- library(MASS)
- birthwt<-birthwt##导入数据集birthwt
- str(birthwt)##不存在因子和字符串变量
- summary(birthwt)
-
- ##分析数据集可以知道,low的分类是以bwt为基准,并有着直接联系,对此在建立low的logistic回归时要剔除bwt。
- data_2<-birthwt[,1:9]
-
- ## 作热力图观察变量之间的关联性
- str(data_2)##观察数据类型
- birt_cor <- cor(data_2)
- corrplot.mixed(birt_cor,tl.col="black",tl.pos = "d",number.cex = 0.8)
- ## 换一种热力图作法
- library(ggcorrplot)
- ggcorrplot(birt_cor,method = "square",lab = TRUE)+
- theme(axis.text.x = element_text(size = 10),
- axis.text.y = element_text(size = 10))
- ## 不难观察得到,low和其它自变量几乎没有明显关联性
-
- ## 作不同体重的概率密度图
- data_3<-data_2
- data_3$low<-as.factor(data_3$low)
- plotdata <- gather(data_3,key="variable",value="value",c(-low))
- ggplot(plotdata,aes(fill = low))+ ##aes(fill = label)是设置不同性别作密度图
- theme_bw()+geom_density(aes(value),alpha = 0.5)+
- facet_wrap(~variable,scales = "free")
- ## 观察密度图不难发现,绝大部分变量几乎重合,说明自变量几乎难以区分low。
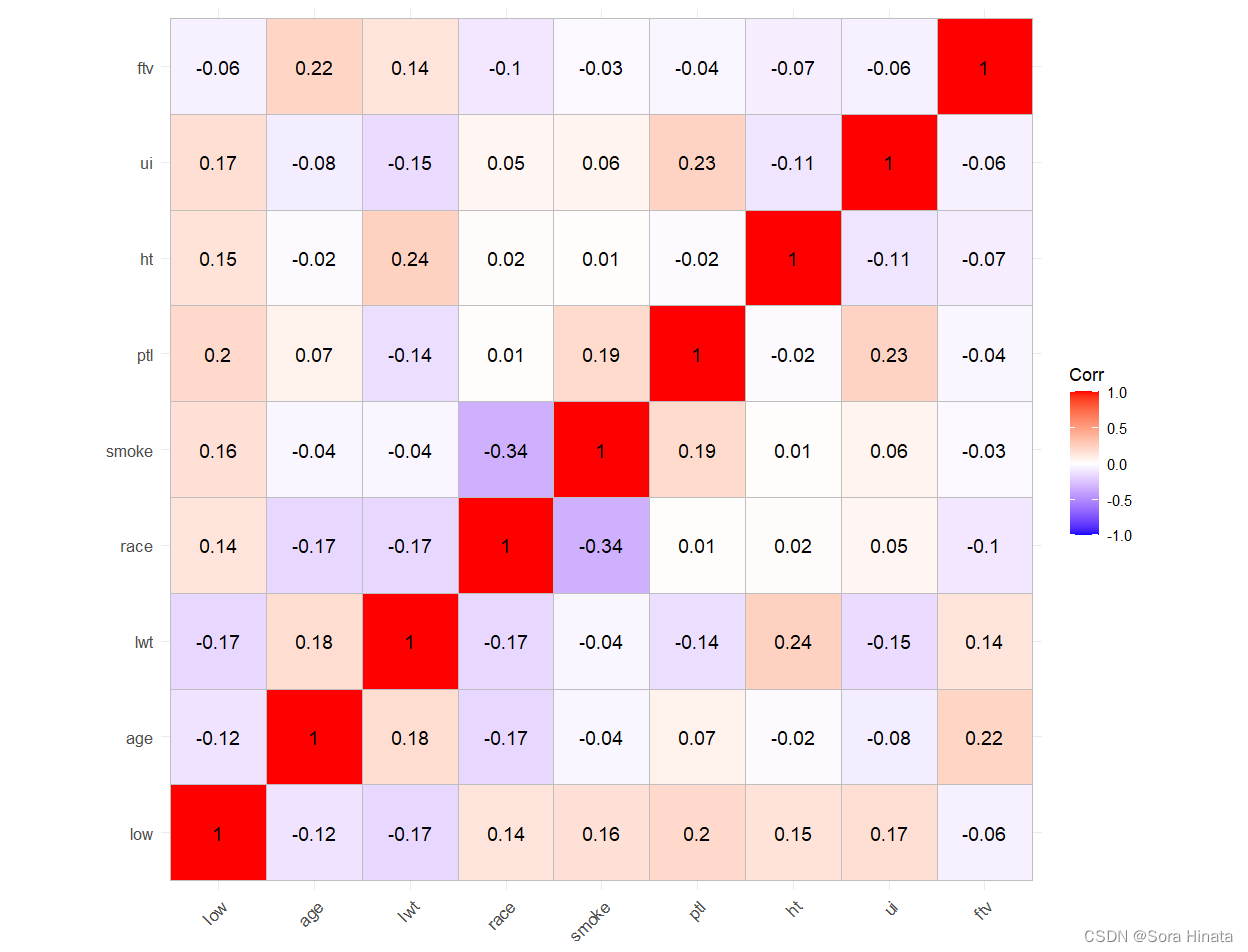

观察密度图不难发现,绝大部分变量几乎重合,说明自变量几乎难以区分low,对此需要对数据进行清洗,如果直接建立模型,模型的精度可能会下降。
- ## 数据的清洗
- ## 从上面初步观察,变量难以直接建立logistic回归模型,对数据进行清洗。
- str(data_2)
- summary(data_2)
- ## 二次分析数据集
-
- ## 分析plt早产次数和ftv怀孕初期,并作出其频数图。
- library(epiDisplay)
- tab1(data_2$ptl)
- ## 统计结果累示,有84.1%的孕妇没有早产史,早产次数超过一次的孕妇很少,可以把变量ptl也转换成一个二分类的因子。
- ii=1
- while (ii) {
- if(data_2[ii,6]>1)
- data_2[ii,6]<-1
- if(ii==length(data_2$ptl)){
- break
- }
- ii<-ii+1
- }
- tab1(data_2$ptl)
-
- tab1(data_2$ftv)
- ## 同理根据变量ftv的频数分布,我们有必要将探访医生超过一次的孕妇合并成一类,将变量ftv转换成一个包含3个水平的因子。
- ii<-1
- while (ii) {
- if(data_2[ii,9]>2)
- data_2[ii,9]<-2
- if(ii==length(data_2$ptl)){
- break
- }
- ii<-ii+1
- }
- tab1(data_2$ftv)

统计结果累示,有84.1%的孕妇没有早产史,早产次数超过一次的孕妇很少,可以把变量ptl也转换成一个二分类的因子。

根据变量ftv的频数分布,我们有必要将探访医生超过一次的孕妇合并成一类,将变量ftv转换成一个包含3个水平的因子。
下面二次作热力图和概率密度图进行观察。
- ## 作热力图观察变量之间的关联性
- str(data_2)##观察数据类型
- birt_cor <- cor(data_2)
- corrplot.mixed(birt_cor,tl.col="black",tl.pos = "d",number.cex = 0.8)
- ## 换一种热力图作法
- library(ggcorrplot)
- ggcorrplot(birt_cor,method = "square",lab = TRUE)+
- theme(axis.text.x = element_text(size = 10),
- axis.text.y = element_text(size = 10))
- ## 不难观察得到,low和其它自变量几乎没有明显关联性
-
- ## 作不同体重的概率密度图
- data_3<-data_2
- data_3$low<-as.factor(data_3$low)
- plotdata <- gather(data_3,key="variable",value="value",c(-low))
- ggplot(plotdata,aes(fill = low))+ ##aes(fill = label)是设置不同性别作密度图
- theme_bw()+geom_density(aes(value),alpha = 0.5)+
- facet_wrap(~variable,scales = "free")
- ## 观察密度图不难发现,绝大部分变量几乎重合,说明自变量几乎难以区分low。
但是热力图和密度图也不是绝对说明不能建立logistic回归模型,它只是用来初步判断,但是能肯定建立logistic回归模型的精度不会特别高,下面实际建立logistic回归模型进行测试。
- ## 但是热力图和密度图也不是绝对说明不能建立logistic回归模型,它只是用来初步判断,但是能肯定建立logistic回归模型
- ## 的精度不会特别高,下面实际建立logistic回归模型进行测试。
- ## 切分数据集,将70%作为训练集,30%作为测试集。
- set.seed(123)##设置随机树种子,保证抽样规则一致。
- index<-createDataPartition(data_2$low,p=0.7)
- birth_train<-data_2[index$Resample1,]
- birth_test<-data_2[-index$Resample1,]
- ##将训练集用于建立模型
- birthlm<-glm(low~.,data = birth_train,family = "binomial")## family 设置回归类型,"binomial"为logistic回归。
- summary(birthlm)##查看模型效果
- ## 结果观察得到,只有race、smoke、ptl、ht、ui五个变量是比较显著。
-
- ## 运用逐步回归剔除不显著变量
- birthlmstep <- step(birthlm,direction = "both")
- summary(birthlmstep)
- ##剔除了3个变量
Call:
glm(formula = low ~ race + smoke + ptl + ht + ui, family = "binomial",
data = birth_train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.2932 0.7537 -4.369 1.25e-05 ***
race 0.7304 0.2735 2.670 0.00759 **
smoke 1.2955 0.5083 2.549 0.01081 *
ptl 1.4170 0.5143 2.755 0.00587 **
ht 1.3014 0.8823 1.475 0.14020
ui 1.1929 0.5384 2.216 0.02672 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 167.40 on 132 degrees of freedom
Residual deviance: 136.21 on 127 degrees of freedom
AIC: 148.21
Number of Fisher Scoring iterations: 4
- ## 可视化逐步回归AIC值变化的过程。
- ## 可视化在剔除变量过程中AIC的变化
- stepanova <- birthlmstep$anova
- stepanova$Step <- as.factor(stepanova$Step)
- ggplot(stepanova,aes(x = reorder(Step,-AIC),y = AIC))+
- theme_bw(base_size = 12)+
- geom_point(colour = "red",size = 2)+
- geom_text(aes(y = AIC-1,label = round(AIC,2)))+
- theme(axis.text.x = element_text(angle = 30,size = 12))+
- labs(x = "删除的特征")

- ## 对比逐步回归前后两个模型逐步回归前后的在测试集上预测的精度
- library(Metrics)##accuracy()计算精度的函数在Metrics包里面
- birthlmpre <- predict(birthlm,birth_test,type = "response")##这个报错可以不用理,不影响结果。
- ##设置0.5为分界点,结果大于0.5则认为low等于1,小于0.5则认为low等于0。可以理解为概率,人为设定的。
- birthlmpre2 <- as.factor(ifelse(birthlmpre > 0.5,1,0))
- birthsteppre <- predict(birthlmstep,birth_test,type = "response")
- birthsteppre2 <- as.factor(ifelse(birthsteppre > 0.5,1,0))
- sprintf("逻辑回归模型的精度为:%f",accuracy(birth_test$low,birthlmpre2))##优化前
- sprintf("逐步逻辑回归模型的精度为:%f",accuracy(birth_test$low,birthsteppre2))##优化后
- ## 不难观察得到,优化前逐步回归的精度为0.642857,优化后的逐步回归精度为0.678571。
- ## 综合来看AIC值降低,在测试集上检验的模型精度提高。
不难观察得到,优化前逐步回归的精度为0.642857,优化后的逐步回归精度为0.678571。综合来看AIC值降低,在测试集上检验的模型精度提高。
模型的检验
上面我们只是从AIC值和精度两个指标来分析模型的好坏,下面换其它的方法。
详细比较模型间参数比较逐步回归前后的模型可以用 似然比检验(Likelihhod Ratio Test,LRT)进行比较。似然比检验通过计算似然比(Log Likelihhod Ratio,LLR)来评价两个模型的拟合优先度。通过两个对数似然值求出X2检验的p值。
- ## 计算方法一:
- ## logLik()函数计算对数似然值
- lowlm<-as.numeric(logLik(birthlm))
- lowlmstep<-as.numeric(logLik(birthlmstep))
- ## 计算X2检验的p值,若p值<0.001,说明两个模型的X2差异具有统计学意义:反之p值>0.001,两个模型的X2差异无统计学意义。
- pchisq(2*(lowlm-lowlmstep),df = 3,lower.tail = FALSE)##df表示前后两个模型变量变化差值。
- ## p值等于0.627417>0.001,两个模型的X2差异无统计学意义,说明使用逐步回归优化模型是合理的。
-
- ## 计算方法二:
- ## anova()可以直接计算对数似然值
- anova(birthlm,birthlmstep,test = "Chisq")
- ## p值等于0.627417
-
- ## 综合考虑,逐步回归后的logistic回归模型虽然模型的精度略微下降,但变量选择数量减少,模型AIC值下降,且似然比检验
- ## 的结果说明两个模型的X2差异无统计学意义,说明使用逐步回归优化模型是合理的,因此使用逐步回归后的logistic回归模型。
且似然比检验的结果说明两个模型的X2差异无统计学意义,说明使用逐步回归优化模型是合理的,因此使用逐步回归后的logistic回归模型。
- ## 模型结果
- library(epiDisplay)
- logistic.display(birthlmstep)
Logistic regression predicting low
crude OR(95%CI) adj. OR(95%CI) P(Wald's test) P(LR-test)
race (cont. var.) 1.47 (0.99,2.19) 2.08 (1.21,3.55) 0.008 0.005
smoke: 1 vs 0 2.32 (1.1,4.89) 3.65 (1.35,9.89) 0.011 0.008
ptl: 1 vs 0 5.33 (2.11,13.46) 4.12 (1.51,11.3) 0.006 0.005
ht: 1 vs 0 2.97 (0.64,13.93) 3.67 (0.65,20.71) 0.14 0.139
ui: 1 vs 0 3.9 (1.51,10.06) 3.3 (1.15,9.47) 0.027 0.026
Log-likelihood = -68.1061
No. of observations = 133
AIC value = 148.2121
案例2和案例1的区别在于,案例1明显通过热力图和密度图能够直接发现和分析能够建立logistic回归模型。案例2热力图和密度图直接分析难以建立logistic回归模型,需要对数据进行清洗,最后再用似然比检验模型是否合理。
数学建模里面,模型的好坏不单取决于数据的好坏,还得取决于怎么去建立模型,怎么处理数据适当对模型进行优化(适当的假设),最后并通过检验证明模型的合理性,整个过程要自圆其说,希望通过这两个案例能够对理解logistic回归模型和模型的建立有所帮助。

