
- 1c语言学习第十五天
- 22024年AGI行业研究:多模态大模型与商业应用 建议都看一下,说不定就是你的菜_agi大模型_算力生态商业模式和客户画像
- 3Transformers 自然语言处理(一)_transformer中为了解决自然语言顺序问题,采用的策略是
- 4鸿蒙系统与Android有何不同?_鸿蒙系统和安卓的区别
- 5vue3插件原理
- 6Oracle 表空间、用户、Schema_oracle schemas
- 7GraphRAG本地部署(Xinference本地模型)+ neo4j可视化_graphrag支持xinference
- 8iOS Runtime应用实例(一)类别添加属性_ios runtime添加属性
- 9slurm集群搭建
- 102024年华数杯C题老外游中国深度剖析!代码思路文章全解!_问题 1 请问 352 个城市中所有 35200 个景点评分的最高分(best score,简 称
全球最强AI程序员 “Genie” 横空出世_cosine genie
赞
踩
World’s best AI Software Engineer.

Genie is the best AI software engineer in the world by far - achieving a 30% eval score on the industry standard benchmark SWE-Bench.
Genie is able to solve bugs, build features, refactor code, and everything in between either fully autonomously or paired with the user, like working with a colleague, not just a copilot.
Genie 是什么
Genie是迄今为止世界上最好的 AI 程序员
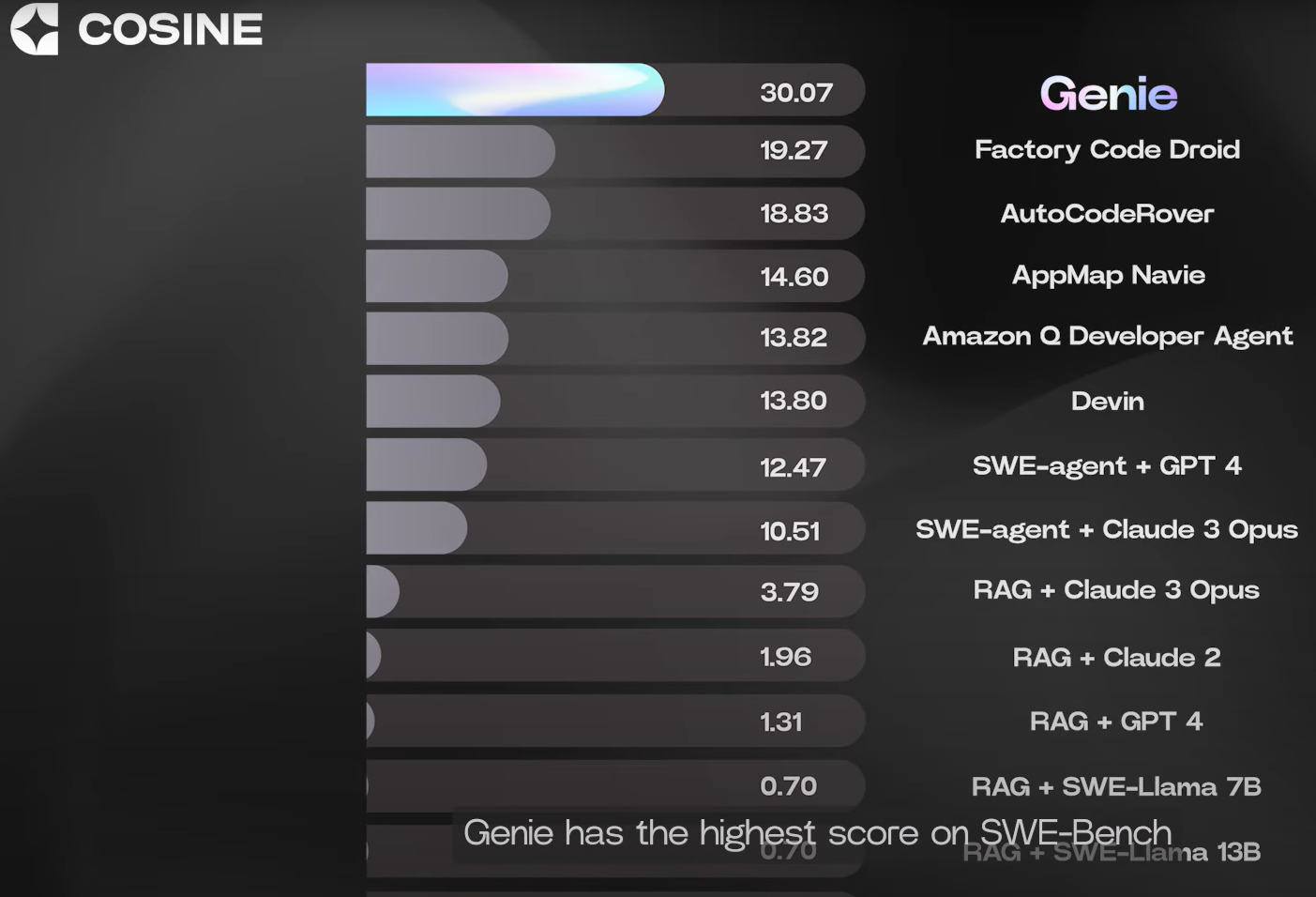
- 在权威榜单 SWE-Bench 上得分为 30%,遥遥领先第二名19.27%!(SWE-Bench:评估大模型解决现实中软件问题的基准)
- 比亚马逊的 Q 和 Factory 的 Code Droid 的 SOTA 得分高出 56%:两者在 SWE-Bench 上的得分均为 19%
- 比 Cognition 的 Devin 高出 118%:在 SWE-bench 的 subset 上得分为 13.8%
由于 Devin 只跑了 SWE-Bench 上 2294 个任务中的 500 个,因此它们的可比得分为 3.44%。
Genie not just a copilot
Genie 能够完全自主地与用户匹配,处理bug、构建特征、重构代码以及在两者之间的一切,智能如你身旁的同事。
研发团队认为:若希望模型更像程序员,就需要教会它人类程序员的工作方式。这种方法不仅在基准测试中表现出色,而且还能够构建出真正像人类程序员一样行事的产品。

那么如何训练一名AI工程师呢
首先,让它观察程序员如何工作,并模仿这个过程。但在实践中,获取这些数据并加以利用均极为困难。因此研发团队尝试从数据集、上下文语言模型、多模态数据入手。
利用构建工具创建数据集
在过去的一年里,Genie 研发团队致力于通过构建工具来创建一个能够展示这个过程的数据集。他们的数据管道结合了人工制品、静态分析、自我博弈、逐步验证和经过大量标记数据训练的微调AI模型,从而实现最佳输出。
数据质量的把控
从语言、任务类型、任务长度等不同维度入手,在数据混合方面做了诸多尝试,并对多模态数据进行大量试验。
基础模型的选用
当第一次开始这个项目时,能训练的最好结果是 gpt-3.5-turbo-16k,但很快意识到这个模型智能受限,其最关键的还是上下文长度。

要想获得高质量的输出,模型需尽可能多的信息;研发团队与OpenAI 一起训练出更佳的上下文长度模型,极大地释放研究项目能力。
so much has been learned, but the number one learning, and it sounds obvious, is that the data is absolutely everything.

Genie采用特殊数据集和自我改进机制,使其在复杂编码中表现出色。
未来,Genie 将更熟练地掌握更广泛的编程语言,重点是熟练掌握每种语言最新和最广泛使用的框架,以满足开发人员各式各样的业务需求。
Genie启动
Genie
那么,可以给 Genie 分派开发任务了:cosine.sh
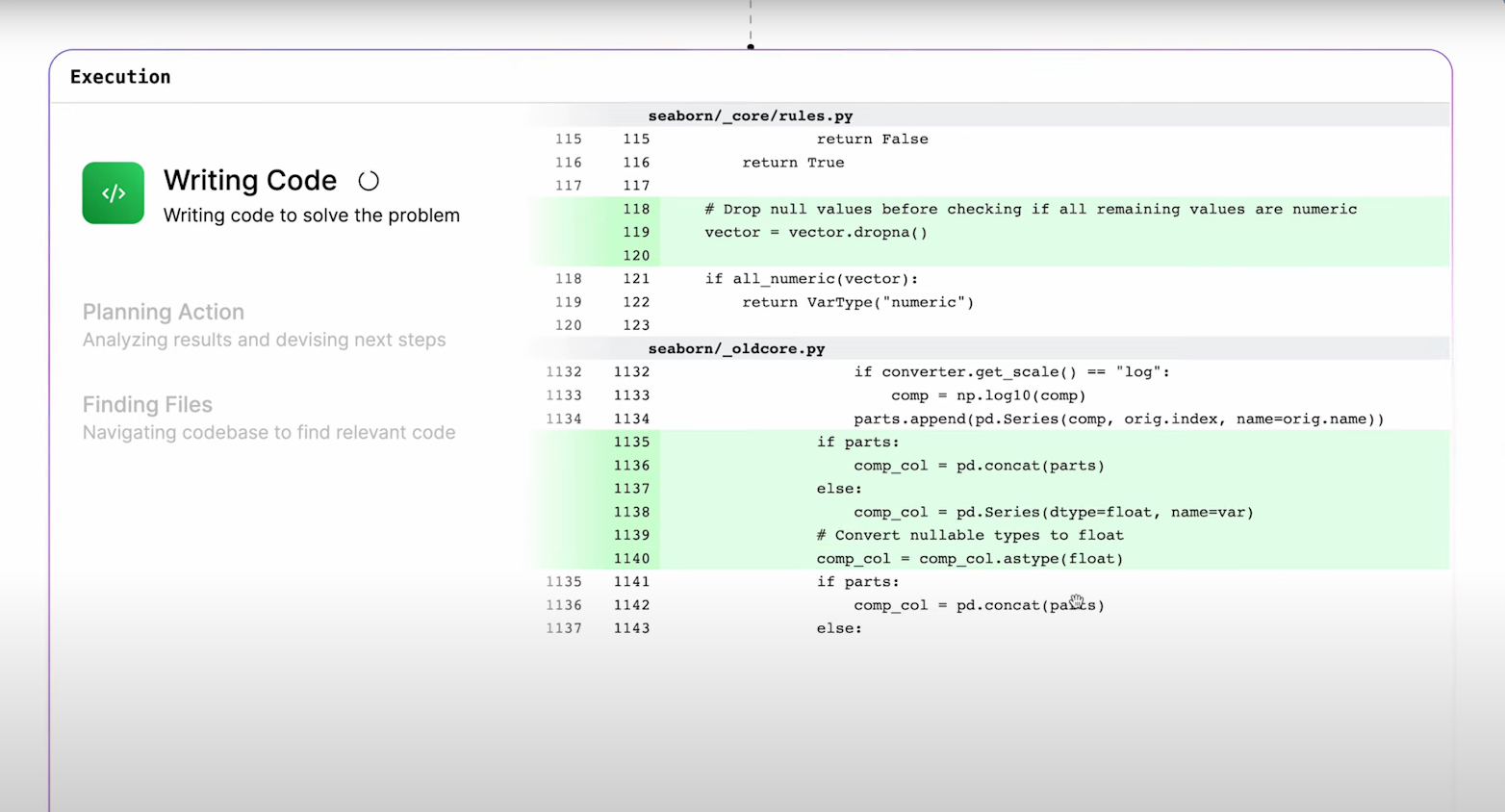
对付这点小事对我来说真是小菜一碟----麦克阿瑟
欢迎关注:有点建树,做更多交流。


