
- 1基于freeswitch 自动外呼系统实现(一)_基于freeswith的智能外呼
- 2Android 音视频开发——录屏直播,android开发基础在线培训学校
- 3Android gradle 构建
- 4【技术变现小技巧】-- Boss直聘 批量求简历_boss直聘投递简历技巧
- 5Webpack 从入门到精通_webpack 学习 csdn
- 6主从复制--01---搭建集群---热备份_集群热备
- 7Flink SQL对于window aggregation的优化_aggregation 优化
- 820个值得做的AI变现案例分享,副业搞钱“支棱”起来_ai赚钱项目
- 9[AIGC] 对比MySQL全文索引,RedisSearch,和Elasticsearch的详细区别
- 10JAVA学习第一天_java不适合互联网模式的到处修改
【AI绘画】2024年最新Stable Diffusion实战入门详细教程(环境安装,插件,参数,提示词)
赞
踩
Stable Diffusion
是利用扩散模型进行图像生成的产品,可以支持
text2image、image2image。并且由于“论文公开+代码开源”,其用户群体远大于其他 AI
图像生成产品,之后小编会连续更新一些关于AI绘画的干货教程
目标 :了解入门Stable Diffusion相关背景,环境安装,插件,文生图参数,提示词等相关知识
参考:
在线体验:
dreamstudio.ai/
git地址:
github.com/AUTOMATIC1111/stable-diffusion-webui
文档:
github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
论文地址:
arxiv.org/abs/2112.10752
目录:
1 环境部署
2 关于插件
3 文生图参数
4 提示词
一 环境部署
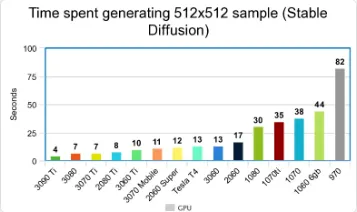
512x生图 主流显卡速度对比:
安装步骤可参考前期文章-AI绘画:搭建自己的AI绘画网站(StableDiffusion)(todo);
其他方式:
启动器一键安装(秋葉 aaaki),适合没有开发经验的同学
地址放到了文末,有需要自行提取
二 关于插件

Stable Diffusion 可配置大量插件扩展,在 webui 的“扩展”选项卡下,可安装插件
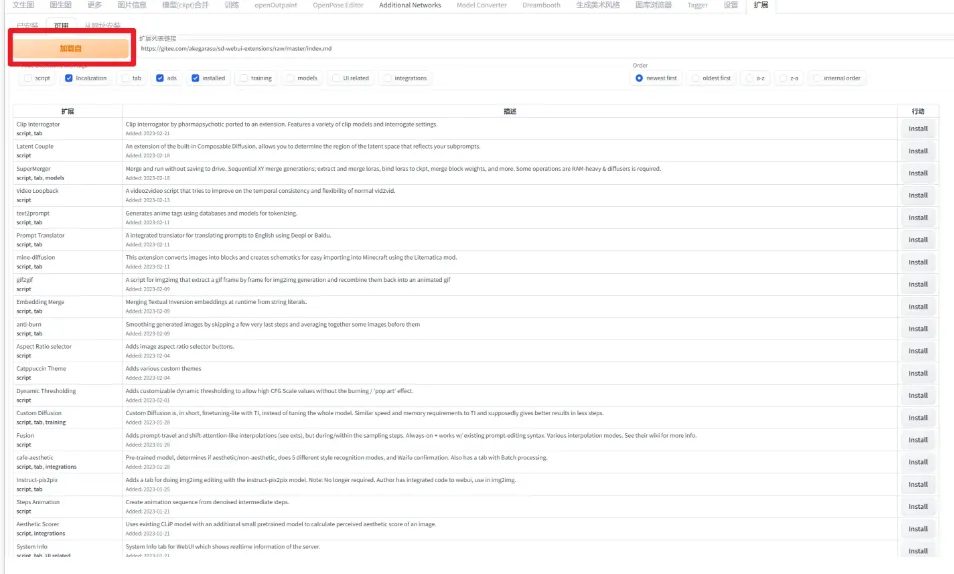
点击「加载自」后,目录会刷新。选择需要的插件点击右侧的 install 即可安装。安装完毕后,需要在右侧点击重新启动用户界面
好用插件:
https://zhuanlan.zhihu.com/p/579538165
三 文生图参数
首先不同模型所生成的图风格是会完全不一样的,在 C 站 上可以直接下载模型。具体可参照文章AI绘画:搭建自己的AI绘画网站(Stable
Diffusion)(todo);
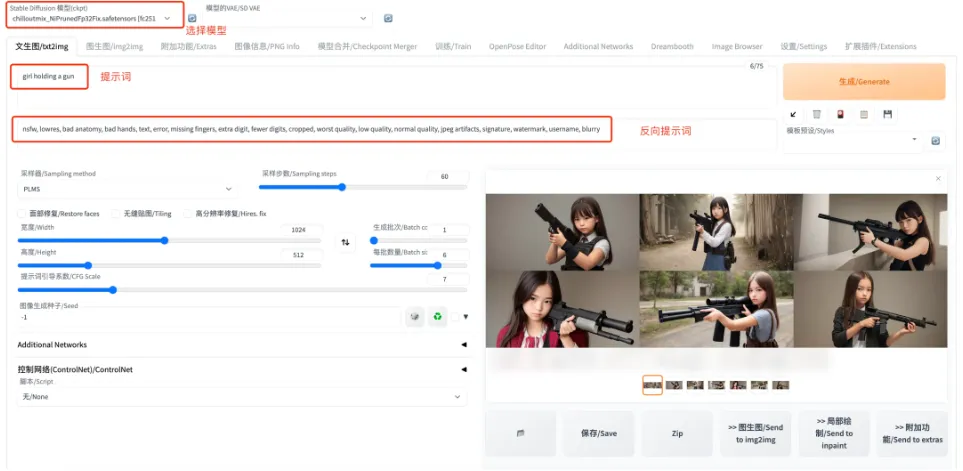
参数介绍:
1 Sampler采样器:
其实就是在做图像生成的步骤,选用哪种模型(或扩散模型)
2 Sampling Steps采样步数:
其实就是扩散模型进行扩散的 step,一般设置为 20~30
以随机高斯噪声起步,向符合提示的图像一步步降噪接近。随着步数增多,可以得到对目标更小、更精确的图像。但增加步数也会增加生成图像所需的时间。增加步数的边际收益递减,取决于采样器。一般开到。
3 height高度/width宽度:
生成图片的 size
4 Batch size生成批次/Batch count每批数量:
最终会生成“生成批次 x 每批数量”张图片
5 CFG Scale提示词相关性
图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示,一般开到 7~11
5 seed随机种子
种子决定模型在生成图片时涉及的所有随机性
6 Highres. fix高清修复,restore faces面部修复
如果使用高清修复,会型首先按照指定的尺寸生成一张图片,然后通过放大算法将图片分辨率扩大,以实现高清大图效果;
修复画面中人物的面部,但是非写实风格的人物开启面部修复可能导致面部崩坏
7 Aditional Networks
是一个插件,可以为模型加上一些其他结构(如 LoRA 等),关于模型训练和组合,后期详细介绍
8 ControlNet
是一个插件,可以通过输入一张图片,来控制生成结果与输入图片相似,后期详细介绍
9 Script脚本
尾部有一个脚本的选项
text2image 功能支持 4 个脚本选择
1 Prompt matris
提示词矩阵:当我们有多个提示词时,该脚本提供一个能够看不同组合效果的功能。例如我们输入"girl with skirt|gun|blue
hair"作为 prompt,其中包含 3 个提示词,且用"|"分割
2 Prompts from file or textbox
从文本框或文件载入提示词 :就是让用户能够从文件中导入提示词
3 X/Y/Z plot
X/Y/Z 图表 :针对特定 prompt,对比不同纬度的参数取不同值时的效果
4 controlnet m2m
这个是一个视频处理功能,本质上是把用户上传的视频切帧,并分别进行 image2image,最后捏成一整个新的视频
四 提示词
提示词中可以有3种方式填写
1 句子描述:可以使用描述物体的句子作为提示词。大多数情况下英文有效,也可以使用中文。勿复杂语法
2 单词标签:可以使用逗号隔开的单词作为提示词。一般使用普通常见的单词。单词的风格要和图像的整体风格搭配,勿拼写错误(donmai.us)
3Emoji:Emoji (
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

