
- 1我的十年创业路
- 2大模型时代的网络安全:安恒“网安三剑客”实战指南_网络安全运营大模型参考架构 安恒
- 3SQLServer数据库、附加数据库时出错。有关详细信息,请单击“消息”列中的超链接_sql server请单击信息列中超链接
- 42024年软件测试最全Python基础介绍 —— 使用pytest进行测试!,35岁老年程序员的绝地翻身之路
- 5LeetCode算法题(数组相关)(五)——有序数组的平方_leetcode 给定一个升序数组1,元素有重复,对每个元素算一下平方后得到新的数组2,问
- 6数据绑定之prism_microsoft.practice.prism.dll文件
- 7【华为GAUSS数据库】从0到1,数据库连接,新建用户,新建数据库,新建表等简单使用_gauss创建用户
- 8创龙科技位居头版,2023深圳elexcon电子展为智能化赋能!_创龙科技与正点原子
- 9十五届蓝桥杯EDA设计与开发组模拟题1流程与经验分享_蓝桥杯eda csdn
- 10十几个软件测试实战项目【外卖/医药/银行/电商/金融】_软件测试项目
Sora技术详解_cross attention sora
赞
踩
最近Sora的出世引起了许多关注,这里对相关的技术知识和模型结构做了一定的梳理,如有讲解有误的地方,敬请斧正。
根据Demo可以看出Sora的几个突出点:
- 生成方式:文字/ 文字+图片 / 文字+视频 / 视频+视频 生成视频内容/图片
- 画质突破,最高可以生成一分钟1920x1080p,1080x1920p以内的任意纵横比的视频。
- 视频连续性: 视频帧率高、连续性非常一致(无背景切换、明显的时序错误)
- 真实物理引擎模拟:符合现实世界的物理规律
虽然没有模型的实现细节,我们也仍然可以管中窥豹,探寻一下相关的技术实现。
该技术报告主要侧重于:
- 将所有类型的视觉数据统一表示的方法
- 对Sora的功能和局限性的评估
前情提要
许多先前的工作已经研究了使用各种方法对视频数据进行生成建模,包括循环网络,生成对抗网络,自回归转换器,和扩散模型.这些工作通常集中在有限的视觉数据类别,较短的视频或固定大小的视频上。而Sora 是一种通用的视觉数据模型,它可以生成跨越不同持续时间、纵横比和分辨率的视频和图像,最多可生成一整分钟的高清视频。
| 使用模型 | 优势 | 劣势 |
|---|---|---|
| RNN | 适合时序数据的生成 | 无法捕捉长距离依赖 |
| GANs | 通过对抗训练学习真实数据分布,生成的视频内容通常具有较高的真实性。 | 生成的结果缺乏多样性 |
| Autoregressive Transformers | 能够捕捉长距离依赖关系并且有 更好的并行处理能力 | 一般有固定上下文窗口大小限制 |
| Diffusion model | 可高度符合文本生成图像视频 | 背景难以固定,细节描述缺失 |
Sora能够生成多样化的视频和图像,相比于先前方法在视频长度、尺寸和固定大小方面的限制,它在各个方面都有了大的突破。
报告解析
Visual Patches

###前世今生
-
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
-
VIT受NLP中Transformer的启发,将一个标准Transformer直接应用到图像上。为此,它将图像分割成小块,并将这些块转化为线性嵌入序列,作为Transformer的输入。图像块(image patches)就相当于NLP任务中的单词(token)来做处理。并以有监督的方式训练图像分类模型。
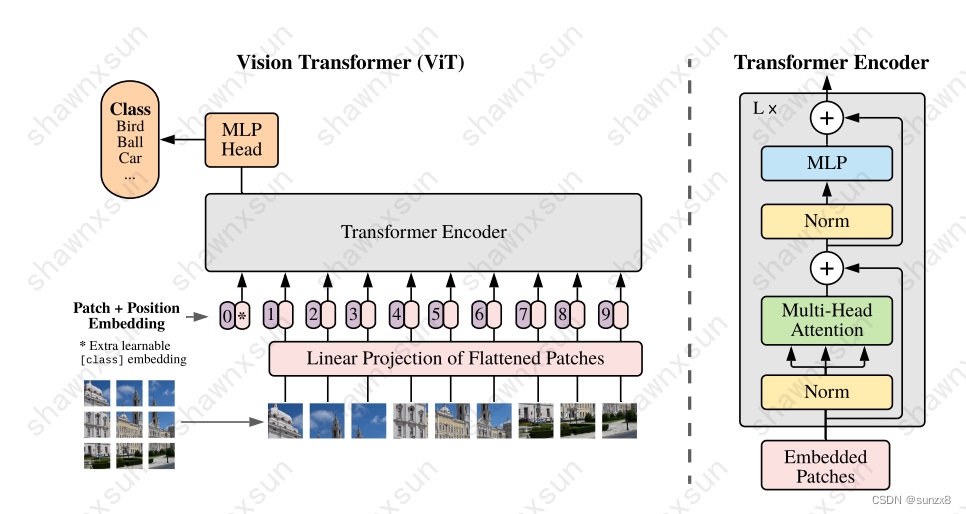
-
这也是Visual Patches的初始形态,VIT输入的时候将一张图像切割成同样大小的小块,将每个小块视为一个Token。每个Token被展平,通过一个线性层,加上相应的位置嵌入传递给模型。
-
需要注意的是,这里对应的图像而不是视频,两者之间最大的差异就是时间维度和空间维度特征的加入
-
-
ViViT: A Video Vision Transformer
- 该论文主要介绍纯transformer结构的视频分类架构,通过挖掘spatio-temporal tokens,进而encode一系列的transformer层。针对视频长距离依赖的问题,构建了一系列不同方式处理时空特征的Encoder变体模型。ViViT提出了两个方法来同时处理时间和空间维度的特征。分别是Uniform Frames Sampling和Tubelet embedding。
- Uniform Frames Sampling:
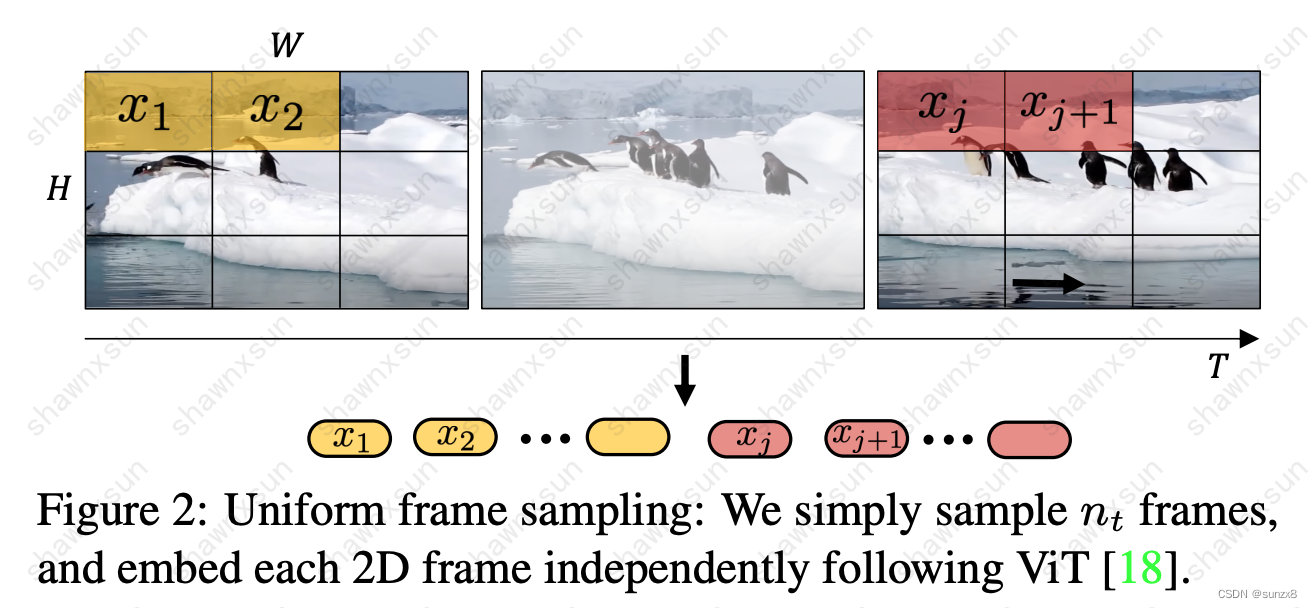
在这种方法中,对视频样本中的每一帧应用类似ViT的分块方式。**每一个Token都是从一帧中提取的一个分块(patch)。然后把这些分块拼接起来形成模型的输入。**但是使用这种方法时,即使我们给Token添加了position embedding,仍然遗漏了这个patch在视频样本中的确切帧和时间索引,对每一块空间和时间位置编码不够充分存在明显缺陷。
-
Tubelet embedding
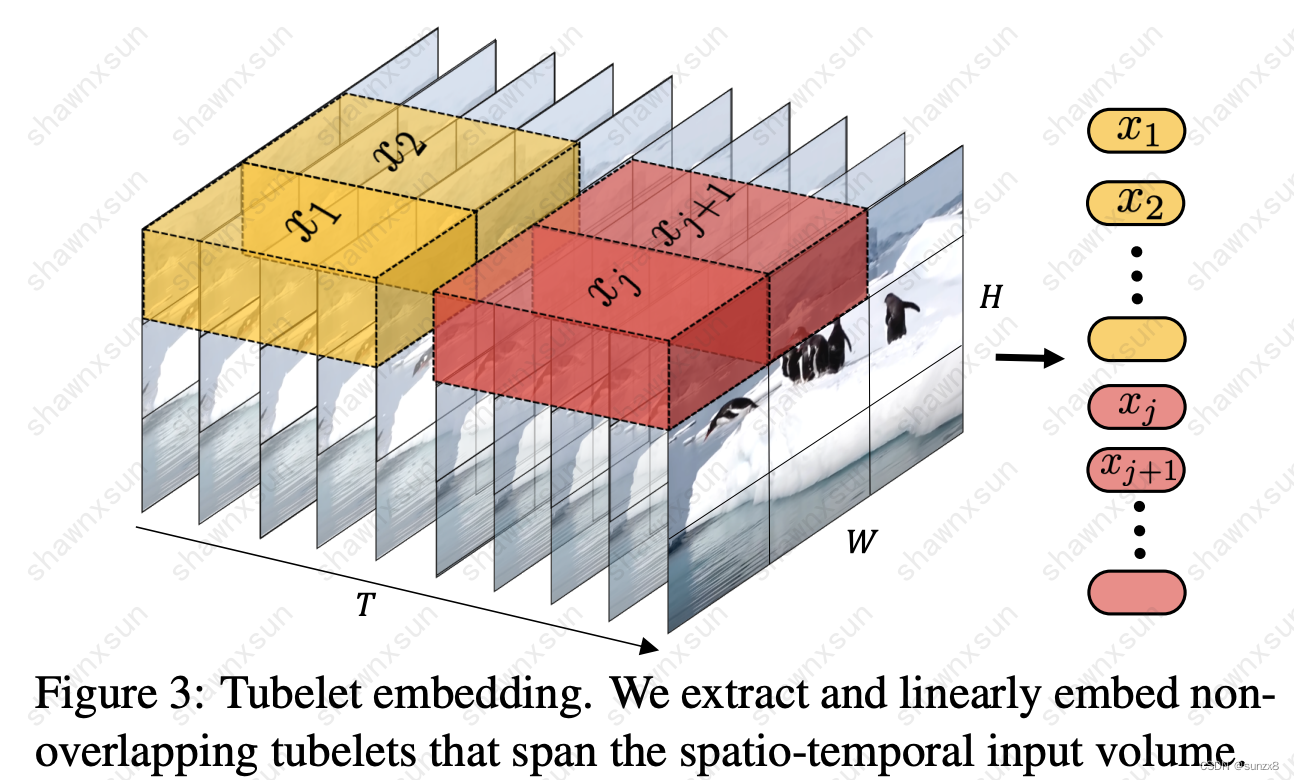
不同于从视频样本的每一帧中提取一个patch,这种方法从一段视频片段中提取一系列patch,将VIT的embedding扩展到三维度。一个patch的维度是t * w * h,即时间窗口乘以图片分块的宽和高。虽然这种方式增加了生成token的计算量,但是它很好地保留了时间信息,更加合理。
从Tubelet embedding可以看到,可以横跨时空的Patches——Spacetime Patches初现雏形。
-
Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
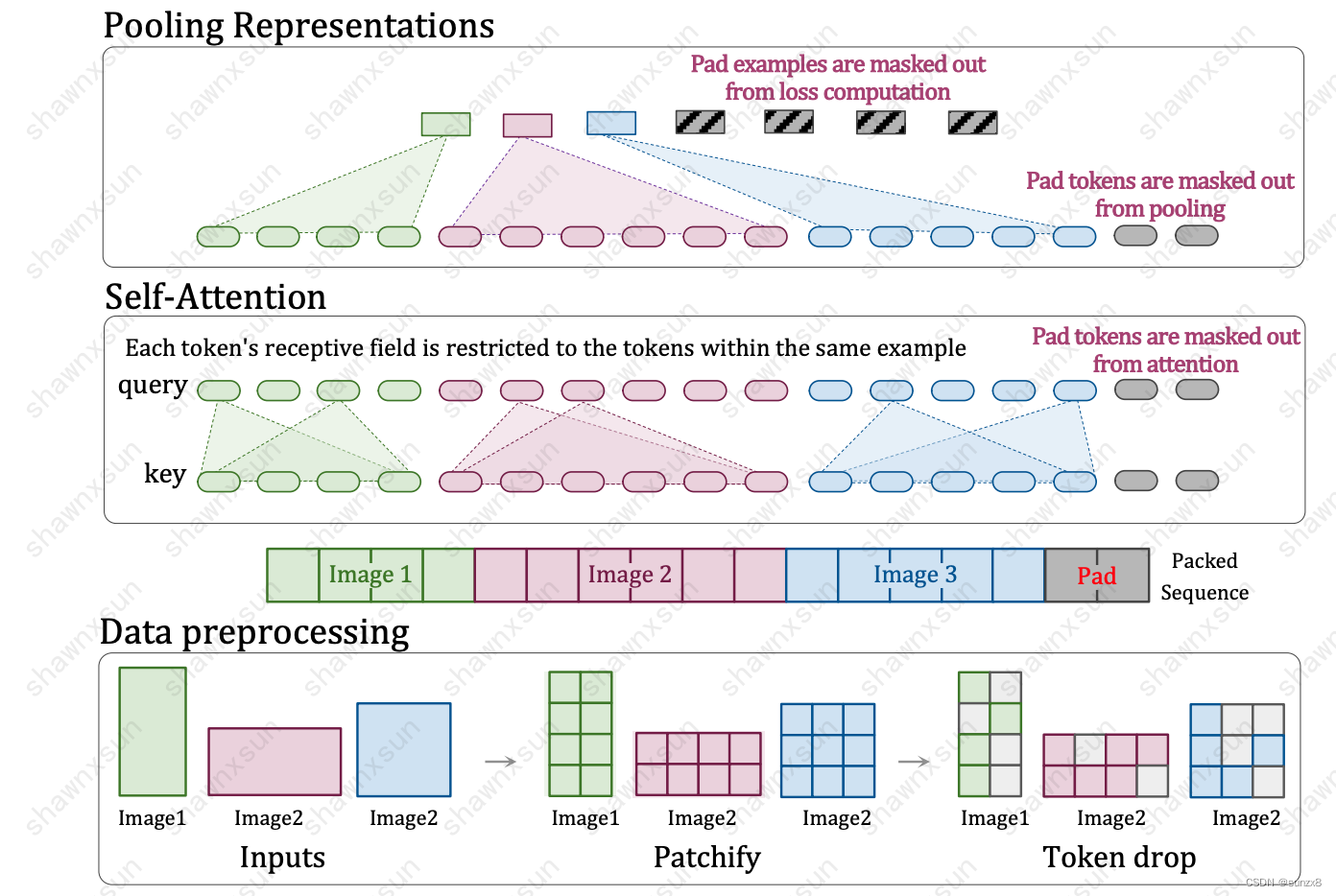
- 这个图从下往上推进:
- 第一部分,数据预处理的时候,各个size的图片,都统一编码为各不一致的patches,然后再对其进行一个随机dropout 的操作,dropout操作可以提高算法的鲁棒性。之后再把不同的patches进行flatten变为一个序列,不够的地方用padding填充。
- 第二部分则是 masked self-attention部分,这部分由于有mask 的作用,他可以分块让patches各自运算,不会互相影响。
- 第三部分是masked pooling。这部分计算好的特征,通过masked pooling进行分别池化。
- 主要内容:输入的图片无论各种尺寸,都通过加上mask来让他们在一个小模块里单独计算单独处理,不影响整体的input shape 和 output shape,从而达到了多尺寸全分辨率统一训练。另外,由于他随机丢弃了一些patches,因此算法的鲁棒性和速度也变快了。
- Factorized & fractional positional embeddings
- 为了支持可变宽高比并轻松地推广到未见过的分辨率,作者引入了因子化位置嵌入,不同于一般使用低秩矩阵进行因式分解的方法,本文将x和y坐标分解为单独嵌入ϕx和ϕy。然后将这两个嵌入相加(还可以尝试其他组合策略)。在此的基础上,作者考虑了两种方案:绝对嵌入,其中ϕ§:[0, maxLen(x+y/…)] 是绝对patch索引的函数;分数嵌入,其中ϕ®:[0, 1] 是相对距离r = p/side-length的函数,即两者沿着图像的相对距离。后者提供了与图像大小无关的位置嵌入参数,但部分模糊了原始宽高比,该比例仅隐含在patch数量中。除此之外,作者还考虑了简单的学习嵌入ϕ、正弦嵌入和学习傅立叶位置嵌入(learned Fourier positional embedding,后期有机会写文章讲)
- 一般来说,在使用计算机视觉模型处理图像之前,要先将图像调整到固定的分辨率,这种方式很普遍,但并不是最佳选择。本篇论文在训练过程中使用序列打包和Factorized & fractional positional embeddings来让模型可以处理任意分辨率和长宽比的输入内容。
- 这也是为什么这么多人推测OpenAI借鉴了Navit的思想(Sora可以生成1920x1080p,1080x1920p以内的任意纵横比的视频。)
- 这个图从下往上推进:
Video compression network
Difusion Model

- 这里这段话提到的lower-dimensional latent space就是参考的diffusion model系列延伸出的技巧。
-
DDPM: 扩散模型最早是在2015年的Deep Unsupervised Learning using Nonequilibrium Thermodynamics文章中提出的,在2020年,Denoising Diffusion Probabilistic Models(简称为DDPM)出现,让扩散模型重新开始被提及。

- 可以看到扩散模型分为两个阶段,分为前向过程和逆向过程。
- 前向过程即上图中x_0 到x_T 的过程,我们向原始图像中逐步添加高斯噪声,并且后一时刻都是由前一时刻添加噪声得到的,这样我们就得到x 1,x 2,…,x T ,x T是完全的高斯噪声。前向过程存在的意义就是帮助神经网络去训练逆向过程,即前向过程中得到的噪声就是一系列标签,根据这些标签,逆向过程在去噪的时候就知道噪音是怎么加进去的,进而进行训练。正向过程对应网络的训练过程。
- 逆向过程即上图中x T到x 0的过程。我们从标准正态分布采样的高斯噪声x T,逐步对其去噪,得到x T − 1,x T − 2 ,…,x 0,x 0是没有噪声的的图像。逆向过程对应网络的推理过程。
-
LDM
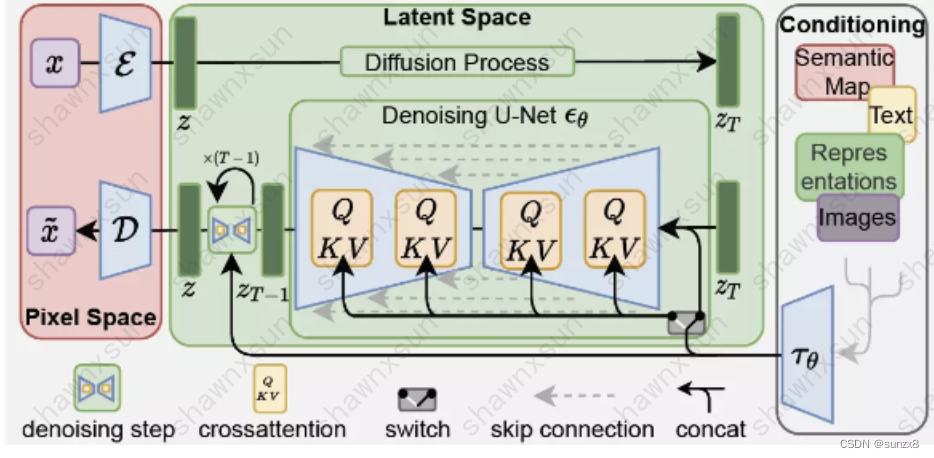
- 此模型出自High-Resolution Image Synthesis with Latent Diffusion Models,原DDPM类模型虽然效果不错,但是它要求扩散模型在像素空间进行模型的训练和推理,这会消耗大量的GPU资源,同时,他不能引入条件信息(文本,图片…)为了解决这两个问题,LDM做出了以下改进:
1.将模型从像素空间迁移到隐式特征空间中,比如从1024x1024降到512x512,这样的目的是去除不必要的高频和细节信息,在保留的核心信息上进行和DDPM一样的扩散过程。
2.通过cross attention的方式在去燥过程中注入条件信息,这样可以让模型依据文本来进行对应的绘画。
- 此模型出自High-Resolution Image Synthesis with Latent Diffusion Models,原DDPM类模型虽然效果不错,但是它要求扩散模型在像素空间进行模型的训练和推理,这会消耗大量的GPU资源,同时,他不能引入条件信息(文本,图片…)为了解决这两个问题,LDM做出了以下改进:
-
DIT
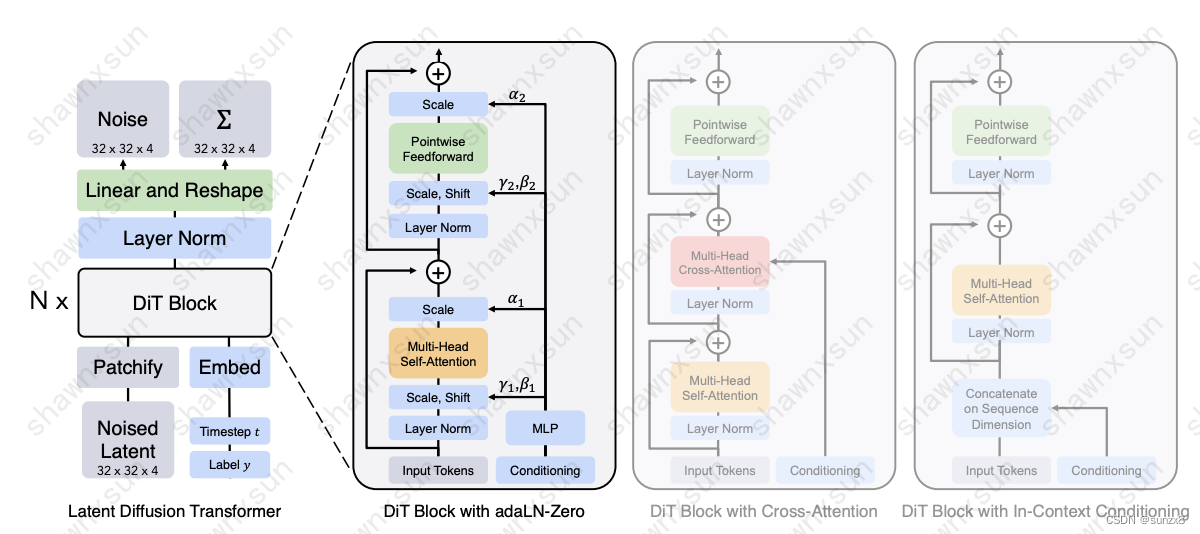
- DIT的特点是将 Diffusion 中常用的 UNet 模型替换为 Transformer 模型,Diffusion 仅要求其去噪网络是一个输入输出等尺寸的图到图模型,基于 CNN 的 UNet可以很好的做到尺寸放缩。而本文中作者使用 ViT 替换掉 UNet,在 Diffusion 中也验证了 Transformer 的 scaling 能力。
- DiT 探究了四种对 Transformer 的条件注入方法:
- Cross-attention:
- 我们将时间片特征t和类标签c两个 embedding 拼成一个长度为2的序列,然后在transformer block 中插入一个 cross attention,将这个序列embedding作为 cross attention的 K 和 V参与训练。
- Adaptive layer norm (adaLN):
- 将常规的 LN 替换为自适应的 adaLN,回归尺度scale 和偏移 shift 两个参数。
- adaLN-zero:
- 即采用零初始化,将adaLN的线性层参数初始化为零,网络初始化时 transformer block 的残差模块就是一个 identity 函数。在每个残差模块结束之前进行舒适化。
- In-context conditioning:
- 将两个 embedding 作为两个 special tokens 拼接到图像块 token 后,类似 ViT 中的 cls token。
-
U-ViT
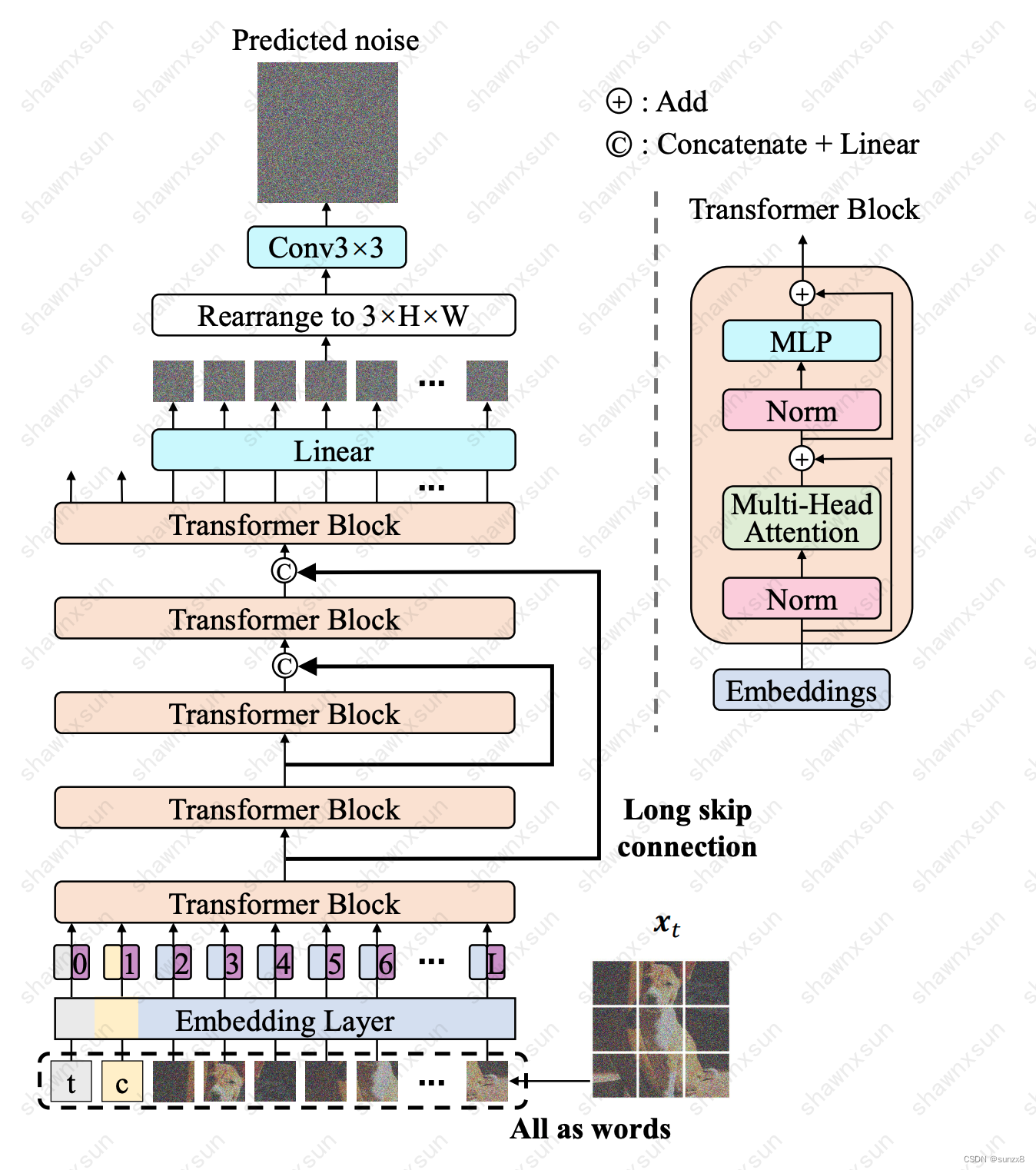
- U-ViT延续了ViT的方法,将带噪图片划分为多个patch之后,将时间t,条件c,和图像patch视作token输入到Transformer block,同时在网络浅层和深层之间引入long skip connection。
-
推测
在讲完一些背景知识,我们回归技术报告本身:
将视觉数据转换为补丁(Turning visual data into patches)

“我们首先将视频压缩为低维潜在空间,然后将表示分解为时空补丁,从而将视频转换为补丁。”
这里输入的视频被看成是若干帧图像, 它通过Visual Encoder生成在时间和空间上都压缩过的潜在表示,这些patch最终会被flatten成一维向量,送入diffusion model。根据引用文献可以看出,这里主要是参考了VIT,VIVIT和NAVIT对patch的处理。参考VIT将视频帧转换为固定大小的 patch,参考VIVIT将时间维度计入patch来插入帧之间的运动和变化,以此捕捉视频的动态信息。参考NAVIT解决不同的分辨率输入在训练时候带来的是大量的计算负载不均衡,让模型可以接受任意比例的视频/图片的输入和输出。
视频压缩网络(Video compression network)
这里根据引用文献可以看出压缩模型是基于VAE,VQ- VAE技术的。这个网络以原始视频为输入,并输出一个在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在空间上进行训练,并在此空间内生成视频。
时空潜在补丁(Spacetime Latent Patches)
参考NAVIT
扩展Transformers用于视频生成(Scaling transformers for video generation)
可以理解为一个视频版本的DIT。DIT已经证明使用transformer结构很容易scale up,在此基础上,用高质量数据训练好的dit处理前面压缩好的潜在token表示,输出去噪的视觉表示
语言理解(Language understanding)
这里分为两部分:
- 训练部分:Sora 采用了与 DALL・E 3 类似的方法。该方法首先训练图像描述器(视觉语言模型),以生成精确的描述性图像描述。之后再用描述器生成的描述性图像描述将用于微调文本到图像模型。
- 让文本参与视频生成部分:这里采用了CLIP模型的调节机制接收用户指令,用类似cross attention 的方法影响模型生成。
PS.
文章还没写完的时候,看到微软最近发了一篇推测分析Sora及其结构的论文,里面介绍的更加详细,整体与上面的内容相似:
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
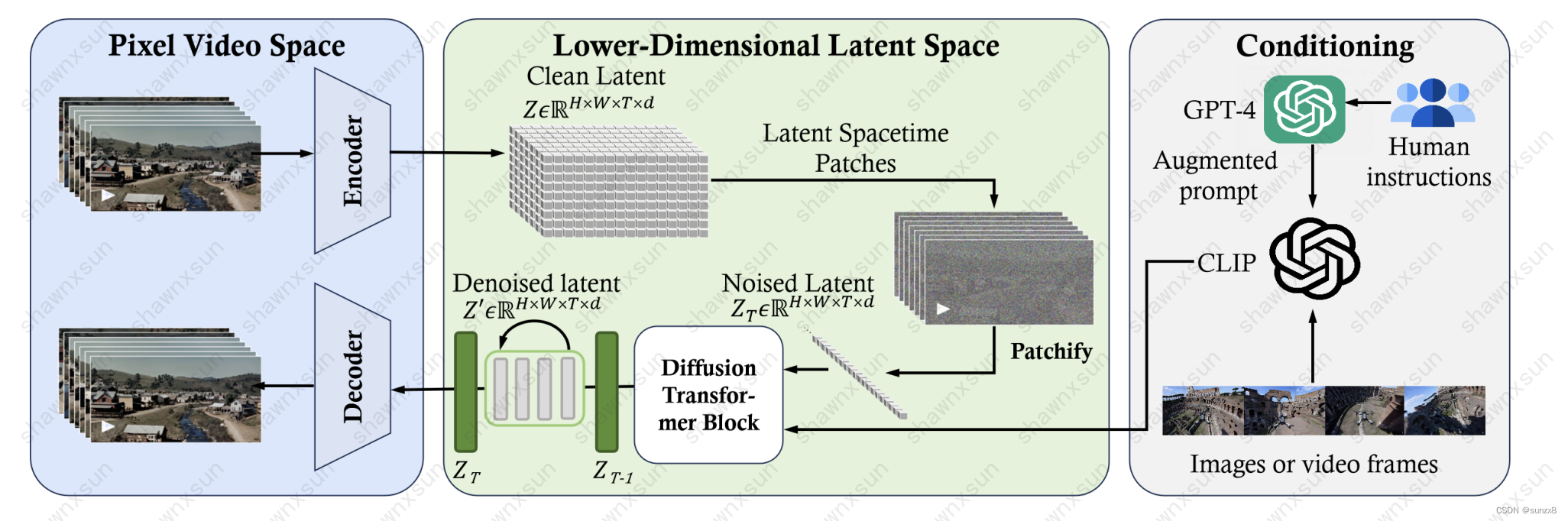
它推断Sora主要包含三部分结构:
- 时空压缩器首先将原始视频映射到潜在空间。
- 然后,ViT 处理 token 化的潜在表示,并输出去噪潜在表示。
- 类似 CLIP 的调节机制接收 LLM 增强的用户指令和潜在的视觉提示,引导扩散模型生成风格化或主题化的视频。经过许多去噪步骤后,生成视频的潜在表示被获取,然后通过相应的解码器映射回像素空间。

