
- 1使用deepspeed继续训练LLAMA_deepspeed train llama
- 2百度AI攻略:图像风格转换_调用百度ai实现图像风格转换的方法sdk代码
- 3通义千问2.5正式发布,能力升级,全面赶超GPT4
- 4[汇编语言&计算机原理] 带开机音乐,速度、进度和行驶方向显示的出租出计费系统设计_基于汇编程序的收费系统
- 5动手学ROS2-2节点通信-接口之RCLCPP实现
- 6MQ选型对比_ibmmq和rabbitmq区别
- 7一句话木马该怎么实现?现在就带你了解_playload和calss
- 8VMware Workstation Pro各版本下载链接汇总(特全!!!)_vmware workstation pro下载
- 9g++配置选项-std=c++11_g++ -std=c++11
- 10ECC算法介绍
redis watchdog_Redis分布式锁的租约续租实现
赞
踩

回顾
上篇文章中我们介绍了基于Redis的分布式锁实现,我们知道客户端想要获得访问一个resource的RedLock,实际上是尝试向N个Redis实例(一般每个实例都部署在一个机器上)使用SETNX来对该resource设置键值,当在超过(N/2 + 1)个实例上设置成功后,就认为获得锁成功。同时为了防止客户端进程失败无法正常释放锁进而导致其他的客户端再也获得不到锁,在使用SETNX的时候我们还需要为每个锁加一个过期时间Expire Time, 这样即使在客户端不能正常释放锁的情况下,过期时间到了之后,Redis会自动释放掉锁来让别的客户端能够继续申请锁。这就是一种典型的租约机制,客户端申请了一个租约时长为lock_timeout的锁,客户端可以在租约期间使用完之后正常释放锁,如果过了租约时间,即使客户端没有释放锁,Redis也会自动释放掉这个锁。
大龙:基于Redis的分布式锁详解zhuanlan.zhihu.com
当用户清晰的知道自己将要使用锁的时长时,设置lock_timeout是容易的,但是当用户并不知道自己要使用多长时间的锁时,设置租约时长就会是一个困难。如果设置的过短,那么就可能客户端还没用完锁,锁就被Redis给释放了,造成后续多个客户端同时访问某资源的错误,如果设置的时间过长,那么当客户端因为failure不能正常释放锁的时候,其他客户端就需要等待较长的时间(时间过了锁的租约期)才能够重新释放锁。一个好的想法就是,当用户并不知道自己将会用多久的锁时,我们为该锁设置一个较小的lock_timeout,同时每隔一段时间在该锁过期之前,就自动的向服务器延长该锁的lifetime。比如我们可以为该锁设置一个10s的lock_timeout,然后每过6s就重新再次设置锁的过期时间为10s【锁的过期时间即为 current_time 到current_time + lock_timeout期间,锁都是有效的】。这就是自动续租的概念。
上篇文章的结束向大家介绍了python的RedLock实现,同时指出该实现缺少自动续租特性。为了能够讲明白这件事,我上周向RedLock的异步开源实现代码中提交了watchdog的开发代码,并于昨天被merge到master分支,同时在整个过程中我重构了异步RedLock的代码,使得新的aioredlock的版本从0.3.0 jump到0.4.0。
https://github.com/joanvila/aioredlock.gitgithub.com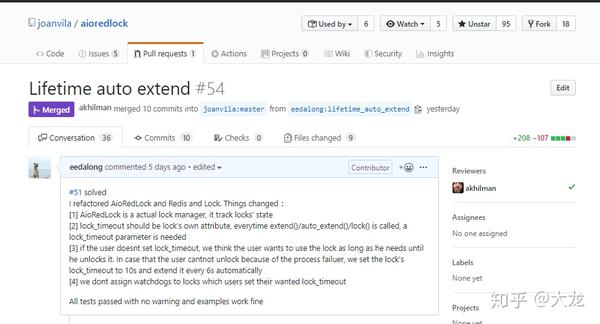
今天的文章就和大家分享下整个开发过程的一些设计和实现细节以及用到的一些比较有意思的底层特性:

Watchdog的设计原则
要实现watchdog,首先要明确watchdog的设计原则,在经过分析之后,得到如下几条原则
- 每隔定期时间向Redis服务器重新设置锁的过期时间以延长lifetime
- 当使用锁的用户线程出错时,watchdog也需要停止自动续约以防其他的客户端无法再次获得锁
- watchdog应当只对用户未主动设置lock_timeout的锁进行自动续约,而对用户已经设置了该参数的锁不进行自动续约,这样从用户的使用角度来讲更加明晰。
其中第1点和第2点更为重要,第3点更多是锁管理器需要关心的事情而非watchdog本身该care的原则,由于我在开发watchdog的过程中重构了aioredlock的锁管理器,所以把这点也放在这里。
Watchdog的实现
基于上述的设计原则,协程是非常好的watchdog实现选型。watchdog协程与用户的工作协程处在同一个线程,当用户的工作协程出问题之后,该线程报错,进而也就终止了watchdog的工作,那么watchdog就不会再去自动续约,那么锁在一段时间之后就会自动过期。话不多说,直接上代码(加了注释,比较好读)。
当加锁的时候,如果用户没有对锁设置过期时间(lock_timeout), 则设置一个默认的internal_lock_timeout, 同时为该锁分配一个watchdog,加入到事件循环中。
#代码有删减
加入事件循环的是_auto_extend()这个任务。该协程每隔0.6*internal_lock_tiemout之后尝试延长锁的lifetime,完成后再把自己加入到事件循环中等待下一次执行。
async 当释放锁的时候,如果该锁被分配了watchdog,则不仅需要删除掉Redis上的锁,同时还需要取消掉锁的watchdog,这样其他的客户端就可以再次顺利申请到该锁。
async 主体的核心实现就是这些,很简单易懂,只需要代码写的周全一点就都没什么问题。接下来回到上面那张作者大呼黑魔法的图片,这实际上是我在测试unlock函数的时候使用的一些技巧。
问题说明
在上述的unlock函数中,我需要测试的是异常捕获这部分的代码,我的核心诉求就是要让await fut这里出错来覆盖执行下面的log输出语句。
# 取消掉锁的看门狗
当我们执行一个Task.cancel()之后,该协程并不会立刻取消,只是在标记了该协程需要被取消,标记self._must_cancel = True
def 当该协程下次被调度运行的时候,当检查到self._must_cancel为True时,就会raise CancelledError异常。另外需要注意的是,如果一个协程已经运行完成了,还对该协程await的话,就会raise InvalidStateError。
def 而我们的需求是需要一个正在事件队列中pending且本该正常运行结束的协程非正常结束,同时raise的异常不是CancelledError。那我们该怎么做呢?
栈帧操作(最有趣的部分!!)
在Python虚拟机的文章中,我们介绍到虚拟机中函数的执行环境是保存在PyFrameObject中的。
大龙:Python线程、协程探究(终篇)—python虚拟机是如何保存协程的执行环境的zhuanlan.zhihu.com
我们再来看看PyFrameObject的定义,在这个结构体中保存了关于这个协程执行的所有信息,包括协程的调用者栈帧指针(f_back)、协程的函数代码(f_code),协程的全局变量(f_globals)以及局部变量(f_locals)以及上一条执行的字节码在CodeObject中的偏移位置(f_code, 相当于操作系统在执行代码时的PC_Count)。
typedef 如果我们能拿到一个协程对象的PyFrameObject,我们可以对这个协程为所欲为。比如,我们可以重置f_lasti = 0来让协程从头重新开始执行,我们甚至还可以修改协程的函数代码*f_code,来让协程下次被调度时完全执行另一个代码,我们还可以强行清除掉局部变量,这样当协程再次被调度执行时,访问一些局部变量时就会报错等等等等。幸运的是,尽管PyFrameObject对象是一个用于Python虚拟机实现的极为隐秘的内部对象,但Python还是提供了某种途径来访问到PyFrameObject对象。在Python中,有一种frame object,他是对C一级的PyFrameObject的包装。同时Python提供了一种方法来方便的获得当前处于活动状态的frame object。这个方法就是sys module中的_get_frame方法。
在asyncio中,对于每个task,也给我们了一个接口来获取到每个task的PyFrameObject,即get_stack()接口,该接口返回某个task的栈帧队列。
def 我们看Python的frame对象文档, 几乎和C的PyFrameObject一致。只不过不幸的是,我们没法做那些为所欲为的操作,因为这些field是readonly的。
class 但是又比较幸运的是,他提供了一个操作栈帧的接口:clear(). clear()操作就是清除掉绝大部分的协程执行期间的引用,因为我们知道Python里所有都是引用。如果我们调用了这个接口,那么该栈帧中的绝大部分全局变量和所有的局部变量会被删除掉。
我们来看这样一段代码:首先获得一个协程的栈帧,然后打印栈帧中的所有局部变量值,接着我们清空栈帧,最后再次打印局部变量值。从输出结果中我们可以看出当调用auto_frame之后,协程栈中的局部变量全部被清除了。那么当下次协程被调用时,如果引用其中的某个局部变量,就会因为该局部变量没有定义而报错。
auto_frame 所以在测试unlock的时候,我只需要在事件队列中定位到watchdog对应的task,获得协程的栈帧对象,然后强行清空栈帧,那么下次该Task被调度执行时就自然会报错了。这就好比,为了让一辆在高速路上正常行驶的车坏掉, 我们乘着司机下车休息的时候,把车的方向盘、邮箱、轮胎等全部卸了,这样等司机再次准备开车出发时,发现车上的部件一个都没了,于是司机就原地报错。比较有意思的是,这个测试想法是我在去实验室的路上突然想到的,想到这个解决方案的时候,脑海里浮现的一个词是偷天换日。
总结
本篇文章就是完完全全的技术实现贴,讲了watchdog的设计原则,基于协程的watchdog实现以及关于协程栈帧的骚气操作。最后一部分是我个人觉得最有趣的内容,如果大家对此有进一步了解的兴趣,强烈推荐陈儒写的《Python源码剖析》,这本书写于2008年,至今已有12年之久,Python的语法糖和特性在这12年期间增加了很多,但是底层的细节变动很小。陈儒的这本书是我目前看过的最硬核,最实在的Python语言剖析书,非常适合做平常的资料查阅使用。最后希望上面的内容对大家有所帮助或者有所启发,从下篇开始,我们要正式的进入集群的相关技术内容分析了,感兴趣的话,可以考虑订阅我的专栏~
Python源码剖析 (豆瓣)book.douban.com

