
AI又炸了!照片+声音就能出视频,阿里让Sora女主唱歌小李子说rap?
赞
踩
衡宇 梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
Sora之后,居然还有新的AI视频模型,能惊艳得大家狂转狂赞!

有了它,《狂飙》大反派高启强化身罗翔,都能给大伙儿普法啦(狗头)。
这就是阿里最新推出的基于音频驱动的肖像视频生成框架,EMO(Emote Portrait Alive)。
有了它,输入单张参考图像,以及一段音频(说话、唱歌、rap均可),就能生成表情生动的AI视频。视频最终长度,取决于输入音频的长度。
你可以让蒙娜丽莎——这位AI届效果体验的老选手,朗诵一段独白:
年轻俊美的小李子来段快节奏的rap才艺秀,嘴形跟上完全没问题:
甚至粤语口型也能hold住,这就让哥哥张国荣来首陈奕迅的《无条件》:
总之,不管是让肖像唱歌(不同风格的肖像和歌曲)、让肖像开口说话(不同语种)、还是各种“张冠李戴”的跨演员表演,EMO的效果,都让咱看得一愣一愣的。
网友大感叹:“我们正在走进一个新的现实!”
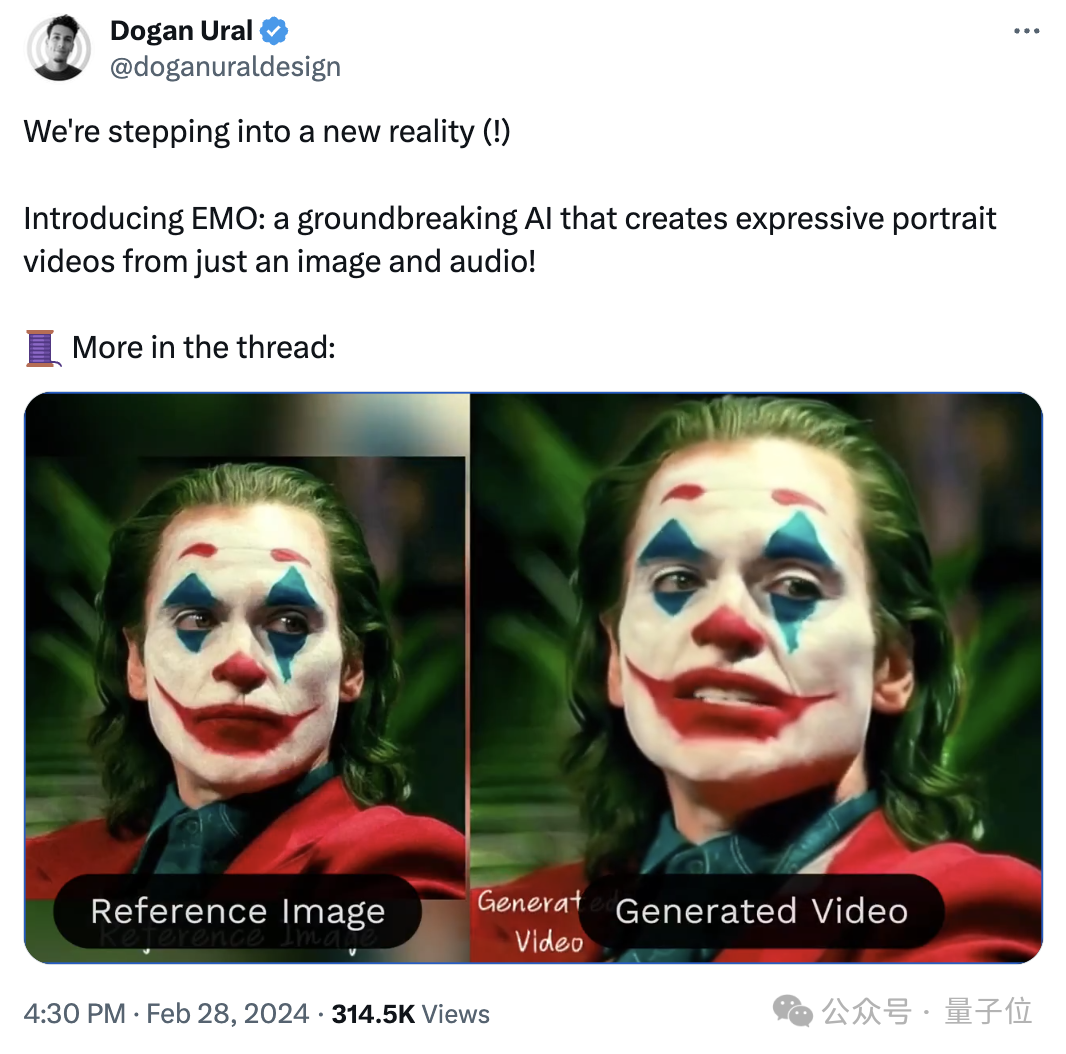
(2019版《小丑》说2008版《蝙蝠侠黑暗骑士》的台词)
甚至已经有网友开始对EMO生成视频开始了拉片,逐帧分析效果究竟怎么样。
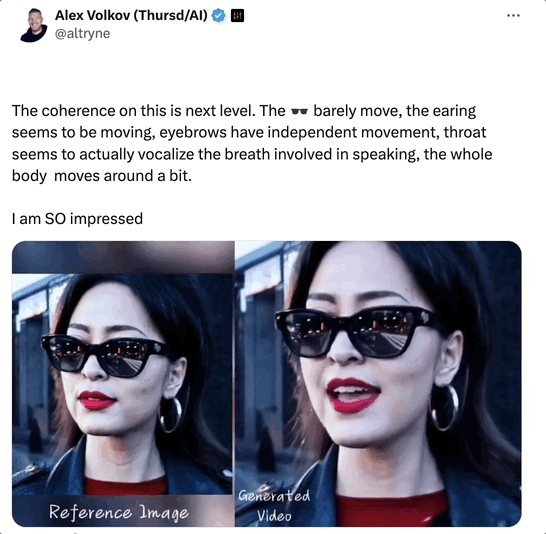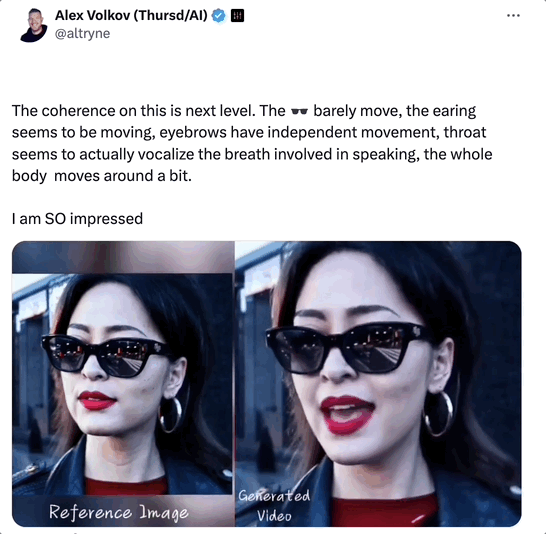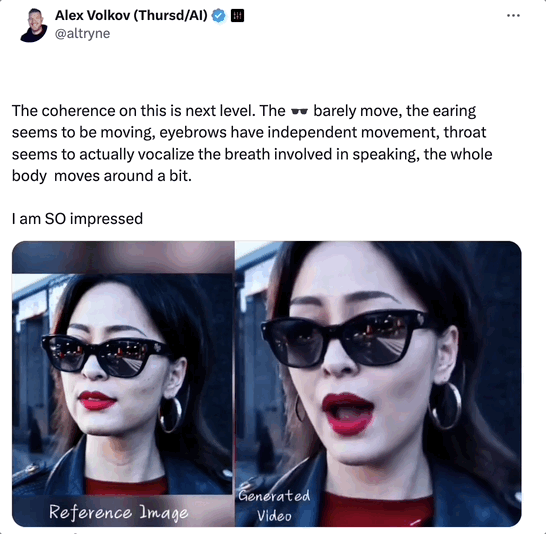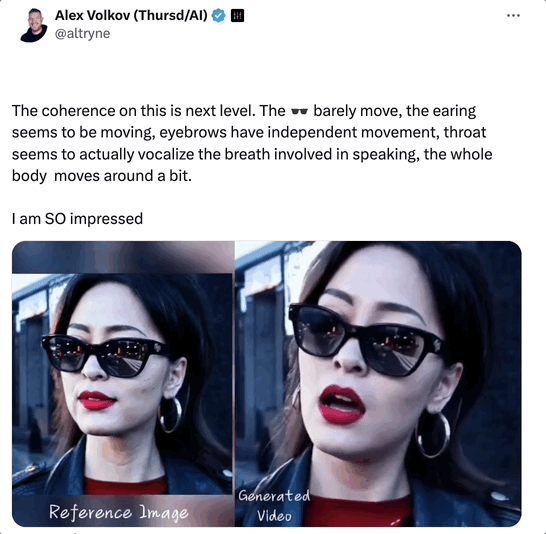
如下面这段视频,主角是Sora生成的AI女士,本次为大家演唱的曲目是《Don’t Start Now》。
推友分析道:
这段视频的一致性,比以往更上一层楼了!
一分多钟的视频里,Sora女士脸上的墨镜几乎没有乱动,耳朵、眉毛都有独立的运动。
最精彩的是Sora女士的喉咙好像真的有呼吸哎!她唱歌的过程中身体还有微颤和移动,我直接大震惊!
话说回来,EMO是热门新技术嘛,免不了拿来与同类对比——
就在昨天,AI视频生成公司Pika也推出了为视频人物配音,同时“对口型”的唇形同步功能,撞车了。
评论区网友对比过后得出的结论是,被阿里吊打了。
EMO公布论文,同时宣布开源。
但是!虽说开源,GitHub上仍然是空仓。
再但是!虽然是空仓,标星数已经超过了2.1k。
惹得网友们真的是好着急,有吉吉国王那么急。
与Sora不同架构
EMO论文一出,圈内不少人松了口气。
它与Sora技术路线不同,说明复刻Sora不是唯一的路。
EMO并不是建立在类似DiT架构的基础上,也就是没有用Transformer去替代传统UNet,其骨干网络魔改自Stable Diffusion 1.5。
具体来说,EMO是一种富有表现力的音频驱动的肖像视频生成框架,可以根据输入视频的长度生成任何持续时间的视频。
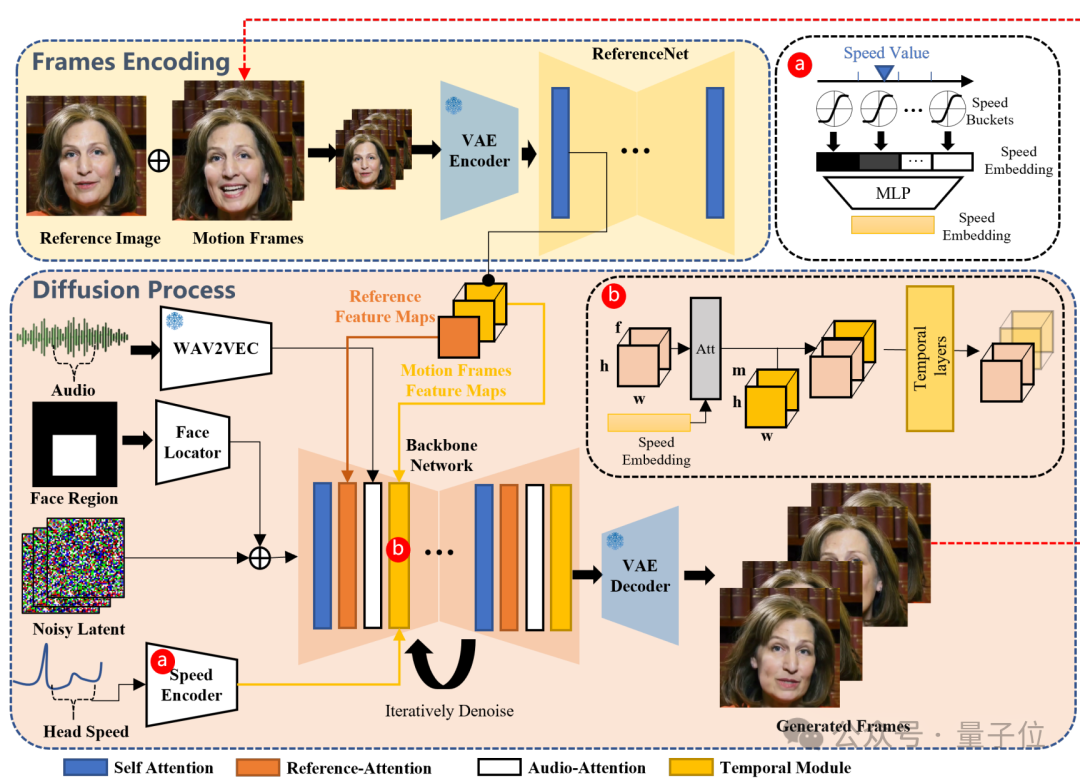
该框架主要由两个阶段构成:
帧编码阶段
部署一个称为ReferenceNet的UNet网络,负责从参考图像和视频的帧中提取特征。
扩散阶段
首先,预训练的音频编码器处理音频嵌入,人脸区域掩模与多帧噪声相结合来控制人脸图像的生成。
随后是骨干网络主导去噪操作。在骨干网络中应用了两种注意力,参考注意力和音频注意力,分别作用于保持角色的身份一致性和调节角色的运动。
此外,时间模块被用来操纵的时间维度,并调整运动的速度。
在训练数据方面,团队构建了一个包含超过250小时视频和超过1500万张图像的庞大且多样化的音视频数据集。
最终实现的具体特性如下:
可以根据输入音频生成任意持续时间的视频,同时保证角色身份一致性(演示中给出的最长单个视频为1分49秒)。
支持各种语言的交谈与唱歌(演示中包括普通话、广东话、英语、日语、韩语
支持不同画风(照片、传统绘画、漫画、3D渲染、AI数字人)

在定量比较上也比之前的方法有较大提升取得SOTA,只在衡量口型同步质量的SyncNet指标上稍逊一筹。
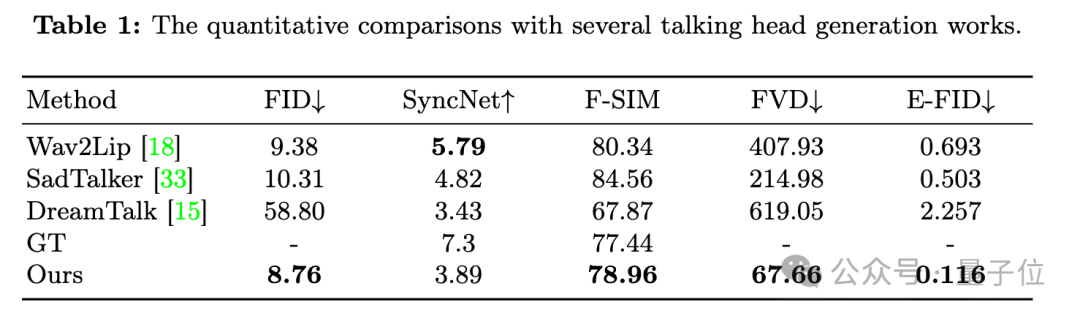
与其他不依赖扩散模型的方法相比,EMO更耗时。
并且由于没有使用任何显式的控制信号,可能导致无意中生成手等其他身体部位,一个潜在解决方案是采用专门用于身体部位的控制信号。
EMO的团队
最后,来看看EMO背后的团队有那些人。
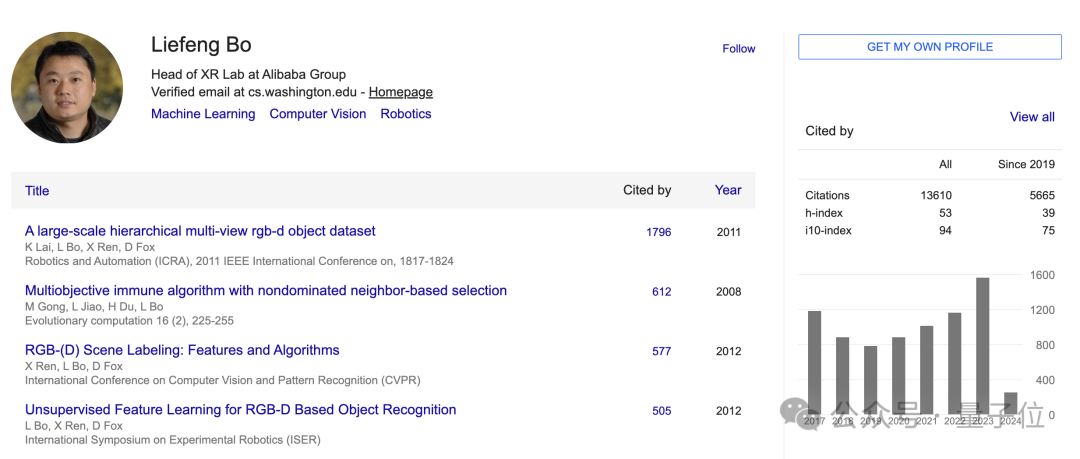
论文显示,EMO团队来自阿里巴巴智能计算研究院。
作者共四位,分别是Linrui Tian,Qi Wang,Bang Zhang和Liefeng Bo。

其中,薄列峰(Liefeng Bo),是目前的阿里巴巴通义实验室XR实验室负责人。
薄列锋博士毕业于西安电子科技大学,先后在芝加哥大学丰田研究院和华盛顿大学从事博士后研究,研究方向主要是ML、CV和机器人。其谷歌学术被引数超过13000。
在加入阿里前,他先是在亚马逊西雅图总部任首席科学家,后又加入京东数字科技集团AI实验室任首席科学家。
2022年9月,薄列峰加入阿里。
EMO已经不是第一次阿里在AIGC领域出圈的成果了。
有AI一键换装的OutfitAnyone。

还有让全世界小猫小狗都在跳洗澡舞的AnimateAnyone。
就是下面这个:

如今推出EMO,不少网友在感叹,阿里是有些技术积累在身上的。

如果现在把所有这些技术结合起来,那效果……
不敢想,但好期待。

总之,我们离“发给AI一个剧本,输出整部电影”越来越近了。

One More Thing
Sora,代表文本驱动的视频合成的断崖式突破。
EMO,也代表音频驱动的视频合成一个新高度。
两者尽管任务不同、具体架构不同,但还有一个重要的共性:
中间都没有加入显式的物理模型,却都在一定程度上模拟了物理规律。
因此有人认为,这与Lecun坚持的“通过生成像素来为动作建模世界是浪费且注定要失败的”观点相悖,更支持了Jim Fan的“数据驱动的世界模型”思想。

过去种种方法失败了,而现在的成功,可能真就来自还是强化学习之父Sutton的《苦涩的教训》,大力出奇迹。
让AI能够像人们一样去发现,而不是包含人们发现的内容
突破性的进展最终通过扩大计算规模来实现
论文:
https://arxiv.org/pdf/2402.17485.pdf
GitHub:
https://github.com/HumanAIGC/EMO
参考链接:
[1]https://x.com/swyx/status/1762957305401004061
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

