
- 130个Kafka常见错误小集合_kafka无法查看topic报错
- 22022 nature machine intelligence | GLAM: An adaptive graph learning method for automated molecular i
- 32024年Python最全python模块pymysql对数据库进行增删改查_python操作数据库实现增删改查
- 4智能优化算法——灰狼优化算法(Python&Matlab实现)_灰狼算法
- 5Error running app: This version of Android Studio is incompatible with the Gradle Plugin used. Try d_he project uses gradle version which is incompatib
- 6com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure_jdbc4 communication failure
- 7appinum1.15 + python3 + iOS 环境搭建_appinum ios
- 8pikachu靶场之XSS漏洞测试_pikachu靶场xss
- 9使用群晖docker将小爱音箱接入chatgpt_小爱接入chatgpt
- 10从零开始如何学习人工智能?
YOLO目标检测综述(2024.6月最新!)_目标检测 综述
赞
踩
1 基本概念
目标检测(Object Detection)是计算机视觉领域的重要任务之一,旨在识别图像或视频中的特定目标并将其位置标记出来。与图像分类任务不同,目标检测要求不仅能够识别目标类别,还需要精确地定位目标的位置。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。

2 发展历史
目标检测技术的发展历史可以追溯到20世纪80年代。在早期阶段,目标检测主要依赖于手工设计的特征提取算法和分类器。这些方法通常基于边缘、纹理、颜色等低级特征,并结合模板匹配或统计模型进行目标检测。然而,这些方法受限于特征的表达能力和鲁棒性,对于复杂场景的检测效果较差。
随着计算机视觉和机器学习的快速发展,基于机器学习的目标检测方法逐渐兴起。其中,主要的突破之一是提出了基于特征的机器学习方法,如Haar特征和HOG特征。这些方法通过训练分类器来学习目标的特征表示,从而实现目标的检测。然而,这些方法仍然需要手动设计特征,并且对于复杂的目标来说,特征的表示能力较弱。
近年来,深度学习的兴起极大地推动了目标检测技术的发展。基于深度学习的目标检测方法将深度神经网络引入目标检测领域,并取得了重大突破。最具代表性的方法之一是基于区域的卷积神经网络(R-CNN),它将目标检测任务分解为候选区域提取和区域分类两个子任务。后续的方法,如Fast R-CNN、Faster R-CNN和YOLO(You Only Look Once)等进一步改进了速度和准确性。这些方法不仅能够自动学习特征表示,还能够在端到端的框架下进行目标检测。
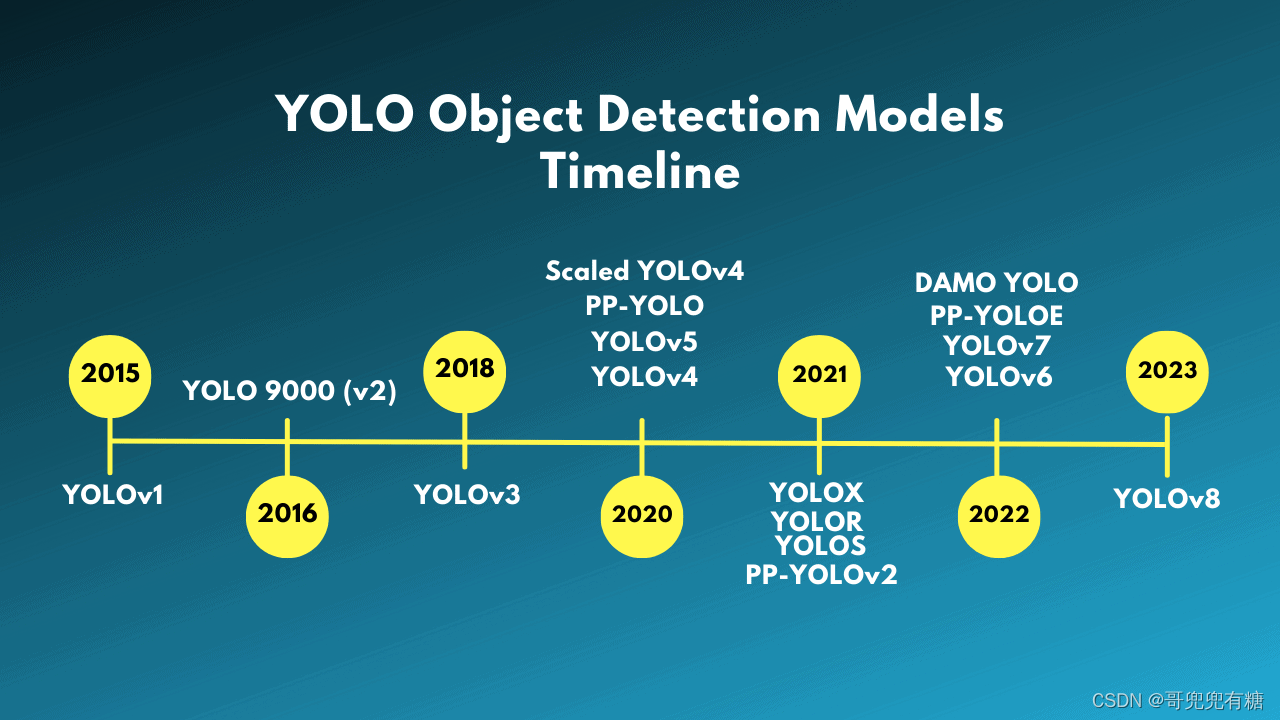
YOLO(You Only Look Once)是一种对象检测算法,由Joseph Redmon等人于2015年提出。YOLO的核心思想是将对象检测任务转化为一个回归问题,通过一个卷积神经网络直接在图像上进行推理,实现实时对象检测。
YOLO的发展历程可以分为以下几个阶段:
YOLO v1:YOLO的第一个版本是在2015年提出的,它采用了一个全卷积神经网络,将输入图像分为S×S个网格,每个网格预测B个边界框和各自边界框的类别概率。然后,通过阈值筛选和非极大值抑制(NMS)来获得最终的检测结果。YOLO v1在速度和准确率上取得了很大的突破,但对小目标和近似目标的检测效果较差。

YOLOv5是由Ultralytics团队在2020年开发的。YOLOv5相比于之前的版本在精度和速度上都有显著提升。它采用了一种轻量化的结构,包括多个不同大小的卷积层和池化层,用于提取图像特征。与以往的版本相比,YOLOv5引入了新的网络架构,以及一种新的训练方法,使用更大的数据集和更长的训练时间,从而提高了算法的性能。
YOLOv8 是由 Ultralytics 公司在2023年1月发布的最新一代实时目标检测模型。YOLOv8 采用了先进的骨干网络和颈部架构,实现了改进的特征提取和目标检测性能。它采用了无锚点的分割 Ultralytics 头部设计,这有助于提高准确性并使检测过程更加高效。YOLOv8 还专注于在准确性和速度之间保持最佳平衡,适合于不同应用领域的实时目标检测任务。此外,YOLOv8 提供了一系列预训练模型,以满足不同任务和性能要求,使得用户可以根据自己的具体用例找到合适的模型。

YOLOv9 由中国台湾 Academia Sinica、台北科技大学等机构联合开发。YOLOv9引入了程序化梯度信息(Programmable Gradient Information, PGI),这是一种全新的概念,旨在解决深层网络中信息丢失的问题。传统的目标检测网络在传递深层信息时,往往会丢失对最终预测至关重要的细节,而PGI技术能够保证网络在学习过程中保持完整的输入信息,从而获得更可靠的梯度信息,提高权重更新的准确性。这一创新显著提高了目标检测的准确率,为实时高精度目标检测提供了可能。此外,YOLOv9采用了全新的网络架构——泛化高效层聚合网络(Generalized Efficient Layer Aggregation Network, GELAN)。GELAN通过梯度路径规划,优化了网络结构,利用传统的卷积操作符实现了超越当前最先进方法(包括基于深度卷积的方法)的参数利用效率。这一设计不仅提高了模型的性能,同时也保证了模型的高效性,使YOLOv9能够在保持轻量级的同时,达到前所未有的准确度和速度。
论文地址:https://arxiv.org/abs/2402.13616
Yolov9源代码:https://github.com/WongKinYiu/yolov9
YOLOv10是清华大学的研究人员在Ultralytics的基础上,引入了一种新的实时目标检测方法,解决了YOLO 以前版本在后处理和模型架构方面的不足。通过消除非最大抑制(NMS)和优化各种模型组件,YOLOv10 在显著降低计算开销的同时实现了最先进的性能。大量实验证明,YOLOv10 在多个模型尺度上实现了卓越的精度-延迟权衡。
YOLOv10 的结构建立在以前YOLO 模型的基础上,同时引入了几项关键创新。模型架构由以下部分组成:
主干网络:YOLOv10 中的主干网络负责特征提取,它使用了增强版的 CSPNet(跨阶段部分网络),以改善梯度流并减少计算冗余。
颈部网络:颈部设计用于汇聚不同尺度的特征,并将其传递到头部。它包括 PAN(路径聚合网络)层,可实现有效的多尺度特征融合。
一对多头:在训练过程中为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性。
一对一头:在推理过程中为每个对象生成一个最佳预测,无需 NMS,从而减少延迟并提高效率。
论文:https://arxiv.org/pdf/2405.14458
源码: GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
目前,目标检测技术仍在不断发展。一方面,研究者们致力于提高目标检测的准确性和效率。另一方面,一些新的方向也在探索中,如目标实例分割、多目标跟踪等。可以预见,随着技术的不断进步,目标检测技术将在更广泛的应用领域中发挥更大的作用。
3 目标检测四大任务
-
分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
-
定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
-
检测-Detection:解决“是什么?在哪里?”的问题,即定位出这个目标的的位置并且知道目标物是什么。
-
分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。

目标检测任务可分为两个关键的子任务:目标分类和目标定位。目标分类任务负责判断输入图像或所选择图像区域(Proposals)中是否有感兴趣类别的物体出现,输出一系列带分数的标签表明感兴趣类别的物体出现在输入图像或所选择图像区域(Proposals)中的可能性。目标定位任务负责确定输入图像或所选择图像区域(Proposals)中感兴趣类别的物体的位置和范围,输出物体的包围盒、或物体中心、或物体的闭合边界等,通常使用方形包围盒,即Bounding Box用来表示物体的位置信息。
4 目标检测算法的分类
目前主流的目标检测算法主要是基于深度学习模型,大概可以分成两大类别:
(1)One-Stage(单阶段)目标检测算法,这类检测算法不需要Region Proposal阶段,可以通过一个Stage直接产生物体的类别概率和位置坐标值,比较典型的算法有YOLO、SSD和CornerNet;One-Stage目标检测算法可以在一个stage直接产生物体的类别概率和位置坐标值,相比于Two-Stage的目标检测算法不需要Region Proposal阶段,整体流程较为简单。如下图所示,在Testing的时候输入图片通过CNN网络产生输出,解码(后处理)生成对应检测框即可;在Training的时候则需要将Ground Truth编码成CNN输出对应的格式以便计算对应损失loss。

目前对于One-Stage算法的主要创新主要集中在如何设计CNN结构、如何构建网络目标以及如何设计损失函数上。
(2)Two-Stage(双阶段)目标检测算法,这类检测算法将检测问题划分为两个阶段,第一个阶段首先产生候选区域(Region Proposals),包含目标大概的位置信息,然后第二个阶段对候选区域进行分类和位置精修,这类算法的典型代表有R-CNN,Fast R-CNN,Faster R-CNN等。目标检测模型的主要性能指标是检测准确度和速度,其中准确度主要考虑物体的定位以及分类准确度。一般情况下,Two-Stage算法在准确度上有优势,而One-Stage算法在速度上有优势。不过,随着研究的发展,两类算法都在两个方面做改进,均能在准确度以及速度上取得较好的结果。
Two-Stage目标检测算法流程如下图所示,在Testing的时候输入图片经过卷积神经网络产生第一阶段输出,对输出进行解码处理生成候选区域,然后获取对应候选区域的特征表示(ROIs),然后对ROIs进一步精化产生第二阶段的输出,解码(后处理)生成最终结果,解码生成对应检测框即可;在Training的时候需要将Ground Truth编码成CNN输出对应的格式以便计算对应损失loss。


