
热门标签
热门文章
- 1stremlit学习前骤_streamlit需要什么编译器
- 2AI 模型量化格式介绍,LangChain Agent 原理解析,HugggingFace 推理 API、推理端点和推理空间使用介绍_huggingface 量化格式
- 3深度学习实践1-----文献复现_深度对接 文献复现
- 4so库生成和用法汇总
- 52024体育赛事一波接一波,大学生借IKCEST国际大数据竞赛打造AI“嘴强”主播
- 62024最新字节跳动技术五面(刚拿Offer):一面+主管二面+总监三四面+HR五面_字节五面
- 7Django REST framework安全实践:轻松实现认证、权限与限流功能_django 限流开关
- 84.1.5 Flink-流处理框架-HA-Flink集群环境搭建(Standalone模式)_flink ha部署
- 9输入PM2.5的值,判断空气质量_编写函数实现空气质量提醒 (0<=pm2.5值<35,输出“空气优质,快去户外运动!”; 35<=p
- 1011.1JavaEE——Spring MVC的核心类和注解(一)DispatcherServlet
当前位置: article > 正文
昇思25天学习打卡营第12天|基于MindNLP+MusicGen生成自己的个性化音乐
作者:运维做开发 | 2024-07-04 21:01:01
赞
踩
昇思25天学习打卡营第12天|基于MindNLP+MusicGen生成自己的个性化音乐
课程打卡凭证

MusicGen模型
MusicGen是由Meta推出的一个开源人工智能音乐模型,该模型允许用户通过文本描述来生成音乐,详见https://arxiv.org/abs/2306.05284。
MusicGen采用基于Transformer的语言模型架构,可以同时处理多个压缩的离散音乐表示(即token),并通过一种有效的token交错模式提高了生成效率和质量。它利用Meta公司开发的EnCodec神经音频压缩技术,将音乐从高采样率压缩到低采样率以减小计算量,同时保持高保真度重建。为了改进音频质量,MusicGen还采用了多频带扩散解码器,该解码器通过独立生成频谱的不同部分来避免低频误差对高频的影响。
下载模型

生成音乐
MusicGen模型支持贪心(greedy)和采样(sampling)两种模式,采样模式要显著优于贪心模式,因此这里均采用采样模式。
无提示生成
这种方式可以让系统根据输入的信息和算法内部的模型来创作音乐,而无需具体的指令或提示。

使用sicpy库将输出的数据转换成.wav音频文件保存。

计算生成的音频样本的长度(单位为秒)。

文本提示生成
使用自然语言描述希望音乐具有的情感、风格、节奏或其他特征,MindNLP会分析和理解文本提示,提取关键信息如情感、节奏、风格等,MusicGen根据MindNLP提供的信息来生成符合描述的音乐。

音频提示生成
首先,将音频文件转换为文本描述或音频特征向量,然后将处理后的音频数据表示为模型可以处理的形式,最后再使用预训练的音乐生成模型来生成音乐。
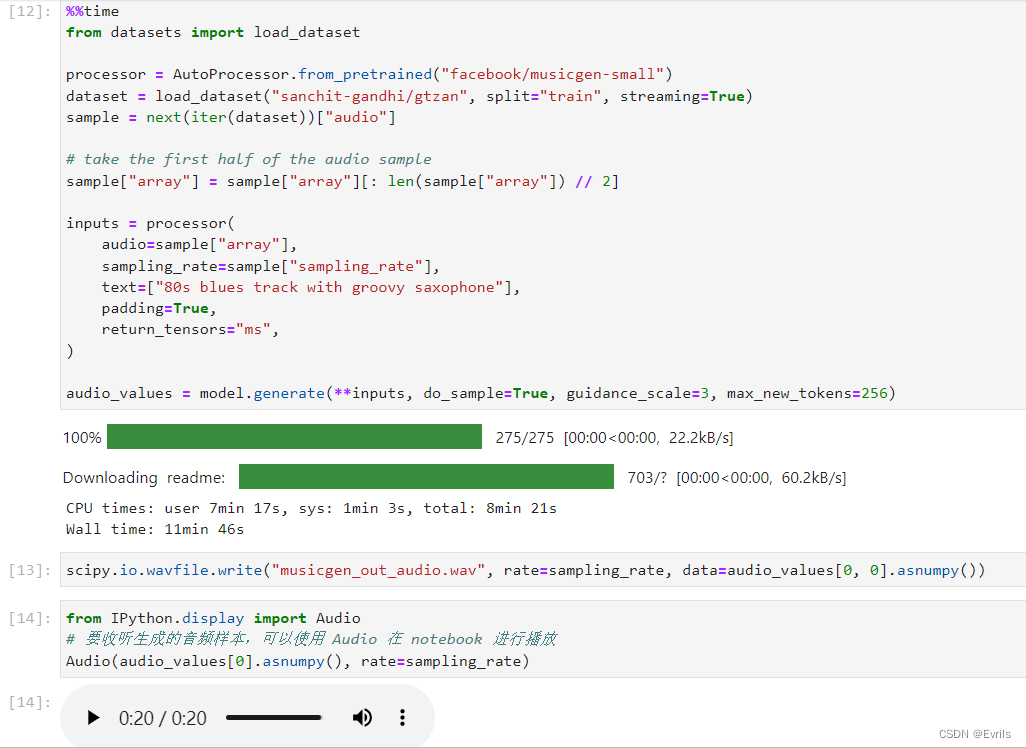
如图演示了如何结合音频和文本提示来生成个性化音乐。

生成配置
显示模型的默认参数。

修改默认参数。

重新生成模型。

声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

