
- 1【算法题】编辑距离(动态规划),一文彻底弄懂!
- 2HDFS知识点_块大小及组成文件的块
- 3【git】git rebase详解_git rebase --hard
- 4技术分享 | 关于 MySQL 自增 ID 的事儿_mysql 分区表 自增id间隔是8
- 5制作img文件
- 6Vision Transformer详解(附代码)
- 7SwiftUI 如何隐藏和显示 NavigationView 侧边栏?_swift-ui ipad侧边栏状态
- 8自己动手实现JSON解析_自建json视频解析接口
- 9DFS和BFS_bfs和dfs
- 10springboot对接kafka启动报错ICMP Port Unreachable_javax.security.auth.login.loginexception: icmp por
如何评估大模型音频理解能力-从Gemini说起_大模型如何理解声音
赞
踩
Gemini家族包含Ultra、Pro和Nano三种大小的模型是谷歌开发的大型多模态人工智能模型,它在人工智能的多模态领域实现了重大突破,结合了语言、图像、音频和视频的理解能力。
Gemini的性能评估情况如下:
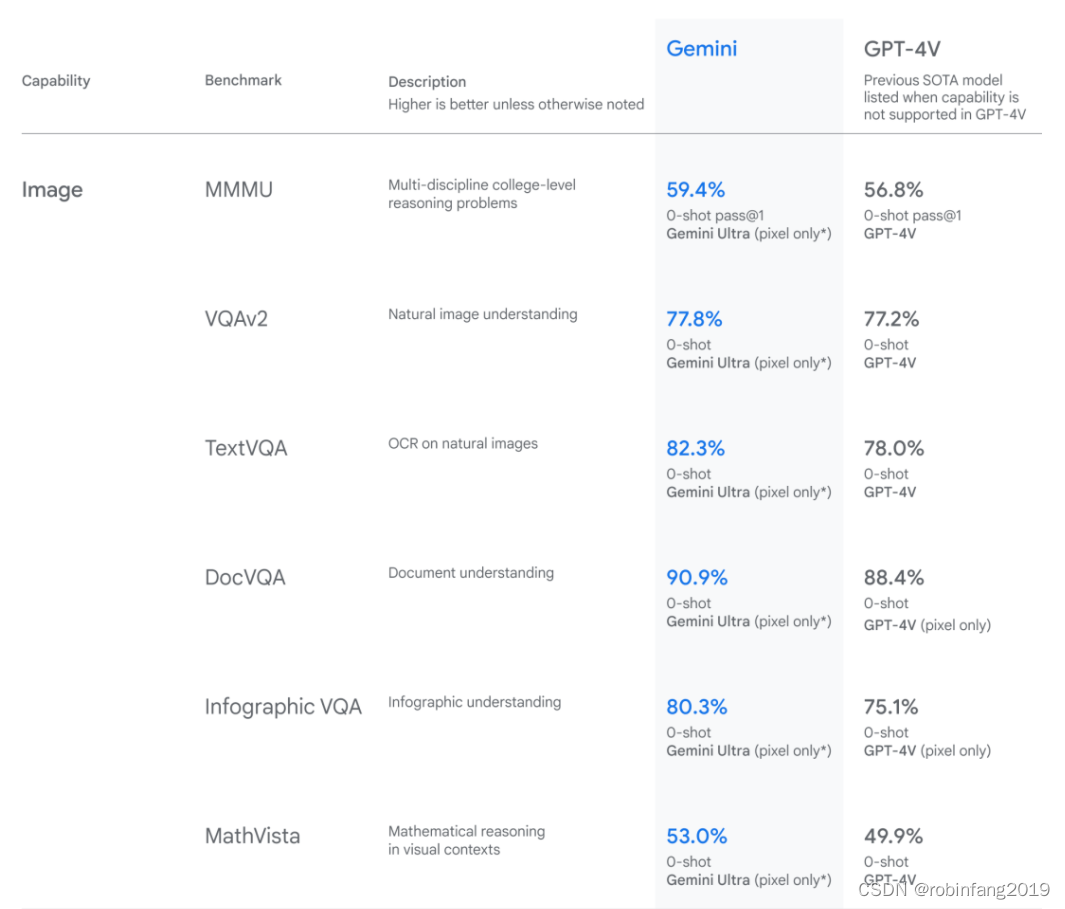
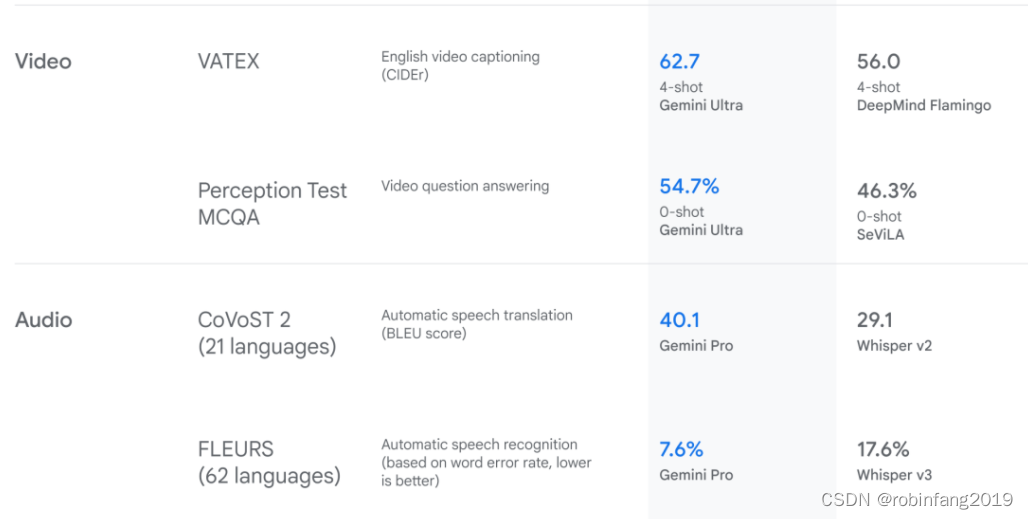
Gemini模型的评估的具体指标从文本理解能力、图像理解能力、音频理解能力、多模态能力四个维度进行测试。评估具体指标核心之一就是选择基准测试集。选择基准测试集时,我们会从几个关键因素做选择,如数据覆盖范围、数据质量和规模、评价指标和评价指标。
1、Gemini模型的评估的具体指标
1.1 文本理解能力
学术基准测试:包括MMLU、GSM8K、Math、BIG-Bench等文本理解和推理基准测试。
长文本理解:涵盖NarrativeQA、Scrolls等长文本理解基准测试。
数学/科学理解:包括GSM8K、Math、MMLU等数学和科学知识理解基准测试。
推理能力:包括BigBench Hard、CLRS等推理能力基准测试。
摘要能力:涵盖XL Sum、WikiLingua等摘要生成基准测试。
多语言能力:包括WMT23、WikiLingua等机器翻译和多语言摘要生成基准测试。
1.2 图像理解能力
对象识别:包括VQAv2、TextVQA等图像和文档的文本理解基准测试。
细节识别:涵盖DocVQA、ChartQA等细节识别基准测试。
图表理解:包括MathVista、AI2D等图表理解基准测试。
跨语言图像理解:包括XM-3600等跨语言图像理解基准测试。
1.3 视频理解能力
视频问答:涵盖VATEX、YouCook2、NextQA等视频问答基准测试。
视频推理:包括ActivityNet-QA、Perception Test MCQA等视频推理基准测试。
1.4 音频理解能力
语音识别:包括FLEURS、VoxPopuli、Librispeech等语音识别基准测试。
语音翻译:涵盖CoVoST 2等语音翻译基准测试。
1.5 多模态能力
跨模态推理:涵盖MMMU、AI2D等跨模态推理基准测试。
图像生成:涵盖图像生成基准测试。
视频理解:涵盖视频理解基准测试。
音频理解:涵盖音频理解基准测试。
跨模态组合推理:涵盖多模态推理基准测试。
2、语音识别领域三大基准测试集
在语音识别领域,FLEURS、VoxPopuli和Librispeech是几个重要的基准测试集,用于评估语音识别系统的性能。
2.1 FLEURS
FLEURS(Few-shot Learning Evaluation of Universal Representations of Speech)基准测试集是一个用于评估和推动低资源语言语音理解研究的多语言语音数据集,由Alexis Conneau等人创建,并在arXiv上发表相关论文。它旨在鼓励在更多语言中发展语音技术,以实现更广泛的语音识别和语音翻译技术的普及。
主要特点:
多语言覆盖:FLEURS包含102种语言,提供了大约12小时的有监督语音数据支持每种语言,这为研究者提供了足够的数据来训练和评估多语言语音识别模型。
任务多样性:FLEURS可以用于多种语音相关的任务,包括自动语音识别(ASR)、语音语言识别(Speech LangID)、翻译和检索。
数据集构建:FLEURS是基于机器翻译的FLoRes-101基准测试构建的,它使用了来自FLoRes公开可用的dev和devtest数据集中的多对多平行句子。
2.2 VoxPopuli
VoxPopuli是由Facebook AI(现为Meta AI)开源的大规模多语言语音数据集,旨在推动语音识别、表示学习、半监督学习以及同声传译等领域的研究。数据集可通过GitHub仓库获取,其中包含了下载脚本和使用指南。
主要特点:
数据集规模和多样性:VoxPopuli提供了23种语言的100,000小时未标记语音数据,以及1,800小时的转录演讲和它们对15种目标语言的口译,总计达到17,300小时。
数据来源:VoxPopuli的数据来源于2009-2020年间欧洲议会的事件录音,包括全体会议、委员会会议等。这些录音包括了来自不同欧盟语言的演讲,并被部分转录和口译。
数据处理:为了提高数据质量,VoxPopuli的创建者们构建了数据处理流程,包括使用基于能量的语音活动检测(VAD)算法将长录音分割成15-30秒的短片段,并去除连续沉默超过2秒的片段。
数据集应用:VoxPopuli不仅适用于自动语音识别(ASR)任务,还适用于语言模型训练、半监督学习以及语音到文本的翻译任务。
预训练模型:Facebook AI还提供了基于VoxPopuli数据训练的预训练wav2vec 2.0模型,这些模型可以用于下游语音任务。
下载:https://github.com/facebookresearch/voxpopuli
2.3 Librispeech
LibriSpeech是一个用于评估英语语音识别性能的开源数据集,它包含了约1000小时的16kHz采样率的有声读物录音。这个数据集被广泛用于训练和评估自动语音识别(ASR)系统的性能。
主要特点:
数据集规模:LibriSpeech数据集规模庞大,提供了充足的数据用于深度学习模型的训练和测试。
数据分集:LibriSpeech数据集通常被分为多个子集,包括训练集(train-clean-100, train-clean-360, train-other-500)、开发集(dev-clean, dev-other)和测试集(test-clean, test-other)。这些子集根据录音的质量和来源进行了区分。
测试集特点:
test-clean:此测试集包含了清晰度较高的说话人的录音,用于评估ASR系统在理想或较为理想条件下的性能。
test-other:相比test-clean,此测试集包含了更多不同背景和录音条件下的语音数据,用于评估ASR系统在更广泛或更具有挑战性的场景下的性能。
数据格式:LibriSpeech数据集中的音频文件通常以flac格式存储,同时提供对应的文本文件(.trans.txt),其中包含了音频内容的转录文本。
数据预处理:在使用LibriSpeech数据集进行ASR任务之前,需要进行数据预处理,包括将音频文件转换成适合模型输入的特征表示,如梅尔频率倒谱系数(MFCC)等。
使用工具:LibriSpeech数据集可以与多种工具和库一起使用,例如TensorFlow Datasets、Torchaudio等,这些工具提供了方便的数据加载和管理功能。

