
- 1程序员入门培训班多少钱?可以学到哪些东西?_程序员培训班要多少钱
- 2jwt 介绍_怎么查看一个浏览器网页的jwt
- 32021年危险化学品生产单位安全生产管理人员考试题库及危险化学品生产单位安全生产管理人员考试内容_人体是导体,在静电场中可能接触起电
- 4Vivado工程经验与时序收敛技巧_vivado fix cell
- 5算法——动态规划_完全加括号是什么意思
- 6git代码库迁移保留commit历史_Git 如何迁移仓库并保留 commit 记录
- 7RK3328 Debian安装OpenMediaVault
- 8git 拉取代码时显示Filename too long的解决办法_git file name too long
- 9系统盘50G,数据盘100G(需求:将数据磁盘扩容至1T)_系统盘和数据盘配比
- 10WooCommerce入门指南:简介
万字逐行解析与实现Transformer,并进行德译英实战(一)_基于tranformer的德翻译
赞
踩
本文由于长度限制,共分为三篇:
你也可以在该项目找到本文的源码。
本文内容
本文代码来源于该链接,该作者对Transformer进行了详细解释,并进行了德译英实战,且增加了许多注解。但对于像我这样的新手来讲还是有些难度,所以我在该作者代码与注释的基础上,进一步增加注释,将英文注释改为中文注释,且去掉了一些与理解Transformer无关的代码(例如并行计算等),方便大家理解Transformer。
该教程需要读者对Transformer有一些了解。
本篇中可能有些注释比较难懂,请不要慌张,可以先打个标记,因为大部分都会在后面对其进行讲解。
如果本篇有什么错误的地方或写的不清楚的地方,欢迎在评论区或者issue模块提出来,我会进行改正或进一步解释。
本文主要内容有:
- Transformer各模块的逐行代码实现
- Transformer逐行代码的详细注释
- Transformer的训练和推理
- 利用Transformer进行德译中实战
你可以通过Google Colab直接运行以下代码
你也可以在该项目(https://github.com/iioSnail/chaotic-transformer-tutorial)找到本文的源码。
环境准备
本教程使用到的类库版本如下:
pandas==1.3.5
torch==1.11.0+cu113
torchdata==0.3.0
torchtext==0.12
spacy==3.2
altair==4.1
jupytext==1.13
flake8
black
GPUtil
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
一定要按照该版本进行安装,尤其是torchtext与torchdata,否则后面会报错
除了上面的库外,还需要用到spacy进行分词。关于spacy可参考该文章。在安装完spacy后,需要安装德语和英语的库,命令如下:
!python -m spacy download de_core_news_sm
!python -m spacy download en_core_web_sm
- 1
- 2
接下来导入需要用到的类库:
import os from os.path import exists import torch import torch.nn as nn # Pad: 用于对句子进行长度填充,官方地址为:https://pytorch.org/docs/stable/generated/torch.nn.functional.pad.html from torch.nn.functional import log_softmax, pad import math # copy: 用于对模型进行深拷贝 import copy import time from torch.optim.lr_scheduler import LambdaLR import pandas as pd # 和matplotlib.pypolt类似,用于绘制统计图,但功能功能强大 # 可以绘制可交互的统计图。官网地址为:https://altair-viz.github.io/getting_started/overview.html import altair as alt # 用于将 iterable 风格的 dataset 转为 map风格的 dataset,详情可参考:https://blog.csdn.net/zhaohongfei_358/article/details/122742656 from torchtext.data.functional import to_map_style_dataset from torch.utils.data import DataLoader # 用于构建词典 from torchtext.vocab import build_vocab_from_iterator # datasets:用于加载Multi30k数据集 import torchtext.datasets as datasets # spacy: 一个易用的分词工具,详情可参考:https://blog.csdn.net/zhaohongfei_358/article/details/125469155 import spacy # GPU工具类,本文中用于显示GPU使用情况 import GPUtil # 用于忽略警告日志 import warnings # 设置忽略警告 warnings.filterwarnings("ignore")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
# 用于验证时,不进行参数更新。 class DummyOptimizer(torch.optim.Optimizer): def __init__(self): self.param_groups = [{"lr": 0}] None def step(self): None def zero_grad(self, set_to_none=False): None # 用于验证时,不进行学习率调整。 class DummyScheduler: def step(self): None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Part 1: 模型架构
大部分序列模型(neural sequence transduction models)都是encoder-decoder结构。encoder负责将一个符号表示的输入序列 ( x 1 , . . . , x n ) (x_1, ..., x_n) (x1,...,xn) 映射为一个连续表示的序列 z = ( z 1 , . . . , z n ) \mathbf{z} = (z_1, ..., z_n) z=(z1,...,zn)。然后将 z \mathbf{z} z作为Decoder的其中一个输入,decoder会一次一个的产生字符输出序列(output sequence of symbols) ( y 1 , . . . , y m ) (y_1,...,y_m) (y1,...,ym)。在每个时刻,模型都是自回归的(auto-regressive),也就是上一个时刻的产生的字符,作为写一个时刻额外的输入。
而Transformer也是这样的encoder-decoder结构,一个标准的EncoderDecoder模型如下:
class EncoderDecoder(nn.Module): """ 一个标准的EncoderDecoder模型。在本教程中,这么类就是Transformer """ def __init__(self, encoder, decoder, src_embed, tgt_embed, generator): """ encoder: Encoder类对象。Transformer的Encoder decoder: Decoder类对象。 Transformer的Decoder src_embed: Embeddings类对象。 Transformer的Embedding和Position Encoding 负责对输入inputs进行Embedding和位置编码 tgt_embed: Embeddings类对象。 Transformer的Embedding和Position Encoding 负责对“输入output”进行Embedding和位置编码 generator: Generator类对象,负责对Decoder的输出做最后的预测(Linear+Softmax) """ super(EncoderDecoder, self).__init__() self.encoder = encoder self.decoder = decoder self.src_embed = src_embed self.tgt_embed = tgt_embed self.generator = generator def forward(self, src, tgt, src_mask, tgt_mask): """ src: 未进行word embedding的句子,例如`[[ 0, 5, 4, 6, 1, 2, 2 ]]` 上例shape为(1, 7),即batch size为1,句子词数为7。其中0为bos, 1为eos, 2为pad tgt: 未进行word embedding的目标句子,例如`[[ 0, 7, 6, 8, 1, 2, 2 ]]` src_mask: Attention层要用的mask,对于source来说,就是要盖住非句子的部分, 例如`[[True,True,True,True,True,False,False]]`。相当于对上面 `[[ 0, 5, 4, 6, 1, 2, 2 ]]`中最后的`2,2`进行掩盖。 tgt_mask: Decoder的Mask Attention层要用的。该shape为(N, L, L),其中N为 batch size, L为target的句子长度。例如(1, 7, 7),对于上面的例子, 值为: [True,False,False,False,False,False,False], # 从该行开始,每次多一个True [True,True,False,False,False,False,False], [True,True,True,False,False,False,False], [True,True,True,True,False,False,False], [True,True,True,True,True,False,False], # 由于该句一共5个词,所以从该行开始一直都只是5个True [True,True,True,True,True,False,False], [True,True,True,True,True,False,False], """ # 注意,这里的返回是Decoder的输出,并不是Generator的输出,因为在EncoderDecoder # 的forward中并没有使用generator。generator的调用是放在模型外面的。 # 这么做的原因可能是因为Generator不算是Transformer的一部分,它只能算是后续处理 # 分开来的话也比较方便做迁移学习。另一方面,推理时只会使用输出的最后一个tensor送给 # generator,而训练时会将所有输出都送给generator。 return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask) def encode(self, src, src_mask): """ 该encode做三件事情: 1. 对src进行word embedding 2. 将word embedding与position encoding相加 3. 通过Transformer的多个encoder层计算结果,输出结果称为memory """ return self.encoder(self.src_embed(src), src_mask) def decode(self, memory, src_mask, tgt, tgt_mask): """ memory: Transformer Encoder的输出 decoder和encoder执行过程基本一样: 1. 对src进行word embedding 2. 将word embedding与position encoding相加 3. 通过Transformer的多个decoder层计算结果 当完成decoder的计算后,接下来可以使用self.generator(nn.Linear+Softmax)来进行最后的预测。 """ return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
上述的代码中包含几个重要的模块,与Transformer的对应关系如下图:
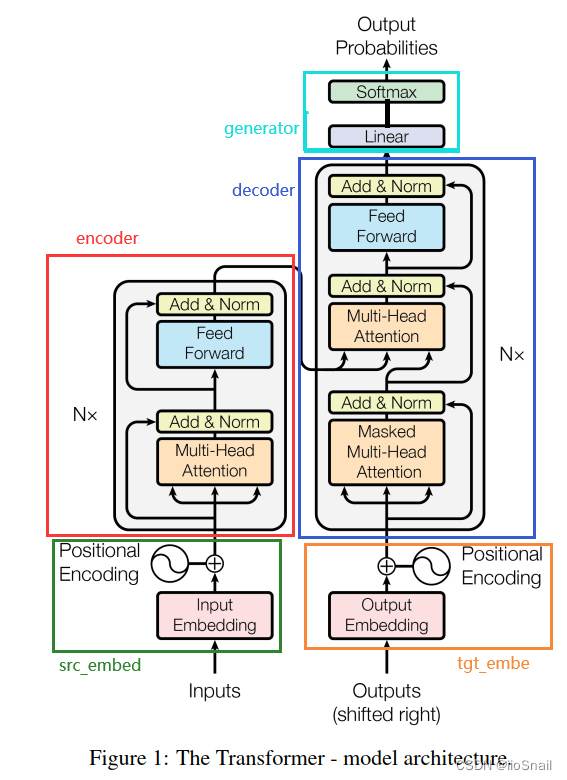
我们根据上图来对Transformer进行拆解:
- 模型的输入:Transformer模型的输入包含两部分:① Inputs ② Outputs。这里可能就会问了Outputs不是输出吗?怎么成输入了?且看后面解释
1.1 Inputs: Inputs可以理解为原始文本,例如我们可以将“I love you”根据字典对应的index转换为数字后(例如[5, 4, 6]),作为inputs传给Transformer的Encoder层。
1.2 Outputs: Outputs是上一次Decoder的输出。例如我们在做机器翻译的时候,Encoder接收的是一个完整的句子(假设为I love you),然后输出一个memory(在RNN里叫Hidden State),但是Decoder并不是一下子就能输出“我爱你”,它和RNN一样,要一个字一个字输出。而Outputs就是上次的输出。(这里看不懂没关系,后面会完整的举个例子) - Embedding: 在Inputs和Outputs的上面有两个Embedding,
Input Embedding和Output Embedding,它们的作用是对字符进行编码。如果你不是特别了解,可以参考该文章。通常Embedding层使用nn.Embedding就可以了。 - Positional Encoding: Transformer和RNN相比,一个重要的提升就是Transformer可以并行计算,其实就是Transformer的Encoder可以一次性接收整个句子,而RNN需要一个词一个词接收。但一次性接收整个句子就会淡化句子中词与词的位置关系,例如 “我爱你”和“爱你我” 可能对网络来说没什么不一样的。 为了解决这个问题,Transformer在Embedding后给每个词增加了位置成分。例如:可以让
I向量的每个值都加0.1,Love加0.2,you加0.3。 当然,Transformer使用的机制并不是像这个例子那么简单,但道理是一样的。 - Encoder:Encoder就是将Inputs进行编码,在效果上和RNN的Encoder应该也没啥不一样的,但因为增加了Attention机制,Performance有了大幅提升。注意这里的 N x Nx Nx 指的是有N个这样的Encoder层叠加。
- Decoder: 和RNN类似,接收“Encoder的输出(称为Memory)和上一次Decoder的输出”作为输入,然后进行一系列运算得到输出。
- Generator:Decoder的输出并不能直接拿来用,还要在经过一个线性层才能得到你想要的结果。有点类似CNN中,卷积层之后需要再接一个线性层做分类。注意:在推理时,generator使用的并不是decoder的所有输出,而是最后一个
out[:, -1],而在训练时,则是使用Decoder的全部输出。 - Output Probabilities: 这个就是线性层后经过Softmax的概率分布。最大的值对应的index,然后再去字典中查询,就知道预测的词是什么了。
有了上述对Transformer各层的解释,我们来看一下Transformer实际是怎么使用的。这里还使用上述翻译的例子:
首先,假设我们有两个字典:
[0(<bos>), 1(<eos>), 2(<pad>), 3(<unk>), 4(Love), 5(I), 6(You), ..., 100(other)][0(<bos>), 1(<eos>), 2(<pad>), 3(<unk>), 4(爱), 5(我), 6(你), ..., 100(其他)]
则我们翻译的第一步如下图:
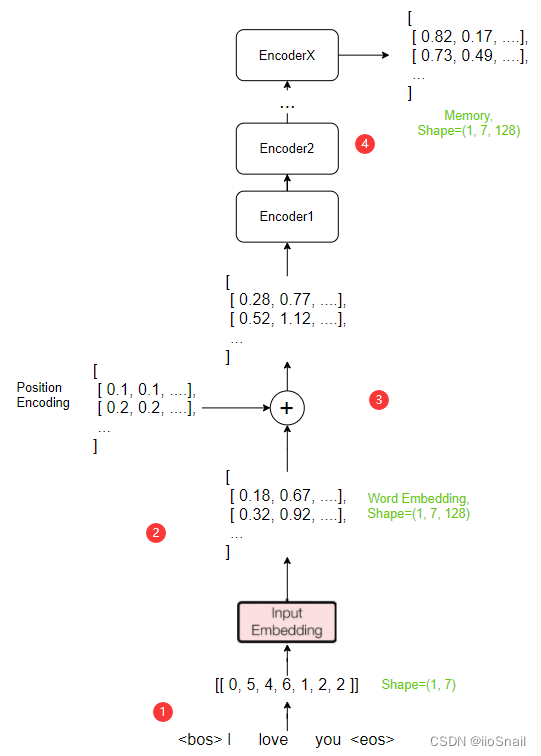
上图为Encoder的执行过程:
- 首先我们根据字典将
I Love you转变为了向量[[ 0, 5, 4, 6, 1, 2, 2 ]],这里的Shape为(1,7),1是batch size, 7是句子长度。而向量中的0表示开始(<bos>),1表示结束(<eos>),2表示填充(<pad>)。这里我假设句子长度固定为7,所以需要填充两个字符。 - 当我们将文字转换为向量后,就会经过Embedding层对向量进行编码,我们这里将一个字符编码成128维的向量,而这个值也对应模型中的参数
d_model(dimension of model)。而对向量编码一般使用参数可学习的nn.Embedding来实现。具体可参考该篇文章 - 接下来我们使用Position Encoding为我们的Embedding增加位置成分。这里我假设位置1就是加0.1,位置2加0.2,依次类推
- 在完成位置编码后,就会正式进入Encoder层,我们有 X X X个Encoder层,所以一层一层计算,最终得到Encoder的输出Memory,这个Memory的Shape与输入是一致的。
接下来我们来看Decoder的执行过程,如图所示:
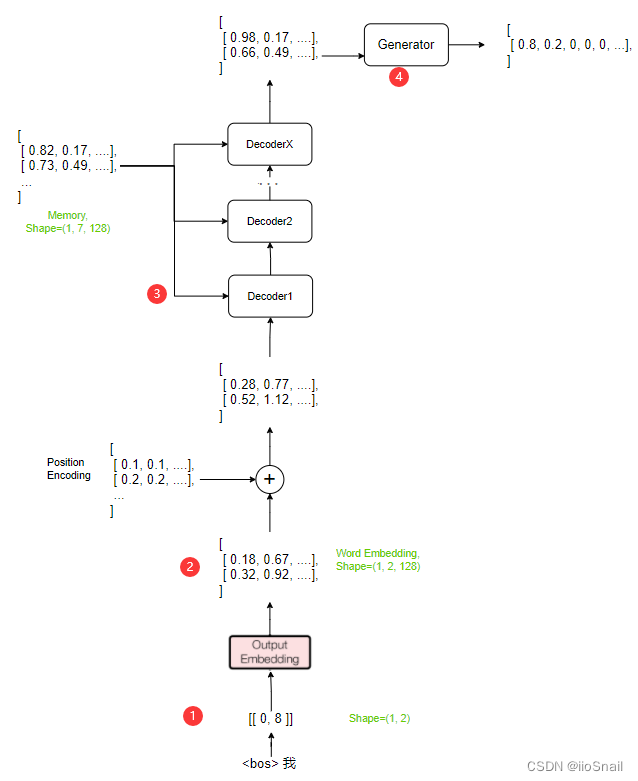
Decoder的执行过程与Encoder类似,区别主要有以下:
- 输入为目标句子:Encoder的输入是原句子(即要被翻译的句子),而Decoder的输入是目标句子(即翻译后的句子)。在推理时,Decoder是一遍一遍的执行,每次的输入都是之前的所有输出,例如,第一次输入为
<bos>,输出为我,则第二次输入为<bos> 我, 输出为爱,依次类推。而在训练时,是一次将目标句子全部送给Decoder,通过掩码(mask)的方式来得到和推理一个一个送同样的结果。 - 第二步与Encoder一致
- Decoder层的输入除了有上一层的输出外,还需要Encoder的输出Memory。在Encoder层的Attention层,query、key和value都是输入x(即前一层的输出)。而在Decoder的Attention层,query是x,但key和value都是memory.
- 在Decoder层输出结果后,需要经过Generator线性层进行最后的预测,其会输出一个概率分布根据这个概率分布找出最大值对应的index,然后查词典就可以了。这个就是个标准的分类网络。需要注意的一点是,在推理时,只需要拿Decoder输出的最后一个tensor送给Generator,得到一个词的概率分布,就像上图画的那样。而在训练时,需要将Decoder的所有输出送给Generator,然后得到每个词的预测结果。
在Decoder输出结果后,需要将结果送给Generator(Linear+Softmax)来预测下一个词(token)。
class Generator(nn.Module): """ Decoder的输出会送到Generator中做最后的预测。 """ def __init__(self, d_model, vocab): """ d_model: dimension of model. 这个值其实就是word embedding的维度。 例如,你把一个词编码成512维的向量,那么d_model就是512 vocab: 词典的大小。 """ super(Generator, self).__init__() self.proj = nn.Linear(d_model, vocab) def forward(self, x): """ x为Decoder的输出,例如x.shape为(1, 7, 128),其中1为batch size, 7为句子长度,128为词向量的维度 这里使用的是log_softmax而非softmax,效果应该是一样的。 据说log_softmax能够解决函数overflow和underflow,加快运算速度,提高数据稳定性。 可以参考:https://www.zhihu.com/question/358069078/answer/912691444 该作者说可以把softmax都可以尝试换成log_softmax """ return log_softmax(self.proj(x), dim=-1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Encoder and Decoder 的堆叠
Encoder
Encoder是由多个相同的EncoderLayer堆叠而成的。原图中只画了一个EncoderLayer,然后旁边写了个 N x N_x Nx 。这个Nx就表示Encoder是由几个EncoderLayer堆叠而成。默认 N = 6 N=6 N=6
def clones(module, N):
"""
该方法负责产生多个相同的层。
"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
- 1
- 2
- 3
- 4
- 5
class Encoder(nn.Module): """ Encoder的核心部分就是多个相同的EncoderLayer堆叠而成。 """ def __init__(self, layer, N): """ 初始化传入两个参数: layer: 要堆叠的层,对应下面的EncoderLayer类 N: 堆叠多少次 """ super(Encoder, self).__init__() # 将Layer克隆N份 self.layers = clones(layer, N) # LayerNorm层就是BatchNorm。也就是对应Transformer中 # “Add & Norm”中的“Norm”部分 self.norm = LayerNorm(layer.size) def forward(self, x, mask): """ x: 进行过Embedding和位置编码后的输入inputs。Shape为(batch_size, 词数,词向量维度) 例如(1, 7, 128),batch_size为1,7个词,每个词128维 mask: src_mask,请参考EncoderDecoder.forward中的src_mask注释 """ # 一层一层的执行,前一个EncoderLayer的输出作为下一层的输入 for layer in self.layers: x = layer(x, mask) # 你可能会有疑问,为什么这里会有一个self.norm(x), # 这个疑问会在后面的`SublayerConnection`中给出解释 return self.norm(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
下面是LayerNorm的代码实现,这个应该算是torch.nn.BatchNorm2d一个简单的实现:
class LayerNorm(nn.Module): """ Norm层,其实该层的作用就是BatchNorm。与`torch.nn.BatchNorm2d`的作用一致。 torch.nn.BatchNorm2d的官方文档地址:https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html 该LayerNorm就对应原图中 “Add & Norm”中“Norm”的部分 """ def __init__(self, features, eps=1e-6): """ features: int类型,含义为特征数。也就是一个词向量的维度,例如128。该值一般和d_model一致。 """ super(LayerNorm, self).__init__() """ 这两个参数是BatchNorm的参数,a_2对应gamma(γ), b_2对应beta(β)。 而nn.Parameter的作用就是将这个两个参数作为模型参数,之后要进行梯度下降。 """ self.a_2 = nn.Parameter(torch.ones(features)) self.b_2 = nn.Parameter(torch.zeros(features)) # epsilon,一个很小的数,防止分母为0 self.eps = eps def forward(self, x): """ x: 为Attention层或者Feed Forward层的输出。Shape和Encoder的输入一样。(其实整个过程中,x的shape都不会发生改变)。 例如,x的shape为(1, 7, 128),即batch_size为1,7个单词,每个单词是128维度的向量。 """ # 按最后一个维度求均值。mean的shape为 (1, 7, 1) mean = x.mean(-1, keepdim=True) # 按最后一个维度求方差。std的shape为 (1, 7, 1) std = x.std(-1, keepdim=True) # 进行归一化,详情可查阅BatchNorm相关资料。 return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
接下来是“Add & Norm”部分,在该代码中称为SublayerConnection,因为“Add & Norm”就是两个子层之间的残差连接。关于残差连接,可以参考ResNet网络。
class SublayerConnection(nn.Module): """ 在一个Norm层后跟一个残差连接。 注意,为了代码简洁,Norm层是在最前面,而不是在最后面 """ def __init__(self, size, dropout): """ 这里的size就是d_model。也就是词向量的维度 """ super(SublayerConnection, self).__init__() # BatchNorm层 self.norm = LayerNorm(size) # BatchNorm的dropout self.dropout = nn.Dropout(dropout) def forward(self, x, sublayer): """ x:本层的输入,前一层的输出。 sublayer: 这个Sublayer就是Attention层或Feed ForWard层。 """ return x + self.dropout(sublayer(self.norm(x)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
在上面的代码中,有这么一句注释:Norm层是在最前面,而不是在最后面。这句话怎么理解呢?
在Transformer原图中,Encoder架构是这样:Attention -> Add & Norm -> Feed Forward -> Add & Norm。
所以我们会下意识地认为代码也是按照这个顺序实现的,但实际代码为了简单,是按照下图这个顺序实现的:
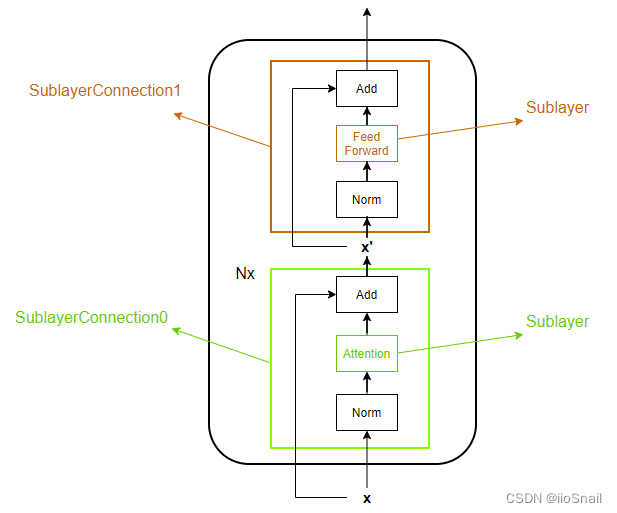
从上图可以看到,Norm是在是放在最前面的,而不是最后面,所以在SublayerConnection中的代码是:
return x + self.dropout(sublayer(self.norm(x)))
- 1
而不是
return self.norm(x + self.dropout(sublayer(x)))
- 1
同时我们也能发现另外两点:
- 在向量经过Position Encoding后到进入Encoder前是有一个Norm动作的。
- 最后一个EncoderLayer层Add后并没有Norm,所以要补一个,这也就是为什么在Encoder类的返回是
return self.norm(x)而不是直接return x。
Encoder的每一层都有两个子层(sub-layers),第一个是多头注意力机制(multi-head
self-attention mechanism),第二个是一个简单的全连接前馈神经网络(Feed Forward)。
class EncoderLayer(nn.Module): "Encoder由一个Attention层和一个前馈网络组成" def __init__(self, size, self_attn, feed_forward, dropout): """ size: 就是d_model,也是词向量的维度。 self_attn: MultiHead Self-Attention模型 feed_forward: 前馈神经网络 """ super(EncoderLayer, self).__init__() self.self_attn = self_attn self.feed_forward = feed_forward # 克隆两个SublayerConnection,第一个给Attention用,第二个给Feed Forward用 self.sublayer = clones(SublayerConnection(size, dropout), 2) self.size = size def forward(self, x, mask): """ 该方法对应原图中Encoder的部分 """ # 首先执行Attention层的计算 x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # 接着执行FeedForward层的计算 return self.sublayer[1](x, self.feed_forward)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Decoder
Decoder和Encoder类似,是由 N N N 个相同的DecoderLayer层堆积而成的。默认 N = 6 N=6 N=6
class Decoder(nn.Module): "Generic N layer decoder with masking." def __init__(self, layer, N): """ layer: 要堆叠的层,对应下面的DecoderLayer类 N: 堆叠多少次 """ super(Decoder, self).__init__() # 克隆出N个DecoderLayer self.layers = clones(layer, N) self.norm = LayerNorm(layer.size) def forward(self, x, memory, src_mask, tgt_mask): """ x: 进行过Embedding和位置编码后的“输入outputs”。Shape为(batch_size, 词数,词向量维度) 例如(1, 7, 128),batch_size为1,7个词,每个词128维 在预测时,x的词数会不断变化,x的shape第一次为(1, 1, 128),第二次为(1, 2, 128),以此类推。 其他参数注释请参考上面的EncoderDecoder类 """ for layer in self.layers: x = layer(x, memory, src_mask, tgt_mask) return self.norm(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
除了Encoder的两个sublayer外,decoder还在中间插入了第三个子层(就是Decoder中Feed Forward和Masked Multi-head Attention中间的那个Multi-Head Attention),该子层也是一个Attention层,只不过这次Attention是针对Encoder的输出Memory和Decoder的第一个Attention的输出。与Encoder类似,每个子层也都做了“Add & Norm”。
class DecoderLayer(nn.Module): """ Decoder由三部分组成: 1. self_attn: 对应图中的Masked Multi-head Attention,负责对Outputs做Attention。 2. src_attn:对应图中Decoder中间的Multi-head Attention,负责对前面Attention的输出 和Encoder的输出做Attention 3. feed_forward:对应Decoder的Feed Forward """ def __init__(self, size, self_attn, src_attn, feed_forward, dropout): """ size: d_model,也就是词向量的维度。 """ super(DecoderLayer, self).__init__() self.size = size self.self_attn = self_attn self.src_attn = src_attn self.feed_forward = feed_forward # 因为Decoder有三个sublayer,所以拷贝3份。 self.sublayer = clones(SublayerConnection(size, dropout), 3) def forward(self, x, memory, src_mask, tgt_mask): "对应原图中Decoder的部分" m = memory # DecoderLayer的第一个Attention,对应的Mask MultiHead Attention x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask)) # DecoderLayer的第二个Attention(中间那个),attention的key和value使用的是memory x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask)) # DecoderLayer最后的Feed Forward层。 return self.sublayer[2](x, self.feed_forward)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Transformer的Attention层还有一个mask机制,主要是为了防止词向量注意一些不该注意的内容,例如:对于Encoder来说,不应该注意<pad>的部分,因为这不属于句子成分。对于Decoder来说,前面的词不应该注意后面的词,同时,也不能注意<pad>的部分。
关于注意力机制和Mask,可参考该篇文章
def subsequent_mask(size): """ 生成一个大小为 size x size 的方阵,该方阵对角线与左下全为True,右上全为False。 例如,size为5时,则结果为: [[[ True, False, False, False, False], [ True, True, False, False, False], [ True, True, True, False, False], [ True, True, True, True, False], [ True, True, True, True, True]]] 该方法在会在构建tgt的mask时使用。 """ # 生成一个Shape为(1, size, size)的矩阵,这里要在 # 前面加个1是为了和tgt的tensor维度保持一致, # 因为tgt最前面是batch_size attn_shape = (1, size, size) """ 生成一个左上角全为1的方阵,例如,当attn_shape为5时,结果为: [[[0., 1., 1., 1., 1.], [0., 0., 1., 1., 1.], [0., 0., 0., 1., 1.], [0., 0., 0., 0., 1.], [0., 0., 0., 0., 0.]]] """ subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type( torch.uint8 ) # 将 0 全部变为True, 1变为False return subsequent_mask == 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
Attention
Attention机制比较复杂,这里只是做简单的说明,如果感兴趣,可以参考该文章
Self-Attention如果只看公式,其实也简单,就是执行下面这个公式即可:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
如果用图表示该公式的话,则为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bnbpnMa9-1659248446974)(./images/ModalNet-19.png)]
大部分对上述的疑问可能就是Q, K, V是怎么来的, d k d_k dk 又是什么。其实是这样,在Self-Attention层会训练三个矩阵: W q , W k 和 W v W^q, W^k和W^v Wq,Wk和Wv,然后用这三个矩阵乘以输入即可,即:
Q = W q I K = W k I V = W v I Q = W^q I \\ K = W^k I \\ V = W^v I \\ Q=WqIK=WkIV=WvI
这里的I就是EncoderLayer层的输入。而
d
k
d_k
dk 就是d_model的值,例如128。(如果是MultiHead Attention,则d_k = d_model / h,h是head数量。所以这也是为什么d_model必须要能整除head数)
通常我们定义这三个
W
W
W矩阵是通过nn.Linear。如果你对nn.Linear的本质不太清楚,可以参考该文章
这里的三个 W W W矩阵通常都是方阵,而Q,K,V的shape与输入I的shape一致。
def attention(query, key, value, mask=None, dropout=None): """ 计算Attention的结果。 这里其实传入的是Q,K,V,而Q,K,V的计算是放在模型中的,请参考后续的MultiHeadedAttention类。 这里的Q,K,V有两种Shape,如果是Self-Attention,Shape为(batch, 词数, d_model), 例如(1, 7, 128),即batch_size为1,一句7个单词,每个单词128维 但如果是Multi-Head Attention,则Shape为(batch, head数, 词数,d_model/head数), 例如(1, 8, 7, 16),即Batch_size为1,8个head,一句7个单词,128/8=16。 这样其实也能看出来,所谓的MultiHead其实就是将128拆开了。 在Transformer中,由于使用的是MultiHead Attention,所以Q,K,V的Shape只会是第二种。 mask: mask有两种,一种是src_mask,另一种是tgt_mask。 """ # 获取d_model的值。之所以这样可以获取,是因为query和输入的shape相同, # 若为Self-Attention,则最后一维都是词向量的维度,也就是d_model的值。 # 若为MultiHead Attention,则最后一维是 d_model / h,h为head数 d_k = query.size(-1) # 执行QK^T / √d_k # 这里scores是一个方阵, shape为(batch_size, head数,词数,词数) scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) """ mask有两种: 第一种为: src_mask。Shape为(batch_size, 1, 1, 词数)。例如:(1, 1, 1, 10)。 [[[1., 1., 1., 1., 1., 1., 1., 0., 0., 0.]]],表示第一个句子的 前7个是单词(包括bos、eos和unk),后面3个是填充。而mask就是要对 后面三个进行mask。 例如,mask前,score的shape为(1, 2, 10, 10),2个head,10个词 score在mask前为: [[[[x1, x2, ..., x7, x8, x9, x10], ... [x1, x2, ..., x7, x8, x9, x10]] [x1, x2, ..., x7, x8, x9, x10], ... [x1, x2, ..., x7, x8, x9, x10]]]] score在mask后为: [[[[x1, x2, ..., x7, -1e9, -1e9, -1e9], ... [x1, x2, ..., x7, -1e9, -1e9, -1e9]] [x1, x2, ..., x7, -1e9, -1e9, -1e9], ... [x1, x2, ..., x7, -1e9, -1e9, -1e9]]]] 第二种为:tgt_mask。Shape为(batch_size, 1, 词数, 词数)。例如:(1, 1, 10, 10)。例如: [[[1, 0, 0, 0, 0], [1, 1, 0, 0, 0], [1, 1, 1, 0, 0], [1, 1, 1, 1, 0], [1, 1, 1, 1, 1]] 即对角线的右上面都盖住。具体为什么这样可以参考链接:https://blog.csdn.net/zhaohongfei_358/article/details/125858248 score在mask前为: [[[[x1, x2, ..., x7, x8, x9, x10], ... [x1, x2, ..., x7, x8, x9, x10]] [x1, x2, ..., x7, x8, x9, x10], ... [x1, x2, ..., x7, x8, x9, x10]]]] score在mask后为: [[[[x1, 1e9, ..., 1e9, -1e9, -1e9, -1e9], ... [x1, x2, ..., 1e9, -1e9, -1e9, -1e9]] [x1, x2, ..., 1e9, -1e9, -1e9, -1e9], ... [x1, x2, ..., x7, x8, x9, x10]]]] 两者比较:src_mask的shape为(batch_size, 1, 1, 词数),而tgt_mask的shape为(batch_size, 1, 词数, 词数) 这是因为src要对后面非句子的词整个mask,所以只需要在最后一维做就行了。 而tgt需要斜着进行mask,所以需要一个方阵来进行。 """ if mask is not None: # 这里的填充值并不是0,而是-1e9,原因是后续还要进行softmax, # 而softmax会让负无穷变为0。 scores = scores.masked_fill(mask == 0, -1e9) # 执行公式中的Softmax # 这里的p_attn是一个方阵 # 若是Self Attention,则shape为(batch, 词数, 次数),例如(1, 7, 7) # 若是MultiHead Attention,则shape为(batch, head数, 词数,词数) p_attn = scores.softmax(dim=-1) if dropout is not None: p_attn = dropout(p_attn) # 最后再乘以 V。 # 对于Self Attention来说,结果Shape为(batch, 词数, d_model),这也就是最终的结果了。 # 但对于MultiHead Attention来说,结果Shape为(batch, head数, 词数,d_model/head数) # 而这不是最终结果,后续还要将head合并,变为(batch, 词数, d_model)。不过这是MultiHeadAttention # 该做的事情。 return torch.matmul(p_attn, value), p_attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
Multi Attention建议参考该文章。
Multi Attention简单点说,就是将Q, K, V的最后一个维度进行拆分,拆成了多个head,然后再带入attention函数进行计算,最终再将多个head融合到一起。
class MultiHeadedAttention(nn.Module): def __init__(self, h, d_model, dropout=0.1): """ h: head的数量 """ super(MultiHeadedAttention, self).__init__() assert d_model % h == 0 # We assume d_v always equals d_k self.d_k = d_model // h self.h = h # 定义W^q, W^k, W^v和W^o矩阵。 # 如果你不知道为什么用nn.Linear定义矩阵,可以参考该文章: # https://blog.csdn.net/zhaohongfei_358/article/details/122797190 self.linears = clones(nn.Linear(d_model, d_model), 4) self.attn = None self.dropout = nn.Dropout(p=dropout) def forward(self, query, key, value, mask=None): """ query, key, value: 这里的这三个变量名容易对人产生误导, 它指的并不是公式中经过W^q, W^k, W^v计算后的Q, K, V, 而是要跟 W^q, W^k, W^v 计算的输入。 对于Encoder的Attention层来说,这里的query,key,value全都是输入x, 从EncoderLayer类中的`self.self_attn(x, x, x, mask)`这段代码也 可以看出来。 对于Decoder最前面那个Mask Attention,query,key,value也全都是输入x。 但对于Decoder中间的那个Attention就不一样了,它是将Encoder的输出memory 作为key和value,将输入x作为query。通过DecoderLayer中的代码 `self.src_attn(x, m, m, src_mask)`可看出来。 """ if mask is not None: # 原本mask和query的Tensor维度都是3,即len(mask.size())为3 # 但是由于是多头注意力机制,所以query的维度会变成4,也 # 就是在第2个维度插入了head,变为了(batch, head数, 词数,d_model/head数)。 # mask为了和query的维度保持一致,所以也要将自己扩展成4维。 mask = mask.unsqueeze(1) # 获取Batch Size nbatches = query.size(0) """ 1. 求出Q, K, V,这里是求MultiHead的Q,K,V,所以Shape为(batch, head数, 词数,d_model/head数) 1.1 首先,通过定义的W^q,W^k,W^v求出SelfAttention的Q,K,V,此时Q,K,V的Shape为(batch, 词数, d_model) 对应代码为 `linear(x)` 1.2 分成多头,即将Shape由(batch, 词数, d_model)变为(batch, 词数, head数,d_model/head数)。 对应代码为 `view(nbatches, -1, self.h, self.d_k)` 1.3 最终交换“词数”和“head数”这两个维度,将head数放在前面,最终shape变为(batch, head数, 词数,d_model/head数)。 对应代码为 `transpose(1, 2)` """ query, key, value = [ linear(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for linear, x in zip(self.linears, (query, key, value)) ] """ 2. 求出Q,K,V后,通过attention函数计算出Attention结果, 这里x的shape为(batch, head数, 词数,d_model/head数) self.attn的shape为(batch, head数, 词数,词数) """ x, self.attn = attention( query, key, value, mask=mask, dropout=self.dropout ) """ 3. 将多个head再合并起来,即将x的shape由(batch, head数, 词数,d_model/head数) 再变为 (batch, 词数,d_model) 3.1 首先,交换“head数”和“词数”,这两个维度,结果为(batch, 词数, head数, d_model/head数) 对应代码为:`x.transpose(1, 2).contiguous()` 3.2 然后将“head数”和“d_model/head数”这两个维度合并,结果为(batch, 词数,d_model) """ x = ( x.transpose(1, 2) .contiguous() .view(nbatches, -1, self.h * self.d_k) ) del query del key del value # 最终通过W^o矩阵再执行一次线性变换,得到最终结果。 return self.linears[-1](x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
Position-wise 前馈神经网络
除了Attention子层外,Encoder和Decoder的每一个层还包含一个全连接的前馈网络,该网络分别且相同地应用于每个位置。该前馈网络包括两个线性变换,并在第一个的最后使用ReLU激活函数。
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \mathrm{FFN}(x)=\max(0, xW_1 + b_1) W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
虽然线性变换在不同位置上是相同的,但它们在层与层之间使用不同的参数。描述这种情况的另一种方式是两个内核大小为1的卷积。输入和输出的维度是 d model = 512 d_{\text{model}}=512 dmodel=512,内层的维度 d f f = 2048 d_{ff}=2048 dff=2048。
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
"""
d_ff: 隐层的神经元数量。
"""
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 公式中的max(0, xW+b)其实就是ReLU的公式
return self.w_2(self.dropout(self.w_1(x).relu()))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Embeddings and Softmax
与其他的序列转化模型相同,我们也是用可学习的Embeddings来将input和output的token和转换为 d model d_{\text{model}} dmodel维的向量。
我们也使用常用的线性层和Softmax函数来对decoder的输出做预测,预测下一个token的概率。在我们的模型中,两个Embedding层使用相同的权重。在Embedding层,会乘以权重 d model \sqrt{d_{\text{model}}} dmodel
关于nn.Embedding的使用,可参考该文章
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
"""
d_model: 词向量的维度
vocab: 词典的大小。
"""
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
关于为什么Embedding层要乘以权重 d model \sqrt{d_{\text{model}}} dmodel ,可以参考这个知乎问题中@王四喜和@Quokka的回答。这里我只做一个直观的说明。
由于模型使用了nn.init.xavier_uniform_的方式进行初始化,会导致Embedding的结果长这样(self.lut(x)的结果):
[[[ 0.0052, -0.0021, 0.0071, ..., -0.0161, -0.0092, -0.0077],
[-0.0170, 0.0148, -0.0011, ..., 0.0118, -0.0128, 0.0143],
[-0.0137, 0.0146, 0.0196, ..., -0.0194, -0.0049, -0.0072],
...
- 1
- 2
- 3
- 4
可以看到,都是0.0x开头的。若乘以 d model \sqrt{d_{\text{model}}} dmodel ,结果就变为了:
[[[ 0.0593, -0.0239, 0.0808, ..., -0.1818, -0.1036, -0.0875],
[-0.1924, 0.1677, -0.0127, ..., 0.1332, -0.1452, 0.1619],
[-0.1553, 0.1656, 0.2222, ..., -0.2198, -0.0554, -0.0815],
...
- 1
- 2
- 3
- 4
所以乘以 d model \sqrt{d_{\text{model}}} dmodel 其实就是起到了一个标准化的作用。
位置编码(Position Encoding)
因为Transformer模型不像RNN那样存在循环卷积,为了让模型可以利用输入序列的顺序,我们就必须往序列中注入一些相对位置和绝对位置的信息。因此,我们在input embeddings后增加了“positional encodings”. Positional Encodings与 d model d_{\text{model}} dmodel有相同的维度,这样他们就可以相加了。
在该工作中,我们使用了不同频率的sine和cosine函数:
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d model ) PE_{(pos,2i)} = \sin(pos / 10000^{2i/d_{\text{model}}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d model ) PE_{(pos,2i+1)} = \cos(pos / 10000^{2i/d_{\text{model}}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中 p o s pos pos是位置, i i i是维度。也就是说,位置编码的每个维度都对应着一个正弦曲线(sinusoid)。波长形成 2 π 2\pi 2π 到 10000 ⋅ 2 π 10000\cdot 2\pi 10000⋅2π的几何级数。我们选择了这个函数,因为我们假设它允许模型容易地学习相对位置,因为对于任何固定偏移 k k k, P E p o s + k PE_{pos+k} PEpos+k可以表示为 P E p o s PE_{pos} PEpos的线性函数。
除此之外,我们还在embedding与positional encoding的sum结果上应用了dropout。默认dropout=0.1
上面这段原论文的解释看起来有些晦涩难懂,可以参考该篇文章。
总之就是,我们对第pos个单词的第i个维度,就是加上 P E ( p o s , 2 i ) PE(pos, 2i) PE(pos,2i)即可。
class PositionalEncoding(nn.Module): "Implement the PE function." def __init__(self, d_model, dropout, max_len=5000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) # 初始化Shape为(max_len, d_model)的PE (positional encoding) pe = torch.zeros(max_len, d_model) # 初始化一个tensor [[0, 1, 2, 3, ...]] position = torch.arange(0, max_len).unsqueeze(1) # 这里就是sin和cos括号中的内容,通过e和ln进行了变换 div_term = torch.exp( torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model) ) # 计算PE(pos, 2i) pe[:, 0::2] = torch.sin(position * div_term) # 计算PE(pos, 2i+1) pe[:, 1::2] = torch.cos(position * div_term) # 为了方便计算,在最外面在unsqueeze出一个batch pe = pe.unsqueeze(0) # 如果一个参数不参与梯度下降,但又希望保存model的时候将其保存下来 # 这个时候就可以用register_buffer self.register_buffer("pe", pe) def forward(self, x): """ x 为embedding后的inputs,例如(1,7, 128),batch size为1,7个单词,单词维度为128 """ # 将x和positional encoding相加。 x = x + self.pe[:, : x.size(1)].requires_grad_(False) return self.dropout(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
在上面的代码计算
div_term时,并没有直接使用 p o s / 1000 0 2 i / d model pos / 10000^{2i/d_{\text{model}}} pos/100002i/dmodel 公式,而是使用它的变种 e − 2 i ln ( 10000 ) / d m o d e l e^{-2i\ln(10000) / d_{model}} e−2iln(10000)/dmodel,我认为原因可能是因为这样计算效率较高。
我测试了使用原始公式的代码1 / torch.pow(10000, torch.arange(0., d_model, 2) / d_model),发现结果和变种一样,但速度却慢了一倍。
完整模型
这里我们定义一个函数来构建完整模型
def make_model( src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1 ): """ Helper: Construct a model from hyperparameters. src_vocab:原词典的大小。假设你要做英译汉,那么src_vocab就是英文词典的大小 tgt_vocab: 目标词典的大小。 N: EncoderLayer和DecoderLayer的数量 d_model: 词向量的大小。 d_ff: 模型中Feed Forward层中隐层神经元的数量 h: MultiHead中head的数量 """ # 用于将模型深度拷贝一份(相当于全新的new一个) c = copy.deepcopy # 1. 构建多头注意力机制 attn = MultiHeadedAttention(h, d_model) # 2. 构建前馈神经网络 ff = PositionwiseFeedForward(d_model, d_ff, dropout) # 3. 构建位置编码 position = PositionalEncoding(d_model, dropout) # 4. 构建Transformer模型 model = EncoderDecoder( # Encoder层。 Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N), # Decoder层,其包含两个Attention层,复制两份 Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N), # inputs的编码器和位置编码 nn.Sequential(Embeddings(d_model, src_vocab), c(position)), # outputs的编码器和位置编码 nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)), # Decoder最后的Linear层和Softmax,用于预测下一个token Generator(d_model, tgt_vocab), ) # 使用xavier均匀分布的方式进行模型参数初始化 # 关于为什么要用该初始化方式,我并没有在网上 # 找到很好的解释。 for p in model.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p) return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
推理(Inference)
我们这里使用前向传递来测试一下我们的模型。我们会尝试使用Transformer来记住input。因为模型没训练过,所以输出是随机的。不过在下一章,我们将会构建训练函数来尝试训练我们的模型,让他记住从1到10这几个数字。
def inference_test(): """ 测试模型 """ # 构架测试模型,原词典和目标词典大小都为11, # EncoderLayer和DecoderLayer的数量为2 test_model = make_model(11, 11, 2) test_model.eval() # 定义inputs, shape为(1, 10),即一个句子,该句子10个单词。 src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]]) # 定义src_mask,即所有的词都是有效的,没有填充词 src_mask = torch.ones(1, 1, 10) # 将输入送给encoder,获取memory memory = test_model.encode(src, src_mask) # 初始化ys为[[0]],用于保存预测结果,其中0表示'<bos>' ys = torch.zeros(1, 1).type_as(src) # 循环调用decoder,一个个的进行预测。例如:假设我们要将“I love you”翻译成 # “我爱你”,则第一次的`ys`为(<bos>),然后输出为“I”。然后第二次`ys`为(<bos>, I) # 输出为"love",依次类推,直到decoder输出“<eos>”或达到句子长度。 for i in range(9): # 将encoder的输出memory和之前Decoder的所有输出作为参数,让Decoder来预测下一个token out = test_model.decode( # ys就是Decoder之前的所有输出 memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data) ) # 将Decoder的输出送给generator进行预测。这里只取最后一个词的输出进行预测。 # 因为你传的tgt的词数是变化的,第一次是(<bos>),第二次是(<bos>, I) # 所以你的out的维度也是变化的,变化的就是(batch_size, 词数,词向量)中词数这个维度 # 既然只能取一个,那当然是最后一个词最合适。 prob = test_model.generator(out[:, -1]) # 取出数值最大的那个,它的index在词典中对应的词就是预测结果 _, next_word = torch.max(prob, dim=1) # 取出预测结果 next_word = next_word.data[0] # 将这一次的预测结果和之前的拼到一块,作为之后Decoder的输入 ys = torch.cat( [ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1 ) print("Example Untrained Model Prediction:", ys) def run_tests(): for _ in range(10): inference_test() run_tests()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51

