
热门标签
热门文章
- 1撸起袖子开干?没有功能需求文档,我拒绝开发!_功能设计需求文档有哪些内容
- 2阿里云的短信验证码(超详细)_阿里云短信验证码服务
- 3数据仓库实践:了解和定义指标
- 4爬虫:使用Python的BeautifulSoup库进行网页抓取_beautifulsoup features='xml
- 5Typora+PicGo,最好用的Markdown+最好用的图床工具!
- 6Oracle的性能调整
- 7Smartphone 应用程序安全与代码签名模型开发人员实用指南_签名模型的执行过程。
- 8Keras 之 LSTM 有状态模型(stateful LSTM)和无状态模型(stateless LSTM)_electricityloaddiagrams20112014
- 9Sora模型
- 10学习使用CSS实现div中的内容垂直居中的方法_div垂直居中显示三种方式
当前位置: article > 正文
python爬虫--selenium的理解以及使用(六)_movebyoffset设值
作者:运维做开发 | 2024-07-17 11:18:53
赞
踩
movebyoffset设值
前言
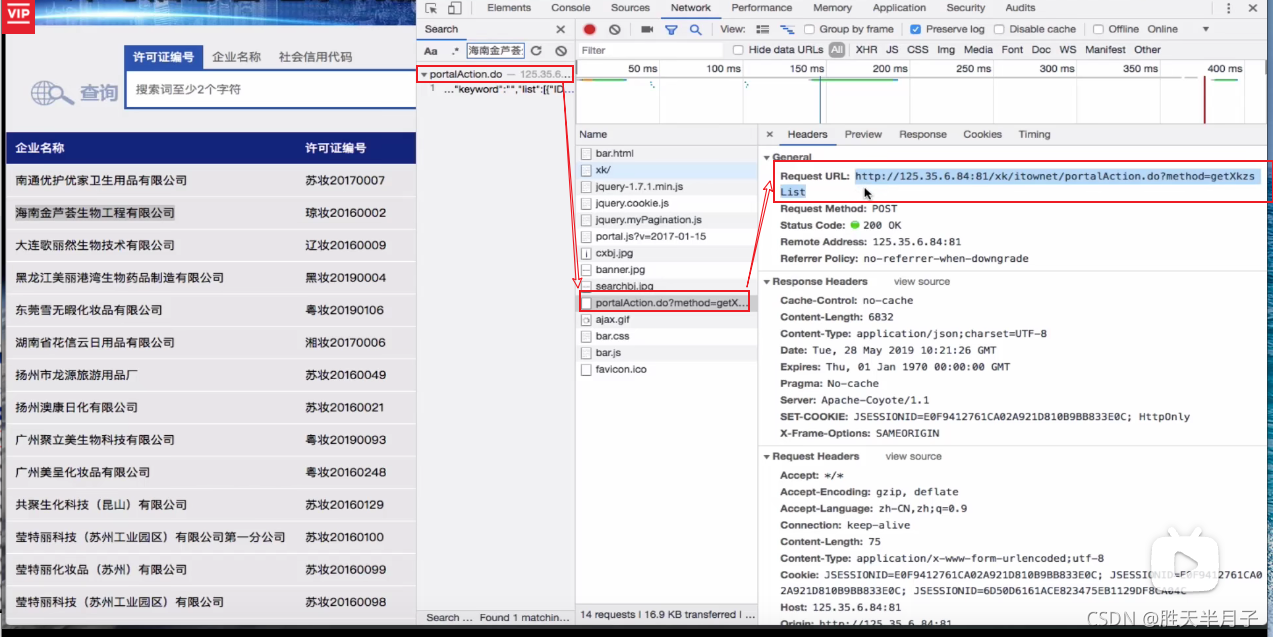
- 关于一个页面是否是动态加载(Aajax)数据的判断方法⭐⭐
动态加载数据意味着直接对网址进行请求是无法直接拿到页面数据的,我们可以通过网页上的抓包工具定位到network对网页进行请求,并查看网页上的某个数据是否在network请求页面加载的数据页中
- 步骤详解
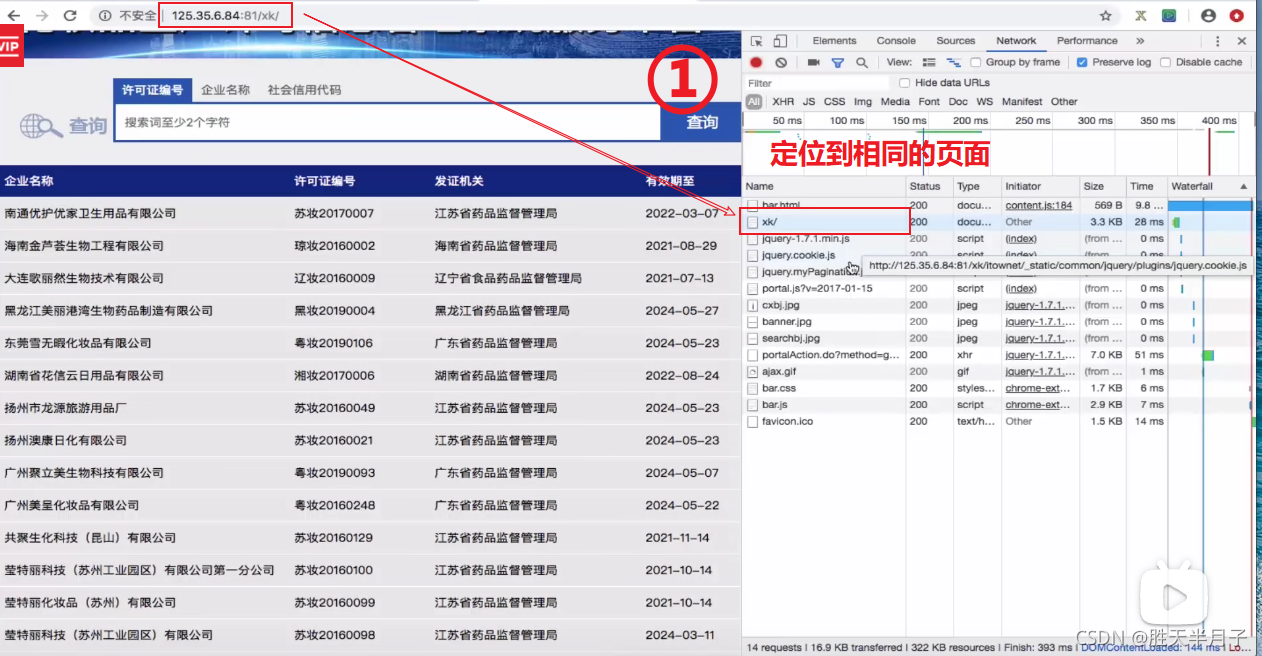
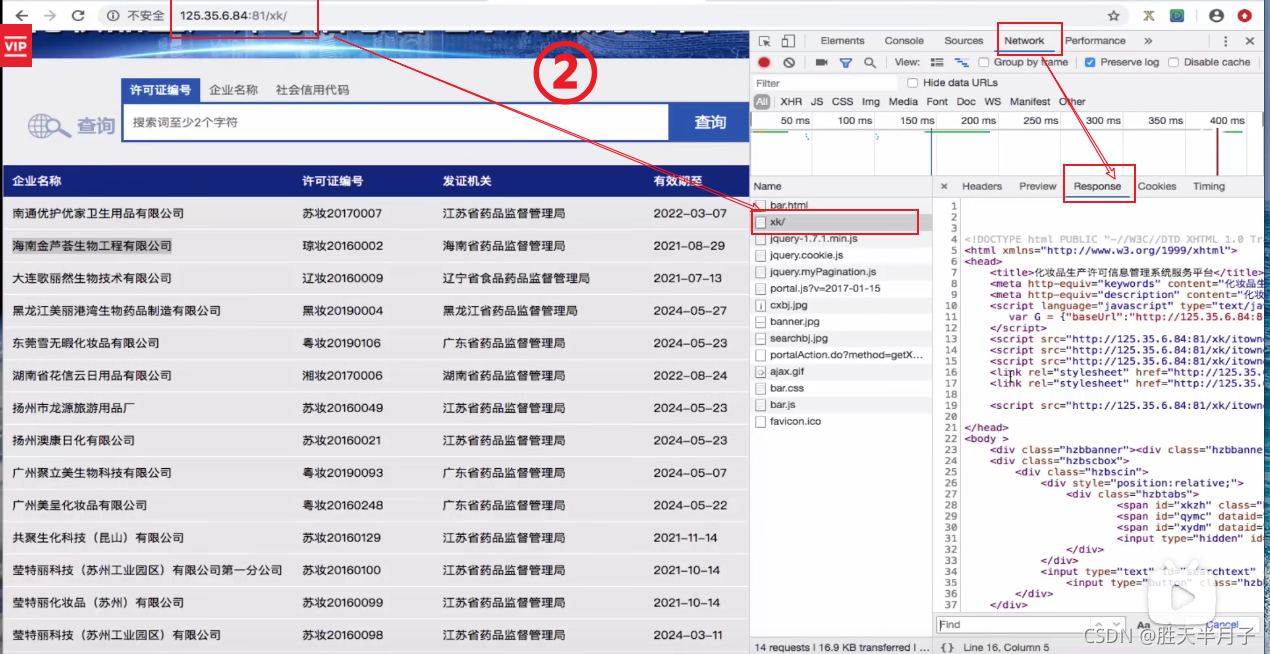
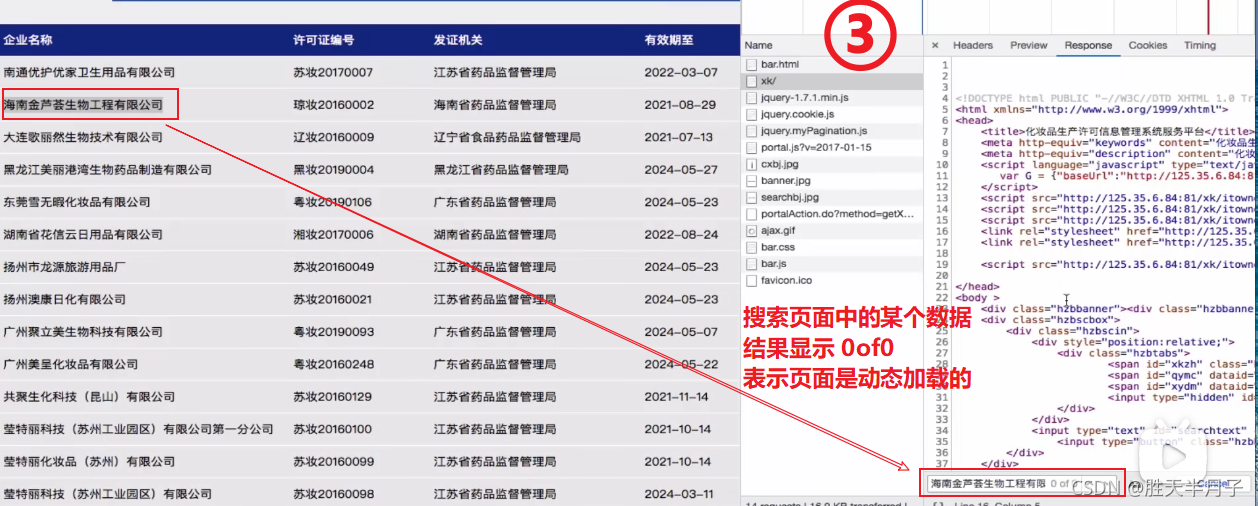
动态加载的数据是如何来的?

一、selenium简介
selenium模块和爬虫之间具有怎样的关联?
- 便捷的获取网站中动态加载的数据
- 边界的实现模拟登录
什么是selenium模块?
- 基于
浏览器自动化的一个模块
selenium模块使用流程:
- 环境安装:
pip install selenium⭐- 下载一个浏览器的驱动程序:用什么浏览器就下载什么浏览器驱动程序:谷歌驱动程序
对于现在正在使用的google浏览器根据版本号寻找对应驱动程序即可。- 实例化一个浏览器对象
- 编写基于浏览器自动化的操作代码:
- 发起请求:get(url)
- 标签定位:find系列方法
- 标签交互:send_keys(‘xxx’)
- 执行js程序:execte_script(‘jsCode’)
- 关闭浏览器:quit()
- 使用selenium爬取药监总局的数据⭐
from selenium import webdriver from lxml import etree from time import sleep # 实例化一个浏览器对象(传入浏览器的驱动程序) bro = webdriver.Chrome(executable_path='E:\Google\chromedriver') # 让浏览器发起一个指定的url对应请求 bro.get('http://scxk.nmpa.gov.cn:81/xk/') # 获取浏览器当前的页面源码数据 page_text = bro.page_source # 解析企业名称 tree = etree.HTML(page_text) li_list = tree.xpath('//ul[@id="gzlist"]/li') for li in li_list: name = li.xpath('./dl/@title')[0] print(name) sleep(5) # 关闭浏览器 bro.quit()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

- 使用selenium进行简单的自动化操作
from selenium import webdriver from time import sleep bro = webdriver.Chrome(executable_path=r'E:\Google\chromedriver') bro.get('https://www.taobao.com/') # 找到搜索框:标签定位 search_input = bro.find_element_by_id('q') # 返回所定位的标签 # 标签的交互 search_input.send_keys('Iphone') # 执行一组js程序 :滚轮滚动一个屏幕的高度 bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(2) # 点击搜索按钮 class = 'btn-search tb-bg' btn = bro.find_element_by_css_selector('.btn-search') # btn = bro.find_element_by_class_name('btn-search') btn = bro.find_element_by_class_name('tb-bg') btn.click() bro.get('https://www.baidu.com') sleep(2) # 回退 bro.back() sleep(2) # 前进 bro.forward() sleep(5) bro.quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
二、selenium处理iframe
- 如果定位的标签是存在iframe标签之中的则必须使用switch_to.frame(id)
- 动作链(拖动):
from selenium.webdriver import ActionChains# 动作链
- 实例化动作链对象:
action = ActionChains(bro)
action.click_and_hold(div):长按并点击
move_by_offset(x,y):想要偏移的像素值
action.move_by_offset(17,yoffset=0).perform():让动作链立即执行
action.release()释放动作链对象
- iframe
iframe就是我们常用的iframe标签:<iframe>。iframe标签是框架的一种形式,也比较常用到,iframe一般用来包含别的页面,例如我们可以在我们自己的网站页面加载别人网站或者本站其他页面的内容。
iframe标签的最大作用就是让页面变得美观。
iframe标签的用
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/839597
推荐阅读
相关标签

