
- 1Linux Workqueue_linux中workqueue详细实现机制
- 2flink checkpoint 源码分析 (二)
- 3spark代码sc统一配置_spark sc
- 4关于org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.问题的解决
- 5算子的含义_算子 组合 csdn
- 6Redis单例、主从、哨兵、集群_redis只有一台哨兵实例可以吗
- 7微服务 - Eureka 服务注册与发现机制_注册中心eruka集群下如何进行消息同步
- 8Java后端面试高频问题:Redis_java面试问redis比较多
- 9Linux操作系统 第1关:Linux初体验_第1关:linux初体验
- 10tensorflow06——正则化缓解过拟合_dot.csv
【SIGIR2020】信息检索对话中混合主动性和协同性的分析
赞
踩
点击上方,选择星标,每天给你送干货!
解读:仰望星空(NLP、IR)
Paper: An Analysis of Mixed Initiative and Collaboration in Information-Seeking Dialogues
Author: Svitlana Vakulenko, Evangelos Kanoulas, Maarten de Rijke
PDF: https://arxiv.org/abs/2005.12340
0.写在前面
参与混合主动互动的能力是会话搜索系统的核心要求之一。如何做到这一点,人们知之甚少。我们提出了一组无监督的度量标准,称作ConversationShape,通过比较词汇和话语类型的分布来强调每个会话参与者所扮演的角色。以ConversationShape为标准,仔细地研究了几个会话搜索数据集,并将它们与其他对话数据集进行比较,以便更好地理解它们所代表的对话交互类型,无论是由信息搜索者还是助手驱动的。我们发现,同一类型的人与人对话的对话形态与ConversationShape之间的偏离,可以预测人与机器对话的质量。
1. 简介
虽然会话搜索的想法已经存在了几十年,但这个想法最近引起了相当大的关注。会话式用户界面被认为比传统的界面更有利于有效的信息访问。在这种情况下,对话是一种协作过程,允许信息寻求者满足信息需求。会话交互的关键特征之一是混合主动性的潜力,其中系统和用户都可以采取适当的主动性。在这篇论文中,作者提出了一种分析评估对话参与者之间的主动性和协作程度的指标。
迄今为止提出的会话搜索任务主要将对话减少为一系列的问题-答案对。在用于问答任务的数据集中,交互的结构事先是固定的:要么用户主动,系统随后给出答案,要么反过来,这使得它们不适合研究角色之间的主动性如何转移。来自在线问答论坛的讨论是开发会话搜索任务的一个流行的数据来源[18,19]。虽然在线论坛是研究现实世界交互模式的宝贵资源,但它们展示了一种异步信息交换类型,正如我们在分析中所显示的,这与同步对话交互非常不同。
会话系统通常分为问答、任务导向和闲聊。值得注意的是,这种分类模式主要基于构建这种对话系统的方法的不同,而不是它们产生的对话的不同。在本文中,**我们着重分析和测量对话类型之间的差异,并报告由此产生的维度和一个新的对话分类方案。**我们表明,为会话搜索任务收集的人对人对话与面向任务的对话和闲聊对话在结构上具有相似性。
最近对聊天对话模型的评估研究表明,对话系统倾向于通过问太多的问题和忽视用户的主动性来控制对话[4,9]。标准的评估指标不能捕捉到对话互动的这一维度,因此不能预测用户参与度。对话评价最常用的指标是回应的相关性,通常是根据真实的回应来衡量;如果响应是一个答案,那么它可以与答案的准确性相比较。我们的工作是对这项研究的补充。我们提出了一种新的基于一组无监督特征的评价框架。该框架的设计目的是在适当的时候,根据平衡主动性和衡量对话参与者之间的协作来捕获对话互动的质量。
我们的评估框架是基于几个独立的词汇特征,这些词汇特征捕捉了对话中的主动性和协作性。先前采用了基于语篇特征的简单自动测量方法,如词汇和句法多样性,以减少重复的共性回答,并估计问题的复杂性[14,23]。我们使用了一种无监督的方法,类似于在匹配[13]语言风格和衡量生成叙事[22]的质量时所使用的方法。一个关键特征的对话是。它是一种由多个对话参与者产生的话语叙事类型。因此,我们分别估计每个参与者的词汇特征,以便能够比较他们的贡献,从而推断他们在对话中扮演的角色。
我们的对话表示方法是无监督和领域独立的,这允许我们将以前只在少数对话上执行的分析扩展到数千个公开可用的对话文本。
我们的主要贡献可以总结为:(1)我们在10个数据集(超过97k个对话)中考察了主动性和协作的结构模式。我们的研究是第一个在庞大而多样的对话语料库中自动识别这些维度的研究,并将源自不同研究团体的对话任务进行类比。(2)我们所识别的主动性和协作模式与人类对对话质量的判断相关。控制的分配(其中控制被定义为管理会话中的流程方向)是旨在增强人机协作的混合主动对话系统的核心。对话系统应能够识别userâĂŹs提示的主动切换,从而提供适当的回应。检测主动性对于描述交互的质量也很重要。我们的工作有助于洞察,为评估和优化方法的设计提供信息,这些方法能够识别对话中的主动性分配。
2. ConversationShape
ConversationShape是一种关注对话结构属性的对话表示方法。我们认为对话是几个参与者之间交换的一系列话语。我们实验中的所有对话都有两名参与者。然而,我们的方法也适用于多方对话。信息寻求对话的特点通常是参与者在对话中扮演的角色不对称:参与者通常扮演助手(A)的角色,其功能是通过对话搜索系统实现自动化;另一个对话参与者是一个信息寻求者,他正在使用助手的服务来获取信息。为了模拟对话中的混合主动性,我们使用了四个指标,分别为每个对话参与者计算:(1)问题(question);(2)信息(information);(3)重复(repetition);和(4)流(flow)。
问题(question)是一种试图控制谈话方向的明确尝试,因为提出的问题会让另一个参与者产生相应的答案。我们在NPS聊天语料库上训练了一个有监督分类器来识别问题和其他类型的话语。NPS聊天语料库包含了来自网络聊天室的7.9K个话语,标注了14种话语类型:Statement、Emotion、Greet、Bye、Accept、Reject、whQuestion、ynQuestion、yAnswer、nAnswer、Emphasis、Continuer、clear、Other。我们的分类模型是从预先训练的罗伯塔17初始化的,并进一步为话语类型预测任务进行调整,在递出测试集中实现F1为0.81。
其余的度量标准描述协作模式和对对话主题的控制。要解释它们,我们首先需要介绍对话词表的概念。对话词表由出现在同一对话文本中的所有唯一单词(或子单词标记)组成。我们对在同一对话中频繁出现(不止一次)的单词特别感兴趣,因为重复模式很可能表明它们对对话主题的重要性。
信息(information)反映了参与者对谈话主题的贡献。我们将信息估计为会话参与者首先创造的频繁令牌的计数。
重复(repetition)表示对谈话主题的延续。为了分析共享词汇表的出现,我们跟踪会话参与者之间的词汇表重用模式。我们将重复估计为一个会话参与者首先引入并随后被另一个会话参与者重复的标记的数量。我们认为重复是对话中可用的一种相关性反馈,假设重复行为是通过增加标记频率来认可标记对对话主题的重要性。另一种隐式引用前面标记的方法是使用回指。因此,我们将回指计数加到重复计数中。从沃克和惠特克提出的分析框架中,我们使用了一小串英语回指:
“it”,“they”,“they”,“their”,“she”,“he”,“her”,“him”,“his”,“this”,“that”。我们也用现成的共参考分辨率模型进行了实验,但结果并不令人满意。
“流”(flow)是重复和信息之间的区别,它反映了参与者通过引用之前的陈述来维持对话的连贯性,或者通过引入新的信息来推动对话向前的作用。
对于每一次对话,我们分别计算每个对话参与者的值:conceptA和ConceptS(A代表assistant,S代表Seeker ),其中Concept表示我们刚刚介绍的四个指标之一。为了能够比较不同长度的对话,我们还通过对话中说话的数量来标准化得分。然后,我们使用两个指标之间的平均值和差值来描述数据集中对话的类型。平均值显示了每个指标的重要性,例如每次对话的平均问题数量:
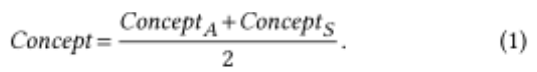
这种差异可以用来比较对话参与者之间的分布(平衡),例如在对话中谁问了更多的问题。我们使用类似于[13]的写作风格的公式:
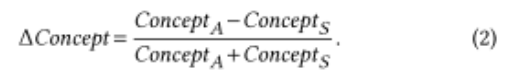
它不仅表明了不同角色之间的指标差异,而且还表明了其方向:负值表示Seeker的主导地位,正值Assistant表示Assistant的主导地位。
3. 数据集
我们的分析跨越了10个公开可用的对话数据集,这些数据集是为各种对话任务而设计的。括号中的数字表示每个数据集中对话的数量。

4.结果
表1显示了前一节中每个对话集的平均ConversationShape。这种表示允许比较集合并识别不同的对话类型,例如,图1显示了基于问题和信息分布的相似性而出现的集群。

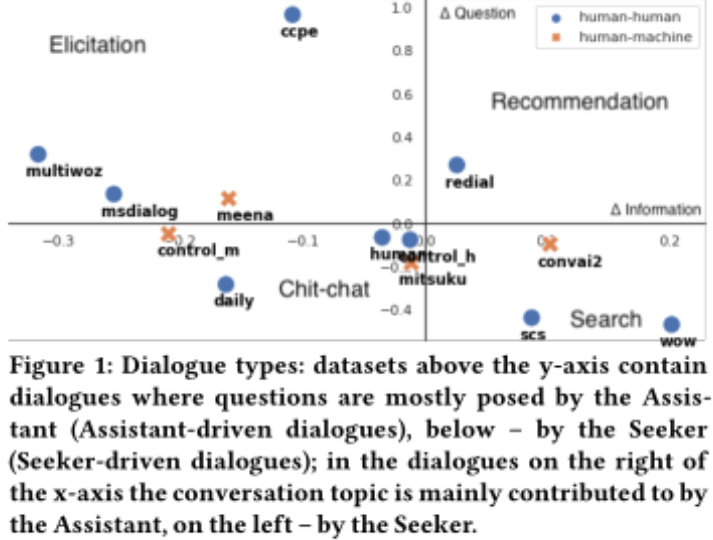
助手驱动对话(Assistant-driven dialogues):从表1中我们可以看到,在CCPE中,助理通过提出问题来引导对话,探索者通过回答问题来跟进(负∆重复)。MultiWOZ和MSDialog也有助理提出的大部分问题,但这些问题是紧跟着探索者提供的问题和答案(正∆重复)。在“ReDial”中,助理通过提供信息和提问来推动对话,而探索者则继续跟进(负∆重复)。

探索者驱动对话(Seeker-driven dialogue):SCS和WoW的相似之处在于:搜索者主要是提问,助理主要是提供信息。然而,在WoW中,导引头会继续跟随助手介绍的主题(负∆重复),而在SCS中,助手会跟随导引头。聊天对话(Human和Control-H)似乎更接近于起源,表明这种对话类型的参与者之间的主动性更平衡。然而,在DailyDialog数据集中,主动权倾向于对话发起者,后者更有可能提出问题并设置对话主题。
模型诊断:ConversationShape有助于评价对话模式,理解对话模式所表现出的越轨行为类型。这些实验是在Control-M数据集的子集上进行的,这些子集对应于不同对话模型产生的文本。总共有28个模型,我们分别计算每个模型的ConversationShape。然后,我们测量模型分布和为人类-人类对话子集(Control-H)计算的分布之间的交叉熵。最后,我们将我们的结果与原始论文[23]中报道的人类评价结果进行比较。与人类-人类分布的交叉熵最低(0.01)的模型,也是人类法官关于兴趣偏好的模型,其特征是更好的flow和更多的信息共享(information sharing)。
此外,ConversationShape允许解释对话模型所展示的偏差类型。在图2中,我们正确地识别出了问太多问题(优化为好奇、面试官)、重复太多(优化为响应性、鹦鹉式)或没有跟进(优化为多样性或消极响应性、说话者式)的模型。在比较Meena和Mitsuku对话[1]的transcripts时,我们无法达到同样的结果。问题分布表明,Meena和Mitsuku对话在结构上彼此非常不同,也不同于典型的人类闲聊分布。Mitsuku正在被审讯,而Meena则主动提出问题。
5. 结论
在本文中,我们介绍了ConversationShape框架,该框架提供了一组简单但有效的无监督度量,旨在度量会话的主动性和流(flow)。我们的分析揭示了不同对话类型之间的关系,并提出了一组适合在开发和评估对话系统或收集新的对话数据集时考虑的维度。我们的“Repetition”度量(估计会话主题的后续内容)是相当粗糙的,因为它只考虑词法匹配和回指语。尽管我们表明它足以对数据集分布进行高级分析,但预测单个对话的质量需要更细粒度的检查。未来的工作应该集中在开发一个可以解释token之间语义相似度的扩展。下一步将这些指标合并到一个学习算法的优化标准,模型提供一个适当的视角的对话,给一个明确的激励来控制一个适当的平衡,,正如我们所展示的,取决于对话的类型。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!


