
热门标签
热门文章
- 12024年最新基于STM32的OV7670摄像头总结_ov7670 dma,看这篇文章就行了
- 2机器人操作实验——抓取及路径实现_机器人抓取实验配置
- 3成为一个优秀的测试工程师需要具备哪些知识和经验?_测试人员需要掌握哪些知识
- 4Vue3-elelment-admin 中 Git提交出现问题_vue3用git提交报错
- 590%国际3A游戏发行商的首选,一文揭秘语音驱动面部动画生成技术!_网易数智
- 6DCMM五个等级,怎么计算出来的?看完你就懂了_dcmm评分标准
- 7分享一个基于Node.js和Vue的农产品销售与交流平台(源码、调试、LW、开题、PPT)
- 8python网络爬虫开发从入门到精通下载_Python网络爬虫开发从入门到精通
- 9Docker_可信镜像中心
- 10【口令爆破】SNETCracker 超级弱口令检查工具 (渗透测试、爆破必备神器!)
当前位置: article > 正文
Kimi仅用5秒钟就帮我抓取了5页文章素材
作者:运维做开发 | 2024-07-31 11:37:31
赞
踩
Kimi仅用5秒钟就帮我抓取了5页文章素材
熟悉我的宝子,都知道我现在开发各类RPA机器人,目前已经投入使用的机器有15款,有需要的小伙伴可以私聊我。
周末在家唱着歌儿,搬着砖的时候,突然一个弹框提醒提示我要进行生财打卡了。原来是我报名了生财有术的AI编程大航海了呀。
其中一个很重要的任务就是通过大模型,让大模型编写代码爬取公众号的文章。
1. 编写提示词
你是一个资深爬虫开发工程师,擅长使用Python语言编写爬虫程序,现在有如下任务:
写一个爬虫程序,按下面的要求在我的 windows 电脑上帮我抓取微信公众号文章。
使用 python3 和最新版的 selenium
目标网站:https://weixin.sogou.com/
输入关键字[ RPA ],点击[ 搜文章 ]按钮
爬取内容: 爬取标题、摘要、链接、来源
爬取后的内容保存到Excel文件中,Excel文件命名为AI_微信_时间
爬取前5页,每爬完1页休眠5s
请首先解析目标网站,然后给我完整可运行的程序,让我看到浏览器中操作的过程,并指导我安装程序依赖的所有库。
你可以先执行步骤 2 和步骤 3 了解网页的结构,然后再生成代码。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2. Kimi快速生成代码中
3.生成代码
import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service from openpyxl import Workbook # 配置WebDriver chrome_drive_path = r'E:\develop\chromedriver-win64\chromedriver.exe' # 设置ChromeDrive服务 service = Service(chrome_drive_path) # 初始化WebDriver options = webdriver.ChromeOptions() driver = webdriver.Chrome(service=service, options=options) # 目标网站 url = "https://weixin.sogou.com/" # 爬取前5页 pages_to_scrape = 5 # 打开目标网站 driver.get(url) # 等待页面加载 time.sleep(2) # 找到搜索框并输入关键字 search_box = driver.find_element(By.CSS_SELECTOR, "input.sec-input") search_box.send_keys("RPA") # 找到搜索按钮并点击 search_button = driver.find_element(By.XPATH, "//input[@uigs=\"search_article\"]") search_button.click() # 创建Excel工作簿 wb = Workbook() ws = wb.active ws.append(["标题", "摘要", "链接", "来源"]) # 开始爬取 for page in range(pages_to_scrape): # 等待页面加载 time.sleep(5) # 找到所有文章的容器 articles = driver.find_elements(By.XPATH, "//ul[@class=\"news-list\"]/li") for article in articles: # 爬取标题 title = article.find_element(By.XPATH, ".//div/h3").text # 爬取摘要 summary = article.find_element(By.XPATH, ".//div/p").text # 爬取链接 link = article.find_element(By.XPATH, ".//div/h3/a").get_attribute("href") # 爬取来源 source = article.find_element(By.XPATH, ".//div/div").text # 将爬取的数据写入Excel ws.append([title, summary, link, source]) # 如果不是最后一页,点击下一页 if page < pages_to_scrape - 1: next_page_button = driver.find_element(By.XPATH, ".//a[@id=\"sogou_next\"]") next_page_button.click() time.sleep(5) # 休眠5秒 # 保存Excel文件 current_time = time.strftime("%Y%m%d_%H%M%S") file_name = f"RPA_微信_{current_time}.xlsx" wb.save(file_name) # 关闭浏览器 driver.quit() print(f"爬取完成,数据已保存至 {file_name}")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
4. 代码运行效果
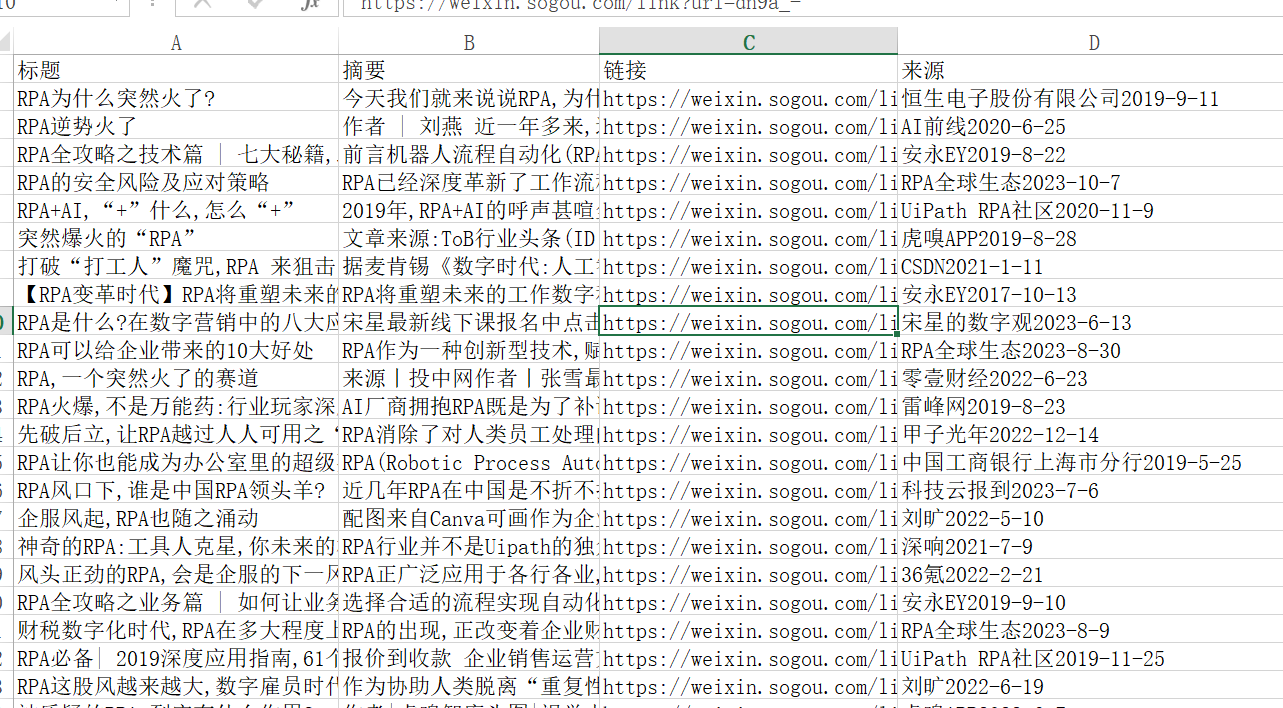
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/908640
推荐阅读
相关标签

