
- 1electron+vue3全家桶+vite项目搭建【二】vite自动引入插件,按需引入element-plus_electron vite vue3 elements-plus
- 2不一样的Gradle多渠道配置总结_build.gradle 多渠道
- 3元宇宙中的云计算,提升你的数字体验_元宇宙云计算应用
- 4Nature Communications|华中科技大学丁汉院士-吴志刚教授团队成果:昆虫尺度水面推进器_丁汉 nature communication
- 5Kafka的基本使用_kafka集群上关闭生产和消费的命令
- 6猿创征文|Hadoop大数据技术_大数据技术文章英文
- 7【记录】Python3|Selenium4 极速上手入门(Windows)_selenium 4.11.2
- 8boot1 io口 stm32,stm32 Boot0,Boot1引脚设置
- 9python如何爬取sci论文中所需的数据_sci论文中的科研数据处理方法
- 10Opencv-python教程(5)——图像算术和逻辑OpenCV_python 图像逻辑运算
知识图谱技术分享会----有关知识图谱构建的部分关键技术简介及思考_知识库构建 关键技术
赞
踩
昨天在北理工参加了一场由 雪晴数据网和北京理工大学大数据创新学习中心联合举办的知识图谱分享活动,聆听了一下午报告,可谓是受益匪浅。一下午时间安排的非常饱满,总共三场报告。
不得不说首都的学校就是厉害啊,楼都这么漂亮。

下面我就来分别说说重点和感想。
1.佛学知识图谱构建技术
东南大学 漆桂林教授

1.1 什么是知识?

1.2 知识图谱为搜索引擎带来的补充作用!
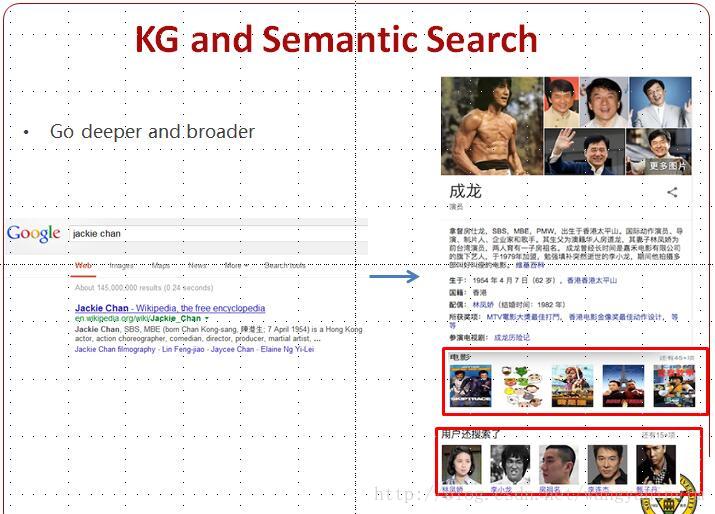
1.3知识图谱的几个关键技术
1.data extraction
数据从哪里来?
2.entity matching
就是说怎么知道beijing和北京是一个东西
3.type inference
e.g. China is an instance of country
1.Explicit IsA Relation Detector
2.Category Attributes Generator
3.Instance Type Ranker
- 1
- 2
- 3
以上步骤中包含一些复杂算法,我个人觉的偏工程应用,具体参考ppt,在下载链接中。
1.4 data extraction实战
报告的老师基于以上内容给出了一个课堂小实战训练,让我们直观体验了一下构建知识图谱中的基础性工作,知识抽取,从非结构化数据中抽取结构化内容,这和我们大数据领域中首当其冲的数据清洗步骤是不谋而合的。
实例文本:
*************************************************************************
title:大报国慈仁寺
大报国慈仁寺,俗称报国寺,位于北京市西城区,在广安门内大街路北。
经考证报国寺始建于辽代;明代塌毁,成化二年(1466年)重修,改名慈仁寺,俗称报国寺;清乾隆十九年(1754年)重修,更名为大报国慈仁寺。曾有七进院落,七层殿堂,后有毗卢阁,为当时北京南城最大庙宇。1900年因义和团在此寺设坛,被八国联军用炮轰毁。现全寺已修整一新,辟作“报国寺文化市场”,成为中国收藏活动著名的聚集地。
明清之际学者顾炎武(字亭林)在北京时曾住该寺西院。道光二十三年(1843年)改西院为顾亭林祠。如今在各种古旧书籍、钱币邮票、古玩首饰等的商摊中,祠堂已不可见,只余《顾亭林先生祠记》和《重建顾亭林先生祠记》两块碑文记载当年旧事。
目前每周四为报国寺文化市场交易日。
*************************************************************************
title:法门寺
法门寺,又称法云寺、阿育王寺,位于中国陕西省宝鸡市扶风县城北10公里处的法门镇。始建于东汉末年桓灵年间,距今约有1700多年历史,有“关中塔庙始祖”之称。法门寺因舍利而置塔,因塔而建寺,原名阿育王寺。释迦牟尼佛灭度后,遗体火化结成舍利。1980年以来,法门寺在前任方丈澄观、净一法师的住持下,相继建成大雄宝殿、玉佛殿、禅堂、祖堂、斋堂、寮房、佛学院等仿唐建筑。现任主持为中国佛教协会副会长学诚法师。
=== 建寺 ===
关于建寺时间,从唐代时就已无法准确确定了。有一种说法认为法门寺及真身宝塔始建于古印度孔雀王朝阿育王(前273年~前232年)时期。阿育王统一印度后为了弘扬佛法,将佛的舍利分送世界各地,兴建八万四千塔。中国有十九处,法门寺为第五处,先建塔后建寺。北周以前法门寺名为阿育王寺,寺塔名为阿育王塔。另一种说法受到了出土的汉代瓦当、砖刻的支持,认为法门寺建于东汉桓灵之世。
公元558年,北魏皇室后裔拓跋育曾扩建,并于元魏二年(494年)首次开塔瞻礼舍利。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
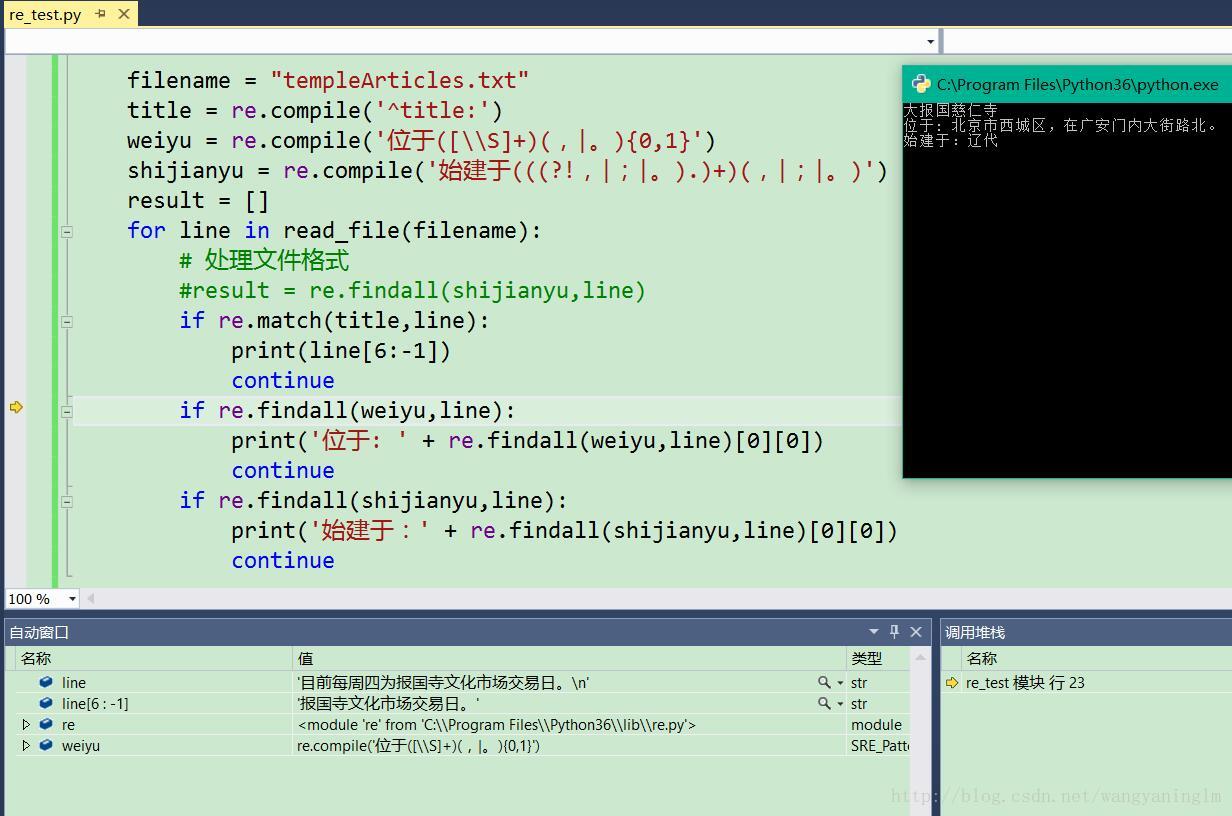
基于给出的文本文件,进行正则表达式的提取python3脚本:
#-*-coding:utf-8-*-
import re
def read_file(filename):
with open(filename, encoding='utf-8') as fd:
for line in fd:
yield line
if __name__== "__main__":
filename = "templeArticles.txt"
title = re.compile('^title:')
weiyu = re.compile('位于([\\S]+)(,|。){0,1}')
shijianyu = re.compile('始建于(((?!,|;|。).)+)(,|;|。)')
for line in read_file(filename):
# 处理文件每一行文件
if re.match(title,line):
print(line[6:-1])
continue
if re.findall(weiyu,line):
print('位于: ' + re.findall(weiyu,line)[0][0])
continue
if re.findall(shijianyu,line):
print('始建于:' + re.findall(shijianyu,line)[0][0])
continue

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
处理结果:
1.5 不能简单使用正则的场景
无法用规则抽取的原因:
句式种类繁多,无法找到高质量且匹配多的规则。
只能界定属性值的一个边界。(如:用规则“(,|。){0,1} ([\S]+)担任主持”匹配上述5个句子,能得到“,并由其徒弟佛智法师”和“,之后交由第一世创古仁波切”,但是无法找到法师名字的前边界)

对于这种问题,需要使用多规则来进行抽取,包括但不限于机器学习深度学习等。
1.6 总结
整体给我的直观感觉是,知识图谱的构建工作是需求驱动的,它需要非常多的人工参与才能构建精确,并且能为你的搜索引擎,智能问答系统提供锦上添花的作用。
2.知识图谱应用关键技术及行业应用

这一场略微有广告嫌疑,不过报告老师提到了面向数据的互联网这个新奇的概念。并且突出了互联网本体,实体的概念。本体中突出和强调的是概念以及概念之间的关系。
2.1 本体以及什么是知识图谱

2.2 知识图谱的部分应用
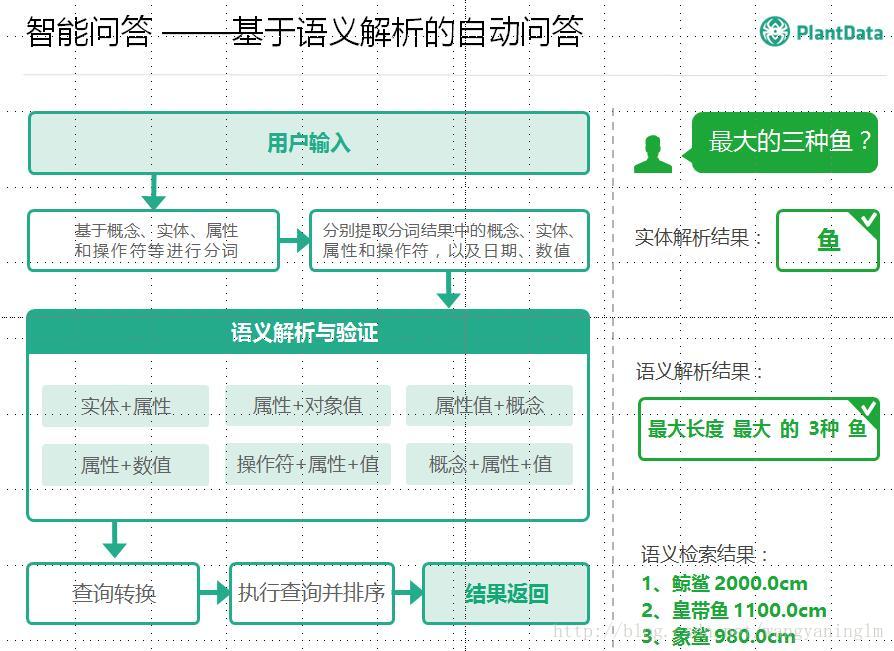
2.3 时代的变化,思维的变化

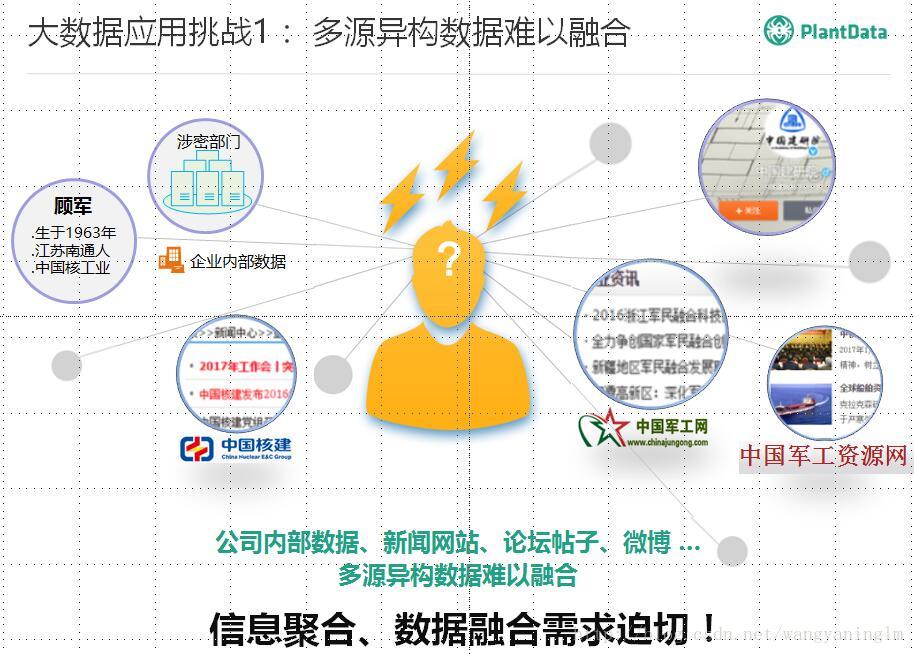
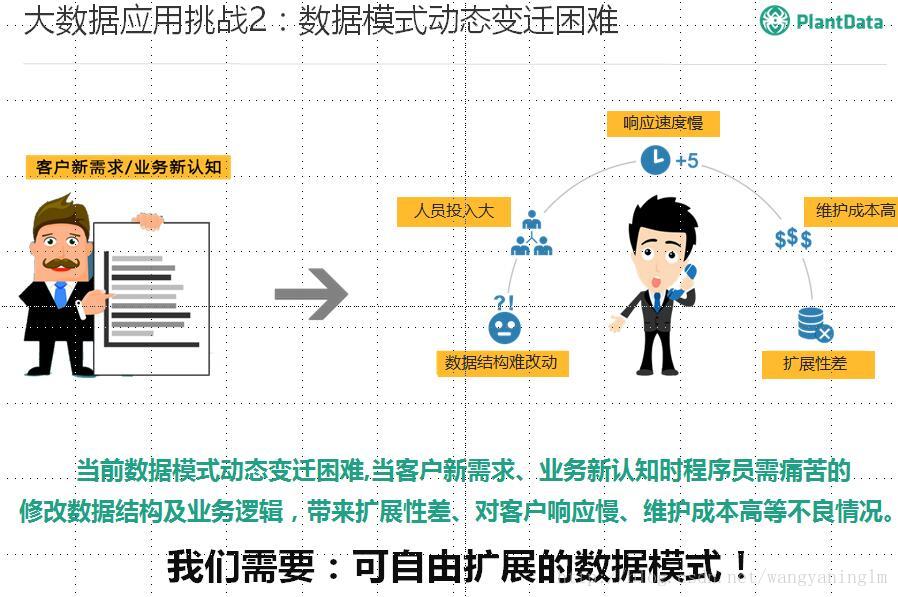
2.4 大数据应用的挑战—-多源异构数据的融合
这块老师总结的非常到位,我司也面临同样的问题,知识图谱可以解决这两个问题么?我们拭目以待!
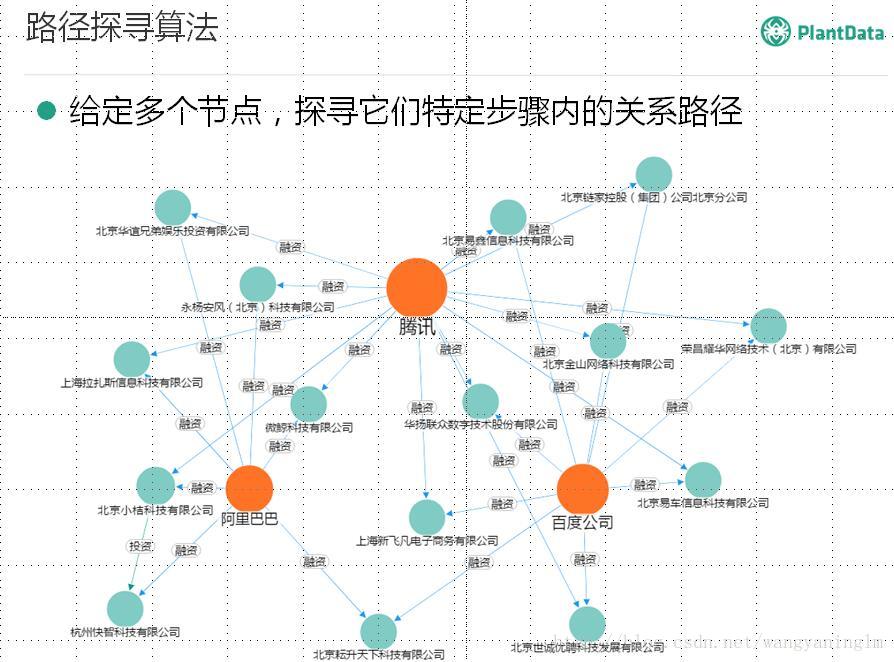
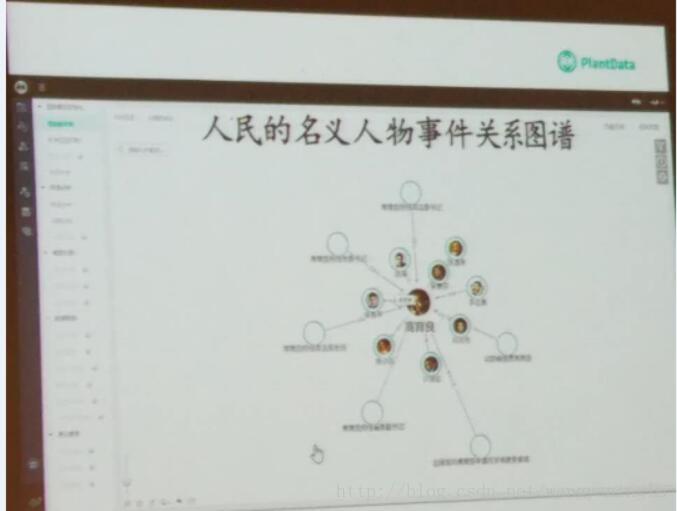
2.5 人民的名义—-关系图谱发掘
现场咨询了老师,他说是echarts结合一些其他定制技术做的效果,这块暂时没有拿到视频,是现场手机拍摄 的,大家凑活看吧。

3.中文知识图谱CN-DBpedia构建的关键技术
徐波
复旦大学知识工场实验室
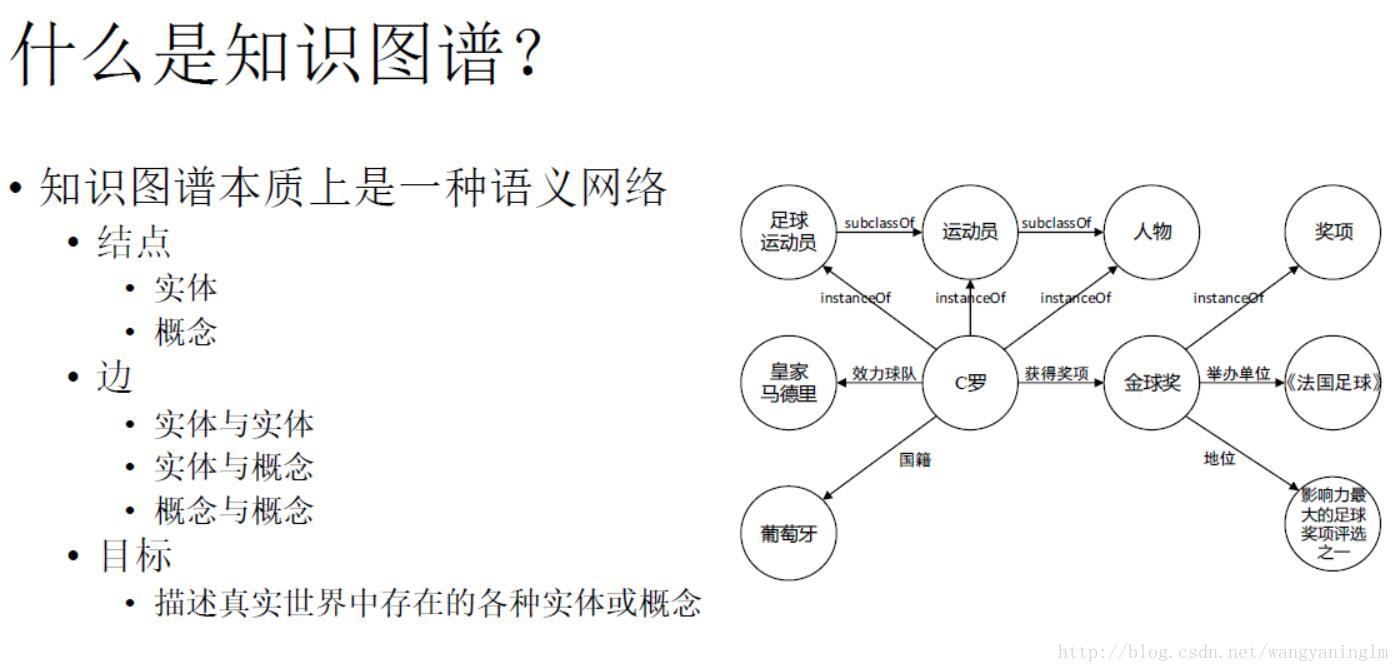
徐老师这个报告真的是干货满满,他讲了非常多的技术细节,包括cn-dpedia的架构,以及我印象比较深刻的cn-dbpedia中知识更新的问题,以及采用深度学习来抽取特征的新思路。
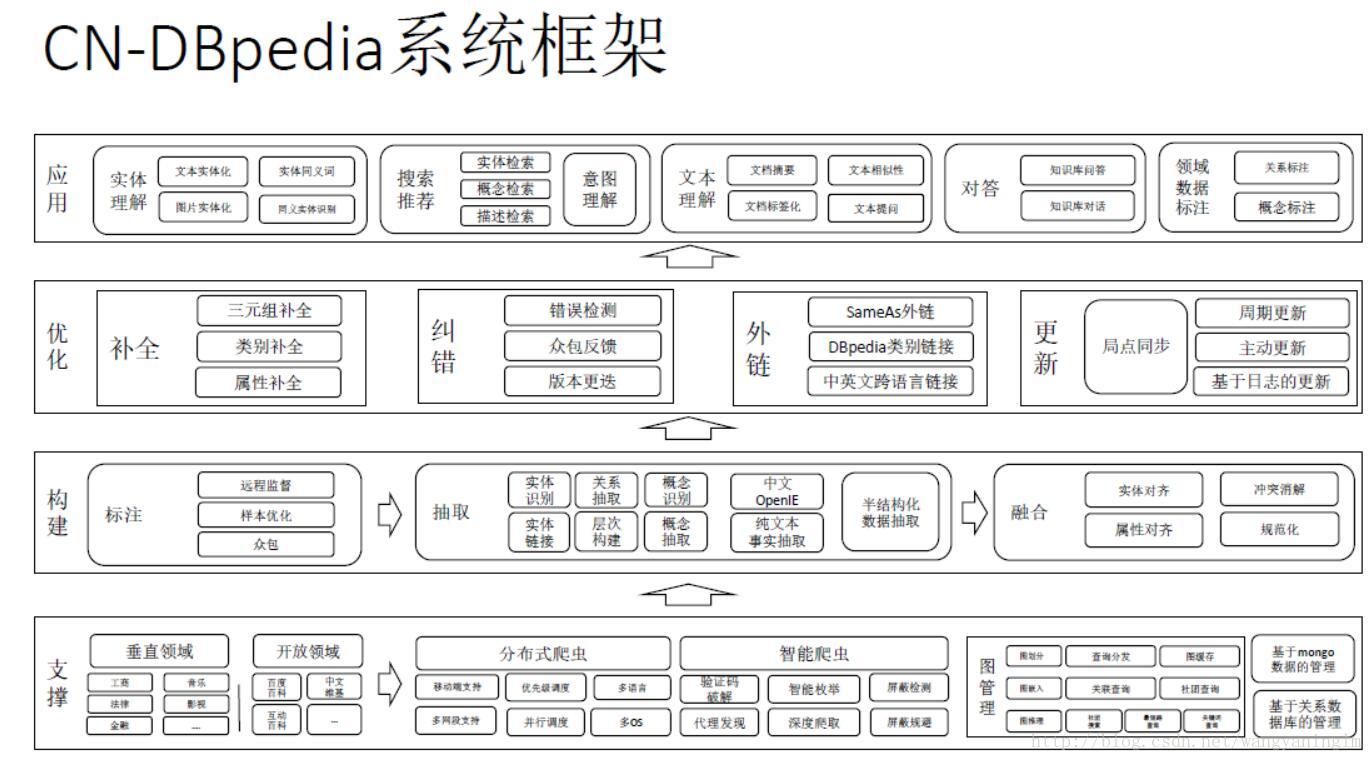
3.1 CN-DBPEDIA系统框架
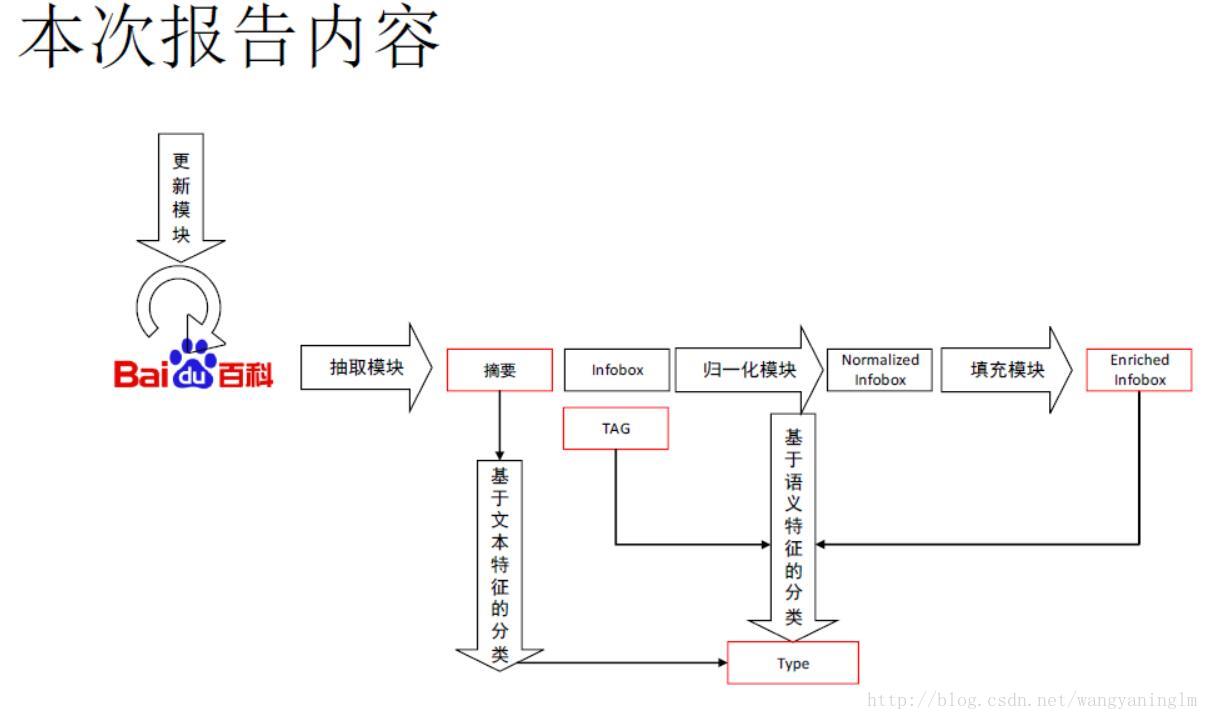
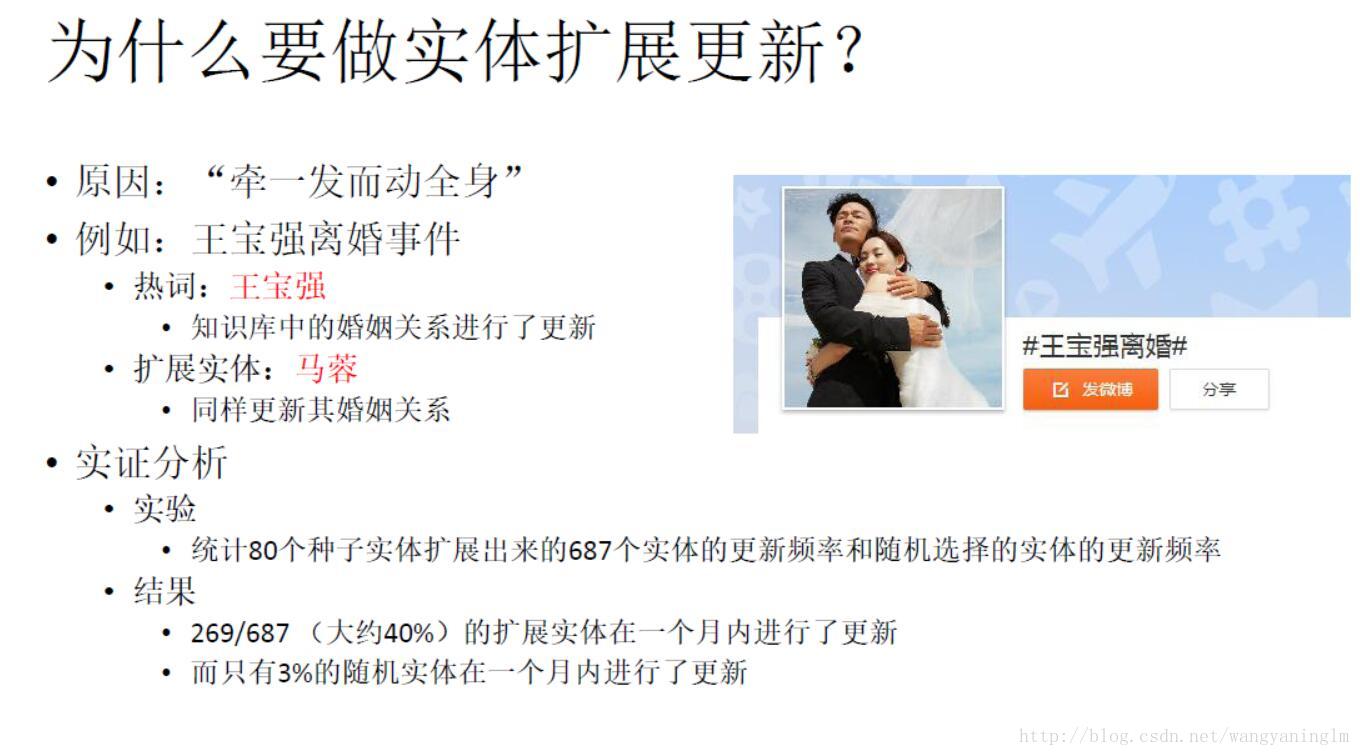
3.2 知识库实体更新

参考文献
以上三场报告ppt

