
- 1网络药理学:autodock tool(mgltools)实现大分子蛋白(PDB ID已知)和小分子配体的分子快速实践流程总结
- 2RabbitMQ基础知识使用springboot整合_rabbitmq基础spring boot配置
- 3【高级应用篇】深入Spring Boot与RabbitMQ:构建可靠的微服务通信_robitmq微服务
- 4ReentrantReadWriteLock读写锁的使用_reentrantreadwritelock.writelock[]
- 5VannaAI 介绍及使用 - 第一篇_vanna ai
- 625个网络安全搜索引擎备忘录_网络空间搜索引擎有哪些
- 7mysql优化_优化 mysql 及 原因
- 8EureKa学习_urka 配置
- 9从 Flask 迁移到 FastAPI_flask转fastapi
- 10Kali Linux 连接无线_kali available networks空
什么是大语言模型(LLM)_大模型(large language model, llm),又称生成式预训练模型,原理是基于深度学
赞
踩
简介
大型语言模型(Large Language Models,简称LLM)是一类基于深度学习的人工智能模型,旨在处理和生成自然语言文本。通过训练于大规模文本数据,这些模型能够理解并生成与人类语言相似的文本,执行包括文本生成、翻译和情感分析等多种自然语言处理任务。LLM的重要性在于其广泛的应用场景,从自动化客户服务到高级研究,都显示出其强大的实用性和潜力。
技术架构
Transformer架构
LLM的核心技术架构是Transformer,这是一个基于自注意力机制的深度学习模型,首次在2017年的论文《Attention is All You Need》中提出。Transformer架构的关键在于其能够并行处理序列数据,大大提高了模型的训练效率和性能。
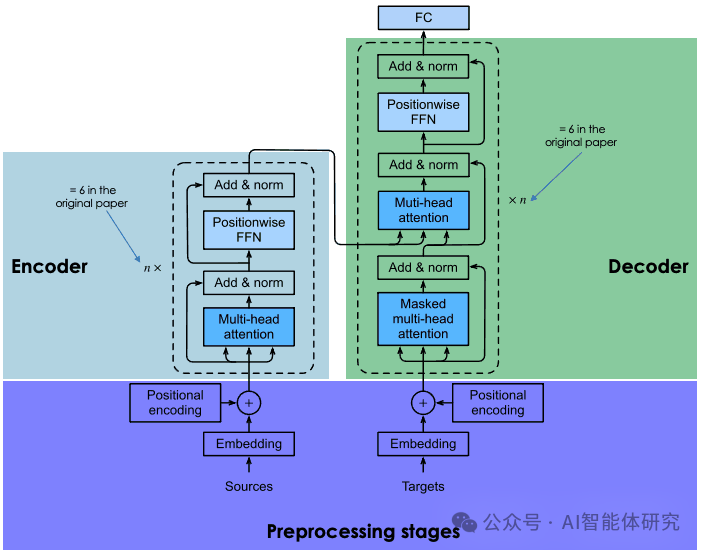
Transformer架构
神经网络与参数规模
LLM通常采用大规模神经网络,参数数量从数百万到数十亿不等。例如,GPT-3拥有1750亿个参数,使其能够处理复杂的语言任务。参数规模的增加使模型具有更强的学习和泛化能力,但也带来了计算成本和资源需求的显著增加。
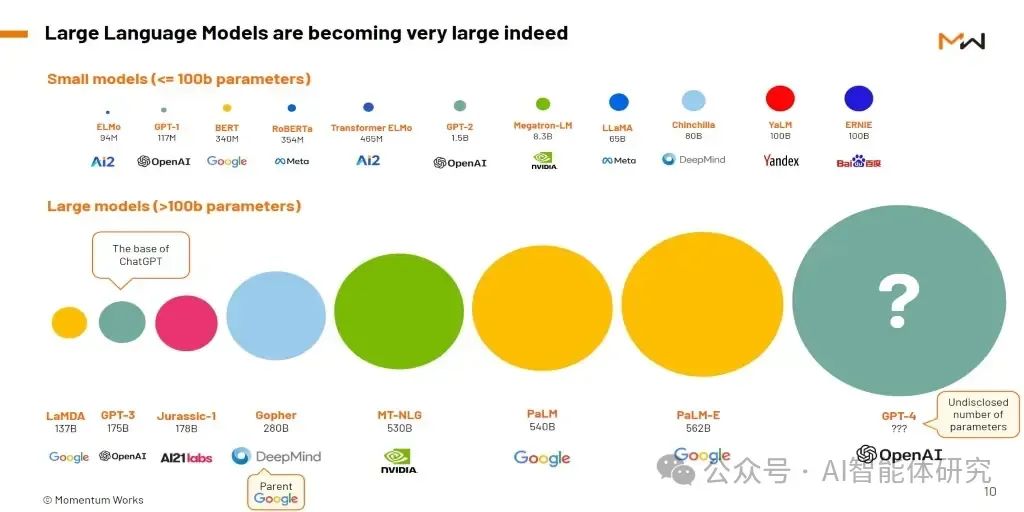
LLM的参数规模
工作机制
预训练与微调
LLM的训练过程分为预训练和微调两个阶段。预训练阶段,模型在大规模未标注文本数据上进行自监督学习,学习通用的语言表示。微调阶段,模型在特定任务的标注数据上进行有监督学习,调整模型参数以适应具体任务需求。
应用场景
文本生成
LLM可以生成高质量的自然语言文本,应用于自动写作、内容创作和对话生成等领域。例如,GPT-3能够根据输入提示生成完整的段落和文章,显示出强大的语言生成能力。
机器翻译
通过训练于多语言数据,LLM能够进行高质量的机器翻译。例如,Google的BERT模型在多种语言之间实现了精准的翻译,提高了跨语言交流的效率。
摘要生成
LLM可以从长篇文本中提取关键信息,生成简洁的摘要,广泛应用于新闻摘要、文献综述和报告生成等领域。
对话系统
基于LLM的对话系统能够理解用户输入并生成自然的对话回应,应用于智能客服、虚拟助手和聊天机器人等领域。例如,OpenAI的ChatGPT能够进行连贯且富有逻辑的对话,提高了用户体验。
情感分析
LLM可以分析文本的情感倾向,帮助企业了解客户情绪和市场反应。例如,通过分析社交媒体评论和客户反馈,企业能够及时调整策略以提高客户满意度。
代表性模型
OpenAI的模型介绍
OpenAI最新的代表性模型是GPT-4o。这款模型在处理文本、语音和视频方面的能力得到了显著提升,并且在理解和讨论图像方面表现出色。GPT-4o不仅继承了GPT-4的智能水平,还在速度和多功能性上有所改进,能够支持超过50种语言的交互。
Google的模型介绍
Google的最新模型是Gemini系列。Gemini 1.5是这一系列的最新版本,采用了新的专家混合(Mixture-of-Experts, MoE)架构,使其在处理效率和性能上有了显著提升。Gemini 1.5 Pro支持最多100万token的上下文窗口,使其在处理长文本、代码库和视频时具有极高的效率和准确性。这些改进使得Gemini系列在多模态任务中的表现更加出色。
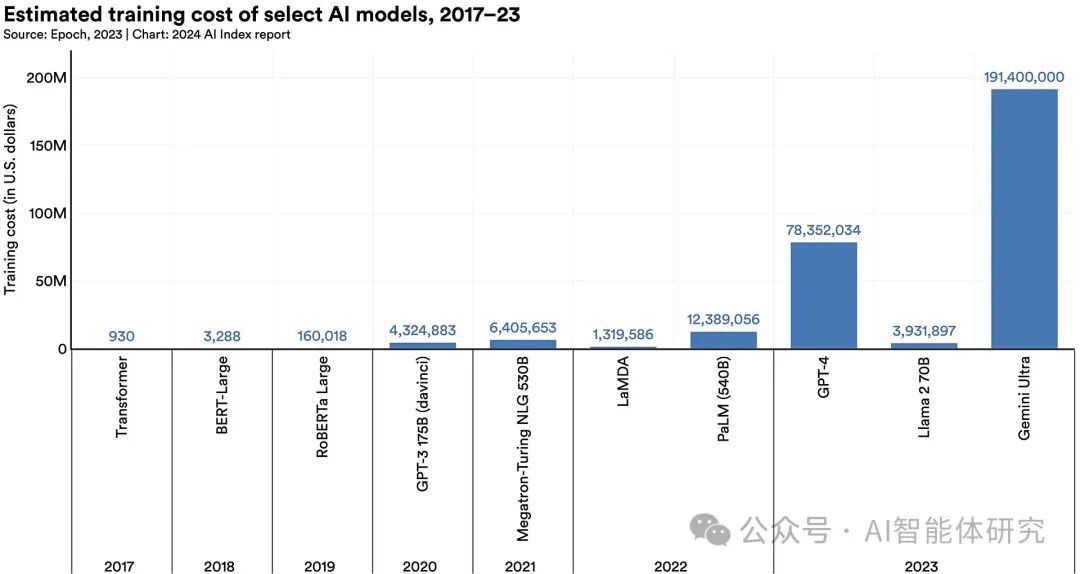
LLM的训练成本
挑战与考虑
计算资源与成本
训练和运行LLM需要大量计算资源和高昂的成本。大规模GPU集群或云计算平台是训练LLM的基础,这不仅增加了硬件成本,还带来了巨大的能源消耗。
数据偏见与伦理问题
LLM的训练数据通常来自互联网,难免包含各种偏见和错误信息。如何消除模型中的偏见,确保其生成的内容公正、准确,是一个重要的研究方向。同时,LLM的广泛应用也引发了隐私和伦理问题,需要在使用过程中谨慎对待。
模型透明度与解释性
LLM的复杂性使得其内部机制难以解释,导致其决策过程缺乏透明度。提高模型的可解释性,有助于增加用户对AI系统的信任,并确保其在关键任务中的可靠性。
历史与发展
LLM的发展经历了多个重要里程碑。从最初的基于统计语言模型,到引入神经网络和深度学习技术,再到Transformer架构的出现,LLM不断进化,性能不断提升。近年来,随着计算资源的增加和算法的优化,LLM的规模和能力达到了前所未有的高度。
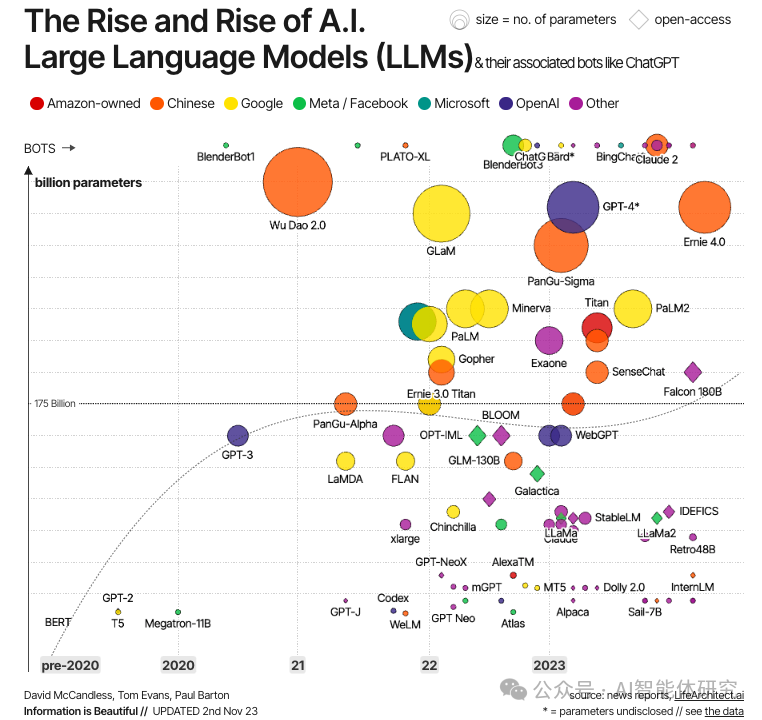
LLM的快速发展
未来展望
潜在的改进方向与应用前景
未来,LLM有望在以下几个方向取得进一步突破:
-
提高模型效率:通过优化算法和架构,降低训练和推理成本,提高能效比。
-
增强模型鲁棒性:开发更健壮的模型,减少偏见,提高对抗攻击的抵抗能力。
-
扩展应用领域:探索LLM在医学、法律、教育等领域的应用,提供更智能的解决方案。
-
提升用户体验:通过个性化定制和实时响应,提升用户与AI系统的互动体验。
LLM作为人工智能领域的重要技术,其发展潜力巨大,有望在未来继续推动科技进步和社会发展。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

