
- 1SpringBoot+Actuator,打造一款强大的监控和管理系统
- 2《机器人SLAM导航核心技术与实战》第1季:第8章_激光SLAM系统
- 3openVBN+MySQL用户认证
- 4多旋翼无人机仿真 rotors_simulator 是如何悬停的(一)_msgmultidofjointtrajectoryfrompositionyaw
- 5在 Docker 容器中运行 macOS:接近本机性能,实现高效运行 | 开源日报 No.96_docker运行macos镜像系统
- 6企业软件公司如何向云转型
- 7并查集(标准并查集、带权并查集、扩展域并查集)
- 8使用python操作neo4j_python怎么打开本地neo4j
- 9如何解决yarn install报错:Expected version “>=16“. Got “14.17.0“
- 102011-2023各省数字普惠金融指数数据(覆盖广度、使用深度和数字化程度)_中国数字普惠金融指数
AI产品经理必备:什么是LLM,有什么优劣势_什么是llm(language model)在搜索应用中的作用?你有过哪些与llm相关的调优和创新
赞
踩
LLM(Large Language Model大型语言模型)是一种人工智能技术,能够理解和生成自然语言文本。LLM可以应用于多种场景,包括自然语言理解、文本生成、机器翻译、对话系统、问答系统、文本摘要、情感分析等。可以帮助人们快速生成文章、回复邮件、翻译文本、进行智能对话等。

【1】大模型发展历

大模型的发展通常可以分为三个阶段:探索阶段、成熟阶段和普及阶段。每个阶段都有其特点和里程碑。
- 探索阶段:
-
特点:在这个阶段,大模型的概念和技术还在初步探索中。研究人员和机构开始尝试构建较大的神经网络,并探索其潜在的应用。
-
里程碑:例如,深度学习的复兴可以追溯到2006年,随后的几年中,研究人员开始开发更大、更复杂的神经网络模型。
- 成熟阶段:
-
特点:在这个阶段,大模型的技术开始成熟,模型规模和性能都有了显著提升。大模型开始在特定的领域和任务中展现出卓越的性能。
-
里程碑:例如,2018年OpenAI发布的GPT(生成对抗网络)模型,以及谷歌的BERT(双向编码器表示从转换器)模型,都是这个阶段的代表。这些模型在自然语言处理等领域取得了突破性的成果。
- 普及阶段:
-
特点:在这个阶段,大模型开始广泛地应用于工业界和日常生活中。模型的大小和复杂性继续增长,同时,更多的工具和平台的出现使得模型的开发和应用变得更加容易和普遍。
-
里程碑:例如,GPT-3的发布,这是一个拥有1750亿参数的巨大模型,它在多个任务中展示了惊人的性能,包括文本生成、翻译、代码编写等。GPT-3的发布标志着大模型进入了普及阶段,其API的提供使得广泛的应用开发成为可能。
【2】大模型的应用步骤
 大模型应用通常包括以下几个关键步骤:数据收集、设计模型、模型训练、模型测试和模型部署。下面详细介绍每个步骤:
大模型应用通常包括以下几个关键步骤:数据收集、设计模型、模型训练、模型测试和模型部署。下面详细介绍每个步骤:
- 数据收集:
-
确定数据需求:根据模型要解决的问题,确定所需数据的类型、量和质量。
-
数据采集:通过各种渠道收集数据,如公开数据集、爬虫、传感器等。
-
数据清洗:去除噪声、异常值和不相关的数据,确保数据质量。
-
数据标注:对于监督学习任务,需要对数据进行准确的标注。
-
目的:收集高质量、多样化的数据集,以训练模型。
-
步骤:
- 设计模型:
-
选择模型类型:根据任务类型(如分类、回归、生成等)选择相应的模型。
-
定义模型结构:确定网络的层数、神经元数目、激活函数等。
-
确定损失函数和优化器:选择适合问题的损失函数和优化算法。
-
目的:根据问题的性质和数据的特征,设计适合的模型架构。
-
步骤:
- 模型训练:
-
数据预处理:对数据进行标准化、归一化等预处理。
-
划分数据集:将数据分为训练集、验证集和测试集。
-
训练模型:使用训练集来训练模型,同时监控验证集的性能。
-
超参数调优:根据验证集的性能调整学习率、批大小等超参数。
-
目的:使用收集的数据来训练模型,调整模型参数以最小化损失函数。
-
步骤:
- 模型测试:
-
性能评估:使用测试集来评估模型的准确率、召回率、F1分数等指标。
-
可视化分析:通过可视化模型的预测结果来分析模型的错误类型。
-
模型调整:根据测试结果调整模型结构或训练过程。
-
目的:评估模型在未见过的数据上的性能,确保模型的泛化能力。
-
步骤:
- 模型部署:
-
模型固化:将模型转换为可以在生产环境中运行的形式,如ONNX、TensorFlow Lite等。
-
集成:将模型集成到应用程序中,如网站、移动应用或云服务。
-
监控与维护:持续监控模型的性能和稳定性,定期更新和优化模型。
-
目的:将训练好的模型部署到实际应用中,供用户使用。
-
步骤:
整个流程需要跨学科的知识和技能,包括数据科学、机器学习、软件工程和系统架构等。
【3】大模型的结构及分类
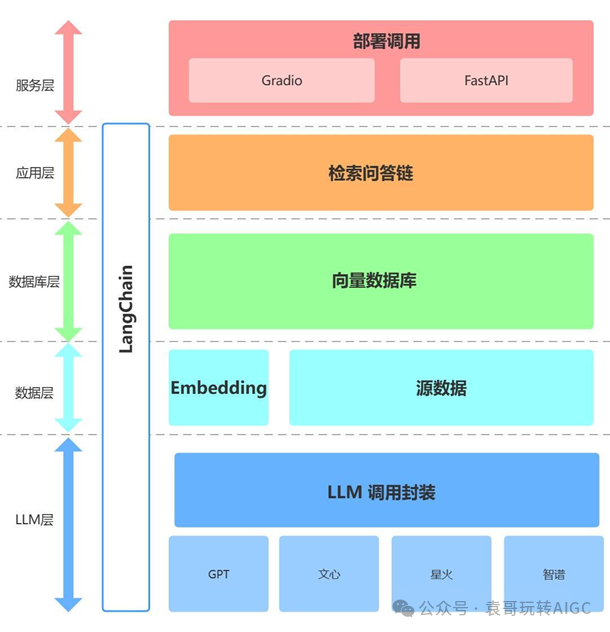
典型的大模型结构:
l最上层:各类应用
l中间层:数据处理、模型训练、工程能力、工 具开发等
l底层:基础大模型
常见的大模型分类
按结构分类:
l深度模型:包含多层神经网络的模型,例如深度卷积神经网络(CNN)和深度循环神经网络(RNN)。
l宽度模型:每一层有多个神经元的模型,如宽度卷积神经网络和宽度循环神经网络。
l深度宽度均衡模型:结合了深度和宽度的模型,如残差网络(ResNet)和深度分离卷积神经网络。
按用途分类:
l预训练模型:在大规模数据上进行预训练的模型,如BERT、GPT等。这类模型具有强大的语言理解和生成能力,能够应用于各种NLP任务。
l无监督学习模型:基于未标记数据的自学习模型,如聚类、降维等。这类模型能够在没有标签的情况下学习数据的内在结构和表示。
其他特定类型:
l自然语言处理大模型:如GPT系列,它们能够生成高质量的文本内容,应用于对话系统、内容创作等领域。
l计算机视觉大模型:如深度残差网络(ResNet)和卷积神经网络(CNN),它们能够处理图像和视频数据,实现图像分类、目标检测等任务。
上述分类只是大模型类型的一部分,实际上还有更多类型和变体存在, 且存在一个模型属于多种分类的情况。
然而,LLM也有其局限性。首先,它的理解和生成能力受限于训练数据集,如果数据集中存在偏见或错误,LLM可能会生成不准确或不公正的文本。其次,LLM可能无法理解复杂的人类情感和意图,因此在某些情况下可能无法生成恰当的回复。此外,LLM的生成结果可能存在重复、模糊或不相关的内容,需要人工进行修正和筛选。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

