
- 1【2024华为OD机试真题-C卷D卷-100分】分配土地【C++/Java/Python】_从前有个村庄,村民们喜欢在各种田地上插上小旗子,旗子上标识了各种不同的数字。
- 2Https证书浏览器红色警告解决_导入证书地址栏还是显示小红叉
- 3技术面试与 HR 谈薪资技巧_跟技术leader谈薪资,会不会不太好
- 4Python中文件数据流处理_python post判断是否有文件流
- 5Apache Kylin快速入门指南:大数据分析的利器
- 6SSM常用面试题60道(SpringMVC+Spring+Mybatis)_ssm面试题
- 7java中邮箱格式正则表达式_java使用正则表达式判断邮箱格式是否正确的方法
- 8Rust在内存安全方面的优势如何体现?有哪些内存安全实践?_rust为什么没有内存泄漏
- 9AI大型语言模型的关键技术解析_语言大模型关键技术
- 10socks4/5和http代理有什么区别
StarRocks 【新一代MPP数据库】
赞
踩
1、StarRocks
1.1、StarRocks 简介
StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing,MPP数据库是一种基于大规模并行处理技术的数据库系统,旨在高效处理大量数据。) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。用户无需经过复杂的预处理,就可以用 StarRocks 来支持多种数据分析场景的极速分析。
StarRocks 架构简洁,采用了全面向量化引擎,并配备全新设计的 CBO (Cost Based Optimizer) 优化器,查询速度(尤其是多表关联查询)远超同类产品。
简单来说,StarRocks 适合对 OLAP 数据库业务(Online Analytical Processing,联机分析处理)进行分析,同时它也可以对接一些外部系统,比如把 Spark、Flink 处理的数据结果写入到 StarRocks 中,这也是支持的。
StarRocks 兼容 MySQL 协议,支持标准 SQL 语法,易于对接使用,全系统无外部依赖,高可用,易于运维管理。StarRocks 还兼容多种主流 BI 产品,包括 Tableau、Power BI、FineBI 和 Smartbi。
StarRocks采用分布式架构,对数据表进行水平划分并以多副本存储。集群规模可以灵活伸缩,能够支持 10PB 级别的数据分析; 支持MPP框架,并行加速计算; 支持多副本,具有弹性容错能力。
StarRocks采用关系模型,使用严格的数据类型和列式存储引擎,通过编码和压缩技术,降低读写放大;使用向量化执行方式,充分挖掘多核CPU的并行计算能力,从而显著提升查询性能。
1.2、StarRocks 使用场景
StarRocks 可以满足企业级用户的多种分析需求,包括 OLAP (Online Analytical Processing) 多维分析、定制报表、实时数据分析和 Ad-hoc 数据分析等。
利用 StarRocks 的 MPP 框架和向量化执行引擎,用户可以灵活的选择雪花模型,星型模型,宽表模型或者预聚合模型。适用于灵活配置的多维分析报表,业务场景包括:
1.2.1、OLAP 多维分析
利用 StarRocks 的 MPP 框架和向量化执行引擎,用户可以灵活的选择雪花模型,星型模型,宽表模型或者预聚合模型。适用于灵活配置的多维分析报表,业务场景包括:
- 用户行为分析
- 用户画像、标签分析、圈人
- 高维业务指标报表
- 自助式报表平台
- 业务问题探查分析
- 跨主题业务分析
- 财务报表
- 系统监控分析
1.2.2、实时数据仓库
StarRocks 设计和实现了 Primary-Key 模型,能够实时更新数据并极速查询,可以秒级同步 TP (Transaction Processing) 数据库的变化,构建实时数仓,业务场景包括:
- 电商大促数据分析
- 物流行业的运单分析
- 金融行业绩效分析、指标计算
- 直播质量分析
- 广告投放分析
- 管理驾驶舱
- 探针分析APM(Application Performance Management)
1.2.3、高并发查询
StarRocks 通过良好的数据分布特性,灵活的索引以及物化视图等特性,可以解决面向用户侧的分析场景,业务场景包括:
- 广告主报表分析
- 零售行业渠道人员分析
- SaaS 行业面向用户分析报表
- Dashboard 多页面分析
1.2.4、统一分析
通过使用一套系统解决多维分析、高并发查询、预计算、实时分析查询等场景,降低系统复杂度和多技术栈开发与维护成本。
使用 StarRocks 统一管理数据湖和数据仓库,将高并发和实时性要求很高的业务放在 StarRocks 中分析,也可以使用 External Catalog 和外部表进行数据湖上的分析。
1.3、StarRocks 基本概念
- FE:FrontEnd简称FE,是StarRocks的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。功能类似于 Hadoop 中的 NameNode。
- BE:BackEnd简称BE,是StarRocks的后端节点,负责数据存储,计算执行,以及compaction,副本管理等工作。功能类似于 Hadoop 中的 DataNode。
- Broker:StarRocks中和外部HDFS/对象存储等外部数据对接的中转服务,辅助提供导入导出功能。这个工具不是必须安装的。
- StarRocksManager:StarRocks的管理工具,提供StarRocks集群管理、在线查询、故障查询、监控报警的可视化工具。
- Tablet:StarRocks中表的逻辑分片,也是StarRocks中副本管理的基本单位,每个表根据分区和分桶机制被划分成多个Tablet存储在不同BE节点上。
1.4、StarRocks 系统架构
StarRocks 架构简洁,整个系统的核心只有 FE(Frontend)、BE(Backend)两类进程,不依赖任何外部组件,方便部署与维护。FE 和 BE 模块都可以在线水平扩展,元数据和业务数据都有副本机制,确保整个系统无单点。StarRocks 提供 MySQL 协议接口,支持标准 SQL 语法。用户可通过 MySQL 客户端方便地查询和分析 StarRocks 中的数据。
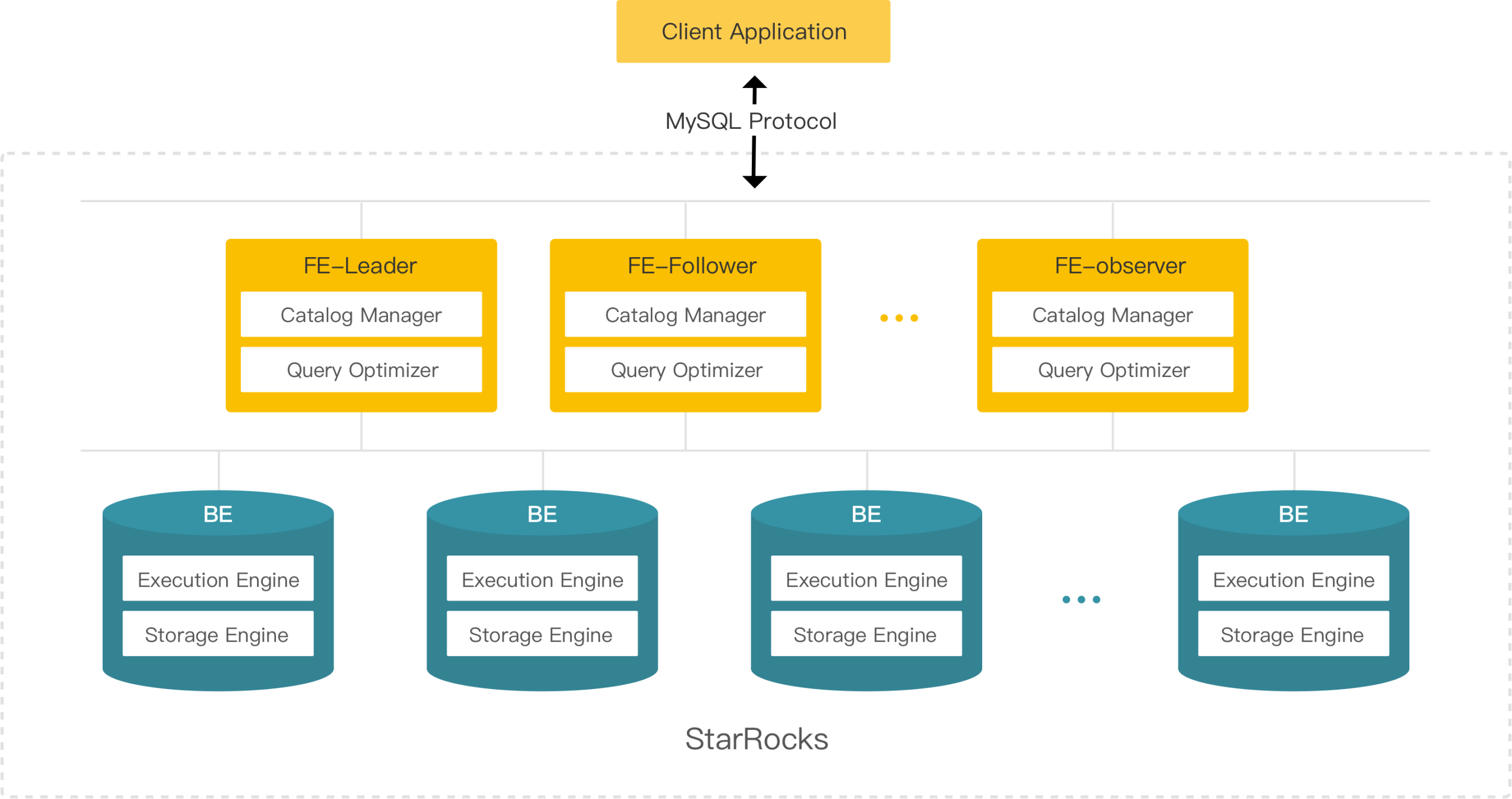
FE
FE 是 StarRocks 的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。每个 FE 节点都会在内存保留一份完整的元数据,这样每个 FE 节点都能够提供无差别的服务。
FE 有三种角色:Leader FE,Follower FE 和 Observer FE。Follower 会通过类 Paxos 的 Berkeley DB Java Edition(BDBJE)协议自动选举出一个 Leader。三者区别如下:
- Leader
- Leader 从 Follower 中自动选出,进行选主需要集群中有半数以上的 Follower 节点存活。如果 Leader 节点失败,Follower 会发起新一轮选举。
- Leader FE 提供元数据读写服务。只有 Leader 节点会对元数据进行写操作,Follower 和 Observer 只有读取权限。Follower 和 Observer 将元数据写入请求路由到 Leader 节点,Leader 更新完数据后,会通过 BDB JE 同步给 Follower 和 Observer。必须有半数以上的 Follower 节点同步成功才算作元数据写入成功。
- Follower
- 只有元数据读取权限,无写入权限。通过回放 Leader 的元数据日志来异步同步数据。
- 参与 Leader 选举,必须有半数以上的 Follower 节点存活才能进行选主。
- Observer
- 主要用于扩展集群的查询并发能力,可选部署。
- 不参与选主,不会增加集群的选主压力。
- 通过回放 Leader 的元数据日志来异步同步数据。
BE
BE 是 StarRocks 的后端节点,负责数据存储、SQL执行等工作。
- 数据存储方面,StarRocks 的 BE 节点都是完全对等的,FE 按照一定策略将数据分配到对应的 BE 节点。BE 负责将导入数据写成对应的格式存储下来,并生成相关索引。
- 在执行 SQL 计算时,一条 SQL 语句首先会按照具体的语义规划成逻辑执行单元,然后再按照数据的分布情况拆分成具体的物理执行单元。物理执行单元会在对应的数据存储节点上执行,这样可以实现本地计算,避免数据的传输与拷贝,从而能够得到极致的查询性能。
在进行 Stream load 导入时,FE 会选定一个 BE 节点作为 Coordinator BE,负责将数据分发到其他 BE 节点。导入的最终结果由 Coordinator BE 返回给用户。更多信息,参见 Stream load。
1.5、StarRocks 安装部署
解压安装这里就不再赘述了,需要注意的是,安装的时候使用用 root !而且 StarRocks 是集群安装。
- # 修改目录所有者和所有组
- sudo chown -R root:root StarRocks-1.19.1/
1.5.1、安装 FE
安装 FE 之前需要在 fe 目录下创建一个 meta 的目录!
[root@hadoop102 fe]# bin/start_fe.sh --daemon启动 MySQL 客户端节点:
注意:启动命令应该是 mysql -h hadoop102 -uroot -P9030 !!!(下面的截图是我普通用户安装的时候截的,但是不应该使用普通用户,而是使用 root 用户)
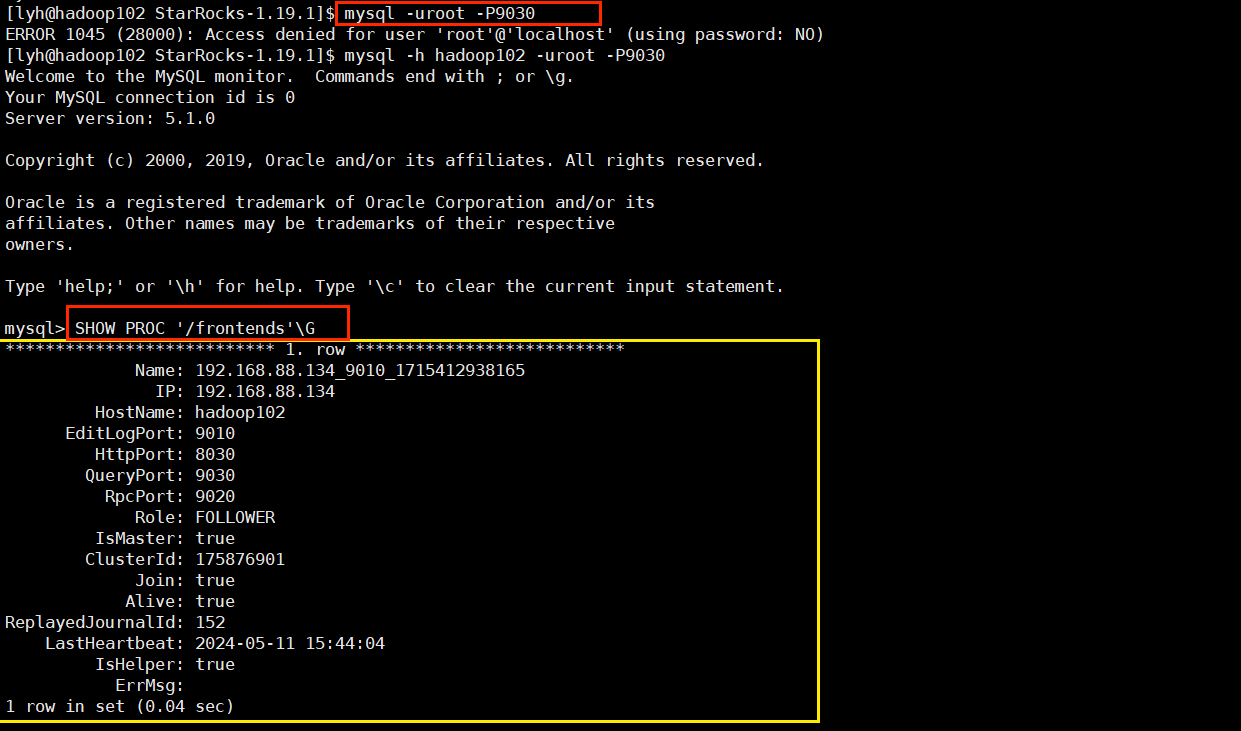
添加其他FE节点,角色也分为FOLLOWER,OBSERVER
- ALTER SYSTEM ADD FOLLOWER "hadoop103:9010";
-
- ALTER SYSTEM ADD OBSERVER "hadoop104:9010";
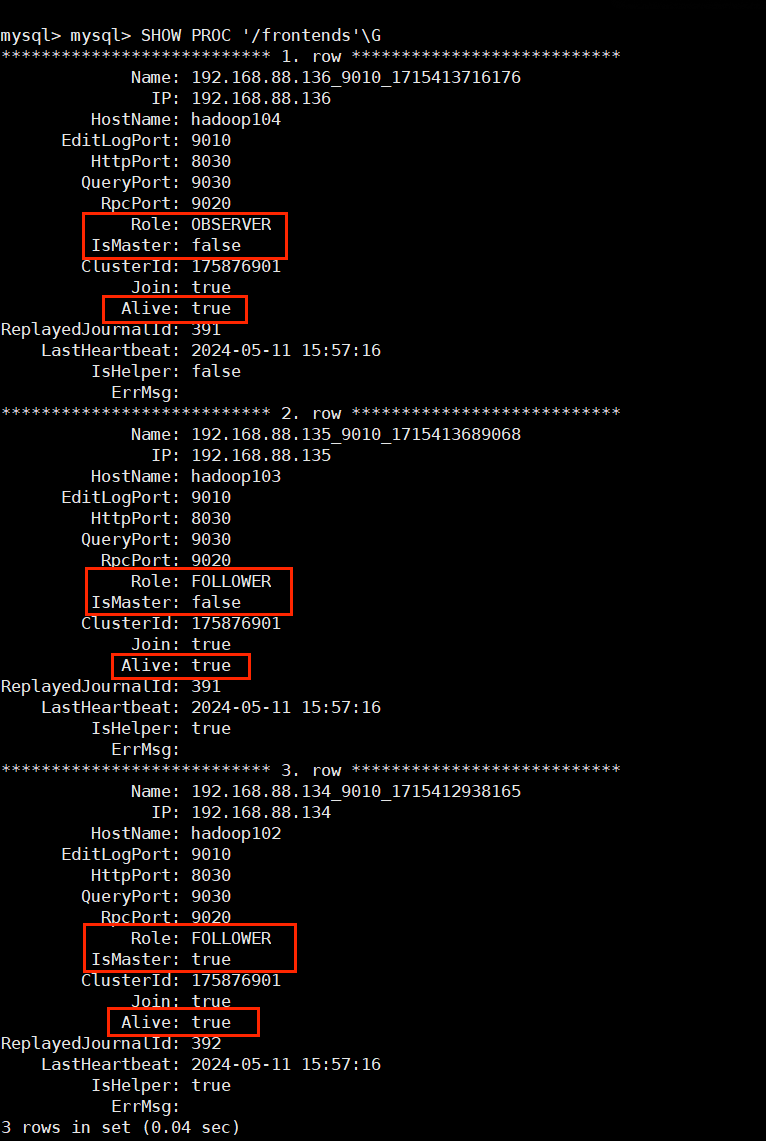
再次查看 StarRocks 集群状态:

可以看到,hadoop103 和 hadoop104 的 FE 节点并没有启动。所以在 hadoop103 和 hadoop104 上分别执行:
bin/start_fe.sh --helper hadoop102:9010 --daemon注意:只有第一次安装的时候需要指定 --helper !之后启动就不用了!
再次查看 StarRocks 集群状态:
1.5.2、安装 BE
和安装 FE 一样,安装 BE 也需要先在每个节点的 be 目录下创建一个 storge 目录:
mkdir -p storage在 mysql 客户端添加第一个 BE 节点:
ALTER SYSTEM ADD BACKEND "hadoop102:9050";启动 hadoop102 对应的 BE 节点:
bin/start_be.sh --daemon 在 MySQL 客户端添加 hadoop103 和 hadoop104 对应的 BE 节点:
- ALTER SYSTEM ADD BACKEND "hadoop103:9050";
- ALTER SYSTEM ADD BACKEND "hadoop104:9050";
启动 hadoop103 和 hadoop104 上的 be 节点:
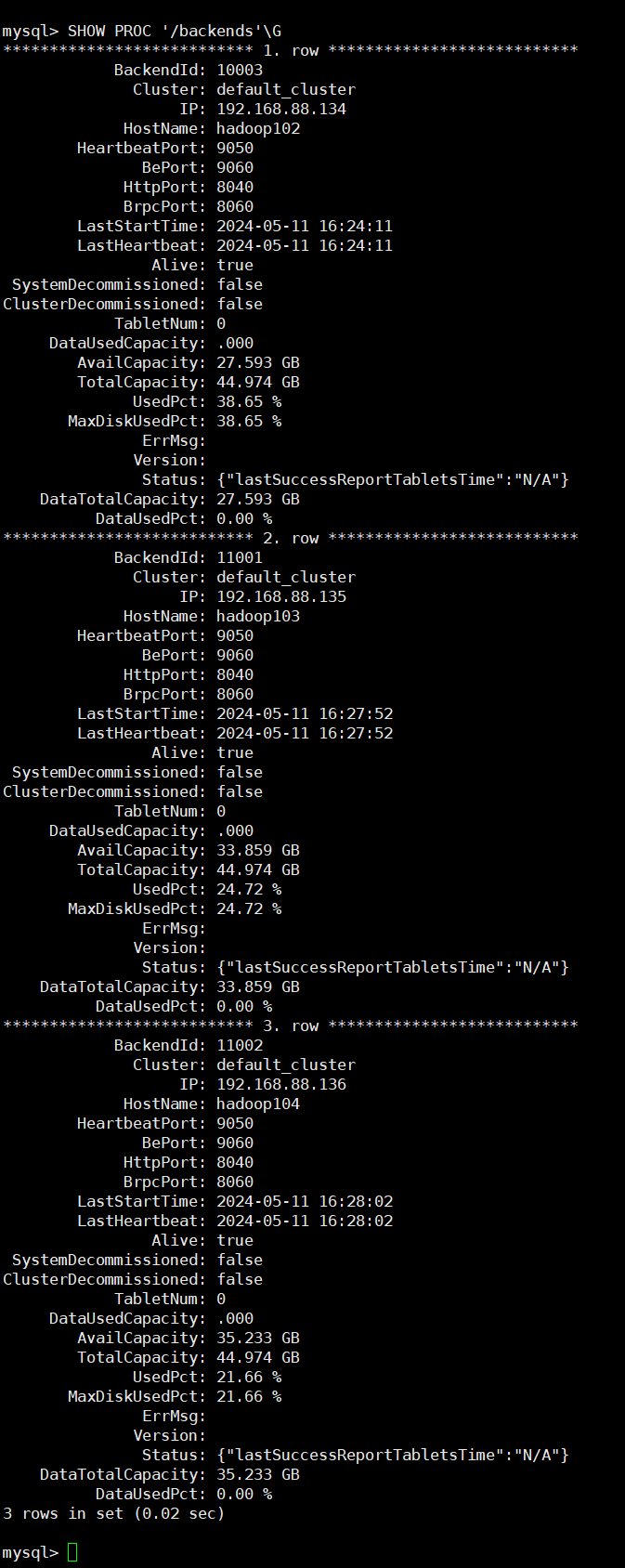
bin/start_be.sh --daemon注意:BE 节点启动后 jps 是不显示进程的,但是可以通过客户端查询它的状态。
查看 BE 状态:
1.5.3、安装 broker(可选)
分别在 hadoop102、hadoop103 和 hadoop104 上启动 broker 节点::
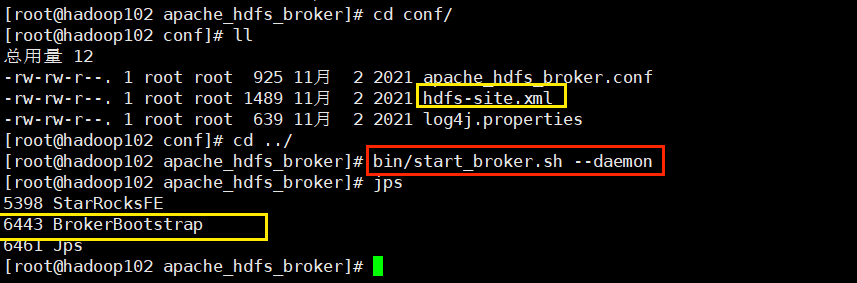
去 MySQL 客户端添加角色地址:
- ALTER SYSTEM ADD BROKER broker1 "hadoop102:8000";
- ALTER SYSTEM ADD BROKER broker2 "hadoop103:8000";
- ALTER SYSTEM ADD BROKER broker3 "hadoop104:8000";
查看 broker 节点状态:
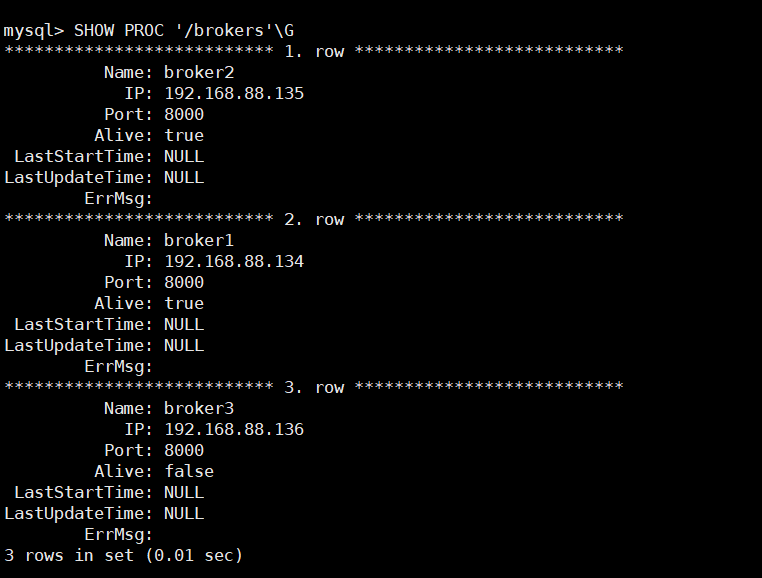
至此 StarRocks 安装完毕,没有想象的惊心动魄,万幸万幸。
2、StarRocks 表设计
2.1、列式存储
StarRocks的表和关系型数据相同, 由行和列构成. 每行数据对应用户一条记录, 每列数据有相同数据类型. 所有数据行的列数相同, 可以动态增删列. StarRocks中, 一张表的列可以分为维度列(也成为key列)和指标列(value列), 维度列用于分组和排序, 指标列可通过聚合函数SUM, COUNT, MIN, MAX, REPLACE, HLL_UNION, BITMAP_UNION等累加起来. 因此, StarRocks的表也可以认为是多维的key到多维指标的映射.
在StarRocks中, 表中数据按列存储, 物理上, 一列数据会经过分块编码压缩等操作, 然后持久化于非易失设备, 但在逻辑上, 一列数据可以看成由相同类型的元素构成的数组. 一行数据的所有列在各自的列数组中保持对齐, 即拥有相同的数组下标, 该下标称之为序号或者行号. 该序号是隐式, 不需要存储的, 表中的所有行按照维度列, 做多重排序, 排序后的位置就是该行的行号.
查询时, 如果指定了维度列的等值条件或者范围条件, 并且这些条件中维度列可构成表维度列的前缀, 则可以利用数据的有序性, 使用range-scan快速锁定目标行. 例如: 对于表table1: (event_day, siteid, citycode, username)➜(pv); 当查询条件为event_day > 2020-09-18 and siteid = 2, 则可以使用范围查找; 如果指定条件为citycode = 4 and username in ["Andy", "Boby", "Christian", "StarRocks"], 则无法使用范围查找.(因为它的第一个条件的字段是 citycode 对应不上 starrocks 的第一个维度列,所以就无法优化查询速度)所以我们在查询的时候需要尽量遵守这个规则。
2.2、稀疏索引
当进行范围查询时,StarRocks如何快速定位到起始目标行呢?答案是使用shortkey index. shortkey index为稀疏索引。
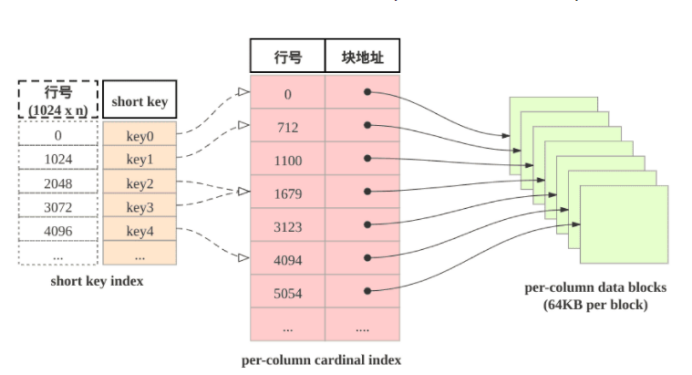
表中组织由三个部分组成:
(1)shortkey index表: 表中数据每1024行, 构成一个逻辑block. 每个逻辑block在shortkey index表中存储一项索引, 内容为表的维度列的前缀, 并且不超过36字节. shortkey index为稀疏索引, 用数据行的维度列的前缀查找索引表, 可以确定该行数据所在逻辑块的起始行号.
(2)Per-column data block: 这是实际存储数据的物理块(经过压缩)。表中每一列数据按64KB分块存储, 数据块作为一个单位单独编码压缩, 也作为IO单位, 整体写回设备或者读出.
(3)Per-column cardinal index: 专门存放地址。表中的每列数据有各自的行号索引表, 列的数据块和行号索引项一一对应, 索引项由数据块的起始行号和数据块的位置和长度信息构成, 用数据行的行号查找行号索引表, 可以获取包含该行号的数据块所在位置, 读取目标数据块后, 可以进一步查找数据.
由此可见, 查找维度列的前缀的查找过程为: 先查找shortkey index, 获得逻辑块的起始行号, 查找维度列的行号索引, 获得目标列的数据块, 读取数据块, 然后解压解码, 从数据块中找到维度列前缀对应的数据项.
2.3、加速数据处理
(1)预先聚合: StarRocks支持聚合模型, 维度列取值相同数据行可合并一行, 合并后数据行的维度列取值不变, 指标列的取值为这些数据行的聚合结果, 用户需要给指标列指定聚合函数. 通过预先聚合, 可以加速聚合操作.
(2)分区分桶: 事实上StarRocks的表被划分成tablet, 每个tablet多副本冗余存储在BE上, BE和tablet的数量可以根据计算资源和数据规模而弹性伸缩. 查询时, 多台BE可并行地查找tablet快速获取数据. 此外, tablet的副本可复制和迁移, 增强了数据的可靠性, 避免了数据倾斜. 总之, 分区分桶保证了数据访问的高效性和稳定性.
(3)RollUp表索引: shortkey index可加速数据查找, 然后shortkey index依赖维度列排列次序. 如果使用非前缀的维度列构造查找谓词, 则无法使用shortkey index. 用户可以为数据表创建若干RollUp表索引, RollUp表索引的数据组织和存储和数据表相同, 但RollUp表拥有自身的shortkey index. 用户创建RollUp表索引时, 可选择聚合的粒度, 列的数量, 维度列的次序; 使频繁使用的查询条件能够命中相应的RollUp表索引.
(4)列级别的索引技术: Bloomfilter可快速判断数据块中不含所查找值, ZoneMap通过数据范围快速过滤待查找值, Bitmap索引可快速计算出枚举类型的列满足一定条件的行.
2.4、数据模型
目前StarRocks根据摄入数据和实际存储数据之间的映射关系,分为明细模型(Duplicate key)、聚合模型(Aggregate key)、更新模型(Unique key)和主键模型(Primary key)。
四中模型分别对应不同的业务场景
2.4.1、明细模型
明细模型是默认的建表模型。如果在建表时未指定任何模型,默认创建的是明细类型的表。它就像我们数仓中的 ODS 层或者 DWD 层,也就是说这个表中存储的是一些明细数据(比如用户的所有下单记录)。
StarRocks建表默认采用明细模型,排序列使用稀疏索引,可以快速过滤数据。明细模型用于保存所有历史数据,并且用户可以考虑将过滤条件中频繁使用的维度列作为排序键,比如用户经常需要查看某一时间,可以将事件时间和事件类型作为排序键。
- mysql> create database test_db;
- mysql> use test_db;
- CREATE TABLE IF NOT EXISTS detail (
- event_time DATETIME NOT NULL COMMENT "datetime of event",
- event_type INT NOT NULL COMMENT "type of event",
- user_id INT COMMENT "id of user",
- device_code INT COMMENT "device of ",
- channel INT COMMENT "")DUPLICATE KEY(event_time, event_type)DISTRIBUTED BY HASH(user_id) BUCKETS 8
这是一个创建名为"detail"的数据库表的SQL语句。该表包含以下列:
- event_time:事件时间,数据类型为DATETIME,不能为空。
- event_type:事件类型,数据类型为INT,不能为空。
- user_id:用户ID,数据类型为INT。
- device_code:设备代码,数据类型为INT。
- channel:通道,数据类型为INT。
此外,该表还具有以下约束:
- 使用 DUPLICATE KEY 子句,确保在event_time和event_type上的唯一性。
- 使用 DISTRIBUTED BY HASH(user_id) BUCKETS 8进行分桶存储,将数据分布在8个桶中,根据user_id的哈希值进行分布。
注意:这里我们指定了 event_time 和 event_type 为排序键,这里的排序键需要按照建表时的排序顺序来,排序键必须从建表语句的第一列开始!
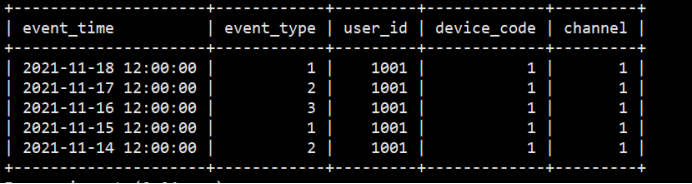
- INSERT INTO detail VALUES('2021-11-18 12:00:00.00',1,1001,1,1);
- INSERT INTO detail VALUES('2021-11-17 12:00:00.00',2,1001,1,1);
- INSERT INTO detail VALUES('2021-11-16 12:00:00.00',3,1001,1,1);
- INSERT INTO detail VALUES('2021-11-15 12:00:00.00',1,1001,1,1);
- INSERT INTO detail VALUES('2021-11-14 12:00:00.00',2,1001,1,1);
查询明细数据,这种模型用来存储所有历史明细数据(和 MySQL、Hive的使用没什么两样):
2.4.2、聚合模型
有些场景我们不希望看到明细,而是希望看到一些聚合的结果(比如用户的下单总金额),那么就可以使用聚合模型来建表。
建表时,支持定义排序键和指标列,并为指标列指定聚合函数。当多条数据具有相同的排序键时,指标列会进行聚合。在分析统计和汇总数据时,聚合模型能够减少查询时所需要处理的数据,提升查询效率。
在数据分析中,很多场景需要基于明细数据进行统计和汇总,这个时候就可以使用聚合模型了。比如:统计app访问流量、用户访问时长、用户访问次数、展示总量、消费统计等等场景。
适合聚合模型来分析的业务场景有以下特点:
- 业务方进行查询为汇总类查询,比如sum、count、max
- 不需要查看原始明细数据
- 老数据不会被频繁修改,只会追加和新增
- CREATE TABLE IF NOT EXISTS aggregate_tbl (
- site_id LARGEINT NOT NULL COMMENT "id of site",
- DATE DATE NOT NULL COMMENT "time of event",
- city_code VARCHAR(20) COMMENT "city_code of user",
- pv BIGINT SUM DEFAULT "0" COMMENT "total page views",
- mt BIGINT MAX
- )
- DISTRIBUTED BY HASH(site_id) BUCKETS 8;
上面的表我们根据 site_id 进行了分组,分别进行聚合计算。
- INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,5);
- INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,10);
- INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,15);
- INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,100);
- INSERT INTO aggregate_tbl VALUES(1001,'2021-11-18 12:00:00.00',100,1,20);
- INSERT INTO aggregate_tbl VALUES(1002,'2021-11-18 12:00:00.00',100,1,5);
- INSERT INTO aggregate_tbl VALUES(1002,'2021-11-18 12:00:00.00',100,3,25);
- INSERT INTO aggregate_tbl VALUES(1002,'2021-11-18 12:00:00.00',100,1,15);
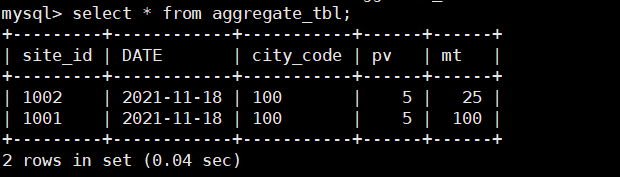
2.4.3、更新模型
建表时,支持定义主键和指标列,查询时返回主键相同的一组数据中的最新数据。相对于明细模型,更新模型简化了数据导入流程,能够更好地支撑实时和频繁更新的场景。
有些分析场景之下,数据需要进行更新比如拉链表,StarRocks则采用更新模型来满足这种需求,比如电商场景中,订单的状态经常会发生变化,每天的订单更新量可突破上亿。这种业务场景下,如果只靠明细模型下通过delete+insert的方式,是无法满足频繁更新需求的,因此,用户需要使用更新模型来满足分析需求。但是如果用户需要更加实时/频繁的更新操作,建议使用主键模型。
使用更新模型的场景特点:
- 已经写入的数据有大量的更新需求(历史数据)
- 需要进行实时数据分析
- CREATE TABLE IF NOT EXISTS update_detail (
- create_time DATE NOT NULL COMMENT "create time of an order",
- order_id BIGINT NOT NULL COMMENT "id of an order",
- order_state INT COMMENT "state of an order",
- total_price BIGINT COMMENT "price of an order"
- )
- UNIQUE KEY(create_time, order_id)
- DISTRIBUTED BY HASH(order_id) BUCKETS 8
插入测试数据,注意:现在是指定create_time和order_id为唯一键,那么相同日期相同订单的数据会进行覆盖操作
INSERT INTO update_detail VALUES('2011-11-18',1001,1,1000);
继续插入一条 create_id 和 order_id 相同的数据:
INSERT INTO update_detail VALUES('2011-11-18',1001,2,2000);查询:
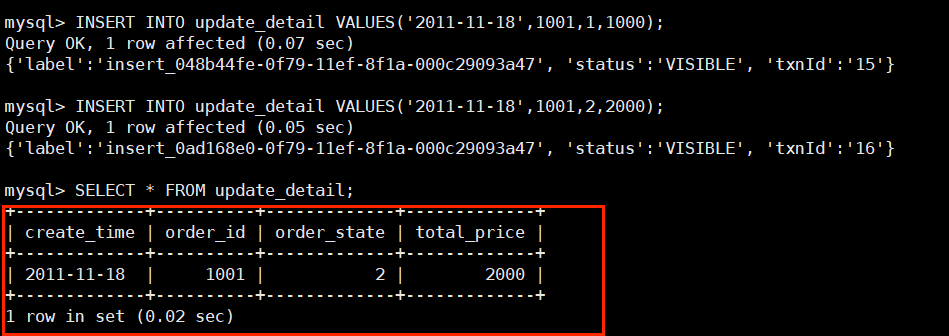
可以看到,如果日期和订单相同则会进行覆盖操作。
2.4.4、主键模型
StarRocks 1.19 版本推出了主键模型 (Primary Key Model) 。建表时,支持定义主键和指标列,查询时返回主键相同的一组数据中的最新数据。相对于更新模型,主键模型在查询时不需要执行聚合操作,并且支持谓词和索引下推,能够在支持实时和频繁更新等场景的同时,提供高效查询。
为什么有了更新模型还要有主键模型呢?其实主键模型相当于更新模型的一个升级版本。相比较更新模型,主键模型可以更好地支持实时/频繁更新的功能。虽然更新模型也可以实现实时对数据的更新,但是更新模型采用Merge on Read读时合并策略会大大限制查询功能,在主键模型更好地解决了行级的更新操作。配合Flink-connector-starrocks可以完成Mysql CDC实时同步的方案。
需要注意的是:由于存储引擎会为主键建立索引,导入数据时会把索引加载到内存中,所以主键模型对内存的要求更高,所以不适合主键模型的场景还是比较多的。
目前比较适合使用主键模型的场景有这两种:
- 数据冷热特征,比如最近几天的数据才需要修改,老的冷数据很少需要修改,比如订单数据,老的订单完成后就不在更新,并且分区是按天进行分区的,那么在导入数据时历史分区的数据的主键就不会被加载,也就不会占用内存了,内存中仅会加载近几天的索引。
- 大宽表(数百列数千列),主键只占整个数据的很小一部分,内存开销比较低。比如用户状态/画像表,虽然列非常多,但总的用户数量不大(千万-亿级别),主键索引内存占用相对可控。
原理:由于更新模型采用Merge策略,使得谓词无法下推和索引无法使用,严重影响查询性能。所以主键模型通过主键约束,保证同一个主键仅存一条数据的记录,这样就规避了Merge操作。
StarRocks收到对某记录的更新操作时,会通过主键索引找到该条数据的位置,并对其标记为删除,再插入一条数据,相当于把update改写为delete+insert
- CREATE TABLE users (
- user_id BIGINT NOT NULL,
- NAME STRING NOT NULL,
- email STRING NULL,
- address STRING NULL,
- age TINYINT NULL,
- sex TINYINT NULL
- ) PRIMARY KEY (user_id)
- DISTRIBUTED BY HASH(user_id) BUCKETS 4
测试数据:
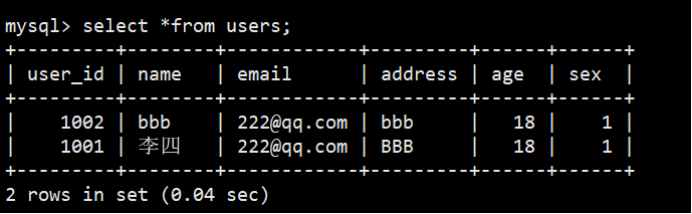
- INSERT INTO users VALUES(1001,'张三','111@qq.com','AAA',17,'0');
- INSERT INTO users VALUES(1001,'李四','222@qq.com','BBB',18,'1');
- INSERT INTO users VALUES(1002,'aaa','222@qq.com','aaa',18,'0');
- INSERT INTO users VALUES(1002,'bbb','222@qq.com','bbb',18,'1');
查询结果:
2.4.5、排序键
我们在上面的四个模型中其实已经用过了。
StarRocks中为加速查询,在内部组织并存储数据时,会把表中数据按照指定的列进行排序,这部分用于排序的列(可以是一个或多个列),可以称之为Sort Key。明细模型中Sort Key就是指定的用于排序的列(即 DUPLICATE KEY 指定的列),聚合模型中Sort Key列就是用于聚合的列(即 AGGREGATE KEY 指定的列),更新模型中Sort Key就是指定的满足唯一性约束的列(即 UNIQUE KEY 指定的列)。下图中的建表语句中Sort Key都为 (site_id、city_code)。
CREATE TABLE site_access_duplicate(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0')
DUPLICATE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
CREATE TABLE site_access_aggregate(
site_id INT DEFAULT '10',
city_code SMALLINT,
pv BIGINT SUM DEFAULT '0')
AGGREGATE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
CREATE TABLE site_access_unique(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0')
UNIQUE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
三种表对应的sort key都为site_id,city_code。创建排序列需要注意以下两点:
(1)排序列的定义必须出现在建表语句中其他列的定义之前。以图5.1中的建表语句为例,三个表的排序列可以是site_id、city_code,或者site_id、city_code、user_name,但不能是city_code、user_name,或者site_id、city_code、pv。
(2)排序列的顺序是由create table语句中的列顺序决定的。DUPLICATE/UNIQUE/AGGREGATE KEY中顺序需要和create table语句保持一致。以site_access_duplicate表为例,也就是说下面的建表语句会报错。
-- 错误的建表语句
CREATE TABLE site_access_duplicate(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0')
DUPLICATE KEY(city_code, site_id)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
-- 正确的建表语句
CREATE TABLE site_access_duplicate(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT DEFAULT '0')
DUPLICATE KEY(site_id, city_code)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
使用时注意事项(并不是说建了排序键就会提升查询效率,取决于查询语句):
(1)用户查询时如果条件包含上述两列,则可以大幅地降低扫描数据行,如:
select sum(pv) from site_access_duplicate where site_id = 123 and city_code = 2;
(2)如果查询只包含site_id一列,也能定位到只包含site_id的数据行,如:
select sum(pv) from site_access_duplicate where site_id = 123;(只用到了排序键的第一位同样可以优化)
(3)如果查询只包含city_code一列,那么需要扫描所有的数据行,排序的效果相当于大打折扣,如:select sum(pv) from site_access_duplicate where city_code = 2; //使用时和mysql索引规则一样,缺少最佳左前缀原则,索引会失效
使用排序键本质就是在进行二分查找,所以排序列指定的越多,那么消耗的内存也会越大,StarRocks为了避免这种情况发生也对排序键做了限制:
- shortkey 的列只能是排序键的前缀;
- shortkey 列数不超过3;
- 字节数不超过36字节;
- 不包含FLOAT/DOUBLE类型的列;
- VARCHAR类型列只能出现一次, 并且是末尾位置;
- 当shortkey index的末尾列为CHAR或者VARCHAR类型时, shortkey的长度会超过36字节;
- 当用户在建表语句中指定PROPERTIES {short_key = "integer"}时, 可突破上述限制;
2.4.6、物化视图
Materialized Views 表:简称 MVs,物化视图
使用场景:
在实际的业务场景中,通常存在两种场景并存的分析需求:对固定维度的聚合分析 和 对原始明细数据任意维度的分析。
例如,在销售场景中,每条订单数据包含这几个维度信息(item_id, sold_time, customer_id, price)。在这种场景下,有两种分析需求并存:
- 业务方需要获取某个商品在某天的销售额是多少,那么仅需要在维度(item_id, sold_time)维度上对 price 进行聚合即可。
- 分析某个人在某天对某个商品的购买明细数据。
在现有的 StarRocks 数据模型中,如果仅建立一个聚合模型的表,比如(item_id, sold_time, customer_id, sum(price))。由于聚合损失了数据的部分信息,无法满足用户对明细数据的分析需求。如果仅建立一个 Duplicate 模型,虽可以满足任意维度的分析需求,但由于不支持 Rollup,分析性能不佳,无法快速完成分析。如果同时建立一个聚合模型和一个 Duplicate 模型,虽可以满足性能和任意维度分析,但两表之间本身无关联,需要业务方自行选择分析表。不灵活也不易用。
如何使用:
使用聚合函数(如sum和count)的查询,在已经包含聚合数据的表中可以更高效地执行。这种改进的效率对于查询大量数据尤其适用。表中的数据被物化在存储节点中,并且在增量更新中能和 Base 表保持一致。用户创建 MVs 表后,查询优化器支持选择一个最高效的 MVs 映射,并直接对 MVs 表进行查询而不是 Base 表。由于 MVs 表数据通常比 Base 表数据小很多,因此命中 MVs 表的查询速度会快很多。
创建物化视图:
- CREATE MATERIALIZED VIEW test_detail_view
- AS SELECT user_id,MAX(event_type),COUNT(device_code),SUM(channel) FROM detail GROUP BY user_id;
创建完视图后,我们并不能感知创建成功,可以通过explain来分析是否命中视图。可以看到上面物化视图对event_type字段使用max函数,那么rollup命中的数据源为创建的物化视图。
explain select max(event_type) from detail;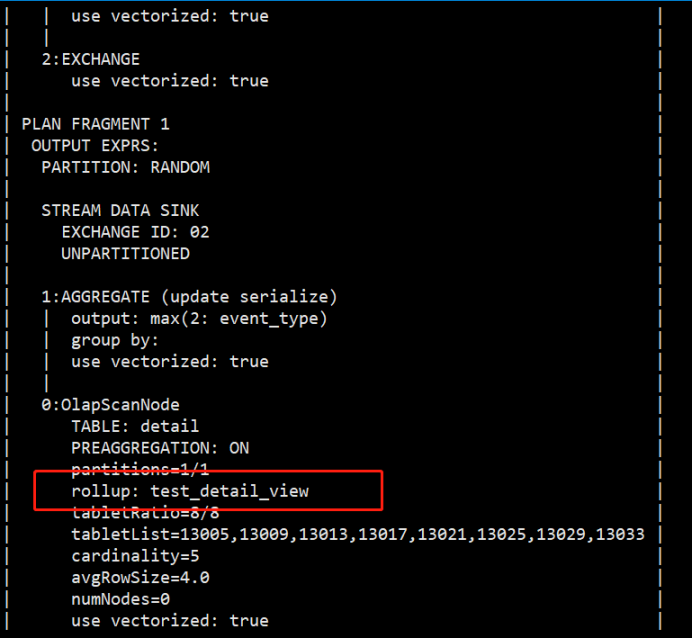
如果使用对event_type字段使用count函数,可以看到rollup命中的是detail表,而不是物化视图。
explain select count(event_type) from detail;
建立物化视图可以帮助用户对于不同场景都起到加速查询的作用。目前物化视图支持的函数如下有:count、max、min、sum、percentile_approx、hill_union、bitmap_union。
所以,如果使用了物化视图,那么我们在查询的时候就需要注意 SQL 中的字段是否能对应上创建的物化视图中字段的函数。
2.4.7、Bitmap 索引
StarRocks支持基于BitMap索引,对于Filter(比如where过滤)的查询有明显的加速效果。
原理:
Bitmap是元素为bit的, 取值为0、1两种情形的, 可对某一位bit进行置位(set)和清零(clear)操作的数组。Bitmap的使用场景有(判断是非):
- 用一个long型表示32位学生的性别,0表示女生,1表示男生。
- 用Bitmap表示一组数据中是否存在null值,0表示元素不为null,1表示为null。
- 一组数据的取值为(Q1, Q2, Q3, Q4),表示季度,用Bitmap表示这组数据中取值为Q4的元素,1表示取值为Q4的元素, 0表示其他取值的元素。
什么是 bitmap 索引?
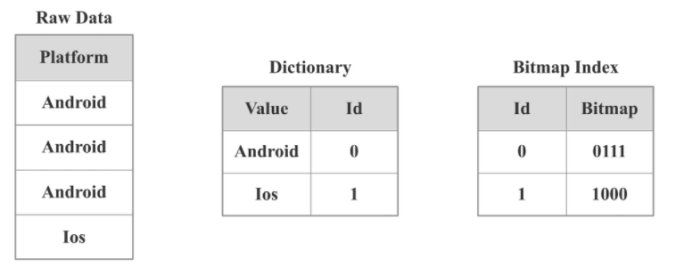
Bitmap只能表示取值为两种情形的列数组, 当列的取值为多种取值情形枚举类型时, 例如季度(Q1, Q2, Q3, Q4), 系统平台(Linux, Windows, FreeBSD, MacOS), 则无法用一个Bitmap编码; 此时可以为每个取值各自建立一个Bitmap的来表示这组数据; 同时为实际枚举取值建立词典.
如上图所示,Platform列有4行数据,可能的取值有Android、Ios。StarRocks中会首先针对Platform列构建一个字典,将Android和Ios映射为int,然后就可以对Android和Ios分别构建Bitmap。具体来说,我们分别将Android、Ios 编码为0和1,因为Android出现在第1,2,3行,所以Bitmap是0111(从右往左),因为Ios出现在第4行,所以Bitmap是1000(从右往左)。
假如有一个针对包含该Platform列的表的SQL查询,select xxx from table where Platform = iOS,StarRocks会首先查找字典,找出iOS对于的编码值是1,然后再去查找 Bitmap Index,知道1对应的Bitmap是1000,我们就知道只有第4行数据符合查询条件,StarRocks就会只读取第4行数据,不会读取所有数据。
适用场景:
使用Bitmap可以大大减少判断过滤时间(存储体积小:只存储一个向量比如0001),提高查询效率
- 当需要对表数据进行非前置列(排序键)进行过滤时,可以创建bitmap索引加速效率。
- 对表数据进行多列过滤,也可以考虑对多列分别创建bitmap索引加速效率
测试:
- CREATE TABLE IF NOT EXISTS user_dup (
- user_id INT,
- sex INT ,
- age INT
- )DUPLICATE KEY(user_id)DISTRIBUTED BY HASH(user_id) BUCKETS 8
插入数据:
- INSERT INTO user_dup VALUES(1001,0,18);
- INSERT INTO user_dup VALUES(1002,1,18);
- INSERT INTO user_dup VALUES(1003,0,18);
- INSERT INTO user_dup VALUES(1004,1,18);
- INSERT INTO user_dup VALUES(1005,0,18);
- INSERT INTO user_dup VALUES(1006,1,18);
- INSERT INTO user_dup VALUES(1007,0,18);
- INSERT INTO user_dup VALUES(1008,1,18);
创建位图索引:
CREATE INDEX user_sex_index ON user_dup(sex) USING bitmap;查看索引:
SHOW INDEX FROM user_dup;
注意事项:
(1)对于明细模型,所有列都可以建Bitmap 索引;对于聚合模型,只有Key列可以建Bitmap 索引。
(2)Bitmap索引, 应该在取值为枚举型, 取值大量重复, 较低基数, 并且用作等值条件查询或者可转化为等值条件查询的列上创建.
(3)不支持对Float、Double、Decimal 类型的列建Bitmap 索引。
(4)如果要查看某个查询是否命中了Bitmap索引,可以通过查询的Profile信息查看。
2.4.8、Bloom Filter 索引
什么是Bloom Filter:
Bloom Filter(布隆过滤器)是用于判断某个元素是否在一个集合中的数据结构,优点是空间效率和时间效率都比较高,缺点是有一定的误判率(因为不同值的hash值可能是相同的,默认循环三次hash算法,如果要求准确率高,需要进行更多层的for循环)。
布隆过滤器是由一个Bit数组和n个哈希函数构成。Bit数组初始全部为0,当插入一个元素时,n个Hash函数对元素进行计算, 得到n个slot,然后将Bit数组中n个slot的Bit置1。
当我们要判断一个元素是否在集合中时,还是通过相同的n个Hash函数计算Hash值,如果所有Hash值在布隆过滤器里对应的Bit不全为1,则该元素不存在。当对应Bit全1时, 则元素的存在与否, 无法确定. 这是因为布隆过滤器的位数有限, 由该元素计算出的slot, 恰好全部和其他元素的slot冲突. 所以全1情形, 需要回源查找才能判断元素的存在性。
什么是Bloom Filter 索引:
StarRocks的建表时, 可通过PROPERTIES{"bloom_filter_columns"="c1,c2,c3"}指定需要建BloomFilter索引的列,查询时, BloomFilter可快速判断某个列中是否存在某个值。如果Bloom Filter判定该列中不存在指定的值,就不需要读取数据文件;如果是全1情形,此时需要读取数据块确认目标值是否存在。另外,Bloom Filter索引无法确定具体是哪一行数据具有该指定的值。
- 建表时指定需要加Bloom Filter索引的列,创建一张测试表
- CREATE TABLE test_bf(
- id INT,
- event_type INT,
- email INT,
- sex INT,
- age INT
- )DUPLICATE KEY(id) DISTRIBUTED BY HASH(id) BUCKETS 8
- PROPERTIES("bloom_filter_columns"="event_type,sex");
- 查看Bloom Filter索引。使用show index查看不到Bloom Filter索引,得用show create table 命令
SHOW CREATE TABLE test_bf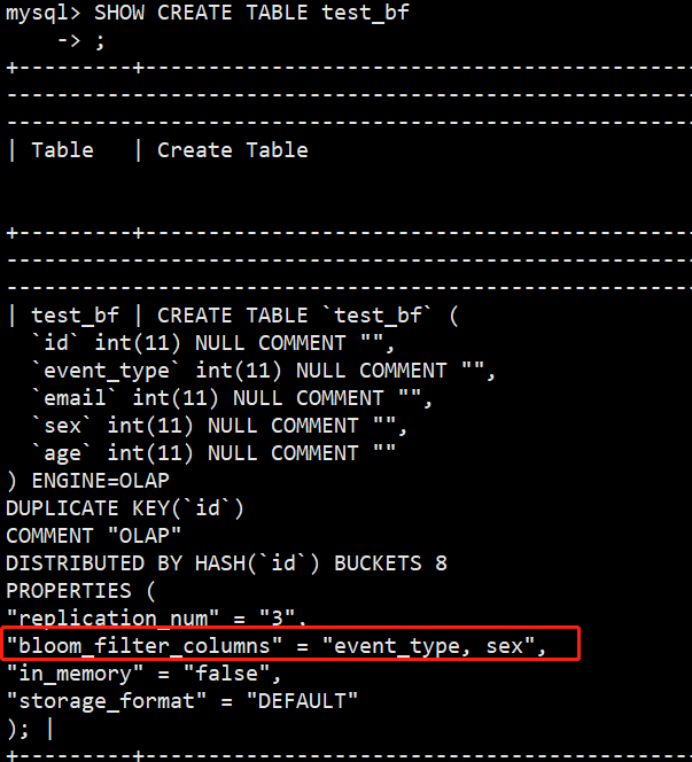
- 删除索引
alter table test_bf set("bloom_filter_columns"="");注意事项:
(1)不支持对Tinyint、Float、Double 类型的列建Bloom Filter索引。
(2)Bloom Filter索引只对in和=过滤查询有加速效果。
(3)如果要查看某个查询是否命中了Bloom Filter索引,可以通过查询的Profile信息查看(TODO:加上查看Profile的链接)。
3、数据导入与查询
3.1、Stream Load(同步导入)
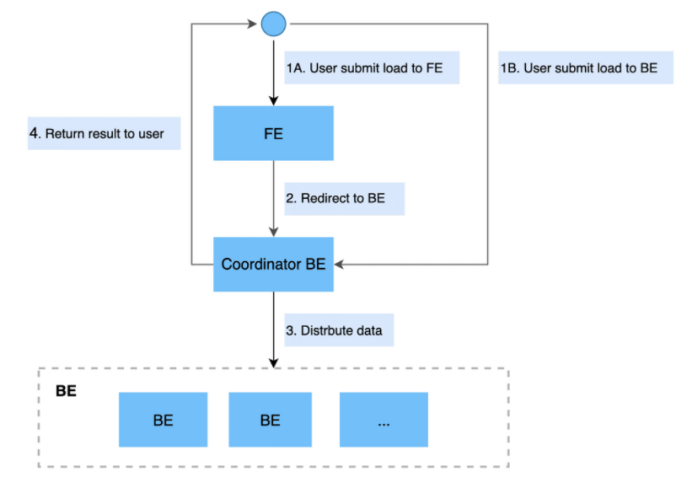
StarRocks支持从本地直接导入数据,支持CSV格式。数据量在10G以下,可以使用Stream Load导入,这种导入方式是通过用户发送HTTP请求将本地文件或数据流导入到StarRocks中。Stream Load 同步执行导入并返回结果。用户可以直接通过返回结果判断是否导入成功。
基本原理:Steam Load中,用户通过HTTP协议提交导入命令,提交到FE节点,FE节点则会通过HTTP 重定向指令请求转发给某一个BE节点,用户也可以直接提交导入命令指定BE节点。
测试:
- [root@hadoop102 ~]# vim test.csv
- 1001,'test1',123456@.qqcom,'测试地址1',18,1
- 1002,'test2',123456@.qqcom,'测试地址2',18,1
- 1003,'test3',123456@.qqcom,'测试地址3',20,0
- 1004,'test4',123456@.qqcom,'测试地址4',21,1
- 1005,'test5',123456@.qqcom,'测试地址5',23,0
- 1006,'test6',123456@.qqcom,'测试地址6',22,1
- 1007,'test7',123456@.qqcom,'测试地址7',18,0
- 1008,'test8',123456@.qqcom,'测试地址8',25,1
- 1009,'test9',123456@.qqcom,'测试地址9',19,0
- 1010,'test10',123456@.qqcom,'测试地址10',10,1
- 1011,'test11',123456@.qqcom,'测试地址11',18,1
根据官网语法将CSV数据导入对应user表中,官网语法:
curl --location-trusted -u user:passwd [-H ""...] -T data.file -XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load注意:命令-H 为头部信息 column_separator为测试文件中字段间隔符,虽然官网写着支持csv但默认是\t,默认支持tsv所以这把这个参数改成逗号
[root@hadoop102 ~]# curl --location-trusted -u root -T test.csv -H "column_separator:," http://hadoop102:8030/api/test/users/_stream_load因为Stream load是同步导入,所以可以立马看到是否导入成功:
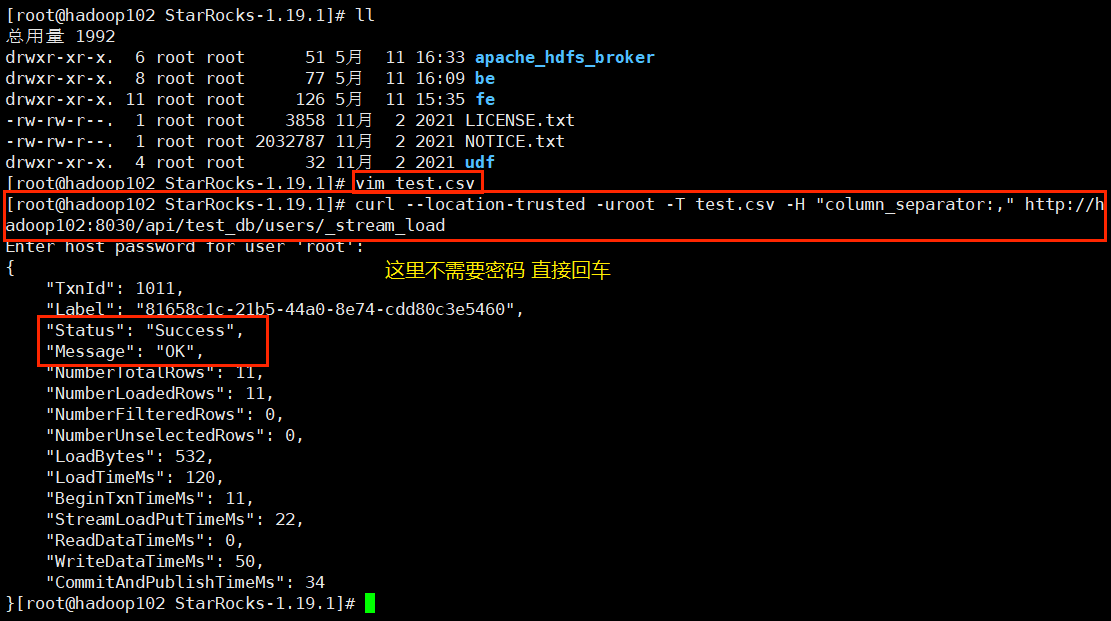
这里的 '_stream_load' 只是一个标识符
导入成功后,查看对应的users表
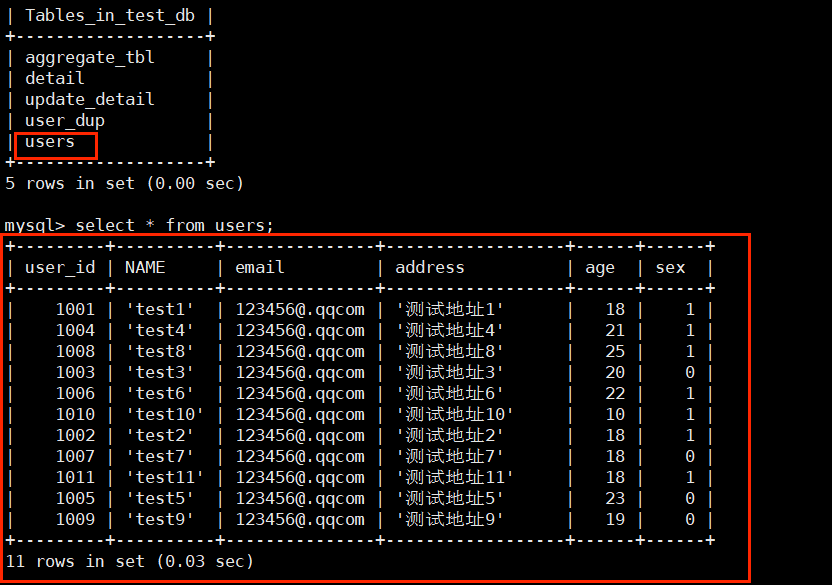
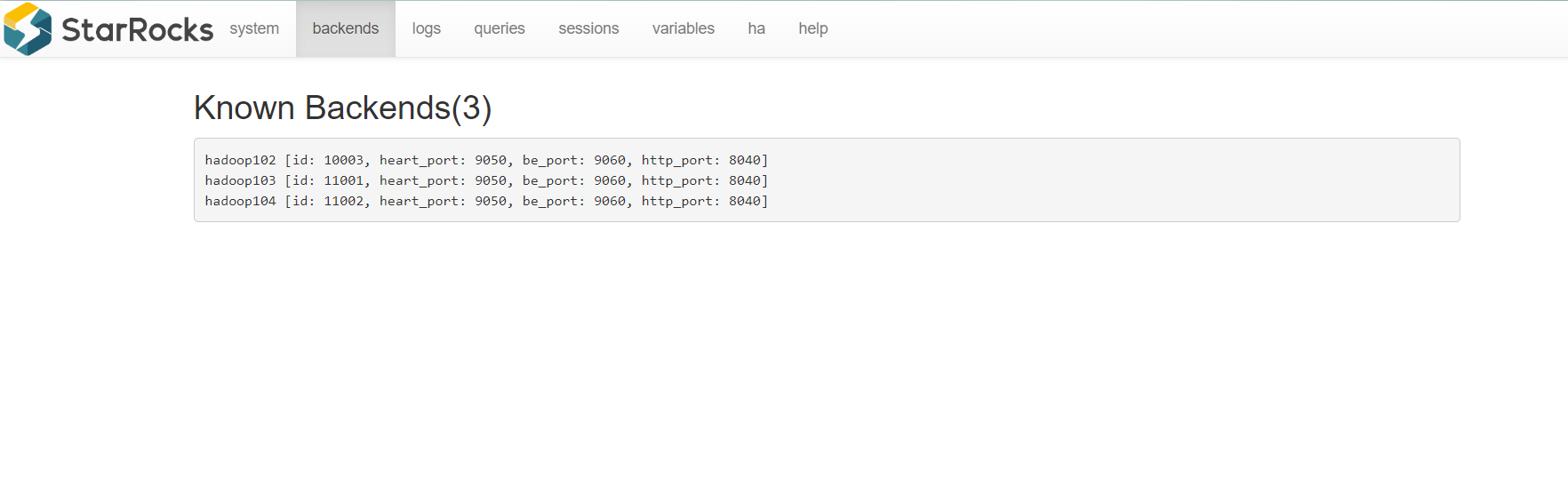
同时,我们也可以通过访问 hadoop102:8030 来访问 starrocks 的 Web UI:
3.2、Broker Load(异步导入)
StarRocks支持从Apache HDFS、Amazon S3等外部存储系导入数据,支持CSV、ORCFile、Parquet等文件格式。数据量在几十GB到上百GB 级别。
在Broker Load模式下,通过部署的Broker程序,StarRocks可读取对应数据源(如HDFS, S3)上的数据,利用自身的计算资源对数据进行预处理和导入。这是一种异步的导入方式,用户需要通过MySQL协议创建导入,并通过查看导入命令检查导入结果。

使用 broker load 的时候必须保证 broker 进程启动!
这里演示Apache HDFS导入StarRocks,将Hadoop集群的hdfs-site.xml文件复制到对应broker conf 目录下:
Broker Load 支持如下数据文件格式:
- CSV
- Parquet
- ORC
创建两个 csv 文件并上传到 HDFS :
file1.csv:
- 1,Lily,23
- 2,Rose,23
- 3,Alice,24
- 4,Julia,25
file2.csv:
200,'北京'
StarRocks 创建两张表,分别对应两个文件:
- CREATE TABLE `table1`
- (
- `id` int(11) NOT NULL COMMENT "用户 ID",
- `name` varchar(65533) NULL DEFAULT "" COMMENT "用户姓名",
- `score` int(11) NOT NULL DEFAULT "0" COMMENT "用户得分"
- )
- ENGINE=OLAP
- PRIMARY KEY(`id`)
- DISTRIBUTED BY HASH(`id`) BUCKETS 10;
-
- CREATE TABLE `table2`
- (
- `id` int(11) NOT NULL COMMENT "城市 ID",
- `city` varchar(65533) NULL DEFAULT "" COMMENT "城市名称"
- )
- ENGINE=OLAP
- PRIMARY KEY(`id`)
- DISTRIBUTED BY HASH(`id`) BUCKETS 10;

从 HDFS 导入:
- LOAD LABEL test_db.label1
- (
- DATA INFILE("hdfs://hadoop102:8020/starrocks/file1.csv")
- INTO TABLE table1
- COLUMNS TERMINATED BY ","
- (id, name, score)
- ,
- DATA INFILE("hdfs://hadoop102:8020/starrocks/file2.csv")
- INTO TABLE table2
- COLUMNS TERMINATED BY ","
- (id, city)
- )
- WITH BROKER "broker1"
- (
- "hadoop.security.authentication" = "simple",
- "username" = "lyh",
- "password" = "123456"
- )
- PROPERTIES
- (
- "timeout" = "3600"
- );
注意:下面标记的地方是需要自定义的地方,参考官网文档:

查看 load 计划:
show load where label=load名称
查询导入结果:

3.3、Rountine Load
如果您需要将消息流不间断地导入至 StarRocks,则可以将消息流存储在 Kafka 的 Topic 中,并向 StarRocks 提交一个 Routine Load 导入作业。 StarRocks 会常驻地运行这个导入作业,持续生成一系列导入任务,消费 Kafka 集群中该 Topic 中的全部或部分分区的消息并导入到 StarRocks 中。
Routine Load 支持 Exactly-Once 语义,能够保证数据不丢不重。
Routine Load 目前支持从 Kakfa 集群中消费 CSV、JSON 格式的数据。

环境要求:
(1)支持访问无认证或使用 SSL 方式认证的 Kafka 集群。
(2)支持的消息格式为 CSV 文本格式,每一个 message 为一行,且行尾不包含换行符。
(3)仅支持 Kafka 0.10.0.0(含) 以上版本。
3.3.1、测试把Kafka的数据导入到StarRocks
StarRocks 创建表格:
- CREATE TABLE test_kafka_routine(
- `order_id` bigint NOT NULL COMMENT "订单编号",
- `pay_dt` date NOT NULL COMMENT "支付日期",
- `customer_name` varchar(26) NULL COMMENT "顾客姓名",
- `nationality` varchar(26) NULL COMMENT "国籍",
- `price`double NULL COMMENT "支付金额"
- )
- ENGINE=OLAP
- DUPLICATE KEY (order_id,pay_dt)
- DISTRIBUTED BY HASH(`order_id`) BUCKETS 5;
创建作业(配置Kafka输入源参数):
- CREATE ROUTINE LOAD test_db.test_kafka_routine_like ON test_kafka_routine
- COLUMNS TERMINATED BY ",",
- COLUMNS (order_id, pay_dt, customer_name, nationality, temp_gender, price)
- PROPERTIES
- (
- "desired_concurrent_number" = "3" #并行度(BE的数量)
- )
- FROM KAFKA
- (
- "kafka_broker_list" ="hadoop102:9092,hadoop103:9092,hadoop104:9092",
- "kafka_topic" = "like",
- "kafka_partitions" ="0,1,2",
- "property.kafka_default_offsets" = "OFFSET_BEGINNING"
- );

查询所有任务:

启动 Kafka 生产者:
 查询:
查询:
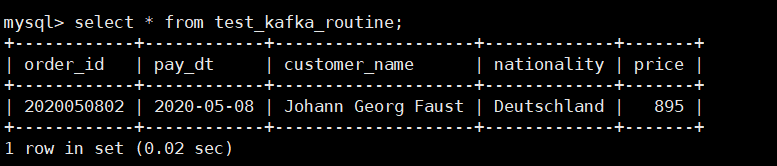 可以看到,我们写入到 Kafka like 分区的数据被成功写入到表格中。
可以看到,我们写入到 Kafka like 分区的数据被成功写入到表格中。

继续测试:

3.3.2、查看导入作业
除了上面的 show routine load\G 查看所有导入的作业之外,还可以通过下面的这些方法查看导入的作业:
通过名称查看导入作业

3.3.3、查看导入任务

3.3.4、暂停导入作业

3.3.5、恢复导入作业
RESUME ROUTINE LOAD FOR test_kafka_routine_like \G3.3.6、停止导入作业

3.3.7、修改导入作业
官方文档写得很详细
4、使用 StarRocks
4.1、Colocate join
Colocate Join 功能是分布式系统实现 Join 数据分布的策略之一,能够减少数据多节点分布时 Join 操作引起的数据移动和网络传输,从而提高查询性能。(也就是把要 join 的数据尽可能放到相同的 BE 节点)
在 StarRocks 中使用 Colocate Join 功能,您需要在建表时为其指定一个 Colocation Group(CG),同一 CG 内的表需遵循相同的 Colocation Group Schema(CGS),即表对应的分桶副本具有一致的分桶键、副本数量和副本放置方式。如此可以保证同一 CG 内,所有表的数据分布在相同一组 BE 节点上。当 Join 列为分桶键时,计算节点只需做本地 Join,从而减少数据在节点间的传输耗时,提高查询性能。因此,Colocate Join,相对于其他 Join,例如 Shuffle Join 和 Broadcast Join,可以有效避免数据网络传输开销,提高查询性能。
Colocate Join 支持等值 Join。
4.1.1、创建 Colocate 表
在建表时,需要在 PROPERTIES 中指定属性 "colocate_with" = "group_name" 以创建一个 Colocate Join 表,并且指定其归属于特定的 Colocation Group。
- CREATE TABLE `tbl1` (
- `k1` date NOT NULL COMMENT "",
- `k2` int(11) NOT NULL COMMENT "",
- `v1` int(11) SUM NOT NULL COMMENT ""
- ) ENGINE=OLAP
- AGGREGATE KEY(`k1`, `k2`) -- 排序键必须一致
- DISTRIBUTED BY HASH(`k2`) BUCKETS 8 -- 分桶键类型和分桶数必须一致
- PROPERTIES (
- "colocate_with" = "group1" -- 指定为同一组
- );
-
- CREATE TABLE `tbl2` (
- `k1` date NOT NULL COMMENT "",
- `k2` int(11) NOT NULL COMMENT "",
- `v1` int(11) SUM NOT NULL COMMENT ""
- ) ENGINE=OLAP
- AGGREGATE KEY(`k1`, `k2`) -- 排序键必须一致
- DISTRIBUTED BY HASH(`k2`) BUCKETS 8 -- 分桶键类型和分桶数必须一致
- PROPERTIES (
- "colocate_with" = "group1" -- 指定为同一组
- );
要想达到优化查询的目的,必须满足下面这些条件:
- 同一 CG 内的表的分桶键的类型、数量和顺序完全一致,并且桶数一致,从而保证多张表的数据分片能够一一对应地进行分布控制。
- 同 CG 的表的分桶键的名字可以不相同,分桶列的定义在建表语句中的出现次序可以不一致,但是在 DISTRIBUTED BY HASH(col1, col2, ...) 的对应数据类型的顺序要完全一致。
- 同一个 CG 内所有表的所有分区的副本数必须一致(默认都是 3)。
- 同一个 CG 内所有表的分区键,分区数量可以不同。
查询是否得到优化:
explain SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);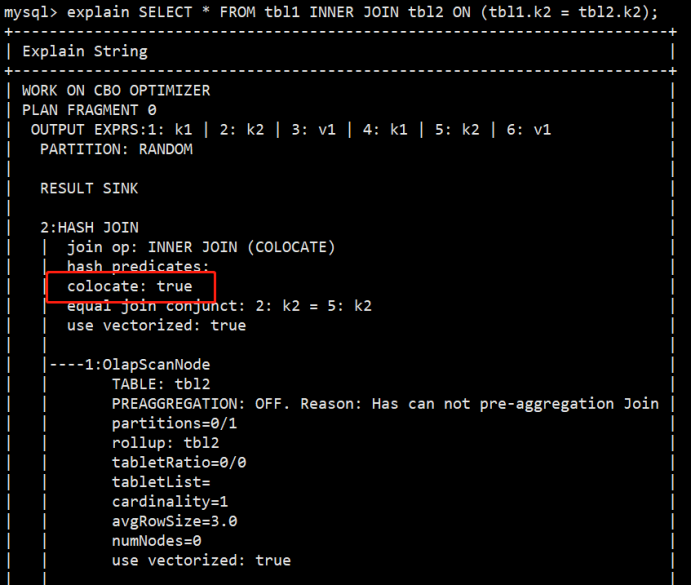
4.2、外部表
StarRocks 不支持修改(update)功能的,所以如果 StarRocks 要修改数据的话,要么把数据模型设置为主键模型或者更新模型,同时 StarRocks 也提供了一种方案——外部表,也就是可以让 StarRocks 对接外部表,当外部表发生变化的时候,StarRocks 自己也会发生变化。当前 StarRocks 已支持的第三方数据源包括 MySQL、Elasticsearch、Apache Hive™、StarRocks、Apache Iceberg 和 Apache Hudi。对于 StarRocks 数据源(StarRocks类型的外部表),现阶段只支持 Insert 写入,不支持读取;对于其他数据源(其它类型外部表),现阶段只支持读取,还不支持写入。
4.2.1、MySQL 外部表
首先在 MySQL 创建一张测试表:

插入测试数据:

在 StarRocks 中创建外部表:
- CREATE EXTERNAL TABLE mysql_external_table
- (
- id int,
- name varchar(20),
- age int
- )
- ENGINE=mysql
- PROPERTIES
- (
- "host" = "hadoop102",
- "port" = "3306",
- "user" = "root",
- "password" = "123456",
- "database" = "starrocks",
- "table" = "test_t1"
- );

查询外部表:
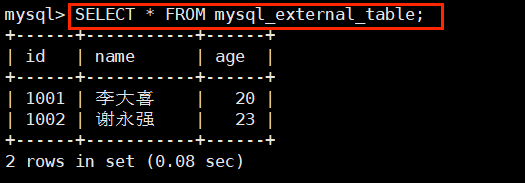
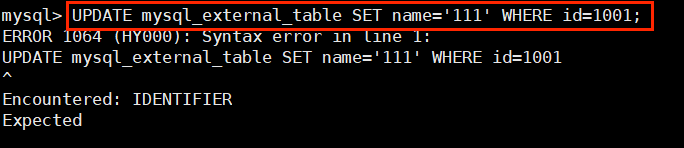
需要注意的是,StarRocks 是不支持修改数据的(不管是外部表还是内部表):
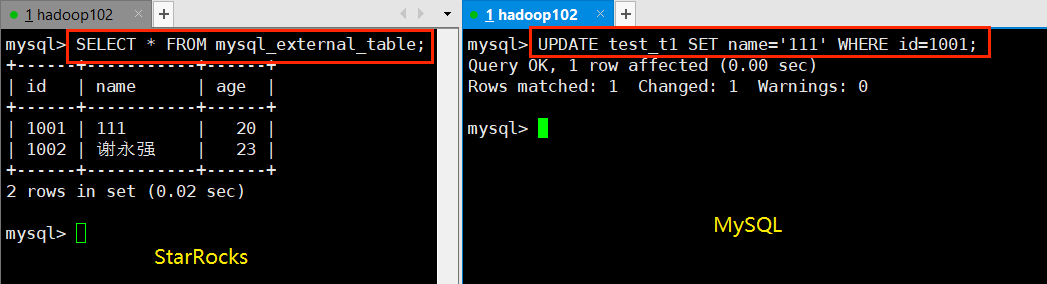
但是可以通过修改外部数据源来更新 StarRocks 的外部表:
4.2.2、Hive 外部表
启动 Hadoop、Hive(这里很可能遇到 Yarn 启动失败,因为 StarRocks 会占用 Yarn 的 8030、8040 端口)
通过 tail -500 xxx-resourcemanager.log 查看日志
查看端口是否被占用:
netstat -tnlp | grep :8040监听日志文件:
tail -f 日志文件.log修改被占用的端口:

创建 Hive 表:
- use test;
-
- create table test_t1(
- id int ,
- name string,
- age int);
向 Hive 表中插入数据(这里用的是 Spark 引擎):
 在 StarRocks 中创建 Hive 数据源:
在 StarRocks 中创建 Hive 数据源:
- CREATE EXTERNAL RESOURCE "hive0"
- PROPERTIES (
- "type" = "hive",
- "hive.metastore.uris" = "thrift://hadoop102:9083");
创建 Hive 外部表:
- create external table hive_t1(
- id int,
- name varchar(20),
- age int)
- ENGINE=HIVE
- PROPERTIES (
- "resource" = "hive0",
- "database" = "test",
- "table" = "test_t1"
- );
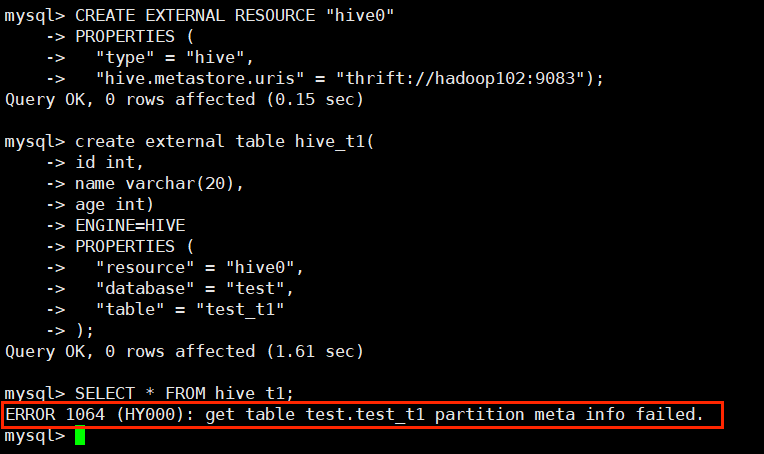
去 hadoop102:8030 的 WebUI 去查看日志:

去官网查询解决方案:
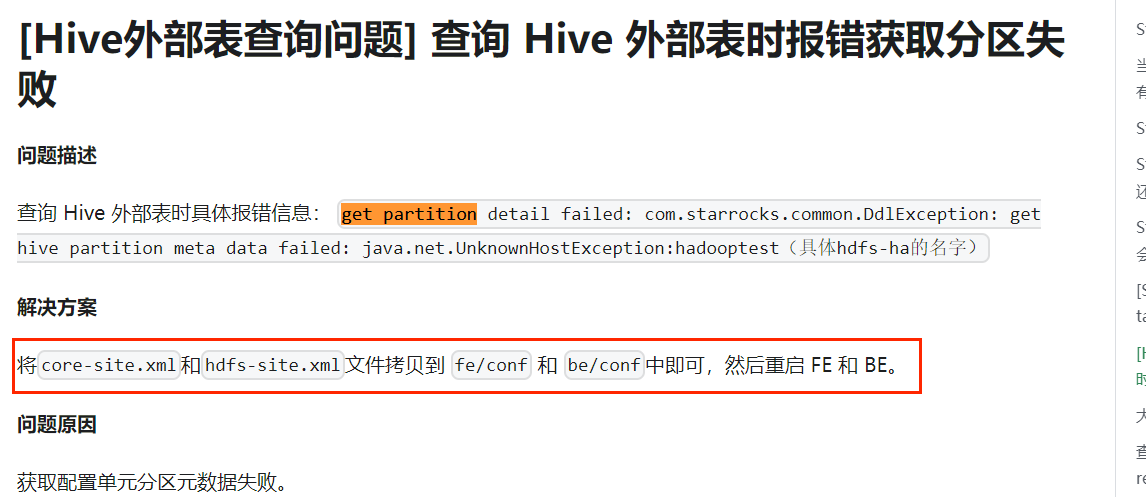

还是查询失败,尝试换 csv 数据源的 Hive 表作为外部表还是不行(可能是版本的问题?之后解决再来更新)。
4.3、数组
StarRocks 是支持数组类型字段的,建表的时候使用。
- CREATE TABLE student(
- id INT,
- hobbies ARRAY<INT>
- )
- DUPLICATE KEY(id)
- DISTRIBUTED BY HASH(id) BUCKETS 3;

查询数组字段指定索引的值:
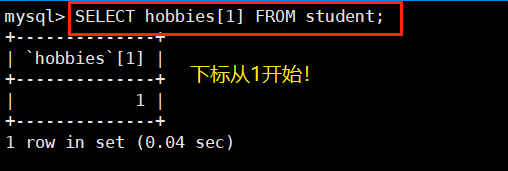
同时 StarRocks 也支持嵌套数组
- create table t1(
- c0 INT,
- c1 ARRAY<ARRAY<VARCHAR(10)>>
- )
- duplicate key(c0)
- distributed by hash(c0) buckets 3;
-
- INSERT INTO t1 VALUES(1, [[1,2,3],[1,2,3],[4,5,6]]);
-

数组的使用有以下限制
- 只能在duplicate table(明细模型)中定义数组列
- 数组列不能作为key列(以后可能支持)
- 数组列不能作为distribution列
- 数组列不能作为partition列

