
- 1Java架构的-高并发解决方案_50并发量在java行业中水平
- 2KafkaGroup:实现高效的数据流处理
- 3数据迁移工具——Sqoop_将数据湖数据导入大数据联机查询服务(kva)可以使用什么导数工具
- 4Android中 logd 详解_android logd
- 5如何在本地创建一个新的Git仓库?_git本地建一个仓库
- 6FPGA 架构笔记_intel的fpga器件内部最小逻辑单元为
- 7使用PL/SQL&自定义函数_pqsql 自定义函数
- 8SQL SERVER~创建函数_sql server创建函数
- 9Git 子模块和子树管理项目_git 子项目
- 10软件测试工程师三次面试失败的血泪教训!!!_软件测试面试4次就想放弃是不是很可惜
15.自动文摘和信息抽取_自动文摘提取
赞
踩
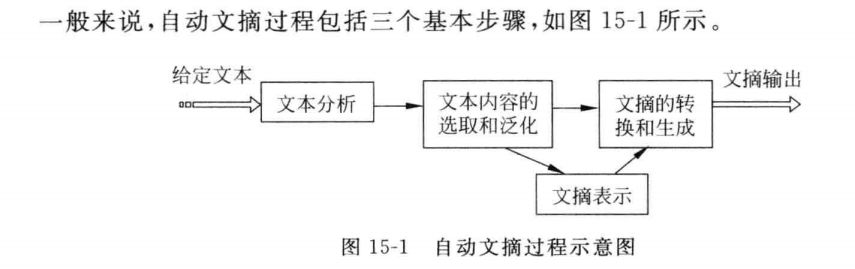
文本分析过程是对原文本进行分析处理,识别冗余信息;文本内容的选取和泛化过程是从文档中辨认重要信息,通过摘录或概括的方法压缩文本,或者通过计算分析的方法形成文摘表示;文摘的转换和生成过程实现对原文内容的重组或者根据内部表示生成文摘并确保文摘的连贯性。文摘的输出形式依据文摘的用途和用户需求确定。由于不同的系统所采用的具体实现方法不同,因此,在不同的系统中上述几个模块所处理的问题和采用的方法也有所差异。例如,在基于句子抽取的多文档文摘系统中,其基本思想是通过计算句子之间的相似性,抽取文摘句,然后对文摘句排序的方法生成最后的文摘,因此,其核心技术集中在句子相似性计算、文摘句抽取和文摘句排序三个问题上,并不需要经过文摘表示这一中间环节。
15.2 多文档摘要
在单文档摘要系统中,一般都采用基于抽取的方法。而对于多文档而言,由于在同一主题中的不同文档中不可避免地存在信息交叠和信息差异,因此,如何避免信息冗余,同时反映出来自不同文档的信息差异是多文档文摘中的首要目标,而要实现这个目标通常意味着要在句子层以下做工作,如对句子进行压缩、合并、切分等。所以,多文档摘要系统所面临的问题更加复杂。
常用的冗余识别方法通常有两种,一种是聚类的方法,测量所有句子对之间的相似性,然后用聚类方法识别公共信息的主题。另一种做法是采用候选法,即系统首先测量候选文段与已选文段之间的相似度,仅当候选段有足够的新信息时才将其人选。如最大边缘相关法 MMR。
辨认重要信息的常用方法有抽取法和信息融合法。抽取法的基本思路是选出每个聚类中有代表性的部分(一般为句子),默认这些代表性的部分(句子)可以表达这个聚类中的主要信息。信息融合(information fusion)法的目的是要生成一个简洁、通顺并能反映这些句子(主题)之间共同信息的句子。为达到这个目标,要识别出对所有人选的主题句都共有的短语,然后将之合并起来。
15.3 信息抽取
传统的命名实体识别任务主要是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体,或针对一些特定领域特定类型的命名实体(如产品名称、基因名称等)进行研究。开放式实体抽取的任务是在给出特定语义类的若干实体(称为“种子”)的情况下,找出该语义类包含的其他实体,其中特定语义类的标签可能是显式,也可能是隐式给出的。如给出“中国、美国、俄罗斯”这三个实体,要求找出“国家”这个语义类的其他实体诸如“德国、法国、日本”等。从方式上传统意义上的实体识别关注的是从文本中识别出实体字符串位置以及所属类别(如人名、地名、组织机构名等),侧重于识别,而开放式实体抽取关注的是从海量、冗余、不规范的网络数据源上抽取出符合某个语义类的实体列表,侧重于抽取。相对而言,抽取比识别在任务上更加底层,实体抽取的结果可以作为列表支撑实体的识别。在互联网应用领域,开放式实体抽取技术对于知识库构建、网络内容管理、语义搜索、问答系统等都具有重要的应用价值。

