
- 1GitHub Pages + Hexo + NexT + Typora + WhatsNote打造完美个人知识共享博客_notenext github
- 2[机器学习]-3 万字话清从传统神经网络到深度学习
- 3python3一篇学会人脸识别(详细教学篇(附源码))_用python代码进行人脸识别完整代码
- 4机器学习实验2 - 逻辑回归_机器学习逻辑回归实验
- 5基于开源项目改造,我制作了15个酷炫的数据大屏(附 Python 源码)_清爽数据可视化大屏
- 6推荐开源项目:F-Droid 客户端
- 7配置微信小程序自动更新_小程序自动更新版本
- 8Xilinx zynq EtherCAT LAN9252_lan9252 zynq
- 9[职场] 采购专员个人简历工作经历怎么写(附范文5篇) #职场发展#微信_采购员经历
- 10网络安全初学者必备的60个工具,零基础入门到精通,收藏这一篇就够了_网络发现工具
第十七篇【传奇开心果系列】Python的OpenCV库技术点案例示例:自适应阈值二值化处理图像提取文字_python 自適應閾值代碼
赞
踩
传奇开心果短博文系列
- 系列短博文目录
- Python的OpenCV库技术点案例示例系列
- 短博文目录
- 前言
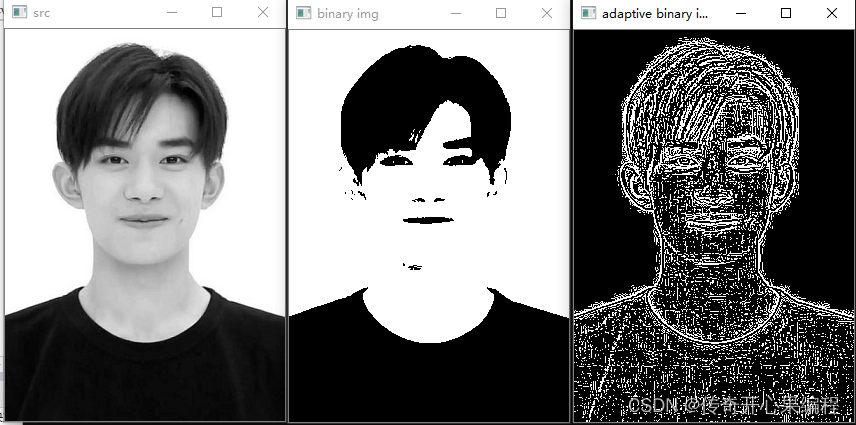
- 一、自适应阈值二值化处理图像提取文字轮廓的初步示例代码:
- 二、扩展思路介绍
- 三、调整自适应阈值二值化的参数示例代码
- 四、对二值化图像进行形态学操作示例代码
- 五、使用轮廓特征进行筛选示例代码
- 六、边缘检测算法示例代码
- 七、使用图像分割算法将图像分割为文字和背景区域示例代码
- 八、调整参数优化文字轮廓示例代码
- 九、应用形态学操作优化文字轮廓示例代码
- 十、筛选轮廓优化文字轮廓示例代码
- 十一、归纳总结
系列短博文目录
Python的OpenCV库技术点案例示例系列
短博文目录
前言
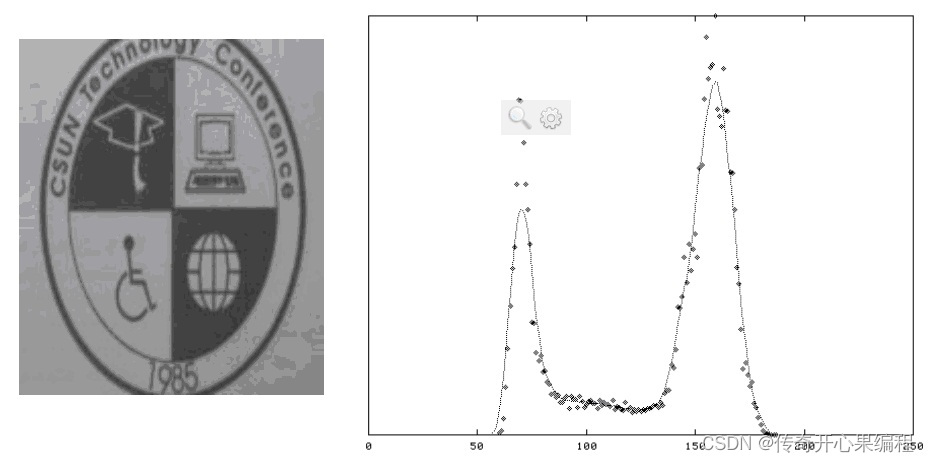
 自适应阈值二值化来处理图像,以更好地提取文字轮廓。自适应阈值二值化可以根据图像局部区域的灰度值自动确定阈值。
自适应阈值二值化来处理图像,以更好地提取文字轮廓。自适应阈值二值化可以根据图像局部区域的灰度值自动确定阈值。
一、自适应阈值二值化处理图像提取文字轮廓的初步示例代码:
 以下是使用Python和OpenCV库进行自适应阈值二值化的示例代码:
以下是使用Python和OpenCV库进行自适应阈值二值化的示例代码:
import cv2 # 读取图像 image = cv2.imread('your_image.jpg', 0) # 自适应阈值二值化 binary = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2) # 查找轮廓 contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 绘制轮廓 contour_image = cv2.drawContours(image.copy(), contours, -1, (0, 255, 0), 2) # 显示结果 cv2.imshow('Binary Image', binary) cv2.imshow('Contour Image', contour_image) cv2.waitKey(0) cv2.destroyAllWindows()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
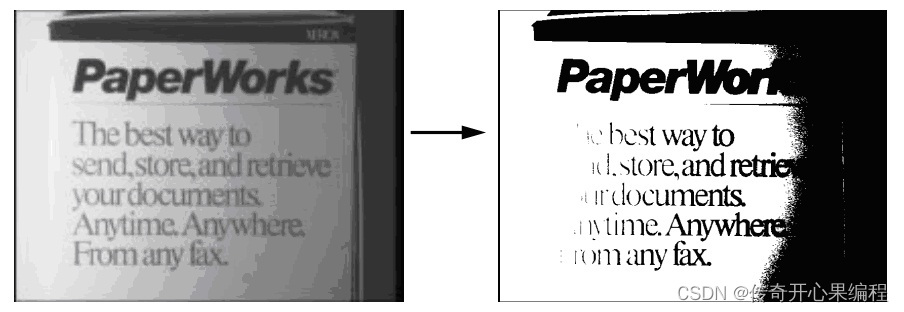
在上述代码中,首先使用cv2.adaptiveThreshold函数对图像进行自适应阈值二值化,其中cv2.ADAPTIVE_THRESH_MEAN_C表示使用局部均值作为阈值计算方式。然后使用cv2.findContours函数查找图像中的轮廓,并使用cv2.drawContours函数绘制轮廓。
您可以根据实际情况调整自适应阈值二值化的参数,如窗口大小和均值计算方法,以获得最佳的结果。
二、扩展思路介绍
 当使用自适应阈值二值化来处理图像时,还可以考虑以下几个方面的扩展:
当使用自适应阈值二值化来处理图像时,还可以考虑以下几个方面的扩展:
-
调整自适应阈值二值化的参数:除了示例代码中使用的
cv2.ADAPTIVE_THRESH_MEAN_C方法外,还可以尝试使用cv2.ADAPTIVE_THRESH_GAUSSIAN_C方法,它使用局部区域的加权和作为阈值计算方式。可以根据图像的特点和需求,比较两种方法的效果并选择最佳的方法。 -
对二值化图像进行形态学操作:在获取到二值化图像后,可以应用形态学操作来进一步处理图像,以改善文字轮廓的提取效果。例如,可以使用
cv2.dilate函数对二值化图像进行膨胀操作,以填充文字内部的空洞;或者使用cv2.erode函数对二值化图像进行腐蚀操作,以去除细小的噪点。 -
使用轮廓特征进行筛选:在查找轮廓后,可以通过一些条件来筛选出符合要求的轮廓。例如,可以根据轮廓的面积、周长、宽高比等特征进行筛选,以排除不需要的轮廓。
-
应用其他图像处理技术:如果仍然无法满足需求,可以尝试其他图像处理技术来提取文字轮廓。例如,可以使用边缘检测算法(如Canny边缘检测)来获取文字的边缘信息;或者使用图像分割算法(如基于区域的分割算法)将图像分割为文字和背景区域。
综上所述,根据具体的需求和图像特点,可以尝试调整参数、应用形态学操作、筛选轮廓以及使用其他图像处理技术来进一步优化文字轮廓的提取效果。
三、调整自适应阈值二值化的参数示例代码
 下面是一个示例代码,演示了如何调整自适应阈值二值化的参数来提取文字轮廓:
下面是一个示例代码,演示了如何调整自适应阈值二值化的参数来提取文字轮廓:
import cv2 # 读取图像 image = cv2.imread('your_image.jpg', 0) # 自适应阈值二值化(调整参数) binary = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 5) # 查找轮廓 contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 绘制轮廓 contour_image = cv2.drawContours(image.copy(), contours, -1, (0, 255, 0), 2) # 显示结果 cv2.imshow('Binary Image', binary) cv2.imshow('Contour Image', contour_image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在上述代码中,我调整了自适应阈值二值化的两个参数:窗口大小(11)和均值计算的偏移值(5)。您可以根据实际需求,尝试不同的参数值来获得最佳的效果。
增大窗口大小可以考虑更大范围的像素值,从而适应不同大小的文字。减小偏移值可以使阈值更接近局部像素均值,以更好地区分文字和背景。
请注意,调整参数时需要根据具体情况进行实验和调整。不同的图像和文字特征可能需要不同的参数设置。
四、对二值化图像进行形态学操作示例代码
 下面是一个示例代码,演示了如何对二值化图像进行形态学操作来改善文字轮廓的提取效果:
下面是一个示例代码,演示了如何对二值化图像进行形态学操作来改善文字轮廓的提取效果:
import cv2 import numpy as np # 读取图像 image = cv2.imread('your_image.jpg', 0) # 自适应阈值二值化 binary = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2) # 形态学操作(膨胀和腐蚀) kernel = np.ones((3, 3), np.uint8) dilated = cv2.dilate(binary, kernel, iterations=1) eroded = cv2.erode(dilated, kernel, iterations=1) # 查找轮廓 contours, _ = cv2.findContours(eroded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 绘制轮廓 contour_image = cv2.drawContours(image.copy(), contours, -1, (0, 255, 0), 2) # 显示结果 cv2.imshow('Binary Image', binary) cv2.imshow('Dilated Image', dilated) cv2.imshow('Eroded Image', eroded) cv2.imshow('Contour Image', contour_image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
在上述代码中,我使用了两种形态学操作:膨胀(dilate)和腐蚀(erode)。首先,使用cv2.dilate函数对二值化图像进行膨胀操作,以填充文字内部的空洞和连接断开的部分。然后,使用cv2.erode函数对膨胀后的图像进行腐蚀操作,以去除细小的噪点。
通过应用形态学操作,可以进一步改善文字轮廓的连通性和完整性,使得提取效果更好。
请注意,形态学操作的参数(如核大小、迭代次数)也可以根据实际情况进行调整,以获得最佳的效果。
五、使用轮廓特征进行筛选示例代码
 下面是一个示例代码,演示了如何使用轮廓特征进行筛选,以提取符合要求的文字轮廓:
下面是一个示例代码,演示了如何使用轮廓特征进行筛选,以提取符合要求的文字轮廓:
import cv2 # 读取图像 image = cv2.imread('your_image.jpg', 0) # 自适应阈值二值化 binary = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2) # 查找轮廓 contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 筛选轮廓 filtered_contours = [] for contour in contours: # 计算轮廓的面积和周长 area = cv2.contourArea(contour) perimeter = cv2.arcLength(contour, True) # 根据面积和周长进行筛选 if area > 100 and perimeter > 50: filtered_contours.append(contour) # 绘制筛选后的轮廓 contour_image = cv2.drawContours(image.copy(), filtered_contours, -1, (0, 255, 0), 2) # 显示结果 cv2.imshow('Binary Image', binary) cv2.imshow('Filtered Contour Image', contour_image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
在上述代码中,我使用了两个轮廓特征进行筛选:面积(area)和周长(perimeter)。根据实际需求,我设置了面积大于100且周长大于50的条件,您可以根据具体情况进行调整。
通过使用轮廓特征进行筛选,可以排除一些不需要的轮廓,只保留符合要求的文字轮廓。
请注意,轮廓特征的筛选条件需要根据具体需求进行调整。您可以根据文字的大小、形状等特征,结合实际情况来设定适合的筛选条件。
六、边缘检测算法示例代码
 下面是一个示例代码,演示了如何应用边缘检测算法(Canny边缘检测)来提取文字的边缘信息:
下面是一个示例代码,演示了如何应用边缘检测算法(Canny边缘检测)来提取文字的边缘信息:
import cv2 # 读取图像 image = cv2.imread('your_image.jpg', 0) # 边缘检测 edges = cv2.Canny(image, 100, 200) # 查找轮廓 contours, _ = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 绘制轮廓 contour_image = cv2.drawContours(image.copy(), contours, -1, (0, 255, 0), 2) # 显示结果 cv2.imshow('Edges Image', edges) cv2.imshow('Contour Image', contour_image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在上述代码中,我使用了Canny边缘检测算法来获取图像中文字的边缘信息。通过调整边缘检测的阈值(100和200),可以控制边缘检测的灵敏度,以获得清晰的文字边缘。
然后,使用cv2.findContours函数查找边缘图像中的轮廓,并使用cv2.drawContours函数绘制轮廓。
除了边缘检测,还可以尝试其他的图像分割算法,如基于区域的分割算法(如基于水平和垂直投影的方法)来将图像分割为文字和背景区域。
请注意,不同的图像处理技术适用于不同的场景和需求,您可以根据实际情况选择适合的技术来提取文字轮廓。
七、使用图像分割算法将图像分割为文字和背景区域示例代码
 基于区域的分割算法可以根据文字和背景的特征将图像分割为不同的区域。下面是一个示例代码,演示了如何使用基于区域的分割算法来将图像分割为文字和背景区域:
基于区域的分割算法可以根据文字和背景的特征将图像分割为不同的区域。下面是一个示例代码,演示了如何使用基于区域的分割算法来将图像分割为文字和背景区域:
import cv2 import numpy as np # 读取图像 image = cv2.imread('your_image.jpg') # 转换为灰度图像 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 二值化处理 _, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU) # 形态学操作(去除噪点) kernel = np.ones((3, 3), np.uint8) opening = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel, iterations=2) # 查找轮廓 contours, _ = cv2.findContours(opening, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 创建空白图像作为文字区域 text_region = np.zeros_like(image) # 根据轮廓绘制文字区域 for contour in contours: x, y, w, h = cv2.boundingRect(contour) cv2.drawContours(text_region, [contour], -1, (255, 255, 255), cv2.FILLED) # 提取文字区域 text_only = cv2.bitwise_and(image, text_region) # 显示结果 cv2.imshow('Original Image', image) cv2.imshow('Text Region', text_region) cv2.imshow('Text Only', text_only) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
在上述代码中,首先将彩色图像转换为灰度图像,然后使用自适应阈值二值化(Otsu’s方法)将图像转换为二值图像。接下来,通过形态学开运算去除噪点,然后使用cv2.findContours函数查找二值图像中的轮廓。
根据轮廓绘制一个与原始图像大小相同的空白图像,并使用cv2.drawContours函数将文字区域绘制为白色。最后,使用位运算cv2.bitwise_and提取原始图像中的文字区域。
请注意,基于区域的分割算法的效果可能会受到图像质量、光照条件等因素的影响。根据具体情况,您可以调整二值化的阈值、形态学操作的参数等来获得最佳的分割结果。
八、调整参数优化文字轮廓示例代码
 下面是一个示例代码,演示了如何通过调整参数来优化文字轮廓的提取效果:
下面是一个示例代码,演示了如何通过调整参数来优化文字轮廓的提取效果:
import cv2 # 读取图像 image = cv2.imread('your_image.jpg', 0) # 自适应阈值二值化(调整参数) binary = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 5) # 形态学操作(调整参数) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) dilated = cv2.dilate(binary, kernel, iterations=2) eroded = cv2.erode(dilated, kernel, iterations=1) # 查找轮廓 contours, _ = cv2.findContours(eroded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 筛选轮廓 filtered_contours = [] for contour in contours: # 计算轮廓的面积和周长 area = cv2.contourArea(contour) perimeter = cv2.arcLength(contour, True) # 根据面积和周长进行筛选(调整参数) if area > 100 and perimeter > 50: filtered_contours.append(contour) # 绘制筛选后的轮廓 contour_image = cv2.drawContours(image.copy(), filtered_contours, -1, (0, 255, 0), 2) # 显示结果 cv2.imshow('Binary Image', binary) cv2.imshow('Dilated Image', dilated) cv2.imshow('Eroded Image', eroded) cv2.imshow('Contour Image', contour_image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
在上述代码中,我调整了自适应阈值二值化和形态学操作的参数,以优化文字轮廓的提取效果。
在自适应阈值二值化中,我调整了窗口大小(11)和均值计算的偏移值(5)。您可以根据实际情况尝试不同的参数值。
在形态学操作中,我调整了核的大小和迭代次数。您可以尝试使用不同大小的核,并根据需要增加或减少迭代次数。
通过调整这些参数,您可以根据具体的图像和文字特征来优化文字轮廓的提取效果。
九、应用形态学操作优化文字轮廓示例代码
 下面是一个示例代码,演示了如何使用形态学操作来优化文字轮廓的提取效果:
下面是一个示例代码,演示了如何使用形态学操作来优化文字轮廓的提取效果:
import cv2 import numpy as np # 读取图像 image = cv2.imread('your_image.jpg', 0) # 自适应阈值二值化 binary = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2) # 形态学操作(膨胀和腐蚀) kernel = np.ones((3, 3), np.uint8) dilated = cv2.dilate(binary, kernel, iterations=1) eroded = cv2.erode(dilated, kernel, iterations=1) # 查找轮廓 contours, _ = cv2.findContours(eroded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 筛选轮廓 filtered_contours = [] for contour in contours: # 计算轮廓的面积和周长 area = cv2.contourArea(contour) perimeter = cv2.arcLength(contour, True) # 根据面积和周长进行筛选 if area > 100 and perimeter > 50: filtered_contours.append(contour) # 绘制筛选后的轮廓 contour_image = cv2.drawContours(image.copy(), filtered_contours, -1, (0, 255, 0), 2) # 显示结果 cv2.imshow('Binary Image', binary) cv2.imshow('Dilated Image', dilated) cv2.imshow('Eroded Image', eroded) cv2.imshow('Contour Image', contour_image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
在上述代码中,我使用了两种形态学操作:膨胀(dilate)和腐蚀(erode)。首先,使用cv2.dilate函数对二值化图像进行膨胀操作,以填充文字内部的空洞和连接断开的部分。然后,使用cv2.erode函数对膨胀后的图像进行腐蚀操作,以去除细小的噪点。
通过应用形态学操作,可以进一步改善文字轮廓的连通性和完整性,使得提取效果更好。
请注意,形态学操作的参数(如核大小、迭代次数)也可以根据实际情况进行调整,以获得最佳的效果。
十、筛选轮廓优化文字轮廓示例代码
 下面是一个示例代码,演示了如何通过筛选轮廓来优化文字轮廓的提取效果:
下面是一个示例代码,演示了如何通过筛选轮廓来优化文字轮廓的提取效果:
import cv2 # 读取图像 image = cv2.imread('your_image.jpg', 0) # 自适应阈值二值化 binary = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2) # 形态学操作(膨胀和腐蚀) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)) dilated = cv2.dilate(binary, kernel, iterations=1) eroded = cv2.erode(dilated, kernel, iterations=1) # 查找轮廓 contours, _ = cv2.findContours(eroded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 筛选轮廓(调整参数) filtered_contours = [] for contour in contours: # 计算轮廓的面积和周长 area = cv2.contourArea(contour) perimeter = cv2.arcLength(contour, True) # 根据面积和周长进行筛选(调整参数) if area > 100 and perimeter > 50: filtered_contours.append(contour) # 绘制筛选后的轮廓 contour_image = cv2.drawContours(image.copy(), filtered_contours, -1, (0, 255, 0), 2) # 显示结果 cv2.imshow('Binary Image', binary) cv2.imshow('Dilated Image', dilated) cv2.imshow('Eroded Image', eroded) cv2.imshow('Contour Image', contour_image) cv2.waitKey(0) cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
在上述代码中,我使用了自适应阈值二值化、膨胀和腐蚀操作来处理图像,并通过筛选轮廓来优化文字轮廓的提取效果。
根据具体需求,您可以调整自适应阈值二值化的参数、形态学操作的核大小和迭代次数,以及筛选轮廓的条件。这些参数可以根据图像特点和文字特征进行调整,以获得最佳的文字轮廓。
请注意,通过筛选轮廓可以排除一些不需要的轮廓,只保留符合要求的文字轮廓,从而进一步优化文字轮廓的提取效果。
十一、归纳总结
 自适应阈值二值化是一种常用的图像处理技术,用于根据局部像素的灰度值自动确定每个像素的阈值,从而将图像分割为前景和背景。下面是关于自适应阈值二值化处理图像以更好地提取文字轮廓的归纳总结知识点:
自适应阈值二值化是一种常用的图像处理技术,用于根据局部像素的灰度值自动确定每个像素的阈值,从而将图像分割为前景和背景。下面是关于自适应阈值二值化处理图像以更好地提取文字轮廓的归纳总结知识点:
-
自适应阈值二值化是一种基于局部像素灰度值的分割方法,可以应对图像中光照不均匀、背景复杂等问题。
-
自适应阈值二值化将图像分割为多个局部区域,并针对每个区域计算相应的阈值。这样可以使得每个区域的阈值更加适应该区域的光照和背景条件。
-
自适应阈值二值化算法通常使用局部均值或局部高斯加权平均来计算每个像素的阈值。
-
自适应阈值二值化可以通过调整参数来适应不同的图像和应用场景。其中,窗口大小决定了局部区域的大小,偏移值决定了阈值的计算方式。
-
在处理文字图像时,自适应阈值二值化可以有效地将文字区域与背景区域分割开来,提取出清晰的文字轮廓。
-
自适应阈值二值化通常与其他图像处理技术(如形态学操作、轮廓查找等)结合使用,以进一步优化文字轮廓的提取效果。
 总而言之,自适应阈值二值化是一种常用的图像处理方法,特别适用于处理文字图像以更好地提取文字轮廓。通过调整参数和结合其他技术,可以实现对不同图像的自适应处理,从而提高文字轮廓的准确性和可靠性。
总而言之,自适应阈值二值化是一种常用的图像处理方法,特别适用于处理文字图像以更好地提取文字轮廓。通过调整参数和结合其他技术,可以实现对不同图像的自适应处理,从而提高文字轮廓的准确性和可靠性。
希望这个归纳总结对您有所帮助!如果您有任何进一步的问题,请随时提问。

