
热门标签
热门文章
- 1苹果Vision Pro国行版首体验:百度网盘所有资源均可200寸大屏播放,一口气看个爽...
- 2人工智能Ai画画——stable diffusion 原理和使用方法详解!_stable diffusion组件
- 3OpenOrder解决CTP API的一系列问题说明_reqqryclassifiedinstrument
- 4猫头虎 最新 Linux 系统查看服务器温度的方法大全_linux 查看服务器温度
- 5细节详解 | Bert,GPT,RNN及LSTM模型
- 6安装java时errors_Kafka java client 连接异常(org.apache.kafka.common.errors.TimeoutException: Failed to upda...
- 7ES系列:range范围查询使用举例_es range
- 8C++STL详解(七)哈希_c++ 哈希 stl
- 9有什么免费python安装包?_python免费安装包
- 10Canal binlog 日志 Dump 流程分析_canal日志
当前位置: article > 正文
强化学习:第一部分,简介和主要概念_强化学习 csdn
作者:酷酷是懒虫 | 2024-07-11 11:10:59
赞
踩
强化学习 csdn
目录
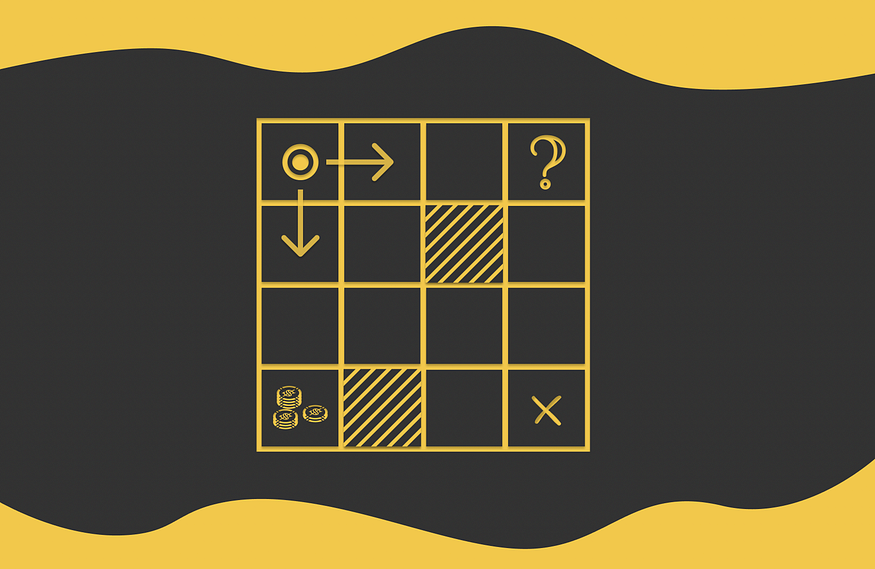
一、介绍
R强化学习是机器学习中的一个特殊领域,与监督或无监督学习中使用的经典方法有很大不同。
最终目标包括开发一种所谓的代理,该代理将在环境中执行最佳操作。从一开始,智能体通常表现得很差,但随着时间的推移,它通过与环境的交互来调整其策略,从试错法中调整其策略。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/809996
推荐阅读

相关标签

