
- 1原理+实战全面探索分布式锁之强大的Redisson【建议收藏】
- 2OSPF—动态路由协议_csdn. ospf
- 3我是这么绕过苹果ID锁的_么绕过苹果5s的隐藏id回主页面
- 4大模型文生图部署和使用教程,轻松实现AI绘图自由
- 5python编程:从入门到实践(第二版) 练习8-4_py编写函数制作t恤
- 6Python08--文件读取及写入操作_python 文件写入
- 7Java 8 函数式接口_遮罩层组件
- 8全网最全最新的Stable Diffusion提示词大全,最详细没有之一_stable diffusion 关键词
- 9免费实用的 Redis 可视化工具推荐, Redis DeskTop Manager 及 Another Redis Desktop Manager 的安装与使用,Redis Insight 下载安装_redis-desktop-manager
- 10FreeRTOS 创建任务_freertos创建任务
第12章 -集成学习_堆叠集成学习
赞
踩
目录
4.1 数据划分方法:自助法(Bootstrap Method)
4.3 Bagging 模型的典型用例:随机森林(Random Forest)
1 简介:
集成学习(Ensemble Learning)是一种机器学习方法,通过将多个学习器(也称为基分类器或弱分类器)组合在一起,以达到更好的预测性能。集成学习通过结合多个学习器的预测结果,可以降低单个学习器的偏差、方差或提高泛化能力,从而提高整体的预测准确性和鲁棒性。
集成学习的基本思想是“三个臭皮匠,顶个诸葛亮”,即通过组合多个弱分类器来形成一个强分类器。这种思想来源于统计学中的“多数表决原则”,即通过多数人的意见来决定最终结果。在集成学习中,弱分类器可以是不同的学习算法,也可以是同一算法在不同的子样本上训练得到的多个模型。
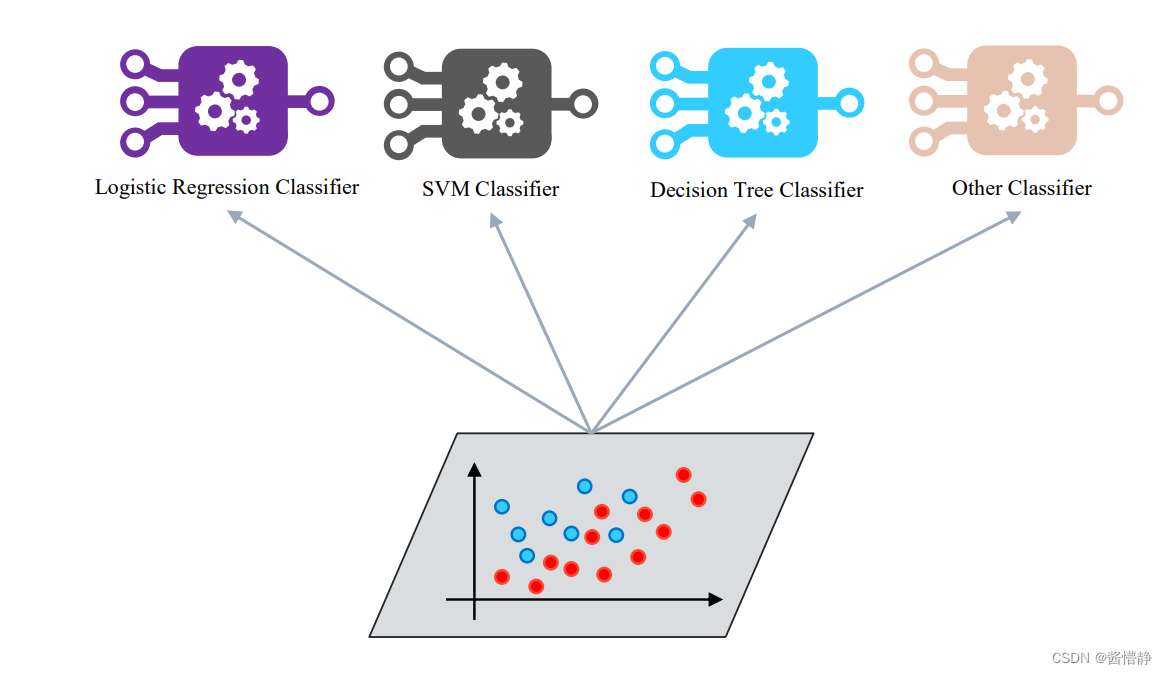
值得注意的是,集成学习并不是说一定要采取不同的机器学习算法结合为一个模型,而是先得到若干个体学习器,然后再采取结合策略组合为一个强学习器。
1.1 两个主要的问题:
在集成学习中,其中两个主要的问题就是:
1)如何得到若干个个体学习器?
2)如何选择一种结合策略,将这些个体学习器集合成一个强学习器?
对于问题1,我们需要从两个方面理解:①同构集成或异构集成;②串行生成和并行生成。
1.2 同构集成或异构集成:
同构集成(Homogeneous Ensemble):在同构集成中,可以使用同一种学习算法来得到若干个体学习器,它们之间可能在训练数据子集或参数设置上有所区别。这样的同构集成通常用于提高模型的稳定性和泛化能力。例如,使用多个决策树构建随机森林就是同构集成的一个例子。通过对训练数据进行随机采样和特征选择,每个决策树可以学习到不同的决策边界,最终集成它们的预测结果来提高整体模型的性能。
异构集成(Heterogeneous Ensemble):在异构集成中,可以使用不同的学习算法来得到若干个体学习器,它们具有不同的结构、特征或学习策略。这样的异构集成可以融合不同类型的学习器,从而利用它们的互补性,提高模型的表现能力。例如,将决策树、支持向量机和神经网络组合在一起形成一个集成模型就是异构集成的一种形式。每个学习器可以从不同的角度对数据进行建模,然后将它们的预测结果进行结合,以达到更好的整体性能。
1.3 串行生成和并行生成:
串行生成(Sequential Generation):在某些集成学习方法中,个体学习器之间存在强依赖关系,需要按照一定的顺序进行生成。这意味着每个个体学习器的生成依赖于前一个个体学习器的结果。典型的串行生成方法包括Boosting算法中的AdaBoost和Gradient Boosting等。在这些方法中,每个个体学习器的生成都依赖于前一个个体学习器的性能和权重调整。通过迭代训练和样本权重调整,每个个体学习器逐步提高对困难样本的拟合能力,从而形成一个强大的集成模型。
并行生成(Parallel Generation):另一类集成学习方法中,个体学习器之间不存在强依赖关系,可以同时生成。这意味着每个个体学习器的生成是独立的,可以并行进行。典型的并行生成方法包括Bagging算法中的随机森林(Random Forest)和Extra-Trees等。在这些方法中,每个个体学习器可以使用不同的训练数据子集进行独立训练,然后通过投票或平均等方式进行结合。并行生成方法的优势在于可以并行处理个体学习器的生成过程,从而提高了集成模型的训练效率。
1.4 三种结合策略:
常见的集成学习结合策略包括投票法(Voting)、平均法(Averaging)、学习法(Learning)等。
-
投票法:将多个分类器的预测结果进行投票,选择得票最多的类别作为最终的预测结果。投票法适用于分类问题,可以是简单投票,也可以是加权投票。
-
平均法:将多个回归器的预测结果进行平均,得到最终的预测结果。平均法适用于回归问题,可以是简单平均,也可以是加权平均。
-
学习法:学习法是一种基于元学习器的汇总策略,它通过学习个体学习器的权重或组合方式来生成最终的集成预测结果。元学习器可以是一个线性模型、神经网络或其他学习算法,它使用个体学习器的预测结果作为输入特征,并学习如何组合它们以获得最佳的集成预测结果。学习法能够自适应地调整个体学习器的权重或组合方式,以提高集成模型的性能和适应性。
1.5 实质:
集成学习有许多集成模型,如自助聚合Bagging、提升法Boosting(包括随机森林)、 堆叠法Stacking以及许多其它模型。集成方法的思想正是通过上述模型来将不同个体学习器(也称“基学习器”或“弱学习器”)的偏置或方差结合起来,从而创建一个更强的学习器(或集成模型),以获得更好的性能。
1.6 三种元算法:
下面介绍三种旨在组合弱学习器的元算法:
-
Boosting(提升法):Boosting是一种迭代的集成学习方法,该方法通常考虑的是同质弱学习器,采用串行生成。它通过训练一系列弱学习器(如决策树)来构建一个强学习器。在每一轮迭代中,Boosting根据之前模型的预测表现调整样本的权重,使得之前预测错误的样本在后续的学习中得到更多的关注。常见的Boosting算法包括AdaBoost、Gradient Boosting和XGBoost。
-
Bagging(自助采样法):Bagging通过自助采样的方式生成多个子训练集,并使用每个子训练集独立地训练出一个基础模型,该方法通常考虑的是同质弱学习器,采用并行生成。最后,通过对基础模型的预测结果进行平均或投票来得到最终的预测结果。Bagging的一个重要特点是每个子训练集可以包含重复的样本,这样可以增加模型对于整体数据分布的覆盖性。著名的Bagging算法包括随机森林(Random Forest)。
-
堆叠法(Stacking):堆叠法是一种更高级的集成学习方法,它通过训练一个元模型来结合多个基础模型的预测结果,该方法通常考虑的是异质弱学习器,采用并行生成。首先,多个基础模型被训练并用于预测数据。然后,这些预测结果被作为输入特征,连同原始数据的标签,一起用于训练元模型。最终,元模型使用基础模型的预测结果来进行最终的预测。
| 元算法 | 若干个体学习器的结构 | 生成方式 | 个体学习器类型 |
|---|---|---|---|
| Boosting(提升法) | 同构 | 串行 | 基学习器 |
| Bagging(自助采样法) | 同构 | 并行 | 基学习器 |
| 堆叠法(Stacking) | 异构 | 并行 | 组件学习器 |
怎么理解呢?说白了就是将“同构集成或异构集成”、“串行生成和并行生成”、“三种结合策略”杂糅在一起催生出了这三种元算法。
接下来我们将围绕这三种元算法展开深入讨论。
2 前置知识:
1、个体学习器:集成学习的一般结构都是先产生一组个体学习器(individual learner),在用某种策略将他们结合起来,个体学习器通常由一个现有的学习算法从训练数据中产生。
2、基学习器:如果集成中只包含同种类型的个体学习器,例如决策树集成中全都是决策树,这样的集成是‘同质’(homogeneous)的,同质集成中的个体学习器又称‘基学习器’,相应的学习算法又称基学习算法。
3、组件学习器:集成也可以是包含不同类型的个体学习器,例如决策树和神经网络相结合,这样的集成是‘异质’(heterogenous)的,异质集成中的个体学习器称为组件学习器或者直接称为个体学习器。
3 三种结合策略详解:
3.1 投票法:
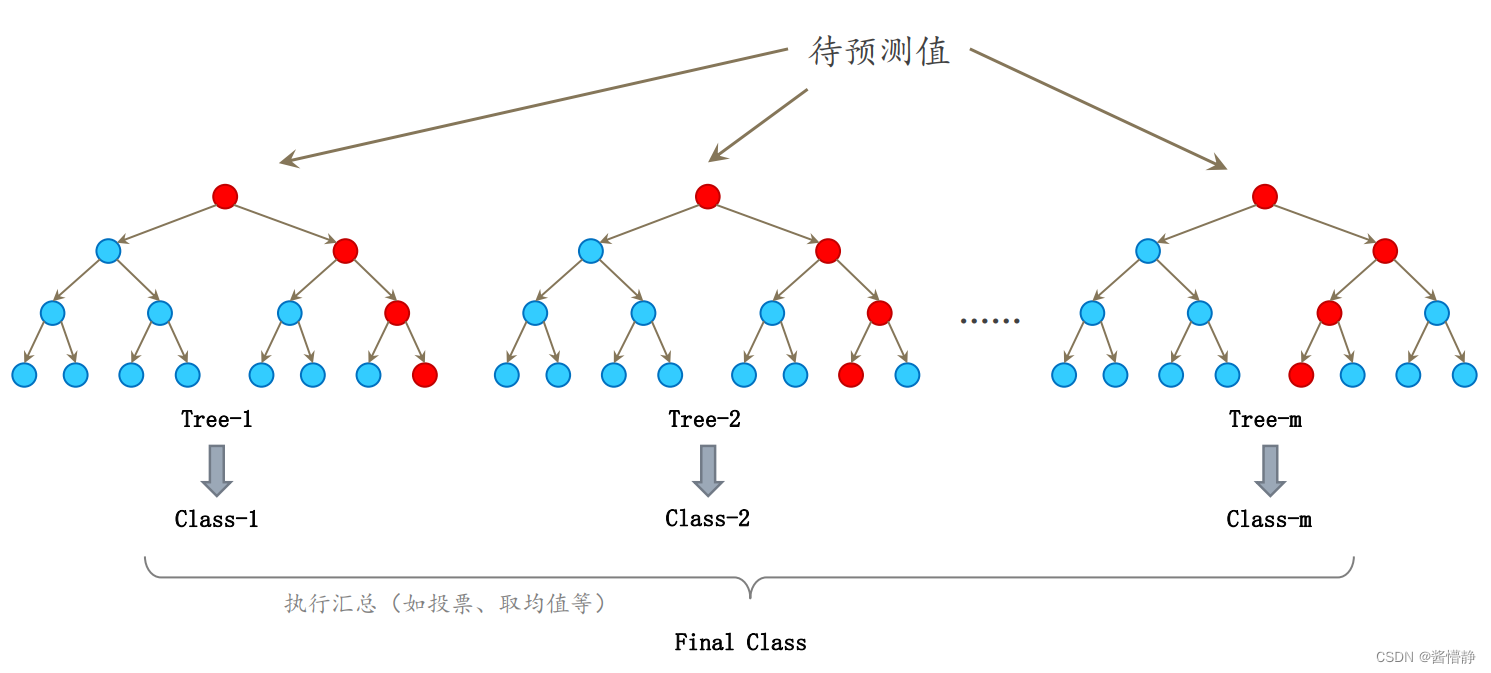
- 硬投票(Hard Voting):硬投票是一种简单的投票策略,其中每个个体学习器对样本进行预测后,集成模型通过多数表决(Majority Voting)来确定最终的预测类别。即选择得票最多的类别作为集成预测结果。在二分类问题中,如果有个体学习器预测为正类的票数大于等于预定阈值,则将最终结果判定为正类;否则,将结果判定为负类。在多分类问题中,最终结果是得票最多的类别。在所有分类器预测的结果里,选择出现频次最高的(少数服从多数)。采取这样的投票策略时,下图展示的集成学习模型则认为待预测样本应被归类为 1 类(3 > 1);
- 软投票(Soft Voting):是一种考虑概率的投票策略,其中每个个体学习器对样本进行预测后,集成模型通过对个体学习器的类别概率进行平均来确定最终的预测结果。对于分类问题,可以计算每个类别的平均概率,然后选择平均概率最高的类别作为集成预测结果。软投票能够利用个体学习器的概率信息,更加灵活地进行集成决策。采取这样的投票策略时,如果每个模型的概率是相同的话,下图展示的集成学习模型则认为待预测样本应被归类为 2 类。
-
加权投票(Weighted Voting):加权投票是一种在硬投票和软投票的基础上引入权重的投票策略。每个个体学习器对样本进行预测后,集成模型根据个体学习器的性能或其他指标为每个个体学习器分配一个权重。在硬投票中,可以根据权重进行投票,权重越高的个体学习器在最终决策中起到更大的作用。在软投票中,可以将个体学习器的类别概率乘以对应的权重,然后对加权概率进行平均得到最终的预测结果。加权投票允许个体学习器对最终结果的贡献程度不同,可以更精确地反映个体学习器的性能。

3.2 平均法:
-
简单平均法(Simple Averaging):简单平均法是最基本的平均法方法,它将多个个体学习器的预测结果直接进行算术平均。对于回归问题,可以直接对个体学习器的预测值进行平均;对于分类问题,可以对个体学习器的类别概率进行平均。
-
加权平均法(Weighted Averaging):加权平均法是在简单平均法的基础上引入权重的方法。每个个体学习器被分配一个权重,表示其在集成中的重要性或贡献度。这些权重可以根据个体学习器的性能、置信度或其他指标进行确定。最终的集成预测结果通过对个体学习器的预测结果进行加权平均得到,权重越高的个体学习器在最终结果中的影响越大。
-
经验风险最小化(Empirical Risk Minimization):经验风险最小化是一种特殊的平均法方法,它通过最小化集成模型的经验风险(即在训练集上的损失函数)来确定个体学习器的权重。这可以通过优化算法(如梯度下降)来实现,迭代地更新个体学习器的权重,使得在训练集上的整体性能最优。
3.3 学习法:
-
元模型(Meta-Model):元模型是一种学习法方法,它使用一个单独的元学习器(也称为元模型)来学习个体学习器的权重或组合方式。元模型可以是一个线性模型、神经网络、决策树等,它接收个体学习器的预测结果作为输入特征,并学习如何组合它们以获得最佳的集成预测结果。通过训练元模型,可以自适应地调整个体学习器的权重或组合方式,以提高集成模型的性能和适应性。
-
堆叠泛化(Stacking):堆叠泛化是一种学习法方法,它通过构建多层次的模型堆叠来进行集成学习。在堆叠泛化中,首先将训练数据划分为多个子集,并使用每个子集训练不同的个体学习器。然后,使用另一个元学习器来融合这些个体学习器的预测结果。这个元学习器可以是一个分类器,回归器或其他模型(不同于元模型的单层次,这个是多层次的),它接收个体学习器的预测结果作为输入,并输出最终的集成预测结果。堆叠泛化能够通过多层次的模型堆叠,充分利用个体学习器的多样性和组合能力。
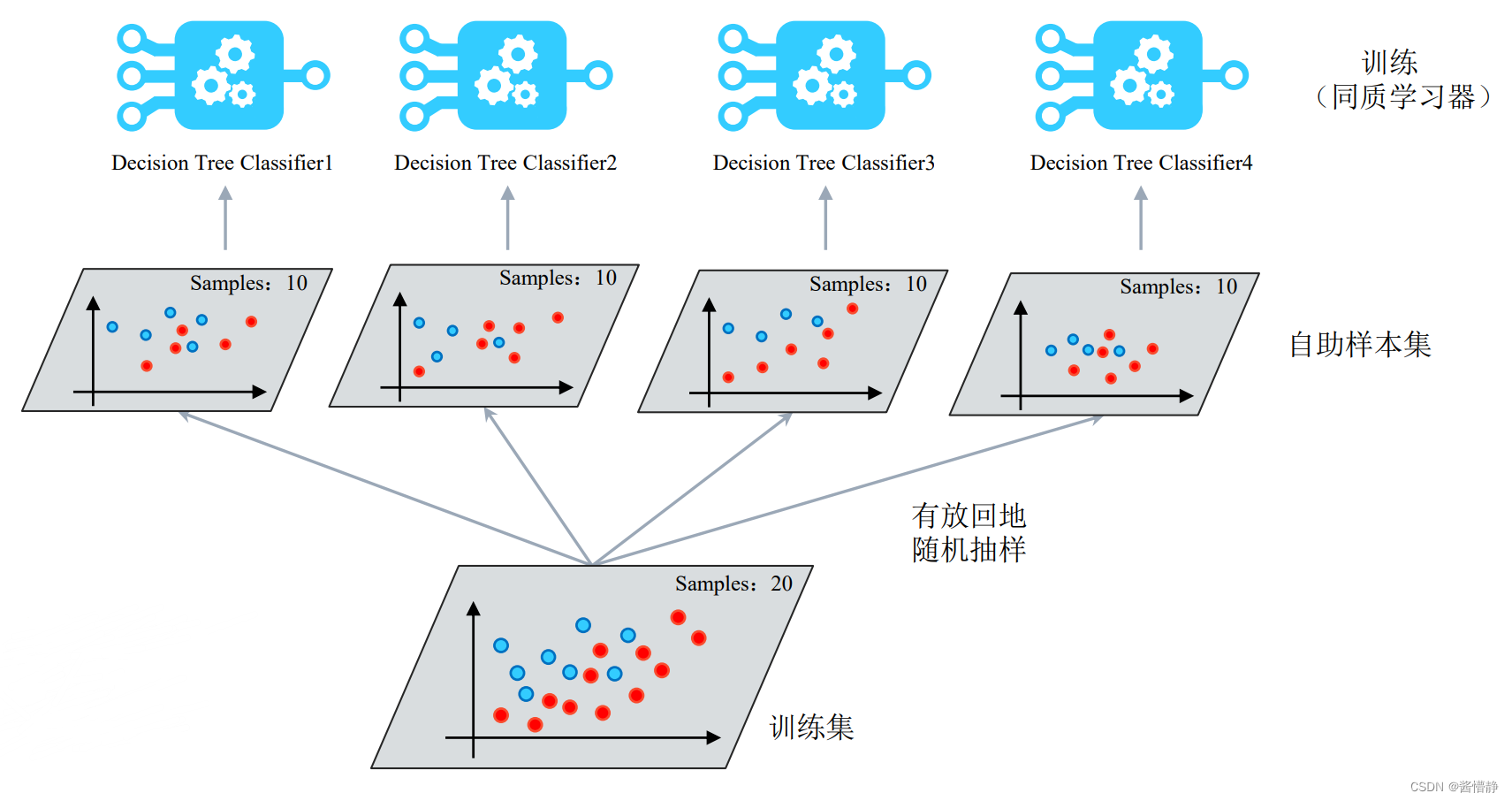
4 Bagging(自助聚合)模型:
并行化方法的最大特点是可以单独且同时训练不同学习器。最著名的方法是自助聚合(Bagging,全称是 Bootstrap Aggregation),它的目标是生成比单个模型更棒的集成模型。其实现思路是:并行训练多个弱学习器 ,并取平均值作为最终的预测结果。即:
![]()
(从该式可以看出,最终的预测结果将更加平滑,方差会大幅降低)
对于每个弱学习器,我们自然希望他它们能在某个方面取得较好的拟合效果(或者说,每个学习器都尽量对不一样的数据进行拟合,否则大家都训练统一的数据将毫无意义)。这样一来,在最终集成时就能汇总大家的长处,来共同组成一个在各方面都不错的集成模型。于是,我们需要设计一种方法,使得一份数据集能够被合理地划分为不同训练集。自助法显然是一个不错的方案。
4.1 数据划分方法:自助法(Bootstrap Method)
一句话来讲就是:从给定训练集中有放回地进行均匀抽样。
假设给定的数据集包含 n 个样本,接下来对该数据集进行有放回地抽样 m 次,这将产生含 m 个样本的训练集。由于采样时对每个样本都有放回,则用这样的方式得到的训练集很可能会包含一些重复样本(即某些样本在该训练集中出现多次)。

在某些假设条件下,这些样本具有非常好的统计特性:在一级近似中,它们可以被视为“直接从真实的底层(并且往往是未知的)数据分布中抽取出,并且彼此之间相互独立”。因此,它们被认为是真实数据分布的代表性和独立样本。为了使这种近似成立,需要最大限度地满足以下两点:
- 初始数据集的大小 n 应该足够大,以服从底层分布的大部分复杂性。这样,从数据集中抽样就是从真实分布中抽样的良好近似(代表性)。
- 与自助样本的大小 m 相比,数据集的规模 n 要足够大,这样样本之间就不会有太大的相关性(独立性)。
4.2 Bagging 策略
在对数据进行合理划分后,就能对其分别构建弱学习器,并在最后进行汇总。这个步骤可归结如下:
- 首先对训练数据集进行多次采样,保证每次得到的采样数据都是不同的;
- 分别训练多个同质的模型,例如树模型;
- 预测时需得到所有模型的预测结果再进行集成。
4.3 Bagging 模型的典型用例:随机森林(Random Forest)
Bagging 模型最典型的例子就是随机森林(Random Forest)。
随机是指数据采样随机,特征选择随机;森林则是指,一片森林由多棵决策树构成。
随机森林的优势在于:
- 能处理高纬度的数据(不用专门做特征选择);
- 训练后得到的模型能反映出哪些特征比较重要;
- 并行算法,执行速度较快;
- 具有可解释性,且便于进行可视化展示(实战部分会证明这一点)。
5 Boosting(提升法)模型:
顺序化方法的主要思路是对模型进行迭代拟合,即每次构建模型时都依赖于其在前一步所构建的模型。对于采取顺序化方法组合的弱模型而言,彼此之间不再独立,而是存在一种后者依赖于前者的关系。在顺序化方法中,提升法(Boosting) 是最著名的一种,由它生成的集成模型通常比组成该模型的弱学习器偏置更小。通俗地说就是,提升法认为:每加入一个新的弱学习器就一定要带来正收益,使得最终的集成模型更强。注意,在Boosting中,并不需要将原始数据集划分为多个训练集
Boosting 和 Bagging 的工作思路相同:构建一系列模型,将它们聚合起来得到一个性能更好的强学习器。然而,与重点在于减小方差的 Bagging 不同,Boosting 着眼于以一种适应性很强的方式顺序拟合多个弱学习器:序列中每个模型在拟合的过程中,会更加重视那些 “序列之前的模型处理很糟糕的观测数据” 。直观地说,每个模型都把注意力集中在目前最难拟合的观测数据上。这样一来,在该过程的最后,就能获得一个具有较低偏置的强学习器(显然,方差也会降低)。

和 Bagging 一样,Boosting 也可以用于回归和分类问题。由于其重点在于减小偏置,所以用 Boosting 基础模型的通常是那些低方差高偏置的模型。例如,如果想要使用树作为基础模型,我们将主要选择只有少许几层的较浅决策树。而选择低方差高偏置模型作为 Boosting 弱学习器的另一个重要原因是:这些模型拟合的计算开销较低(参数化时自由度较低)。实际上,由于拟合不同模型的计算无法并行处理(与 Bagging 最大的不同之处),因此顺序拟合若干复杂模型会导致计算开销变得非常高。
一旦选定了弱学习器,我们仍需要定义它们的拟合方式和聚合方式。这便引出两个重要的 Boosting 算法:自适应提升(Adaboost)和梯度提升(Gradient Boosting)。简单说来,这两种元算法在顺序化的过程中创建和聚合弱学习器的方式存在差异:
- 自适应提升算法:会更新附加给每个训练数据集中观测数据的权重;
- 梯度提升算法:会更新每个训练数据集中观测数据的值。
产生以上差异的主要原因是:两种算法解决优化问题(寻找最佳模型——弱学习器的加权和)的方式不同。
5.1 自适应提升(Adaboost)
5.1.1 原理:
自适应提升(Adaboost)算法的核心思想是:上一次分类错误的数据,接下来需要重点关注(就像上学时,我们的错题本)。因此,Adaboost 通过在训练样本数据时,不断修正对这些数据的权重,以此达到“对症下药”的目的,从而提高最终集成模型的分类效果。
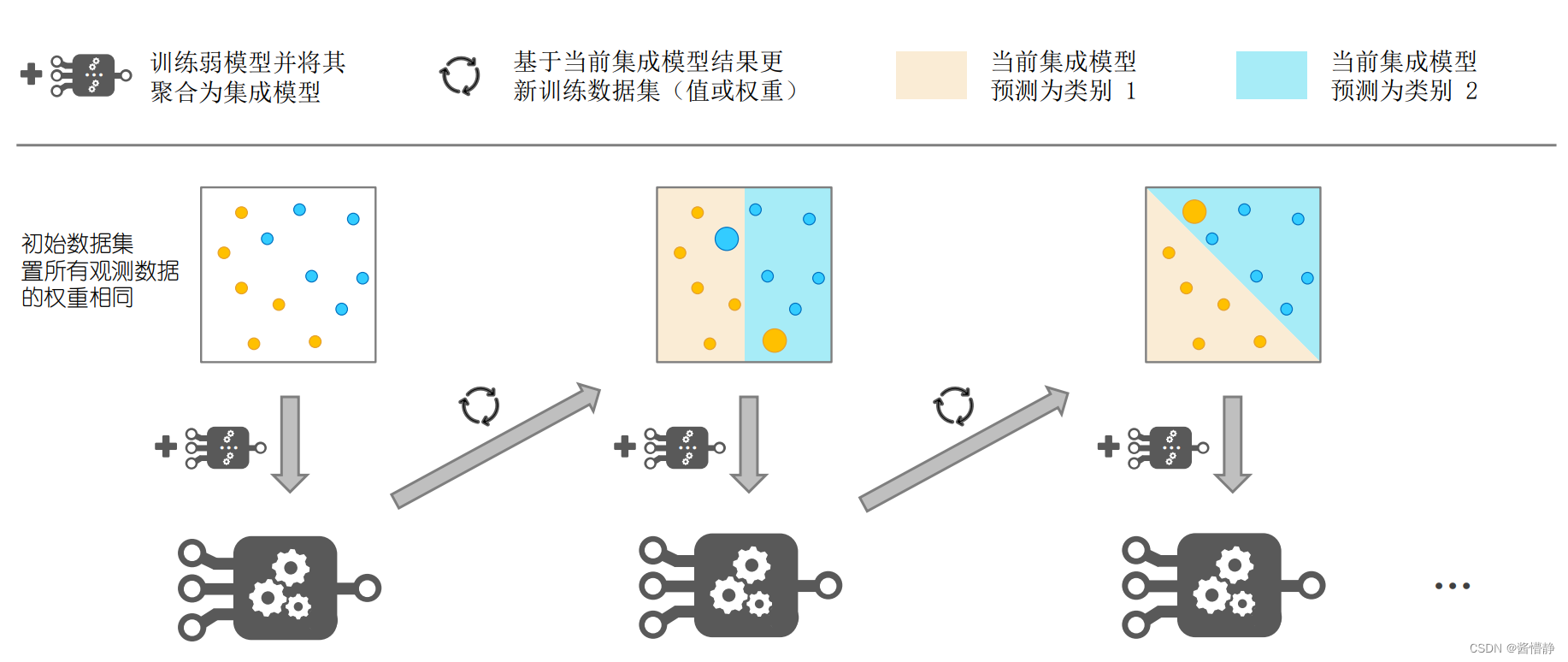
比如,初始的时候数据集上所有观测数据的权重是相同的,等到了下一次,我们将对分类预测错误的数据(黄色区域的蓝色和蓝色区域的黄色)进行重点关注(提高其权重)。
在自适应提升算法中,我们将集成模型定义为 L 个弱学习器的加权和:

其中 为权重系数(可理解为弱学习器的地位评估),
为弱学习器的拟合参数(可理解为弱学习器)。于是,求解集成模型就变为使上式参数最佳的一个优化问题(找到给出最佳整体加法模型的所有系数和弱学习器)。在一步之内“寻找使上式最优的参数”,这无疑是一个非常困难的优化问题。但是,我们可以采取更易于处理的迭代优化方式。也就是说,可以顺序地将弱学习器逐个添加到当前集成模型中,并在每次迭代时寻找可能的最佳组合(系数、弱学习器)。此时,可将某次迭代时的
定义为:(通过迭代的方式将整体优化用局部优化解决)
![]()
其中, 和
是被挑选出来使得
最适合的参数,因此这是对
的最佳可能改进。我们可以进一步将其表示为:
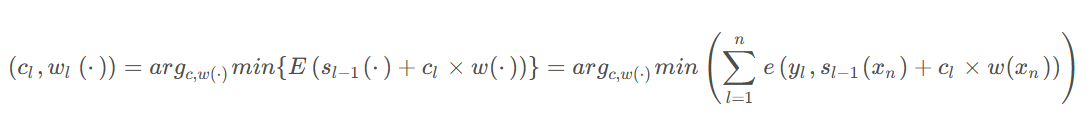
其中,E(⋅) 是给定模型的拟合误差,e(⋅) 是损失(误差)函数。因此,我们并没有在求和过程中对全部(L个)模型进行全局优化,而是通过局部优化来将近似最优系数以及弱学习器逐个添加到强模型中。
特别的是,在考虑二分类问题时,可将 Adaboost 算法写入以下过程:
- 更新数据集中观测数据的权重,并以此训练新的弱学习器(该学习器将重点关注当前集成模型误分类的观测数据);
- 根据一个表示该弱模型性能的更新系数,将弱学习器添加到加权和中(显然,弱学习器的性能越好,其对强学习器的贡献就越大,则对应的更新系数也越大)。
那么,更新系数如何得到呢?
-
对于每个弱学习器,计算其在训练数据集上的错误率(误分类率)。错误率可以通过统计被该弱学习器错误分类的样本数量除以总样本数量得到。
-
根据错误率计算弱学习器的更新系数。常用的计算公式是:
更新系数 = 0.5 * ln((1 - 错误率) / 错误率)
这个公式中,错误率越低的弱学习器会获得较高的更新系数,表示其在集成模型中的重要性更高。
5.1.2 整体流程:
基于此,假设面对具有 n 个观测数据的数据集,则在给定一组弱模型的情况下用 Adaboost 算法求解时,其过程如下:
- 算法开始,置所有观测数据相同权重
.
- 重复以下步骤 L 次(定义了 L 个弱学习器):
① 基于当前观测数据的权重拟合可能的最佳弱模型;
② 计算更新系数的值(更修系数是弱学习器的某种量化评估指标,表示其相对集成模型来说,该弱学习器的分量如何);
③ 添加新的弱学习器及其更新系数的乘积,并由该乘积来更新强学习器接下来要学习的观测数据的权重,该权重表示了在下一轮迭代中会重点关注哪些观测数据(在当前集成模型中,预测错误的观测数据其权重将增加,而预测正确的观测数据其权重则减小)。
重复以上步骤,就能顺序地构建出 L 个模型,并将它们聚合成一个简单的线性组合,最后再由表示每个学习器性能的系数加权。注意,初始 Adaboost 算法有一些变体,比如 LogitBoost(分类)或 L2Boost(回归),它们的差异主要取决于损失函数的选择。
5.2 梯度提升(Gradient Boosting)
5.2.1 原理:
梯度提升(Gradient Boosting)是一种常用于回归和分类问题的集成学习算法,主要以弱预测模型(通常是决策树)集合的形式产生预测模型。聚合算法汇聚不同弱学习器的结果,然后采取均值或投票方式产生最终结果,而梯度提升则是把所有学习器的结果累加起来得出最终结论。梯度提升的核心在于,每一个学习器学习的目标是之前所有学习器结论之和的残差。比如,小明的真实贷款额度为 1000,第一个学习器预测出是 950,差了 50,即残差为 50;那么在第二个学习器里,就需要把小明的贷款额度设为 50 去学习,如果第二个学习器在测试时真的能把小明的贷款额度预测为 50,则累加两个学习器的结果就是小明的真实贷款额度;如果第二个学习器的预测结果是 45,则仍然存在 5 的残差,那第三个学习器里小明的贷款额度就变成 5,继续学习……,直到达到设定的迭代次数或者达到预定的性能指标。这就是梯度提升的算法流程。
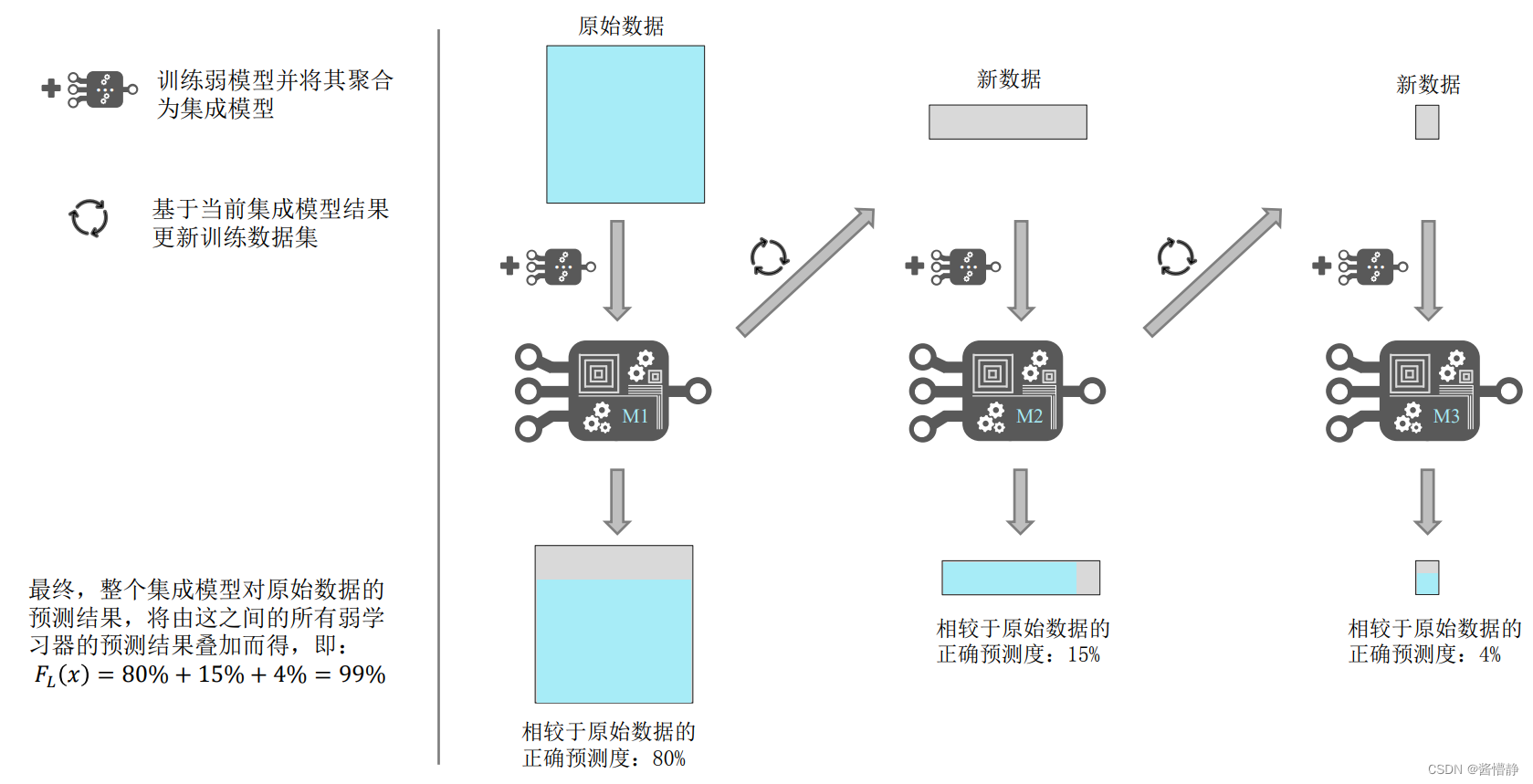
提升算法的主要思想是每步产生一个弱学习器,并不断把弱学习器加权累加到总模型当中,其基本公式如下:
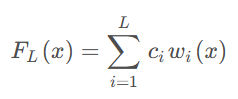
其中, 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/840620
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

