
- 1我在百科荣创企业实践——简易函数信号发生器(1)
- 2给公众号接入`FastWiki`智能AI知识库,让您的公众号加入智能行列_公众号接入ai
- 3生成式人工智能(AIGC):在软件开发中的助手与变革
- 4培训机构出来的程序员目前的就业前景怎么样?
- 56. 详解 IPSec 的 net2net-RSA 组网实践_xfrm 配置ipsec 中公钥、私钥、服务端证书、客户端证书详解
- 6Python模块multiprocessing & 实现多进程并发_python multiprocess
- 7LeetCode 打卡 Day 60 —— 234. 回文链表
- 8Metasploitable2 靶机漏洞(上)_metasploitable-linux-2.0.0靶机, 弱密码漏洞 1、mysql弱密码登录 2
- 9计算机网络网络层之层次化路由_层次化算力路由
- 10(2-5)基于内容的推荐:文本分类和标签提取_决策树标签怎么抽取
Elasticsearch09:Elasticsearch查询:searchType详解、ES 查询扩展、ES中分页的性能问题_es searchtype
赞
踩
一、ES Search查询
在ES中查询单条数据可以使用Get,想要查询一批满足条件的数据的话,就需要使用Search了。
下面来看一个案例,查询索引库中的所有数据,代码如下:
package com.imooc.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; /** * Search详解 * */ public class EsSearchOp { public static void main(String[] args) throws Exception{ //获取RestClient连接 RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("bigdata01", 9200, "http"), new HttpHost("bigdata02", 9200, "http"), new HttpHost("bigdata03", 9200, "http"))); SearchRequest searchRequest = new SearchRequest(); //指定索引库,支持指定一个或者多个,也支持通配符,例如:user* searchRequest.indices("user"); //执行查询操作 SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); //获取查询返回的结果 SearchHits hits = searchResponse.getHits(); //获取数据总量 long numHits = hits.getTotalHits().value; System.out.println("数据总数:"+numHits); //获取具体内容 SearchHit[] searchHits = hits.getHits(); //迭代解析具体内容 for (SearchHit hit : searchHits) { String sourceAsString = hit.getSourceAsString(); System.out.println(sourceAsString); } //关闭连接 client.close(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
在执行代码之前先初始化数据:
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/1' -d '{"name":"tom","age":20}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/2' -d '{"name":"tom","age":15}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/3' -d '{"name":"jack","age":17}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/4' -d '{"name":"jess","age":19}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/5' -d '{"name":"mick","age":23}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/6' -d '{"name":"lili","age":12}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/7' -d '{"name":"john","age":28}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/8' -d '{"name":"jojo","age":30}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/9' -d '{"name":"bubu","age":16}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/10' -d '{"name":"pig","age":21}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/11' -d '{"name":"mary","age":19}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在IDEA中执行代码,可以看到下面结果:
显示数据总数有11条,但是下面的明细内容只有10条,这是因为ES默认只会返回10条数据,如果默认返回所有满足条件的数据,对ES的压力就比较大了。
数据总数:11
{"name":"tom","age":20}
{"name":"tom","age":15}
{"name":"jack","age":17}
{"name":"jess","age":19}
{"name":"mick","age":23}
{"name":"lili","age":12}
{"name":"john","age":28}
{"name":"jojo","age":30}
{"name":"bubu","age":16}
{"name":"pig","age":21}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
二、searchType详解
ES在查询数据的时候可以指定searchType,也就是搜索类型
//指定searchType
searchRequest.searchType(SearchType.QUERY_THEN_FETCH);
- 1
- 2
searchType之前是可以指定为下面这4种:

其中QUERY AND FETCH和DFS QUERY AND FETCH这两种searchType现在已经不支持了。
这4种搜索类型到底有什么区别,下面我们来详细分析一下:
在具体分析这4种搜索类型的区别之前,我们先分析一下分布式搜索的背景:
ES天生就是为分布式而生的,但分布式有分布式的缺点,比如要搜索某个单词,但是数据却分别在5个分片(Shard)上面,这5个分片可能在5台主机上面。
因为全文搜索天生就要排序(按照匹配度进行排名),但数据却在5个分片上,如何得到最后正确的排序呢?ES是这样做的,大概分两步。
第1步:ES客户端将会同时向5个分片发起搜索请求。
第2步:这5个分片基于本分片的内容独立完成搜索,然后将符合条件的结果全部返回。
大致流程如下图所示:
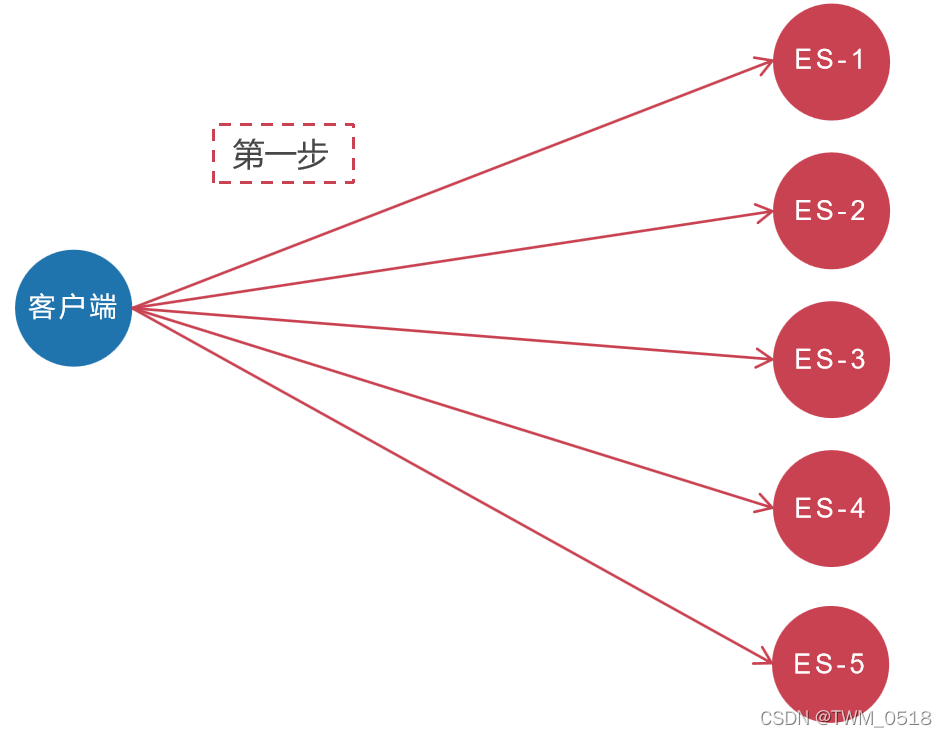
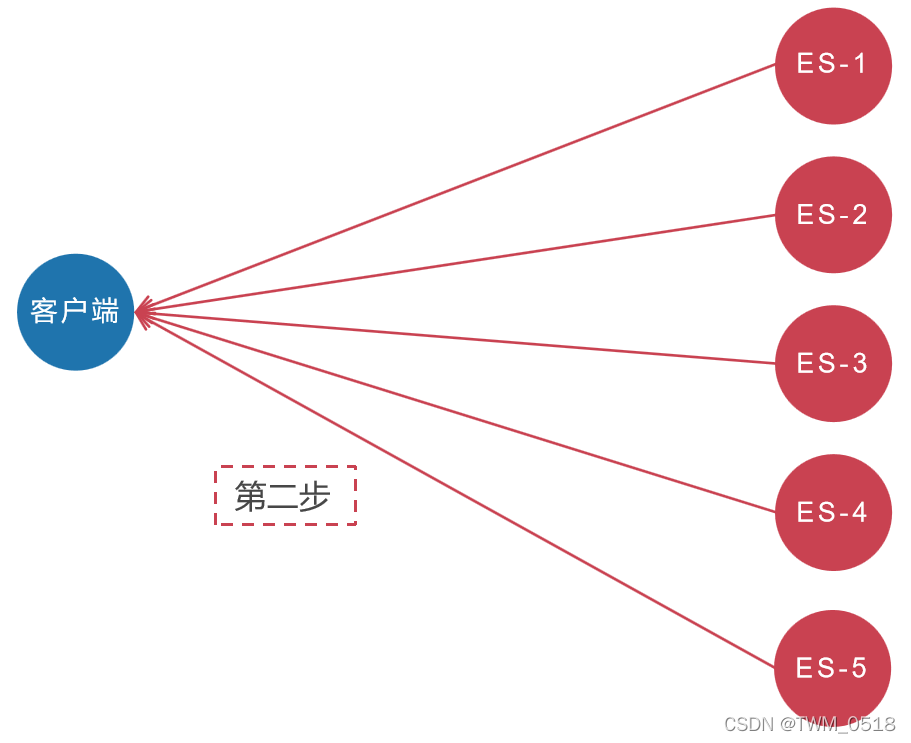
然而这其中有两个问题。
第一:数量问题。比如,用户需要搜索"衣服",要求返回符合条件的前10条。但在5个分片中,可能都存储着衣服相关的数据。所以ES会向这5个分片都发出查询请求,并且要求每个分片都返回符合条件的10条记录。这种情况,ES中5个分片最多会收到10*5=50条记录,这样返回给用户的结果数量会多于用户请求的数量。
第二:排名问题。上面说的搜索,每个分片计算符合条件的前10条数据都是基于自己分片的数据进行打分计算的。计算分值使用的词频和文档频率等信息都是基于自己分片的数据进行的,而ES进行整体排名是基于每个分片计算后的分值进行排序的(相当于打分依据就不一样,最终对这些数据统一排名的时候就不准确了),这就可能会导致排名不准确的问题。如果我们想更精确的控制排序,应该先将计算排序和排名相关的信息(词频和文档频率等打分依据)从5个分片收集上来,进行统一计算,然后使用整体的词频和文档频率为每个分片中的数据进行打分,这样打分依据就一样了。
再举个例子解释一下【排名问题】:
假设某学校有一班和二班两个班级。
期末考试之后,学校要给全校前十名学员发奖金。
但是一班和二班考试的时候使用的不是一套试卷。
一班:使用的是A卷【A卷偏容易】
二班:使用的是B卷【B卷偏难】
结果就是一班的最高分是100分,最低分是80分。
二班的最高分是70分,最低分是30分。
这样全校前十名就都是一班的学员了。这显然是不合理的。
因为一班和二班的试卷难易程度不一样,也就是打分依据不一样,所以不能放在一块排名,这个就解释了刚才的排名问题。
如果想要保证排名准确的话,需要保证一班和二班使用的试卷内容一样。
可以这样做,把A卷和B卷的内容组合到一块,作为C卷。
一班和二班考试都使用C卷,这样他们的打分依据就一样了,最终再根据所有学员的成绩排名求前十名就准确合理了。
这两个问题,ES也没有什么较好的解决方法,最终把选择的权利交给用户,方法就是在搜索的时候指定searchType。
1、QUERY AND FETCH
向索引的所有分片都发出查询请求,各分片返回的时候把元素文档(document)和计算后的排名信息一起返回。
这种搜索方式是最快的。因为相比下面的几种搜索方式,这种查询方法只需要去分片查询一次。但是各个分片返回的结果的数量之和可能是用户要求的数据量的N倍。
优点:
只需要查询一次
缺点:
返回的数据量不准确,可能返回(N*分片数量)的数据
并且数据排名也不准确
2、QUERY THEN FETCH(ES默认的搜索方式)
如果你搜索时,没有指定搜索方式,就是使用的这种搜索方式。这种搜索方式,大概分两个步骤,
第一步,先向所有的分片发出请求,各分片只返回文档id(注意,不包括文档document)和排名相关的信息(也就是文档对应的分值),然后按照各分片返回的文档的分数进行重新排序和排名,取前size个文档。
第二步,根据文档id去相关的分片取文档。这种方式返回的文档数量与用户要求的数量是相等的。
优点:
返回的数据量是准确的
缺点:
性能一般,
并且数据排名不准确
3、DFS QUERY AND FETCH
这种方式比第一种方式多了一个DFS步骤,有这一步,可以更精确控制搜索打分和排名。
也就是在进行查询之前,先对所有分片发送请求,把所有分片中的词频和文档频率等打分依据全部汇总到一块,再执行后面的操作、
优点:
数据排名准确
缺点:
性能一般
返回的数据量不准确,可能返回(N*分片数量)的数据
4、DFS QUERY THEN FETCH
比第2种方式多了一个DFS步骤。
也就是在进行查询之前,先对所有分片发送请求,把所有分片中的词频和文档频率等打分依据全部汇总到一块,再执行后面的操作、
优点:
返回的数据量是准确的
数据排名准确
缺点:
性能最差【这个最差只是表示在这四种查询方式中性能最慢,也不至于不能忍受,如果对查询性能要求不是非常高,而对查询准确度要求比较高的时候可以考虑这个】
DFS是一个什么样的过程?
DFS其实就是在进行真正的查询之前,先把各个分片的词频率和文档频率收集一下,然后进行词搜索的时候,各分片依据全局的词频率和文档频率进行搜索和排名。显然如果使用DFS_QUERY_THEN_FETCH这种查询方式,效率是最低的,因为一个搜索,可能要请求3次分片。但使用DFS方法,搜索精度是最高的。
总结一下,从性能考虑QUERY_AND_FETCH是最快的,DFS_QUERY_THEN_FETCH是最慢的。从搜索的准确度来说,DFS要比非DFS的准确度更高。
目前官方舍弃了QUERY AND FETCH和DFS QUERY AND FETCH这两种类型,保留了QUERY THEN FETCH和DFS QUERY THEN FETCH,这两种都是可以保证数据量是准确的。如果对查询的精确度要求没那么高,就使用QUERY THEN FETCH,如果对查询数据的精确度要求非常高,就使用DFS QUERY THEN FETCH。
三、ES 查询扩展
在查询数据的时候可以在searchRequest中指定一些参数,实现过滤、分页、排序、高亮等功能。
1、过滤
首先看一下如何在查询的时候指定过滤条件
核心代码如下:
//指定查询条件 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //查询所有,可以不指定,默认就是查询索引库中的所有数据 //searchSourceBuilder.query(QueryBuilders.matchAllQuery()); //对指定字段的值进行过滤,注意:在查询数据的时候会对数据进行分词 //如果指定多个query,后面的query会覆盖前面的query //针对字符串类型内容的查询,不支持通配符 //searchSourceBuilder.query(QueryBuilders.matchQuery("name","tom")); //searchSourceBuilder.query(QueryBuilders.matchQuery("age","17"));//针对age的值,这里可以指定字符串或者数字都可以 //针对字符串类型内容的查询,支持通配符,但是性能较差,可以认为是全表扫描 //searchSourceBuilder.query(QueryBuilders.wildcardQuery("name","t*")); //区间查询,主要针对数据类型,可以使用from+to 或者gt,gte+lt,lte //searchSourceBuilder.query(QueryBuilders.rangeQuery("age").from(0).to(20)); //searchSourceBuilder.query(QueryBuilders.rangeQuery("age").gte(0).lte(20)); //不限制边界,指定为null即可 //searchSourceBuilder.query(QueryBuilders.rangeQuery("age").from(0).to(null)); //同时指定多个条件,条件之间的关系支持and(must)、or(should) //searchSourceBuilder.query(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name","tom")).should(QueryBuilders.matchQuery("age",19))); //多条件组合查询的时候,可以设置条件的权重值,将满足高权重值条件的数据排到结果列表的前面 //searchSourceBuilder.query(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("name","tom").boost(1.0f)).should(QueryBuilders.matchQuery("age",19).boost(5.0f))); //对多个指定字段的值进行过滤,注意:多个字段的数据类型必须一致,否则会报错,如果查询的字段不存在不会报错 //searchSourceBuilder.query(QueryBuilders.multiMatchQuery("tom","name","tag")); //这里通过queryStringQuery可以支持Lucene的原生查询语法,更加灵活,注意:AND、OR、TO之类的关键字必须大写 //searchSourceBuilder.query(QueryBuilders.queryStringQuery("name:tom AND age:[15 TO 30]")); //searchSourceBuilder.query(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name","tom")).must(QueryBuilders.rangeQuery("age").from(15).to(30))); //queryStringQuery支持通配符,但是性能也是比较差 //searchSourceBuilder.query(QueryBuilders.queryStringQuery("name:t*")); //精确查询,查询的时候不分词,针对人名、手机号、主机名、邮箱号码等字段的查询时一般不需要分词 //初始化一条测试数据name=刘德华,默认情况下在建立索引的时候刘德华 会被切分为刘、德、华这三个词 //所以这里精确查询是查不出来的,使用matchQuery是可以查出来的 //searchSourceBuilder.query(QueryBuilders.matchQuery("name","刘德华")); //searchSourceBuilder.query(QueryBuilders.termQuery("name","刘德华")); //正常情况下想要使用termQuery实现精确查询的字段不能进行分词 //但是有时候会遇到某个字段已经分词建立索引了,后期还想要实现精确查询 //重新建立索引也不现实,怎么办呢? //searchSourceBuilder.query(QueryBuilders.queryStringQuery("name:\"刘德华\"")); //matchQuery默认会根据分词的结果进行 or 操作,满足任意一个词语的数据都会查询出来 //searchSourceBuilder.query(QueryBuilders.matchQuery("name","刘德华")); //如果想要对matchQuery的分词结果实现and操作,可以通过operator进行设置 //这种方式也可以解决某个字段已经分词建立索引了,后期还想要实现精确查询的问题(间接实现,其实是查询了满足刘、德、华这三个词语的内容) //searchSourceBuilder.query(QueryBuilders.matchQuery("name","刘德华").operator(Operator.AND));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
默认情况下ES会对刘德华这个词语进行分词,效果如下(使用的默认分词器):
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/emp/_analyze?pretty' -d '{"text":"刘德华"}' { "tokens" : [ { "token" : "刘", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "德", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "华", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
初始化数据:
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/12' -d '{"name":"刘德华","age":60}'
[root@bigdata01 ~]$ curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/user/_doc/13' -d '{"name":"刘老二","age":20}'
- 1
- 2
2、分页
ES每次返回的数据默认最多是10条,可以认为是一页的数据,这个数据量是可以控制的
核心代码如下:
//分页
//设置每页的起始位置,默认是0
//searchSourceBuilder.from(0);
//设置每页的数据量,默认是10
//searchSourceBuilder.size(10);
- 1
- 2
- 3
- 4
- 5
3、排序
在返回满足条件的结果之前,可以按照指定的要求对数据进行排序,默认是按照搜索条件的匹配度返回数据的。
核心代码如下:
//排序
//按照age字段,倒序排序
//searchSourceBuilder.sort("age", SortOrder.DESC);
//注意:age字段是数字类型,不需要分词,name字段是字符串类型(Text),默认会被分词,所以不支持排序和聚合操作
//如果想要根据这些会被分词的字段进行排序或者聚合,需要指定使用他们的keyword类型,这个类型表示不会对数据分词
//searchSourceBuilder.sort("name.keyword", SortOrder.DESC);
//keyword类型的特性其实也适用于精确查询的场景,可以在matchQuery中指定字段的keyword类型实现精确查询,不管在建立索引的时候有没有被分词都不影响使用
//searchSourceBuilder.query(QueryBuilders.matchQuery("name.keyword", "刘德华"));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4、高亮
针对用户搜索时的关键词,如果匹配到了,最终在页面展现的时候可以标红高亮显示,看起来比较清晰。
设置高亮的核心代码如下:
//高亮
//设置高亮字段
HighlightBuilder highlightBuilder = new HighlightBuilder()
.field("name");//支持多个高亮字段,使用多个field方法指定即可
//设置高亮字段的前缀和后缀内容
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
searchSourceBuilder.highlighter(highlightBuilder);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
解析高亮内容的核心代码如下:
//迭代解析具体内容 for (SearchHit hit : searchHits) { /*String sourceAsString = hit.getSourceAsString(); System.out.println(sourceAsString);*/ Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String name = sourceAsMap.get("name").toString(); int age = Integer.parseInt(sourceAsMap.get("age").toString()); //获取高亮字段内容 Map<String, HighlightField> highlightFields = hit.getHighlightFields(); //获取name字段的高亮内容 HighlightField highlightField = highlightFields.get("name"); if(highlightField!=null){ Text[] fragments = highlightField.getFragments(); name = ""; for (Text text : fragments) { name += text; } } //获取最终的结果数据 System.out.println(name+"---"+age); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
注意:必须要设置查询的字段,否则无法实现高亮。
//高亮查询name字段
searchSourceBuilder.query(QueryBuilders.matchQuery("name","tom"));
searchSourceBuilder.query(QueryBuilders.matchQuery("name","刘德华"));
- 1
- 2
- 3
5、评分依据(了解)
ES在返回满足条件的数据的时候,按照搜索条件的匹配度返回数据的,匹配度最高的数据排在最前面,这个匹配度其实就是ES中返回结果中的score字段的值。
//获取数据的匹配度分值,值越大说明和搜索的关键字匹配度越高
float score = hit.getScore();
//获取最终的结果数据
System.out.println(name+"---"+age+"---"+score);
- 1
- 2
- 3
- 4
此时,我们搜索name=刘华 的数据
searchSourceBuilder.query(QueryBuilders.matchQuery("name", "刘华"));
- 1
结果如下:
数据总数:2
<font color='red'>刘</font>德<font color='red'>华</font>---60---2.591636
<font color='red'>刘</font>老二---20---1.0036464
- 1
- 2
- 3
可以看到第一条数据的score分值为2.59
第二条数据的score分值为1.00
score分值具体是如何计算出来的呢?可以通过开启评分依据进行查看详细信息:
首先开启评分依据:
//评分依据,true:开启,false:关闭
searchSourceBuilder.explain(true);
- 1
- 2
- 3
获取评分依据信息:
//获取Score的评分依据
Explanation explanation = hit.getExplanation();
//打印评分依据
if(explanation!=null){
System.out.println(explanation.toString());
}
- 1
- 2
- 3
- 4
- 5
- 6
再执行程序,就可以看到具体的评分依据信息了:
数据总数:2 <font color='red'>刘</font>德<font color='red'>华</font>---60---2.591636 2.591636 = sum of: 1.0036464 = weight(name:刘 in 1) [PerFieldSimilarity], result of: 1.0036464 = score(freq=1.0), computed as boost * idf * tf from: 2.2 = boost 1.4552872 = idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from: 3.0 = n, number of documents containing term 14.0 = N, total number of documents with field 0.3134796 = tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from: 1.0 = freq, occurrences of term within document 1.2 = k1, term saturation parameter 0.75 = b, length normalization parameter 3.0 = dl, length of field 1.4285715 = avgdl, average length of field 1.5879896 = weight(name:华 in 1) [PerFieldSimilarity], result of: 1.5879896 = score(freq=1.0), computed as boost * idf * tf from: 2.2 = boost 2.3025851 = idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from: 1.0 = n, number of documents containing term 14.0 = N, total number of documents with field 0.3134796 = tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from: 1.0 = freq, occurrences of term within document 1.2 = k1, term saturation parameter 0.75 = b, length normalization parameter 3.0 = dl, length of field 1.4285715 = avgdl, average length of field <font color='red'>刘</font>老二---20---1.0036464 1.0036464 = sum of: 1.0036464 = weight(name:刘 in 2) [PerFieldSimilarity], result of: 1.0036464 = score(freq=1.0), computed as boost * idf * tf from: 2.2 = boost 1.4552872 = idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from: 3.0 = n, number of documents containing term 14.0 = N, total number of documents with field 0.3134796 = tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from: 1.0 = freq, occurrences of term within document 1.2 = k1, term saturation parameter 0.75 = b, length normalization parameter 3.0 = dl, length of field 1.4285715 = avgdl, average length of field
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
评分依据这块内容了解即可。
四、ES中分页的性能问题
在使用ES实现分页查询的时候,不要一次请求过多或者页码过大的结果,这样会对服务器造成很大的压力,因为它们会在返回前排序。
ES是分布式搜索,所以ES客户端的一个查询请求会发送到索引对应的多个分片中,每个分片都会生成自己的排序结果,最后再进行集中排序,以确保最终结果的正确性。
我们假设在搜索一个拥有5个主分片的索引,当我们请求第一页数据的时候,每个分片产生自己前10名,然后将它们返回给请求节点,然后这个请求节点会将收到的50条结果重新排序以产生最终的前10名。
现在想象一下我们如果要获得第1,000页的数据,也就是第10,001到第10,010条数据,每一个分片都会先产生自己的前10,010名,然后请求节点统一处理这50,050条数据,最后再丢弃掉其中的50,040条!
现在我们就明白了,在分布式系统中,大页码请求所消耗的系统资源是呈指数式增长的。这也是为什么网络搜索引擎一般不会提供超过1,000条搜索结果的原因。
例如:百度上的效果。
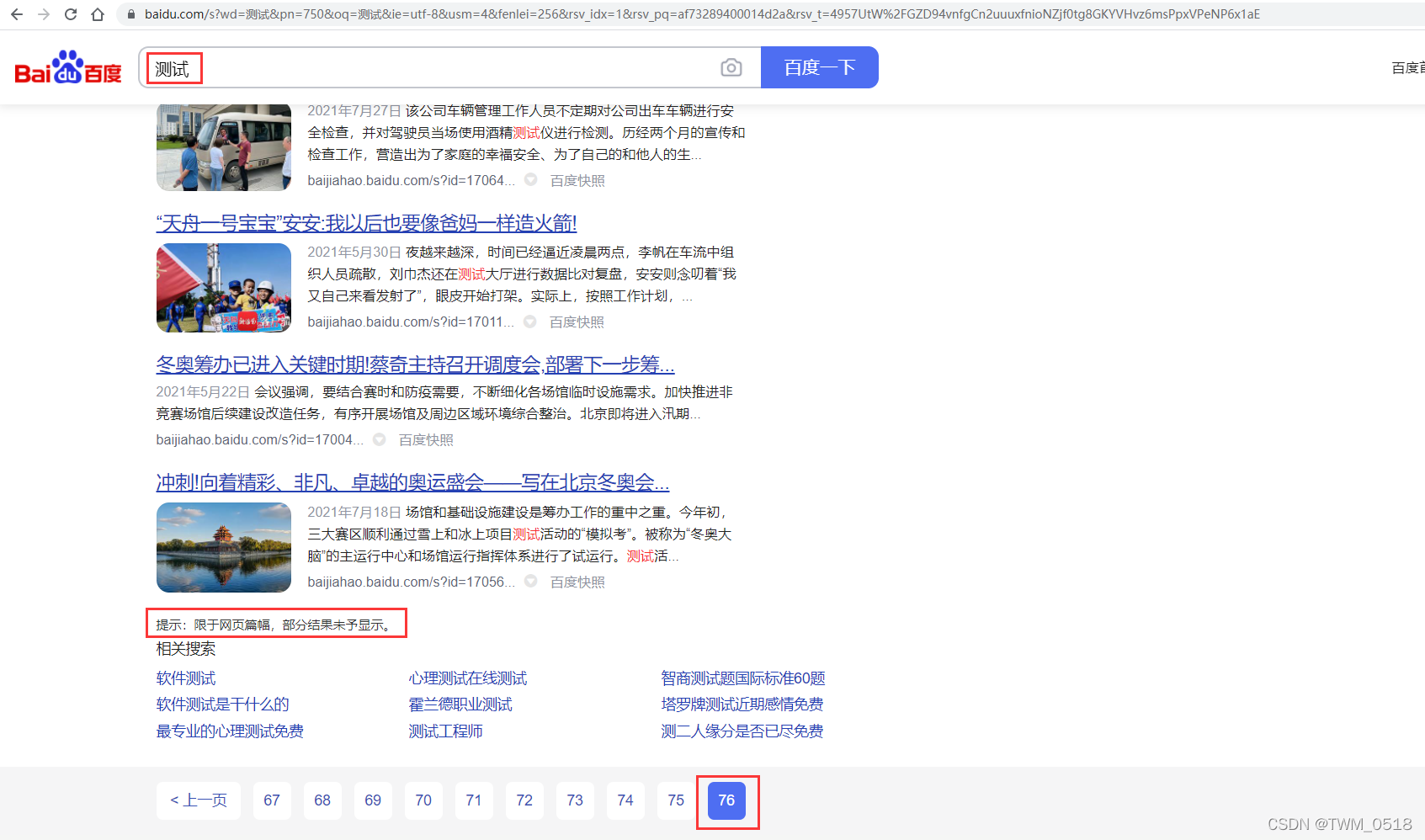
当然还有一点原因是后面的搜索结果基本上也不是我们想要的数据了,我们在使用搜索引擎的时候,一般只会看第1页和第2页的数据。
1、aggregations聚合统计
ES中可以实现基于字段进行分组聚合的统计
聚合操作支持count()、sum()、avg()、max()、min()等
下面来看两个案例
(1)统计相同年龄的学员个数
需求:统计相同年龄的学员个数
数据如下所示:
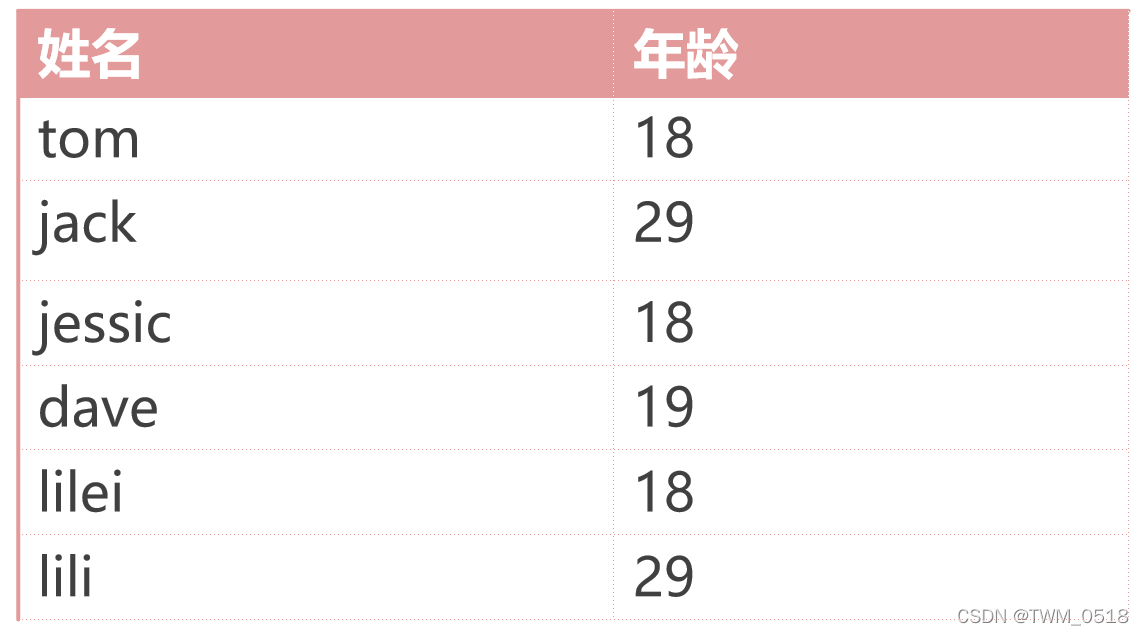
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/1' -d'{"name":"tom","age":18}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/2' -d'{"name":"jack","age":29}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/3' -d'{"name":"jessica","age":18}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/4' -d'{"name":"dave","age":19}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/5' -d'{"name":"lilei","age":18}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/6' -d'{"name":"lili","age":29}'
- 1
- 2
- 3
- 4
- 5
- 6
开发代码:
package com.imooc.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.aggregations.bucket.terms.Terms; import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder; import org.elasticsearch.search.builder.SearchSourceBuilder; import java.util.List; /** * 聚合统计:统计相同年龄的学员个数 * */ public class EsAggOp01 { public static void main(String[] args) throws Exception{ //获取RestClient连接 RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("bigdata01", 9200, "http"), new HttpHost("bigdata02", 9200, "http"), new HttpHost("bigdata03", 9200, "http"))); SearchRequest searchRequest = new SearchRequest(); searchRequest.indices("stu"); //指定查询条件 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //指定分组信息,默认是执行count聚合 TermsAggregationBuilder aggregation = AggregationBuilders.terms("age_term") .field("age"); searchSourceBuilder.aggregation(aggregation); searchRequest.source(searchSourceBuilder); //执行查询操作 SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); //获取分组信息 Terms terms = searchResponse.getAggregations().get("age_term"); List<? extends Terms.Bucket> buckets = terms.getBuckets(); for (Terms.Bucket bucket: buckets) { System.out.println(bucket.getKey()+"---"+bucket.getDocCount()); } //关闭连接 client.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
(2)统计每个学员的总成绩
需求:统计每个学员的总成绩
数据如下所示:
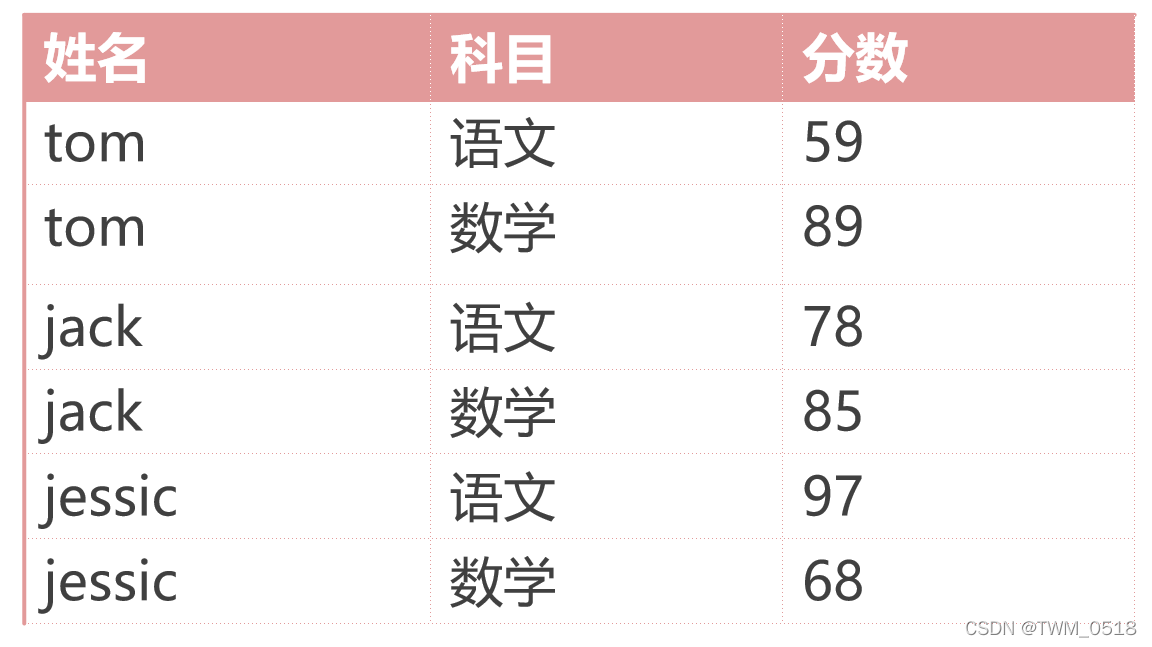
首先在ES中初始化这份数据:
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/score/_doc/1' -d'{"name":"tom","subject":"chinese","score":59}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/score/_doc/2' -d'{"name":"tom","subject":"math","score":89}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/score/_doc/3' -d'{"name":"jack","subject":"chinese","score":78}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/score/_doc/4' -d'{"name":"jack","subject":"math","score":85}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/score/_doc/5' -d'{"name":"jessica","subject":"chinese","score":97}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/score/_doc/6' -d'{"name":"jessica","subject":"math","score":68}'
- 1
- 2
- 3
- 4
- 5
- 6
开发代码:
package com.imooc.es; import org.apache.http.HttpHost; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.search.aggregations.Aggregation; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.aggregations.bucket.terms.Terms; import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder; import org.elasticsearch.search.aggregations.metrics.Sum; import org.elasticsearch.search.builder.SearchSourceBuilder; import java.util.List; /** * 聚合统计:统计每个学员的总成绩 * */ public class EsAggOp02 { public static void main(String[] args) throws Exception{ //获取RestClient连接 RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("bigdata01", 9200, "http"), new HttpHost("bigdata02", 9200, "http"), new HttpHost("bigdata03", 9200, "http"))); SearchRequest searchRequest = new SearchRequest(); searchRequest.indices("score"); //指定查询条件 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //指定分组和求sum TermsAggregationBuilder aggregation = AggregationBuilders.terms("name_term") .field("name.keyword")//指定分组字段,如果是字符串(Text)类型,则需要指定使用keyword类型 .subAggregation(AggregationBuilders.sum("sum_score").field("score"));//指定求sum,也支持avg、min、max等操作 searchSourceBuilder.aggregation(aggregation); searchRequest.source(searchSourceBuilder); //执行查询操作 SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); //获取分组信息 Terms terms = searchResponse.getAggregations().get("name_term"); List<? extends Terms.Bucket> buckets = terms.getBuckets(); for (Terms.Bucket bucket: buckets) { //获取sum聚合的结果 Sum sum = bucket.getAggregations().get("sum_score"); System.out.println(bucket.getKey()+"---"+sum.getValue()); } //关闭连接 client.close(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
2、aggregations获取所有分组数据
默认情况下,ES只会返回10个分组的数据,如果分组之后的结果超过了10组,如何解决?
可以通过在聚合操作中使用size方法进行设置,获取指定个数的数据组或者获取所有的数据组。
在案例1的基础上再初始化一批测试数据:
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/61' -d'{"name":"s1","age":31}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/62' -d'{"name":"s2","age":32}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/63' -d'{"name":"s3","age":33}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/64' -d'{"name":"s4","age":34}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/65' -d'{"name":"s5","age":35}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/66' -d'{"name":"s6","age":36}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/67' -d'{"name":"s7","age":37}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/68' -d'{"name":"s8","age":38}'
[root@bigdata01 ~]# curl -H "Content-Type: application/json" -XPOST 'http://bigdata01:9200/stu/_doc/69' -d'{"name":"s9","age":39}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
支持案例1的代码,查看返回的分组个数:
18---3
29---2
19---1
31---1
32---1
33---1
34---1
35---1
36---1
37---1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
发现结果中返回的分组个数是10个,没有全部都显示出来,这个其实和分页也没关系,尝试增加分页的代码发现也是无效的:
//增加分页参数,注意:分页参数针对分组数据是无效的。
searchSourceBuilder.from(0).size(20);
- 1
- 2
执行案例1的代码,结果发现还是10条数据。
18---3
29---2
19---1
31---1
32---1
33---1
34---1
35---1
36---1
37---1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
通过在聚合操作上使用size方法进行设置:
TermsAggregationBuilder aggregation = AggregationBuilders.terms("age_term")
.field("age")
.size(20);//获取指定分组个数的数据
- 1
- 2
- 3
执行案例1的代码:
18---3
29---2
19---1
31---1
32---1
33---1
34---1
35---1
36---1
37---1
38---1
39---1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
此时可以获取到所有分组的数据,因为结果一共有12个分组,在代码中通过size设置最多可以获取到20个分组的数据。
如果前期不确定到底有多少个分组的数据,还想获取到所有分组的数据,此时可以在size中设置一个Integer的最大值,这样基本上就没什么问题了,但是注意:如果最后的分组个数太多,会给ES造成比较大的压力,所以官方在这做了限制,让用户手工指定获取多少分组的数据。
TermsAggregationBuilder aggregation = AggregationBuilders.terms("age_term")
.field("age")
.size(Integer.MAX_VALUE);//获取指定分组个数的数据
- 1
- 2
- 3
注意:在ES7.x版本之前,想要获取所有的分组数据,只需要在size中指定参数为0即可。现在ES7.x版本不支持这个数值了。

