
- 1Git版本回退更新(强制回退、记录回退)_git强制回滚之前版本
- 2android adb启动失败问题 adb server is out of date. killing... ADB server didn't ACK * failed to start daem_adb nodaemon server
- 3Python爬虫可视化大屏项目居然如此简单!原来都是这样做到的!!_爬虫可视化项目
- 4oracle批量插入数据_oracle新增多条数据sql
- 5淘宝“明星同款”可能要被AI抓出来打了,阿里新研究专攻服装局部抄袭丨CVPR...
- 6PHP开发的小程序如何在本地运行
- 7揭秘视频平台全民任务:会拍视频就能日赚几十元的详细拆解
- 8mysql中的隐式转换_mybatis 0 隐式转换
- 9javascript高级语言程序设计,javascript高级程序编程_javascript高级程序设计
- 10Mooncake:LLM服务的KVCache为中心分解架构_mooncake 月之暗面
图解DSPy:Prompt的时代终结者?!
赞
踩

大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于如果构建生成级别的AI架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。
DSPy是一种编程模型,旨在改进语言模型 (LM)在复杂任务中的使用方式。传统上,LM使用特定的提示模板(Prompt)进行控制,这些模板是基本前期大量的尝试而找到的预设指令。DSPy通过将LM流水线抽象为文本转化图谱,例如被其他申明模块触发的LM的命令计算图谱。

Prompt Engineering
要理解DSPy,需要先理解提示词工程Prompt Engineering。提示词工程也称之为上下文提示词或者上下文学习。它指的是在不更新模型权重的情况下引导LLM的行为以获得预期结果的方法,它属于非参数的模型微调。
20%的EMNLP'23的出版物都是关于提示词工程,其中最受欢迎的字符串模板库有LangChain和LlamaIndex。
提示词工程很好用,简单,高效而且低开销。它在不占用GPU,5分钟之内可以通过调用API快速的试错,而且大部分的提示词可以用一到两句话来解释。

上图为提示词工程的示例,加上一句话“按照artstation的风格来”,结果大不一样。
但是提示词工程最大的问题是它很脆弱,而且缺乏系统性的方法来提升。很多的技巧需要大量的实验和启发式方法,结果不能普遍应用于所有 LLMs/VLM,甚至不能应用于同一LLM家族的不同版本,例如gpt 3->3.5->4。
在继续往下之前,先来复习下传统的Prompt Engineering有哪些?

Zero-Shot,直接提问将数据直接塞给LLM

Few-Shot,在提问的时候,列出一些例子然后和问题一起送给LLM回答。上面要引导大模型进行情感分析,然后列举了一些例子。这里好比你学了很多知识,但是考试的时候,总需要有人告诉你答题的规则。

Instruction-Prompt,在提问的时候,针对回答给出明确的指令。
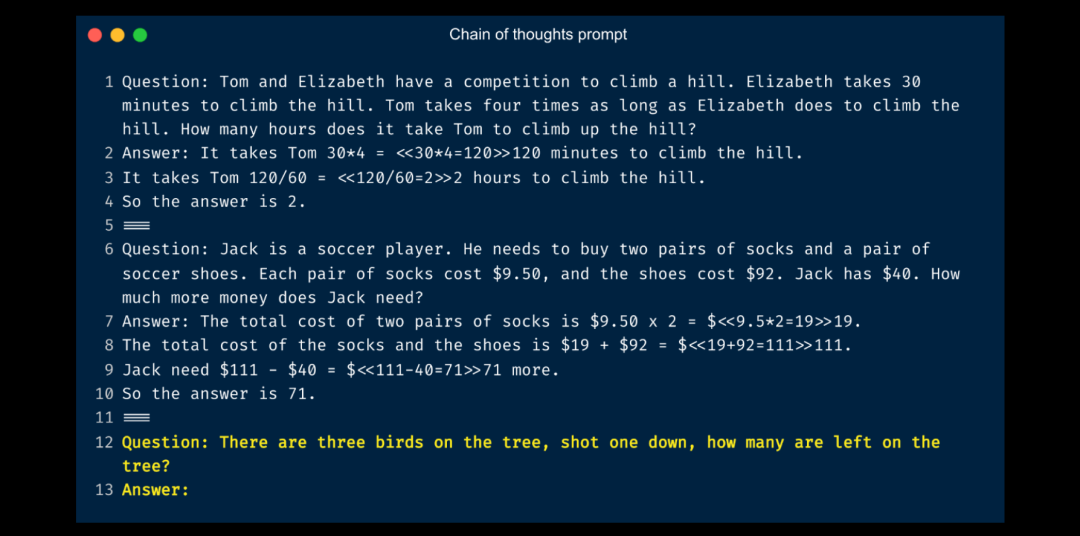
Chain-OF-thought,在提问的时候,帮助大模型整理思维链,以便于大模型能够按照思维链进行回答。

Chain-OF-thought,可以配合zero-shot或者Few-shot进行提问,靠人工或者自动化生成的推导思维链作为上下文。

Program-OF-thought,在提问的时候,让大模型给出可以运行的代码,然后运行可以得到更加正确的答案。

当然基于PROMPT的原理,还可以外挂知识库,比如目前比较流行的RAG

以上为传统提示词工程的概览图

DSPy
对照传统的Prompt Engineering,DSPy其实覆盖了灰色部分:
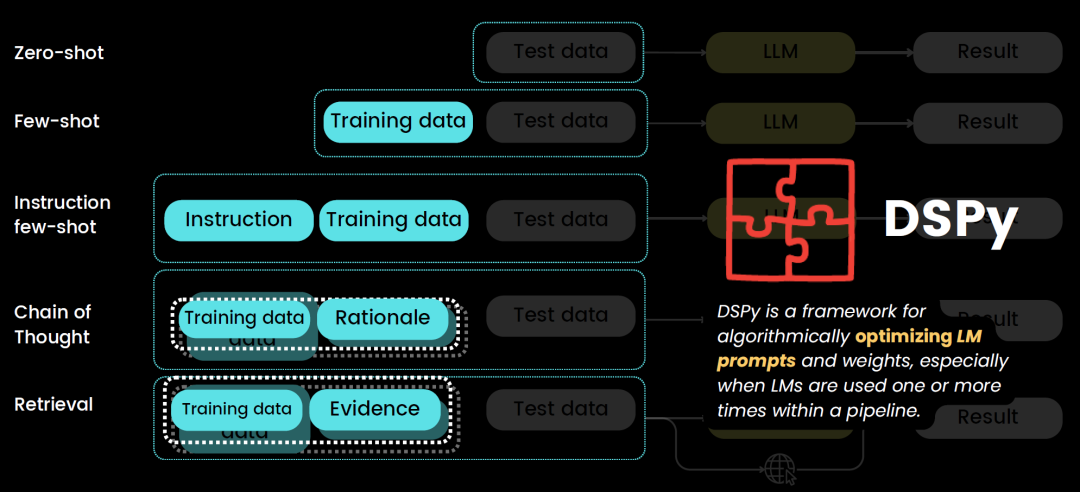
那么什么是DSPy?

DSPy 是一个用于算法优化提示和 LM 权重的框架。然而,它的学习曲线是陡峭的,“是的,伙计,我到处都能看到DSPy,但还没有时间看。”——小编笑了~
DSPy有三个抽象,各位读者先记一下。分别为signatures(签名,这个取名不大贴切), modules(模块或者组件), 和teleprompters(提示器或者优化器)。
DSPy有两个特点,其一,它闭环了提示词工程。它将提示词工程从通常的手动和人工的过程转变为结构化、定义明确的机器学习工作流程(这个流程包括准备数据集、定义模型、训练、评估和测试)。这应该是最具革命性的方面。下图应该很形象地将这段文字表达了出来。

其二,它将逻辑和文本表达分离。说白了就是将传统的提示词工程通过一些语法糖,比较优雅的进行封装。

下面来一段让读者们感受下便捷性,首先要先预设下大模型
import dspy#设置大语言模型turbo = dspy.OpenAI(model='gpt-3.5-turbo-0125', api_key='KEYS', model_type='text')dspy.settings.configure(lm=turbo)第二步定义一个类,看起来和PyTorch定义模型一个调调,只不过父类变成了dspy.Module。
class HelloQA(dspy.Module): def __init__(self): super().__init__() self.prog = dspy.Predict("question -> answer") #在这里定义基本的逻辑 def forward(self, question): return self.prog(question=question)这个时候不用写提示词工程了,直接:
QA = HelloQA()response = QA.forward("How many legs does elephant has?")print(response.answer)结果显示为“Elephant has four legs.”,就是这么干净漂亮!
Elephant has four legs.
小结
至此已经完成了DSPy的初步入门,上面的铺垫之后回头再看看DSPy的三大组件。
Signatures是声明性规范,它抽象出DSPy编程模型中模块的输入/输出行为。这些签名用于指定任务需要执行的操作,而不是如何提示语言模型执行任务。这种方法抽象了提示和微调过程,使其更加模块化。

Modules取代了现有的手动提示词技术,并且可以在管道中随意集成。它利用LM执行各种任务的程序块。DSPy中的每个模块都是参数化的,这意味着它具有可学习的参数,包括提示的细节、要使用的语言模型以及提示。它根据定义的Signatures处理输入,并根据该处理返回输出。
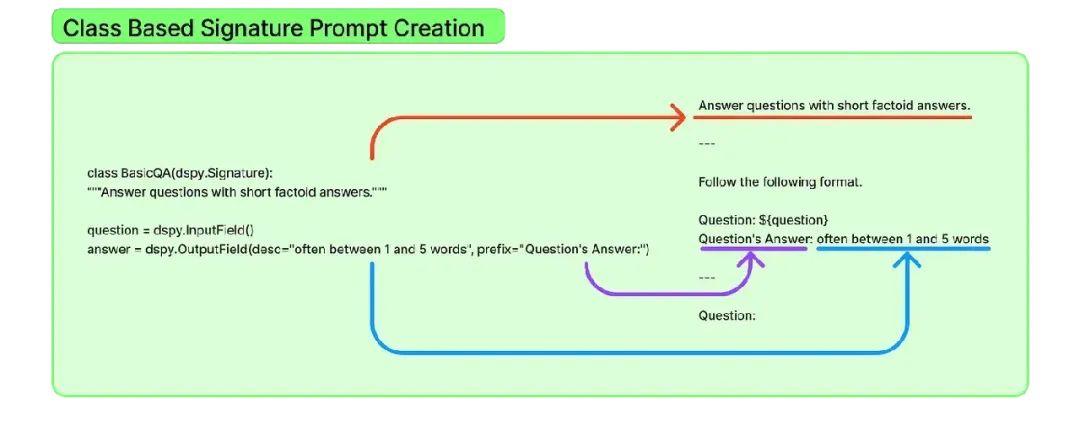
DSPy内置了如下几个模块:
dspy.Predict :基本预测变量
dspy.ChainOfThought:教LM在对Signatures响应之前逐步思考
dspy.ProgramOfThought:教LM 输出代码
dspy.ReAct:能够实现某个Signatures功能的代理(利用工具)
dspy.MultiChainComparison:可以比较多个 ChainOfThought 输出以产生最终预测
例如要实现RAG,分分钟的事情:
import dspyclass RAG(dspy.Module): def __init__(self, num_passages=3): self.retrieve = dspy.Retrieve(k=num_passages) self.generate_answer = dspy.ChainOfThought("context, question -> answer")
def forward(self, question): context = self.retrieve(question).passages return self.generate_answer(context=context, question=question)Teleprompters优化管道中的所有模块,以便于获取最优的评估指标。DSPy 优化器,以前称为提词器,是一种算法,可以调整 DSPy 程序的参数(即提示和/或 LM 权重),以最大限度地提高指定指标,例如准确性。
借助DSPy可以用简洁明了的用Modules替换手工制作的提示词工程,而不会降低质量或表达能力。对Modules进行参数化并将提示视为优化问题,使DSPy能够更好地适应不同的LM。它的模块化能够构建更加具有实用性的应用以及更佳细腻的效果评估标准。
编译正确的Modules可将不同的 LM 的准确率从 4-20% 提高到 49-88%。


