
- 1MySQL 学习笔记(一)_费霄霄
- 2git从clone到pr的全流程_怎么git 去pr别的项目
- 3九大数据分析方法:矩阵分析法
- 4【人工智能】 使用线性回归预测波士顿房价 paddlepaddle 框架 飞桨
- 5【AI原理解析】— 字节豆包模型_豆包语言模型
- 6ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory解决方案
- 7TortoiseGit 使用说明_tortoisegit弹出no working directory found
- 8SD-WAN:成功部署的七个步骤_开源sdwan部署
- 9深度学习四大框架之争(Tensorflow、Pytorch、Keras和Paddle)_pytorch、tensorflow,padl
- 10软件测试52讲-笔记(持续更新中...)_软件测试52讲 百度云
Qwen2 -微调 Qwen2_qwen2 微调
赞
踩

阿里云最新系列语言模型由于性能提升和安全功能增强,于周五推出后迅速跃居开源 LLM 排行榜首位。
Qwen2 系列包括各种基础语言模型和指令调整语言模型,大小从 0.5 到 720 亿个参数,以及混合专家 (MoE) 模型。
这些更新的功能使其在协作人工智能平台 Hugging Face 的 Open LLM Leaderboard 上占据首位,可用于商业或研究活动。

中国电商巨头阿里巴巴在中国人工智能领域占有重要地位。今天,阿里巴巴发布了最新的人工智能模型 Qwen2,该模型被认为是目前最好的开源模型之一。
Qwen2 由阿里云开发,代表了该公司统一千文(Qwen)模型系列的下一阶段,该系列包括统一千文 LLM(Qwen)、视觉 AI 模型 Qwen-VL 和 Qwen-Audio。
Qwen 模型系列已针对不同行业和领域的多语言数据进行了预训练,其中 Qwen-72B 是该系列中最强大的模型。该模型已针对惊人的 3 万亿个 token 数据进行了训练。相比之下,Meta 最强大的 Llama-2 变体基于 2 万亿个 token 构建。与此同时,Llama-3 目前正在处理 15 万亿个 token。
模型详细信息
Qwen2 是一系列语言模型,包括各种大小的解码器模型。阿里巴巴已针对每种大小发布了基础语言模型和对齐聊天模型。这些模型基于 Transformer 架构构建,具有 SwiGLU 激活、注意 QKV 偏差、组查询注意、滑动窗口注意和全注意的混合等功能。此外,阿里巴巴还开发了一种增强的标记器,可适应多种自然语言和代码。
- 型号尺寸:Qwen2–0.5B、Qwen2–1.5B、Qwen2–7B、Qwen2–57B-A14B 和 Qwen2–72B;
- 除了英语和中文之外,还使用了 27 种语言的数据进行训练;
- 各项基准测试中取得优异成绩;
- 增强编码和数学能力;
- 使用 Qwen2-7B 将上下文长度支持扩展到 128K 个标记
- Instruct 和 Qwen2–72B-Instruct。
模型信息
Qwen2 系列由 5 种尺寸的基础和指令调整模型组成:Qwen2–0.5B、Qwen2–1.5B、Qwen2–7B、Qwen2–57B-A14B 和 Qwen2–72B。下表详细介绍了这些模型的基本信息:
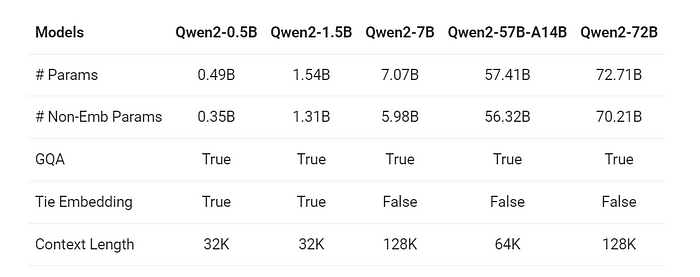
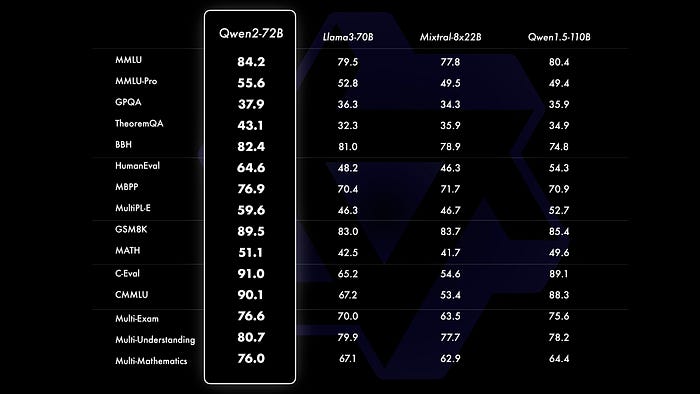
表现
对比评估显示,大规模模型(70B+参数)相比Qwen1.5有显著的性能提升。本研究重点评估大规模模型Qwen2–72B的性能,从自然语言理解、知识获取、编码能力、数学能力、多语言能力等多个方面对Qwen2–72B与前沿开放模型进行比较。得益于精心挑选的数据集和精湛的训练技巧,Qwen2–72B在与Llama-3–70B等顶级模型的对决中展现出优异的表现,尤其在参数较少的情况下,其性能表现优于上一代Qwen1.5–110B。

Qwen2Config
<span style="background-color:#f9f9f9"><span style="color:#242424">(vocab_size = <span style="color:#1c00cf">151936</span> hidden_size = <span style="color:#1c00cf">4096i</span> ntermied_size = <span style="color:#1c00cf">22016</span> num_hidden_layers = <span style="color:#1c00cf">32</span> num_attention_heads = <span style="color:#1c00cf">32</span> num_key_value_heads = <span style="color:#1c00cf">32</span> hidden_act = <span style="color:#c41a16">'silu'</span> max_position_embeddings = <span style="color:#1c00cf">32768i</span> nitializer_range = <span style="color:#1c00cf">0.02</span> rms_norm_eps = <span style="color:#1c00cf">1e-06</span> use_cache = Truetie_word_embeddings = Falserope_theta = <span style="color:#1c00cf">10000.0</span> use_sliding_window = Falsesliding_window = <span style="color:#1c00cf">4096</span> max_window_layers = <span style="color:#1c00cf">28tention_dropout</span> = <span style="color:#1c00cf">0.0</span> **kwargs)</span></span>参数
- vocab_size(
int,可选,默认为 151936)— Qwen2 模型的词汇量。定义调用Qwen2Modelinputs_ids时传递的可以表示的不同标记的数量 - hidden_size (
int,可选,默认为 4096)— 隐藏表示的维度。 - middle_size(
int,可选,默认为 22016)— MLP 表示的维度。 - num_hidden_layers(
int,可选,默认为 32)— Transformer 编码器中的隐藏层的数量。 - num_attention_heads(
int,可选,默认为 32)— Transformer 编码器中每个注意层的注意头的数量。 - num_key_value_heads(
int,可选,默认为 32)— 这是应用于实现分组查询注意的 key_value 头的数量。如果为num_key_value_heads=num_attention_heads,则模型将使用多头注意 (MHA),如果为num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed by meanpooling all the original heads within that group. For more details checkout [this paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to32`。 - hidden_act (
str或function,可选,默认为"silu")——解码器中的非线性激活函数(函数或字符串)。 - max_position_embeddings(
int,可选,默认为 32768)——此模型可能使用的最大序列长度。 - initializer_range(
float,可选,默认为 0.02)— 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - rms_norm_eps (
float,可选,默认为 1e-06)— rms 标准化层使用的 epsilon。 - use_cache (
bool,可选,默认为True) — 模型是否应返回最后的键/值注意(并非所有模型都使用)。仅在 时相关config.is_decoder=True。 - tie_word_embeddings (
bool,可选,默认为False) - 模型的输入和输出词嵌入是否应该绑定。 - rope_theta(
float,可选,默认为 10000.0)— RoPE 嵌入的基准周期。 - use_sliding_window(
bool,可选,默认为False)—是否使用滑动窗口注意力。 - slider_window(
int,可选,默认为 4096)— 滑动窗口注意 (SWA) 窗口大小。如果未指定,则默认为4096。 - max_window_layers(
int,可选,默认为 28)— 使用 SWA(滑动窗口注意力)的层数。底层使用 SWA,顶层使用完全注意力。 - tention_dropout (
float,可选,默认为 0.0)— 注意概率的丢失率。
Ollama — Qwen2
- <span style="background-color:#f9f9f9"><span style="color:#242424">ollama serve
- <span style="color:#007400"># 你需要在使用 ollama 时保持此服务运行</span></span></span>
要提取模型检查点并运行模型,请使用该ollama run命令。您可以通过在 后添加后缀来指定模型大小qwen2,例如:0.5b、:1.5b、:7b或:72b:
- <span style="background-color:#f9f9f9"><span style="color:#242424">ollama run qwen2:7b
- #要退出,请输入“/bye”并按 ENTER</span></span>
您还可以通过其与 OpenAI 兼容的 API 访问 ollama 服务。请注意,您需要 (1)ollama serve在使用该 API 时保持运行,以及 (2)ollama run qwen2:7b在使用此 API 之前执行以确保模型检查点已准备就绪。
- <span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">从</span>openai<span style="color:#aa0d91">导入</span>OpenAI
- 客户端 = OpenAI(
- base_url= <span style="color:#c41a16">'http://localhost:11434/v1/'</span> ,
- api_key= <span style="color:#c41a16">'ollama'</span> , <span style="color:#007400"># 需要但被忽略</span>
- )
- chat_completion = client.chat.completions.create(
- messages=[
- {
- <span style="color:#c41a16">'role'</span> : <span style="color:#c41a16">'user'</span> ,
- <span style="color:#c41a16">'content'</span> : <span style="color:#c41a16">'说这是一个测试'</span> ,
- }
- ],
- model= <span style="color:#c41a16">'qwen2:7b'</span> ,
- )</span></span>
使用 Alpaca 数据集对 Qwen 2 进行微调
以下代码使用 Alpaca 数据集对 Qwen2–0.5B 语言模型进行微调。语言模型对于文本生成、摘要和问答等自然语言处理任务非常有效。
先决条件:所需的软件包和库包括 Unsloth、Xformers (Flash Attention)、trl、peft、accelerate、bitsandbytes、transformers 和 datasets。此代码旨在在 Google Colab 或兼容环境中运行。
步骤 1:安装依赖项
- <span style="background-color:#f9f9f9"><span style="color:#242424">!pip install <span style="color:#c41a16">"unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"</span>
- !pip install --no <span style="color:#aa0d91">-deps</span> xformers <span style="color:#c41a16">"trl<0.9.0"</span> peft 加速 bitsandbytes</span></span>
步骤 2:加载模型和标记器
- <span style="background-color:#f9f9f9"><span style="color:#242424">从 unsloth<span style="color:#aa0d91">导入</span>FastLanguageModel
- <span style="color:#aa0d91">导入</span> <span style="color:#5c2699">torch </span>
- <span style="color:#3f6e74">max_seq_length </span> = <span style="color:#1c00cf">2048</span>
- dtype = <span style="color:#5c2699">None </span>
- <span style="color:#3f6e74">load_in_4bit </span> = <span style="color:#5c2699">True </span>
- <span style="color:#3f6e74">fourbit_models </span> = [
- <span style="color:#c41a16">"unsloth/Qwen2-0.5b-bnb-4bit"</span> ,
- ]
- model, tokenizer = FastLanguageModel.from_pretrained(
- model_name = <span style="color:#c41a16">"unsloth/Qwen2-0.5B"</span> ,
- max_seq_length = max_seq_length,
- dtype = dtype,
- load_in_4bit = load_in_4bit,
- )</span></span>
FastLanguageModel.from_pretrained() 函数加载 Qwen2–0.5B 模型及其 tokenizer。参数 max_seq_length、dtype 和 load_in_4bit 用于配置模型。
步骤 3:应用 PEFT(参数有效微调)
- <span style="background-color:#f9f9f9"><span style="color:#242424">模型 = FastLanguageModel.get_peft_model(
- 模型,
- r = <span style="color:#1c00cf">16</span> ,
- target_modules = [ <span style="color:#c41a16">“q_proj”</span> “ <span style="color:#c41a16">k_proj” </span><span style="color:#c41a16">“v_proj </span><span style="color:#c41a16">” “o_proj”</span> “
- <span style="color:#c41a16">gate_proj”</span> “ <span style="color:#c41a16">up_proj”</span> “ <span style="color:#c41a16">down_proj”</span> ,], lora_alpha
- = <span style="color:#1c00cf">16</span> ,
- lora_dropout = <span style="color:#1c00cf">0</span> ,
- 偏见 = <span style="color:#c41a16">“无”</span> ,
- use_gradient_checkpointing = “ <span style="color:#c41a16">unsloth”</span> ,
- random_state = <span style="color:#1c00cf">3407</span> ,
- use_rslora = <span style="color:#aa0d91">False</span> ,
- loftq_config = <span style="color:#aa0d91">None</span> ,
- )</span></span>
FastLanguageModel.get_peft_model() 函数用于将 PEFT 应用于加载的模型。各种参数(例如 r、target_modules、lora_alpha、lora_dropout、bias、use_gradient_checkpointing、random_state、use_rslora 和 loftq_config)用于配置 PEFT 过程。
步骤 4:定义羊驼提示
alpaca_prompt 变量是格式化输入数据的模板。EOS_TOKEN 和 formatting_prompts_func() 函数用于准备训练数据。
步骤5:加载并预处理数据集
- <span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">从</span>数据集<span style="color:#aa0d91">导入</span>load_dataset
- 数据集 = load_dataset( <span style="color:#c41a16">"yahma/alpaca-cleaned"</span> , split = <span style="color:#c41a16">"train"</span> )
- 数据集 = 数据集.map <span style="color:#5c2699">(</span> formatting_prompts_func, batched = <span style="color:#aa0d91">True</span> ,)</span></span>
使用 Hugging Face 数据集库中的 load_dataset() 函数加载 Alpaca 数据集。使用 map() 函数将 formatting_prompts_func() 函数应用于数据集。
步骤 6:设置训练配置
trl 库中的 SFTTrainer 类用于训练语言模型。TrainingArguments 用于配置各种参数,例如批处理大小、梯度累积步骤、预热步骤、最大步骤、学习率、混合精度设置、记录步骤、优化器、权重衰减、学习率调度程序和种子。
步骤 7:训练模型
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#836c28">训练师统计</span>= 训练师.train()</span></span>调用 trainer.train() 函数启动训练过程。trainer_stats 变量存储训练统计数据。
经过微调的模型可用于各种自然语言处理任务,例如文本生成、摘要和问答。

