
强化学习基本知识_强化学习rl ac单步更新是
赞
踩
一、定义
1、定义
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏。
注:强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物,它的本质是解决 decision making 问题,即自动进行决策,并且可以做连续决策。
2、与监督学习,无监督学习的区别
(1)与监督学习的区别
监督学习可以描述为你在学习过程中,有个老师在旁边教你怎么做,有着严格的标准,而强化学习则没有这个老师教,而且也没有固定的标准方法,其标准方法都是探索出来的。其区别可以归结为以下几点:
- 强化学习是试错学习(Trail-and-error),由于没有直接的指导信息,智能体要以不断与环境进行交互,通过试错的方式来获得最佳策略。
- 延迟回报,强化学习的指导信息很少,而且往往是在事后(最后一个状态)才给出
- 监督学习学习的是输入与输出之间的关系,强化学习学习出的是给机器的反馈 reward function,即用来判断行为是好是坏
(2)与无监督学习的区别
强化学习看似是无监督学习,其实和无监督的学习差别较大,主要体现在几点:
- 无监督的学习更多的是探索数据内部的存在规律或者联系,而强化学习主要探索的是策略方式
- 强化学习和时间有很大的关系,而且反馈都是具有时间效应的,这点和无监督学习非常不一样
二、组成部分
对于大脑的工作原理,我们知之甚少,但是我们知道大脑能通过反复尝试来学习知识。我们做出合适选择时会得到奖励,做出不切当选择时会受到惩罚,这也是我们来适应环境的方式。而强化学习就是利用强大的计算能力,在软件中对这个具体过程进行建模的一种学习。其主要组成部分如下:
智能体(Agent):机器
环境(E):机器所处的环境
状态(S):机器对环境的感知,所有可能的状态称为状态空间;
动作(A):机器所采取的动作,所有能采取的动作构成动作空间;
转移概率(P):当执行某个动作后,当前状态会以某种概率转移到另一个状态;
奖赏函数(R):在状态转移的同时,环境反馈给机器一个奖赏。
三、工作原理
强化学习的工作原理我们可以利用下面的一个例子进行说明:
下图的迷宫中,有一只老鼠,想象下你是那只老鼠,为了在迷宫中尽可能多地收集奖励(水滴和奶酪),你会怎么做?在每个状态下(即迷宫中的位置),你要计算出为获得附近奖励需要采取哪些步骤?当右边有3个奖励,左边有1个奖励,你会选择往哪边走?

这就是强化学习的工作原理。在每个状态下,agent会对所有可能动作(上下左右)进行计算和评估,并选择能获得最多奖励的动作。进行若干步后,迷宫中的小鼠会熟悉这个迷宫,最终采取一个最优的方法从而获得最大的奖励。
但如何确定哪个动作会得到最佳结果呢?这就涉及到强化学习的决策过程。
四、强化学习的分类
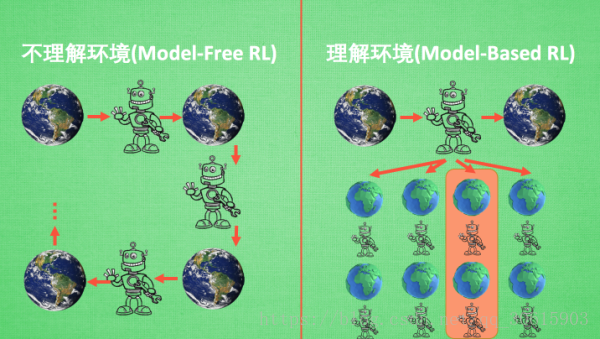
1、Model-free 和 Model-based
举个栗子:我们刚刚学习强化学习的时候都学习过gridworld这个机器人走迷宫的例子吧,就是有一个迷宫机器人从起点出发通过强化学习的方式选择出到达终点的最优路径。
model-based方式就是我们给机器人地图全开,事先了解好整个游戏环境根据过往的经验选取最优策略,也就是说model-based他能通过想象来预判断接下来将要发生的所有情况. 然后选择这些想象情况中最好的那种. 并依据这种情况来采取下一步的策略
model-free方法就是不依赖模型,这种情况下就是直接将我们的机器人丢到迷宫里面瞎溜达,然后机器人会根据现实环境的反馈采取下一步的动作。这种方法不对环境进行建模也能找到最优的策略。Model-free 的方法有很多, 像 Q learning, Sarsa, Policy Gradients 都是从环境中得到反馈然后从中学习。
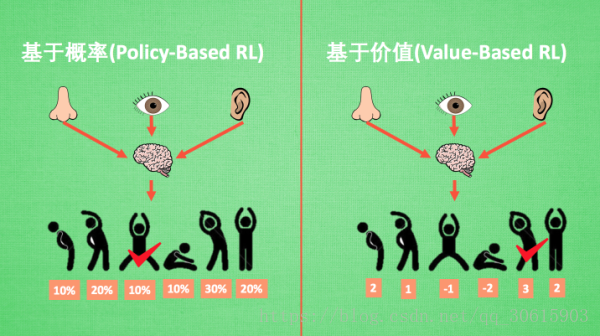
2、Policy-based RL 和 Value-based RL
说道Policy与Value就不得不提到他们的两大代表算法,Policy-based有 Policy Grandient;Value-based有Q-Learning。根据这两种算法我们很清晰的就能看出他们之间的区别,Policy-based算法是通过算法计算出下一个动作的概率,并根据概率来选取对应动作。而Value-based是通过潜在奖励计算出动作回报期望来作为选取动作的依据。
Policy基于概率的算法在连续动作空间上比起Value-based更有优势
还有一种nb的算法Actor-Critic他结合了这两类方法的优势之处, actor 会基于概率做出动作,而 critic 会对做出的动作给出动作的价值, 这样就在原有的 policy gradients 上加速了学习过程。
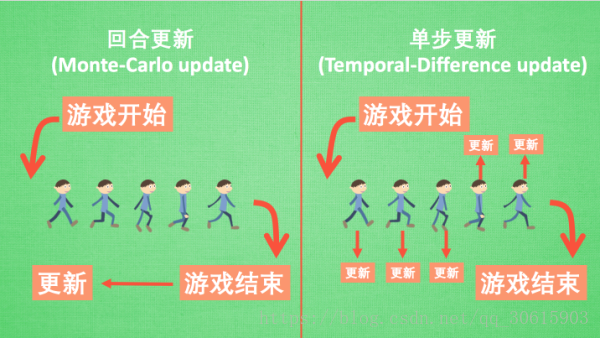
3、回合更新 和 单步更新
回合更新和单步更新, 假设强化学习就是在玩游戏, 游戏回合有开始和结束. 回合更新指的是游戏开始后,我们要等到打完这一局我们才对这局游戏的经历进行总结学习新的策略。 而单步更新则是在游戏进行中每一步都在更新,这样就可以一边游戏一边学习不用等到回合结束。
再来说说方法, Monte-carlo learning 和基础版的 policy gradients 等 都是回合更新制, Qlearning, Sarsa, 升级版的 policy gradients 等都是单步更新制. 因为单步更新更有效率, 所以现在大多方法都是基于单步更新。 比如有的强化学习问题并不属于回合问题。
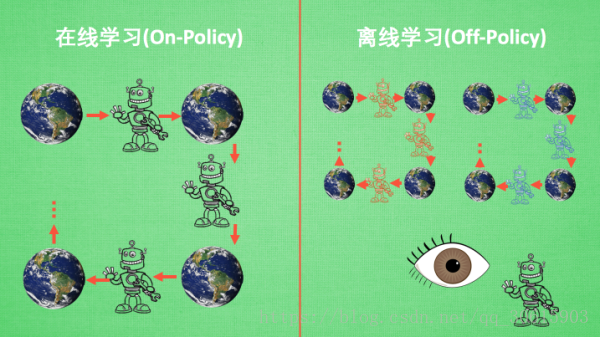
4、在线学习 和 离线学习
On-Policy在线学习智能体本身必须与环境进行互动然后一边选取动作一边学习。
Off-Policy是指智能体可以亲自与环境进行交互进行学习,也可以通过别人的经验进行学习,也就是说经验是共享的,可以使自己的过往经验也可以是其他人的学习经验。
最典型的在线学习就是 Sarsa 了, 还有一种优化 Sarsa 的算法, 叫做 Sarsa lambda, 最典型的离线学习就是 Q learning, 后来人也根据离线学习的属性, 开发了更强大的算法, 比如让计算机学会玩电动的 Deep-Q-Network
五、强化学习常用算法
1、模型已知(Model Based)的动态规划方法
在模型已知的MDP情况下,MDP的状态转移概率和回报函数已知,此时,可以采用动态规划的方法来寻找最优的策略。常用的动态规划方法有四种:
(1)策略迭代方法。根据Bellman方程,通过策略迭代和策略评估交替进行,求取最优策略。
(2)值函数迭代方法。通过一种逐次逼近方式,将有限时段的动态规划算法推广到无限时段上。
(3)线性规划方法。根据Bellman方程,将值函数的求取转换为一个线性规划问题求解。
(4)广义策略迭代方法。结合策略迭代和值迭代的一种强化学习方法。
2、模型未知(Model Free)的强化学习方法
蒙特卡罗学习、TD学习、Q学习、SARSA学习。
3、近似强化学习的基本方法
带值函数的TD学习、近似值迭代、近似策略迭代和最小二乘策略迭代。

